[PROC FREQ] 单组率置信区间的计算
本文链接:https://www.cnblogs.com/snoopy1866/p/15674999.html
利用PROC FREQ过程中的binomial语句可以很方便地计算单组率置信区间,SAS提供了9种(不包括校正法)计算单组率置信区间的方法,现列举如下:
首先准备示例数据:
data test;
input out $ weight;
cards;
阳性 95
阴性 5
;
run;
1. Wald 法
基于Wald法构建的单组率的置信区间应用非常广泛,且Wald在结构上有着以点估计为中心对称分布的天然优势,基于Wald法构建的单样本率置信区间可表示为:
优点:以点估计为中心,对称分布
缺点:(1)Overshoot: 置信区间可能超过[0,1]范围(2)Degeneracy: 区间宽度可能为0(p=0或1时)(3)覆盖率差
代码:
proc freq data = test;
tables out /nopercent nocol norow nocum binomial(level = "阳性" cl = wald);
weight weight;
run;

2. Wald 法(连续性校正)
优点:(1)可避免区间宽度可能为0的情况(2)覆盖率较Wald法有所改善
缺点:(1)结果偏保守(2)更容易发生置信区间超过[0,1]范围的情况
代码:
proc freq data = test;
tables out /nopercent nocol norow nocum binomial(level = "阳性" cl = wald(correct));
weight weight;
run;

3. Agresti-Coull
Agresti-Coull法的主要思路是选择一个大于0的常数作为pseudo-frequency,在计算样本量的时候对点估计进行校正,目的是使点估计尽量向中央(0.5)靠拢,这个大于零0的常数被称为估计因子ϕ。
Agresti和Coull提出了ϕ的两种形式,ϕ=12z2α/2和ϕ=2,前者称为ADDZ2校正法,后者称为ADD4校正法,SAS中仅提供ADDZ2校正法,当α=0.05时,zα/2接近2,此时ADDZ2校正法与ADD4校正法近似。
当ϕ=2时(ADD4校正法),其实际含义是样本成功例数和失败例数分别加2,即总样本量加4。
其中˜p=n1+12z2α/2n+z2α/2
优点:(1)downward spikes现象略有改善(downward spikes:当率在极端情况下,置信区间覆盖率急剧下滑)
缺点:(1)牺牲了置信区间宽度
代码:
proc freq data = test;
tables out /nopercent nocol norow nocum binomial(level = "阳性" cl = agresticoull);
weight weight;
run;

4. Wilson Score法
Wilson Score法作为Wald法的替代,应用十分广泛,是目前学界公认的在非极端率情况下的最佳置信区间构建方法。
基于Wilson Score法构建的置信区间可表示为:
p可表示为:
优点:(1)被认为是moderate proportion(率不接近0或1)的最佳方法
缺点:(1)存在downward spikes现象
代码:
proc freq data = test;
tables out /nopercent nocol norow nocum binomial(level = "阳性" cl = wilson);
weight weight;
run;
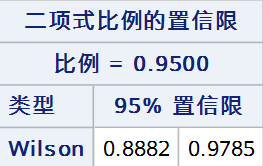
5. Wilson Score法(连续性校正)
基于Wilson Score法连续性校正构建的置信区间可表示为:
代码:
proc freq data = test;
tables out /nopercent nocol norow nocum binomial(level = "阳性" cl = wilson(correct));
weight weight;
run;
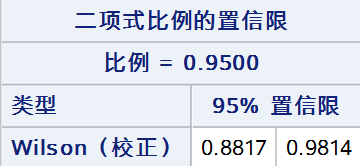
6. Jeffreys法
Jeffreys法构建的置信区间表示如下:
代码:
proc freq data = test;
tables out /nopercent nocol norow nocum binomial(level = "阳性" cl = jeffreys);
weight weight;
run;
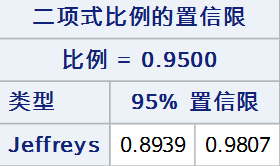
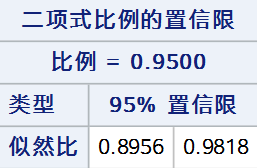
7. 似然比法
似然比法通过逆推似然比检验构造置信区间,零假设下似然比检验统计量可表示为:
使检验统计量L(p0)落在接受域内的所有p0组成的区间即为似然比法的置信区间:{p0:L(p0)<χ21,α},PROC FREQ通过迭代计算寻找置信限。
代码:
proc freq data = test;
tables out /nopercent nocol norow nocum binomial(level = "阳性" cl = likelihoodratio);
weight weight;
run;
8. Logit法
基于Logit变换 Y=ln(ˆp1−ˆp),Y 的近似置信区间用以下公式计算:
p 的置信区间可表示为:
代码:
proc freq data = test;
tables out /nopercent nocol norow nocum binomial(level = "阳性" cl = logit);
weight weight;
run;
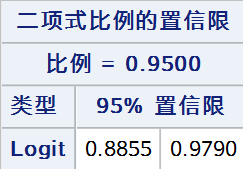
9. Clopper-Pearson法
基于二项分布构建的置信区间方法,使得精确置信限满足以下方程:
PROC FREQ 使用 F 分布计算Clopper-Pearson置信限,公式如下:
代码:
proc freq data = test;
tables out /nopercent nocol norow nocum binomial(level = "阳性" cl = clopperpearson);
weight weight;
run;

10. Mid-P法
Mid-P 精确置信限满足以下方程:
代码:
proc freq data = test;
tables out /nopercent nocol norow nocum binomial(level = "阳性" cl = midp);
weight weight;
run;

11. Blaker法
通过对双侧 Blaker 精确检验逆推来构建置信区间,使检验统计量B(p0,n1)落在接受域内的所有p0组成的区间称为Blaker置信区间:{p0:B(p0,n1)>α}
其中:
代码:
proc freq data = test;
tables out /nopercent nocol norow nocum binomial(level = "阳性" cl = blaker);
weight weight;
run;
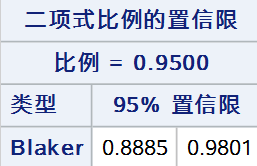
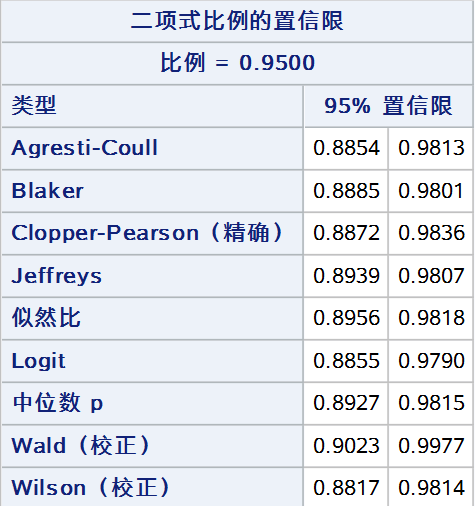
最后,将以上9种方法同时展示(wald 和 wilson 仅展示校正法):
proc freq data = test;
tables out /nopercent nocol norow
nocum binomial(level = "阳性"
cl = (wald(correct) agresticoull wilson(correct)
jeffreys likelihoodratio logit
clopperpearson midp blaker));
weight weight;
run;
参考文献:徐莹. 一种新的单样本率的置信区间估计方法[D].南方医科大学,2019.
本文作者:Snoopy1866
本文链接:https://www.cnblogs.com/snoopy1866/p/15674999.html
版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 2.5 中国大陆许可协议进行许可。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 探究高空视频全景AR技术的实现原理
· 理解Rust引用及其生命周期标识(上)
· DeepSeek 开源周回顾「GitHub 热点速览」
· 物流快递公司核心技术能力-地址解析分单基础技术分享
· .NET 10首个预览版发布:重大改进与新特性概览!
· AI与.NET技术实操系列(二):开始使用ML.NET
· 单线程的Redis速度为什么快?