
git 笔记
从根本上来讲 Git 是一个内容寻址(content-addressable)文件系统,并在此之上提供了一个版本控制系统的用户界面。
objects 目录存储所有数据内容;
refs 目录存储指向数据(分支)的提交对象的指针;
HEAD 文件指示目前被检出的分支;
index 文件保存暂存区信息
Git 的核心部分是一个简单的键值对数据库(key-value data store)。 你可以向该数据库插入任意类型的内容,它会返回一个键值,通过该键值可以在任意时刻再次检索(retrieve)该内容
所有内容均以树对象和数据对象的形式存储,
Git 以一种类似于 UNIX 文件系统的方式存储内容,但作了些许简化。 所有内容均以树对象和数据对象的形式存储,其中树对象对应了 UNIX 中的目录项,数据对象则大致上对应了 inodes 或文件内容。 一个树对象包含了一条或多条树对象记录(tree entry),每条记录含有一个指向数据对象或者子树对象的 SHA-1 指针,以及相应的模式、类型、文件名信息。 例如,某项目当前对应的最新树对象可能是这样的:
Git中对象类型:
(1)blob对象。
blob对象就是单纯存储数据
(2)tree对象。
像一个目录,管理一些“tree”对象或是“blob”对象
(3)commit对象。
“commit”对象指向一个“tree对象”
(4)tag对象。
一个“tag”对象包括一个对象名(SHA1签名)、对象类型、标签名、标签创建人的名字(“tagger”), 还有一条可能包含有
签名(signature)的消息。
树对象;
一个tree对象有一串(bunch)指向blob对象或是其它tree对象的指针,它一般用来表示内容之间的目录层次关系。

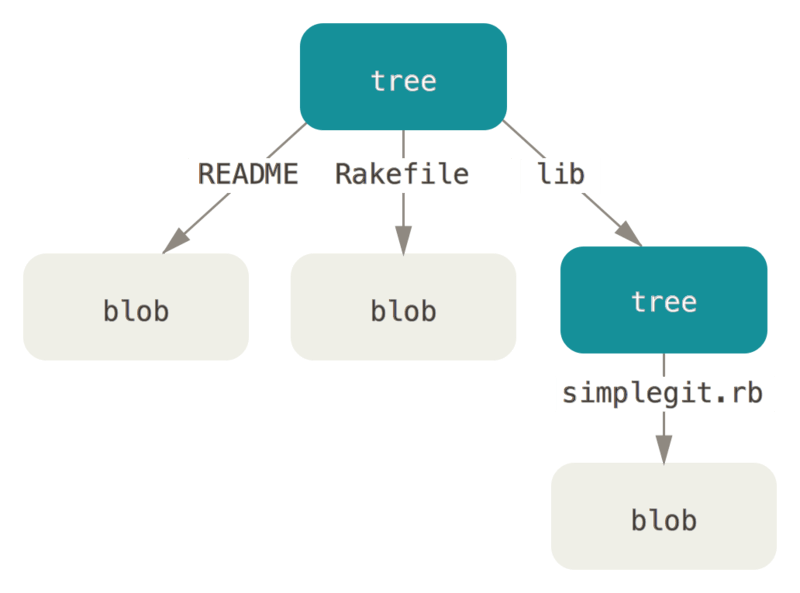
为创建一个树对象,首先需要通过暂存一些文件来创建一个暂存区
Commit对象
"commit对象"指向一个"tree对象", 并且带有相关的描述信息.

对象模型汇总:
如果我们一个小项目, 有如下的目录结构:
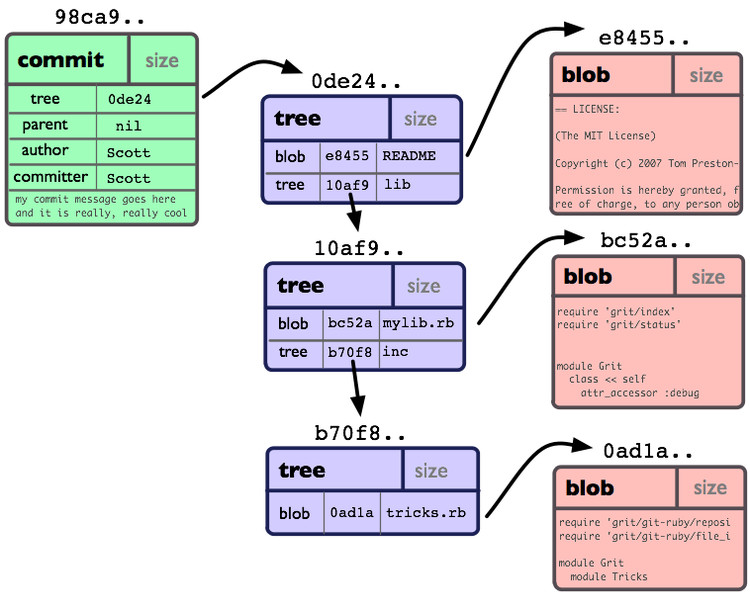
你可以看到: 每个目录都创建了 tree对象 (包括根目录), 每个文件都创建了一个对应的 blob对象 . 最后有一个 commit对象 来指向根tree对象(root of trees), 这样我们就可以追踪项目每一项提交内容.
新增一个文件`
echo 'new file' > newindex.txt
生成数据object
git hash-object newindex.txt

添加到缓存区:
[使用 plumbing 命令 update-index 为一个单独文件 ── test.txt 文件的第一个版本 ── 创建一个 index 。通过该命令人为的将 test.txt 文件的首个版本加入到了一个新的暂存区域中。由于该文件原先并不在暂存区域中 (甚至就连暂存区域也还没被创建出来呢) ,必须传入 --add 参数;由于要添加的文件并不在当前目录下而是在数据库中,必须传入 --cacheinfo 参数。同时指定了文件模式,SHA-1 值和文件名]
git update-index --cacheinfo 100644 748f86e01eb9768e7960b2c7bdf49b284a5160cc newindex.txt

--写入tree节点
$ git write-tree
938d5c398b6ad800099ebc9fb6e1ed0f90923cef
--查看tree节点
$ git cat-file -p 938d5c398b6ad800099ebc9fb6e1ed0f90923cef
100644 blob b256fc2452eb6a96734cb43b694d4462b5080b60 1.txt
100644 blob 9fac77700d61864e5e36f3b8293aeaafb381bb4d 2.txt
100644 blob 3bd9bce7058fdf7b9809c5a87053a5270c6a75ea 3.txt
--commit
$ echo 'my hand commit'| git commit-tree 938d5c398b6ad800099ebc 672dc75a18105da2402d6d329c75954653917d0c
--查看commit对象
$ git cat-file -p 672dc75a18
tree 938d5c398b6ad800099ebc9fb6e1ed0f90923cef author yangxxxong <yangxxxong@corp.autohome.inc> 1552612641 +0800 committer yangxxxong <yangxxxong@corp.autohome.inc> 1552612641 +0800 encoding gbk my hand commit
tree 938d5c398b6ad800099ebc9fb6e1ed0f90923cef
author yangxulong <yangxulong@corp.autohome.inc> 1552612641 +0800
committer yangxulong <yangxulong@corp.autohome.inc> 1552612641 +0800
encoding gbk
my hand commit
与SVN的区别
git 包文件:
Git 使用 zlib 压缩这些文件内容,但针对同一个大文件非常小的修改也会存储两个完整的版本, 这意味着存储两个基本相同的object对象, 如果 Git 只完整保存其中一个,再保存另一个对象与之前版本的差异内容,岂不更好?
事实上 Git 可以那样做。 Git 最初向磁盘中存储对象时所使用的格式被称为“松散(loose)”对象格式。 但是,Git 会时不时地将多个这些对象打包成一个称为“包文件(packfile)”的二进制文件,以节省空间和提高效率。 当版本库中有太多的松散对象,或者你手动执行 git gc 命令,或者你向远程服务器执行推送时,Git 都会这样做。
存储路径:.git/objects/pack/pack*.idx
git数据对象的创建:
1. 计算SHA-1值,
拼接字符串CONTENT:对象类型(tree,blob,commit),+原始数据类型
使用Ruby,调用SHA-1算法计算SHA-1值
2.Git 会通过 zlib 压缩这条新内容(CONTENT)。在 Ruby 中可以借助 zlib 库.
3. w最后将这条经由 zlib 压缩的内容写入磁盘上的某个对象。 要先确定待写入对象的路径(SHA-1 值的前两个字符作为子目录名称,后 38 个字符则作为子目录内文件的名称)
4. 你已创建了一个有效的 Git 数据对象。
plus:
所有的 Git 对象均以这种方式存储,区别仅在于类型标识——另两种对象类型的头部信息以字符串“commit”或“tree”开头,而不是“blob”。 另外,虽然数据对象的内容几乎可以是任何东西,但提交对象和树对象的内容却有各自固定的格式。
Git rebase
把一个分支中的修改整合到另一个分支的办法有两种,第一种是我们常用的git merge操作,而第二种便是本节要讲的rebase(中文翻译为衍合)。该命令的原理是,回到两个分支最近的共同祖先,根据当前分支(也就是要进行衍合的分支experiment)后续的历次提交对象(这里只有一个 C3),生成一系列文件补丁,然后以基底分支(也就是主干分支master)最后一个提交对象(C4)为新的出发点,逐个应用之前准备好的补丁文件,最后会生成一个新的合并提交对象(C3'),从而改写 experiment 的提交历史,使它成为 master 分支的直接下游。如下图所示:
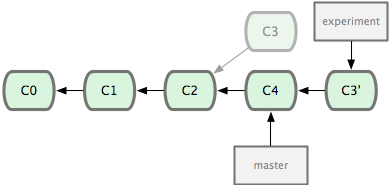
一般我们使用rebase的目的,是想要得到一个能在远程分支上干净应用的补丁,比如某些项目你不是维护者,但想帮点忙的话,最好用rebase:先在自己的一个分支里进行开发,当准备向主项目提交补丁的时候,根据最新的 origin/master 进行一次衍合操作然后再提交,这样维护者就不需要做任何整合工作(实际上是把解决分支补丁同最新主干代码之间冲突的责任,化转为由提交补丁的人来解决),只需根据你提供的仓库地址作一次快进合并,或者直接采纳你提交的补丁。
在rebase的过程中,也许会出现冲突。在这种情况,Git会停止rebase并会让你去解决冲突;在解决完冲突后,用git add命令去更新这些内容的索引, 然后,你无需执行git-commit,只要执行git rebase –continue,这样git会继续应用(apply)余下的补丁。如果要舍弃本次衍合,只需要git rebase --abort即可。切记,一旦分支中的提交对象发布到公共仓库,就千万不要对该分支进行rebase操作。
我们在使用git pull命令的时候,可以使用--rebase参数,即git pull --rebase。这里表示把你的本地当前分支里的每个提交取消掉,并且把它们临时保存为补丁(这些补丁放到.git/rebase目录中),然后把本地当前分支更新为最新的origin分支,最后把保存的这些补丁应用到本地当前分支上。在使用tortoise的pull的过程中,如果你留意tortoiseGit的日志的话,你就会发现,它使用的就是这种方式来pull最新的提交的。
Git reset
在使用Git的过程中,由于操作不当,作为初学者的我们可能经常要去解决冲突。某些时候,当你不小心改错了内容,或者错误地提交了某些commit,我们就需要进行版本的回退。版本回退最常用的命令包括git reset和git revert。这两个命令允许我们在版本的历史之间穿梭。
下面就几种比较经典的场景进行总结:
-
场景1:当你改乱了工作区某个文件的内容,想直接丢弃工作区的修改时,用命git checkout -- filename;
-
场景2:当你不但改乱了工作区某个文件的内容,还添加到了暂存区时,想丢弃修改,分两步,第一步用命令git reset HEAD file,就回到了场景1,第二步按场景1操作;
-
场景3:已经提交了不合适的修改到版本库时,想要撤销本次提交,使用git reset --hard commit_id,不过前提是没有推送到远程库。
穿梭前,用git log可以查看提交历史,以便确定要回退到哪个版本;要重返未来,用git reflog查看命令历史,以便确定要回到未来的哪个版本。
Git revert
Git revert用来撤销某次操作,此次操作之前和之后的commit和history都会保留,并且把这次撤销作为一次最新的提交。git revert是提交一个新的版本,将需要revert的版本的内容再反向修改回去,版本会递增,不影响之前提交的内容。
Git revert和git reset都可以进行版本的回退,将工作区回退到历史的某个状态,二者有如下的区别:
-
git revert是用一次新的commit来回滚之前的commit,而git reset是直接删除指定的commit(并没有真正的删除,通过git reflog可以找回),这是二者最显著的区别;
-
git reset 是把HEAD向后移动了一下,而git revert是HEAD继续前进,只是新的commit的内容和要revert的内容正好相反,能够抵消要被revert的内容;
-
在回滚这一操作上,效果差不多。但是在日后继续merge以前的老版本时有区别。因为git revert是用一次逆向的commit"中和"之前的提交,因此日后合并老的branch时,导致这部分改变不会再次出现;但是git reset是之间把某些commit在某个branch上删除,因而和老的branch再次merge时,这些被回滚的commit应该还会被引入。
参考:
http://git.oschina.net/progit/9-Git-%E5%86%85%E9%83%A8%E5%8E%9F%E7%90%86.html
https://www.cnblogs.com/yelbosh/p/7471979.html
