PROC SQL 004
上一节,我们介绍了使用 SELECT 语句对变量进行查询,这一节我们继续介绍 SELECT 的简单查询操作。
常量
常量包括数值常量和字符串常量,有时候也被称为字面量(literal)。
proc sql noprint;
create table ADSL as
select
"TEST-CLINICAL-TRIAL-2023-0012" as STUDYID,
USUBJID,
SITEID,
SEX,
AGE
from DM;
quit;
上述代码中,在查询语句中使用了常量 "TEST-CLINICAL-TRIAL-2023-0012",查询结果存储在新创建的数据集 ADSL 中。ADSL 包括数据集 DM 中的 4 个变量,以及使用常量定义的一个变量 STUDYID。
💡 使用关键字 AS 可以为未命名的变量指定一个变量名(又称别名),便于后续引用。若查询结果仅仅是为了展示,可以不定义别名;若查询结果将存储在数据集中,则应当指定一个别名,否则 SAS 将自动指定一个变量名(根据查询类型,可以是 _TEMAxxx 或 _TEMGxxx)。基于代码可读性的考虑,依赖 SAS 的自动命名机制是不可取的,在创建数据集的任何时候都应当显式指定变量名。
CASE 表达式
SELECT 语句支持使用 CASE 表达式按照条件进行查询。
proc sql;
select
USUBJID,
SITEID,
SEX,
(case SEX
when "F" then "男"
when "M" then "女"
end) as SEXC
from DM;
quit;
上述代码使用 CASE 表达式根据变量 SEX 的值衍生新的变量 SEXC,对于某一条观测,其变量 SEX 的值都会与指定的 WHEN 条件进行比较,直到符合某一条 WHEN 条件,此时将 THEN 后面的结果作为查询结果赋值给变量 SEXC。
CASE 表达式还有另一种写法,可以不在 CASE 后面指定变量名,但是在 WHEN 后面指定具体的条件,上述代码可以改写为:
proc sql;
select
USUBJID,
SITEID,
SEX
(case
when SEX = "F" then "男"
when SEX = "M" then "女"
end) as SEXC
from DM;
quit;
💡 这两种写法的区别是:第一种适用于要执行的比较仅涉及单个变量的情况,第二种适用于要执行的比较涉及多个变量的情况。
例如,下面的例子就只能使用 CASE 表达式的第二种写法:
proc sql;
select
USUBJID,
SITEID,
SEX
(case
when CMSTDT < TRTDT then "既往用药"
when CMSTDT >= TRTDT then "合并用药"
end) as CMSCAT
from DM;
quit;
通常,CASE 表达式还可以使用 ELSE 关键字指定一条 “兜底” 的查询结果,当所有 WHEN 条件都不匹配时,将返回 ELSE 表达式结果。
proc sql;
select
USUBJID,
SITEID,
(case when HEIGHTU = "m" then HEIGHT/WEIGHT**2
when HEIGHTU = "cm" then HEIGHT/100/WEIGHT**2
else -1
end) as BMI
from DM;
quit;
此外,CASE 表达式也可以嵌套使用,从而实现复杂条件的判断,这类似于 DATA 步中 IF ELSE 语句的嵌套,例如:
proc sql;
select
USUBJID,
SITEID,
(case when HEIGHTU = "m" then
(case when WEIGHTU = "kg" then HEIGHT/WEIGHT**2
when WEIGHTU = "pound" then HEIGHT/(WEIGHT*0.4536)**2
else -1
end)
when HEIGHTU = "cm" then
(case when WEIGHTU = "kg" then HEIGHT/100/WEIGHT**2
when WEIGHTU = "pound" then HEIGHT/100/(WEIGHT*0.4536)**2
else -1
end)
else -1
end) as BMI
from DM;
quit;
函数
SELECT 语句中可以使用任何支持的 SAS 函数,函数的返回值将作为查询结果。PROC SQL 支持大部分 SAS 内置函数以及任何不含数组参数的 PROC FCMP 自定义函数。例如:下面的代码在 SELECT 语句中使用了 INTCK 函数计算用药的持续天数。
proc sql;
select
USUBJID,
SITEID,
CMSTDT,
CMENDT,
intck("day", CMSTDT, CMENDT) as CMDURDT
from CM;
quit;
SELECT 语句支持使用自定义函数。例如:下面的代码在 SELECT 语句中使用了自定义函数 IMPUTE_CMSTDT 用于填补变量 CMSTDT 的缺失日期,受限于篇幅,这里没有给出函数 IMPUTE_CMSTDT 的定义。
proc sql;
select
USUBJID,
SITEID,
impute_cmstdt(CMSTDTC, CMENDTC, TRTSDTC) as CMSTDT format = yymmdd10.,
CMENDT
from CM;
quit;
这里再额外介绍一个 SAS 9.4 尚未公开于文档中的函数:MONOTONIC()。这个函数的作用是自增计数,类似于 DATA 步中的自动变量 _n_,这在附带观测序号输出的情况下是非常有用的。
proc sql;
select
MONOTONIC() as seq label = "序号",
name,
sex,
age,
height,
weight
from sashelp.class;
quit;
输出结果:
CALCULATED 关键字
CALCULATED 关键字用于引用当前 SELECT 子句中已经计算好的变量,使用 CALCULATED 可以减少不必要的计算过程,降低代码的冗余。
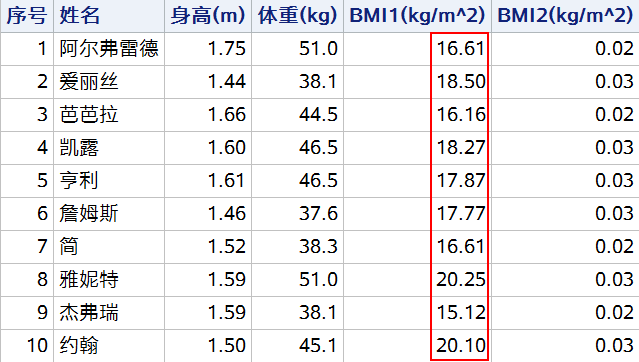
proc sql;
select
MONOTONIC() as seq label = "序号",
name,
height * 0.0254 as height label = "身高(m)" format = 8.2,
weight * 0.4536 as weight label = "体重(kg)" format = 8.1,
(CALCULATED weight / CALCULATED height**2) as BMI1 label = "BMI1(kg/m^2)" format = 8.2,
(weight / height**2) as BMI2 label = "BMI2(kg/m^2)" format = 8.2
from sashelp.class;
quit;
上述例子使用 CALCULATED 关键字引用了当前 SELECT 语句中经过单位转换的变量 height 和 weight,直接使用转换后的结果计算 BMI。若不使用 CALCULATED 关键字,则引用的仍然是未经过单位转换的变量。如下图所示,BMI1 是引用了经过单位转换的变量后的正确计算结果,BMI2 是引用了未经过单位转换的原始变量后的错误计算结果。