【Spark】Spark性能优化之Whole-stage code generation
一、技术背景
Spark1.x版本中执行SQL语句,使用的是一种最经典,最流行的查询求职策略,该策略主要基于 Volcano Iterator Model(火山迭代模型)。一个查询会包含多个Operator,每个Operator都会实现一个接口,提供一个next()方法,该方法返回Operator Tree的下一个Operator,能够让查询引擎组装任意Operator,而不需要去考虑每个Operator具体的处理逻辑,所以Volcano Iterator Model 才成为了20年中SQL执行引擎最流行的一种标准。
比如如下SQL语句:
select count(*) from employees where salary == 1000
使用Java代码手写实现的SQL功能的代码如下
int count = 0; for(emp : employees){ if(emp == 1000){ count += 1; } }
有人实验了Volcano Iterator Model 方式与直接手写Java代码实现的方式,直接手写Java代码是专门为了实现某个指定的功能而编写的,不具有良好的组装性和扩展性,这两种方式进行了性能的对比结果如下图。
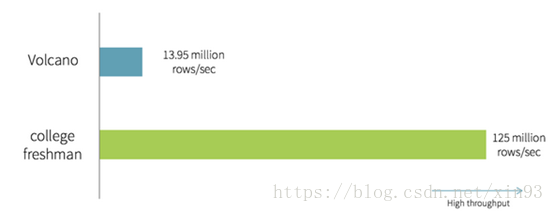
可以看到直接手写Java代码实现某一特定功能的性能比Volcano模型的性能高出了一个数量级,主要的原因有三点:
1. 避免了虚函数调用(Virtual Function Dispatch),Volcano Iterator Model至少需要调用一次next()获取下一个Operator,在操作系统层面会被编译为Virtual Function Dispatch,会执行多个CPU指令,并且速度慢。而直接编写的Java代码中没有任何函数调用逻辑。
2. 使用CPU寄存器存取中间数据 。 Volcano Iterator Model将数据交给下一个Operator时,都需要将数据写入内存缓冲,但是在手写代码中,JVM JIT编译器会将这些数据写入CPU寄存器,CPU直接从寄存器中读写数据比在内存缓冲中读写数据的性能要高一个数量级。
3.编译器Loop Unrolling。手写代码针对某特定功能使用简单循环,而现代的编译器可以自动的对简单循环进行Unrolling,生成单指令多数据流(SIMD),在每次CPU指令执行时处理多条数据。而这些优化特点无法在Volcano Iterator Model复杂的函数调用场景中施展。
二、Whole-stage code generation
1. Spark性能调优思路
在以上论述的技术背景下,如果要对Spark进行性能优化,应该避免使用Volcano模型,在运行时动态生成代码。由此,Spark2.x版本中,基于Tungsten引擎的Whole-stage code generation 技术应运而生。SQL语句编译后的Operator-Tree中,每个Operator不再执行逻辑,而是通过全流式代码生成技术在运行时动态生成代码,并尽量将所有的操作打包到一个函数中。如果是简单查询,Spark会尽量生成一个Stage,如果是复杂的查询,就可能会生成多个Stage。
2. Spark2.x的SQL执行计划
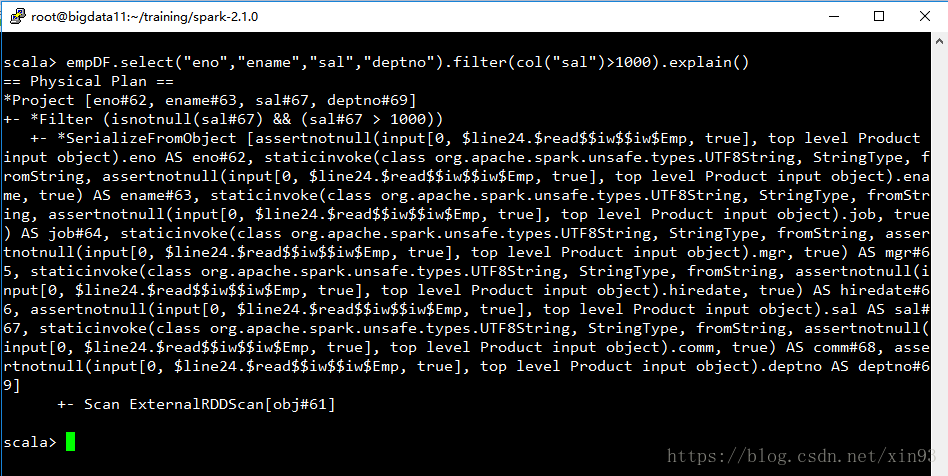
Spark提供了一个explain( )方法来查询SQL的执行计划。
例子:
准备工作:通过saprk读取HDFS上的员工表信息(emp.csv),执行操作如下:
scala> case class Emp(eno:Int,ename:String,job:String,mgr:String,hiredate:String,sal:Int,comm:String,deptno:Int)
defined class Emp
scala> val lines = sc.textFile("hdfs://bigdata11:9000/input/emp.csv").map(_.split(","))
lines: org.apache.spark.rdd.RDD[Array[String]] = MapPartitionsRDD[9] at map at <console>:24
scala> val allEmp = lines.map(x => Emp(x(0).toInt,x(1),x(2),x(3),x(4),x(5).toInt,x(6),x(7).toInt))
allEmp: org.apache.spark.rdd.RDD[Emp] = MapPartitionsRDD[10] at map at <console>:28
scala> val empDF = allEmp.toDF
empDF: org.apache.spark.sql.DataFrame = [eno: int, ename: string ... 6 more fields]
查看执行计划:通过explain()方法查看执行计划。前面带*号的步骤就是通过whole-stage code generation生成的。
三、总结
从以上分析可以看出Spark2.x引入的whole-stage code generation技术,使Spark2.x的性能比Spark1.x的性能有所提高。但并不是所有的操作都能够大幅提升性能,whole-stage code generation技术是从CPU密集操作的方面进行性能调优,对IO密集操作的层面是无法提高效率的,比如Shuffle中产生的读写磁盘操作是无法通过该技术提升性能的,Spark未来版本的更新还需要从IO密集操作层面进行性能调优。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号