PROC SQL 005
上一节,我们提到了 CASE 表达式在 PROC SQL 中的应用。事实上,PROC SQL 支持更为一般的 SQL 表达式。
表达式的结构
SQL 表达式由操作数(operand)和操作符(operator)组成。
操作数可以是以下任意一种:
- 常量
- 变量
- CASE 表达式
- 任何受支持的 SAS 函数
- 任何使用 PROC FCMP 创建的函数(含数组参数的函数除外)
- 聚集函数
- 查询表达式
操作符可以是以下任意一种:
- 算数运算符(
+ - * / **) - 比较运算符(
lt le eq ge gt ne < <= = >= > ^=) - 逻辑运算符(
not and or ^ & |) - 子集运算符(
IS IN BETWEEN LIKE CONTAINS EXISTS) - 其他运算符(
() ||)
操作数可以单独使用作为查询结果,但操作符必须与至少一个操作数同时使用才有意义。根据操作符需要的操作数的数量,有一元操作符、二元操作符等。SAS 根据操作符的运算优先级对表达式进行求值,求值结果即为查询的结果。可以使用括号改变表达式运算的顺序,这使得我们不必记住所有操作符的运算优先级,当不确定某个表达式的运算顺序时,使用括号显式指明运算顺序即可。
先来个例子感受一下:
proc sql;
select
MONOTONIC() as seq label = "序号",
name,
WEIGHT,
WEIGHTU,
put(WEIGHT, 8.2) || " " || WEIGHTU as WEIGHTC,
HEIGHT,
HEIGHTU,
put(HEIGHT, 8.2) || " " || HEIGHTU as HEIGHTC,
((WEIGHTU = "pound") * (WEIGHT * 0.4536) + (WEIGHTU = "kg") * WEIGHT) /
((HEIGHTU = "inch") * (HEIGHT * 0.0254) + (HEIGHTU = "m") * HEIGHT) ** 2
as BMI1 label = "BMI1(kg/m^2)" format = 8.2,
(case when WEIGHTU = "pound" then WEIGHT * 0.4536 else WEIGHT end) /
(case when HEIGHTU = "inch" then HEIGHT * 0.0254 else HEIGHT end) ** 2
as BMI1 label = "BMI2(kg/m^2)" format = 8.2
from class;
quit;
这里例子中,生成变量 WEIGHTC 和 HEIGHTC 的表达式较为简单,仅使用了 SAS 函数和字符串连接符;而生成变量 BMI1 和 BMI2 的表达式则要复杂得多。
💡 计算 BMI1 变量的表达式中,使用了逻辑运算符 =。逻辑表达式的计算结果通常是一个布尔值,在 SAS 中,若表达式结果为 “真”,则运算结果为 1,若为 “假” ,则运算结果为 0。这一特性使得我们可以将逻辑表达式嵌套在算数表达式中,更进一步地说,这其实可以看成指示函数(Indicator function)的一种形式。
💡 计算 BMI2 变量的表达式中,使用了 CASE 表达式的运算结果作为算数表达式 / 的两个操作数,不难发现 CASE 表达式的计算结果也可以作为操作数在其他表达式中使用。
SQL 表达式大部分用法与 DATA 步是一致的,一些简单的用法在此处就不再一一列举了,下面介绍两种仅在 PROC SQL 中常用的表达式用法。
聚集函数
我们都知道,SAS 在执行 DATA 步的时候是以观测为单位的,遍历每条观测,并重复执行 DTAT 步中的可执行语句。这使得在 DATA 步中对变量的横向操作是非常方便的,但与此同时,在 DATA 步中对观测纵向操作却是较为困难的。
例如:计算某条数值变量的均值,DATA 步的做法通常是使用 retain 语句进行,通过保留变量值到下一个观测,实现累加。简单的计算逻辑尚且可以这么做,但如若遇到复杂的逻辑,我们可能需要声明多个 retain 变量,并时刻注意变量值的改变,当运算完成后,可能还需要将临时变量删除,繁琐的语句不仅会降低代码可读性,还可能容易出错。
在 PROC SQL 中,有一类函数被称为聚集函数,专门用来实现对整个数据集中某种信息的汇总。常见的聚集函数如下:
N/FREQ/COUNT: 非缺失频数NMISS: 缺失频数AVG/MEAN: 算术平均数MEDIAN: 中位数MIN: 最小值MAX: 最大值VAR: 方差STD: 标准差STDERR: 标准误SUM: 合计
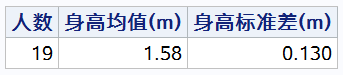
下面的例子使用了聚集函数 count(), mean(), std() 对数据集 class 进行了简单的统计量计算:
proc sql;
select
count(name) as n label = "人数",
mean(height) as mean_hgt label = "身高均值(m)" format = 8.2,
std(height) as std_hgt label = "身高标准差(m)" format = 8.3
from class;
quit;
输出结果:
如果需要对不重复的观测进行汇总统计,可以在聚集函数中使用 DISTINCT 关键字,例如,统计发生不良事件的受试者数量:
proc sql;
select count(distinct usubjid) from adae;
quit;
子集
在某些时候,我们可能只需要查询结果中的一个子集,这时候可以使用 where 子句进行子集的筛选。where 子句支持以下取子集的操作符:
IS MISSING: 缺失值IN: 属于某个集合BETWEEN: 介于某两个值,含边界值LIKE: 模糊匹配CONTAINS: 变量包含某个值EXISTS: 子查询非空
具体介绍:
IS MISSING
proc sql;
select * from adae where aestdt is missing;
quit;
这个例子中,使用 IS 操作符筛选发生日期缺失的所有不良事件的信息。注意:IS 操作符的右侧只能是 NULL 或 MISSING,二者含义相同。
IN
proc sql;
select * from sashelp.class where name in ("John", "Thomas");
quit;
输出结果:
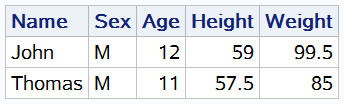
这个例子中,使用 IN 操作符筛选名称为 "John" 和 "Thomas" 的学生信息。
BETWEEN
proc sql;
select * from sashelp.class where (age between 11 and 12) and (name between "L" and "T");
quit;
输出结果:
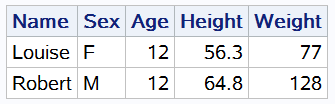
这个例子中,使用 BETWEEN 操作符筛选年龄在 11 ~ 12 岁,且姓名首字母在 "L" ~ "T" 的学生信息。注意:BETWEEN 操作符定义的范围两端必须是同一类型的值。
LIKE
proc sql;
select * from sashelp.class where name like "Jane_" or name like "Ro%";
quit;
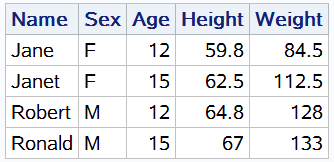
这个例子中,使用 LIKE 操作符进行了姓名的模糊匹配,获取匹配到的的学生信息。其中:
- 下划线 (
_) : 匹配 0 个或 1 个字母 - 百分号 (
%) : 匹配 0 个或 n 个字母(n > 0)
CONTAINS
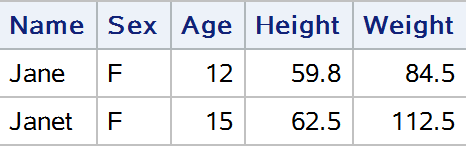
proc sql;
select * from sashelp.class where name contains "Jane";
quit;
💡 受限于目前对 PROC SQL 的了解程度,EXISTS 操作符将在以后进行介绍。
