ElasticSearch 笔记
ES集群脑裂出现的原因:
1:网络原因
内网一般不会出现此问题,可以监控内网流量状态。外网的网络出现问题的可能性大些。
2:节点负载
主节点即负责管理集群又要存储数据,当访问量大时可能会导致es实例反应不过来而停止响应,此时其他节点在向主节点发送消息时得不到主节点的响应就会认为主节点挂了,从而重新选择主节点。
3:回收内存
大规模回收内存时也会导致es集群失去响应。
两节点集群脑裂的预防:
在一个两节点集群,你可以添加一个新节点并把 node.data 参数设置为“false”。这样这个节点不会保存任何分片,但它仍然可以被选为主(默认行为)。因为这个节点是一个无数据节点,所以它可以放在一台便宜服务器上。现在你就有了一个三节点的集群,可以安全的把minimum_master_nodes设置为2,避免脑裂而且仍然可以丢失一个节点并且不会丢失数据。
结论
脑裂问题很难被彻底解决。在elasticsearch的问题列表里仍然有关于这个的问题, 描述了在一个极端情况下正确设置了minimum_master_nodes的参数时仍然产生了脑裂问题。 elasticsearch项目组正在致力于开发一个选主算法的更好的实现,但如果你已经在运行elasticsearch集群了那么你需要知道这个潜在的问题。
对于大型的生产集群来说,推荐使用一个专门的主节点来控制集群,该节点将不处理任何用户请求。
部落节点:部落节点可以跨越多个集群,它可以接收每个集群的状态,然后合并成一个全局集群的状态,它可以读写所有节点上的数据。
Elasticseach查询分为两种,结构化查询和全文查询;
solr使用zk作为分布式管理器, elasticsearch自己维护分布式管理(脑裂问题)
Z 阶曲线通过交织点的坐标值的二进制表示来简单地计算多维度中的点的z值。一旦将数据被加到该排序中,任何一维数据结构,例如二叉搜索树,B树,跳跃表或(具有低有效位被截断)哈希表 都可以用来处理数据。通过 Z 阶曲线所得到的顺序可以等同地被描述为从四叉树的深度优先遍历得到的顺序。
这也是 Geohash 的另外一个优点,搜索查找邻近点比较快。
kafka具有高的吞吐量,内部采用消息的批量处理,zero-copy机制,数据的存储和获取是本地磁盘顺序批量操作,具有O(1)的复杂度,消息处理的效率很高。
rabbitMQ在吞吐量方面稍逊于kafka,他们的出发点不一样,rabbitMQ支持对消息的可靠的传递,支持事务,不支持批量的操作;基于存储的可靠性的要求存储可以采用内存或者硬盘。
Kafka是可靠的分布式日志存储服务。用简单的话来说,你可以把Kafka当作可顺序写入的一大卷磁带, 可以随时倒带,快进到某个时间点重放
ELK一般部署:
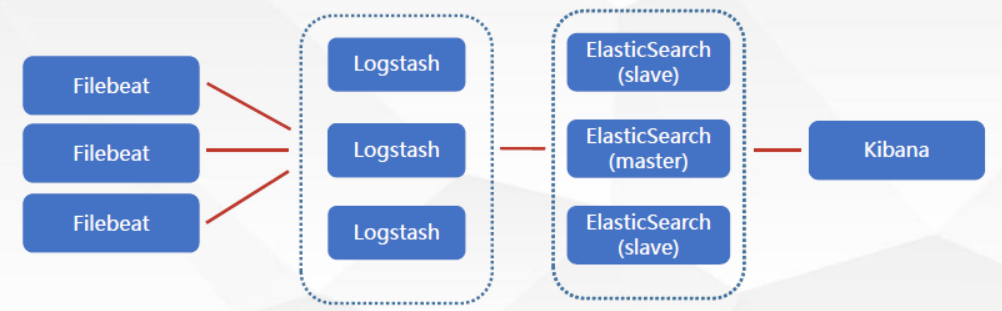
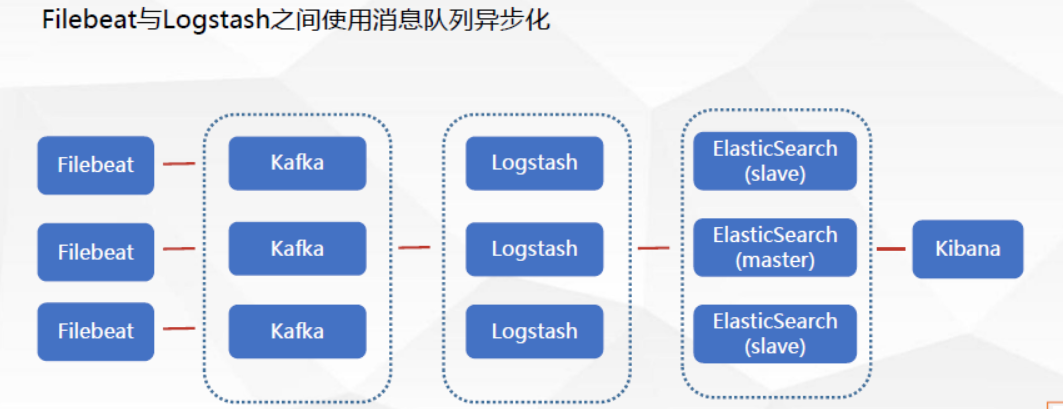
ELK海量日志部署:
Filebeat支持异步话, 增加消息队列机制Kafka

 浙公网安备 33010602011771号
浙公网安备 33010602011771号