kafka学习总结011 --- kafka为什么有如此高的吞吐量和性能
kafka号称能够达到每秒几十万级、甚至是百万级的并发量,而且我们也知道,kafka的数据是保存到磁盘的,那么kafka如何保证如此高的吞吐量(当然也和不同场景调优配置有关);
从两个角度来说:
数据写入角度(生产者角度)
写数据时采用了页面缓存技术和顺序写技术;
1、页面缓存技术

kafka将数据写入磁盘前,先写入操作系统缓存,然后由操作系统决定何时写入磁盘;写入操作系统缓存和数据写内存类似,因此大大提升写入效率;
2、顺序写技术
kafka将数据写入磁盘,采用追加写入方式,看过一篇文章,说追加写入的性能和写内存相差无几。。。
数据读取角度(消费者角度)
不考虑任何优化手段,consumer读取数据的流程如下:
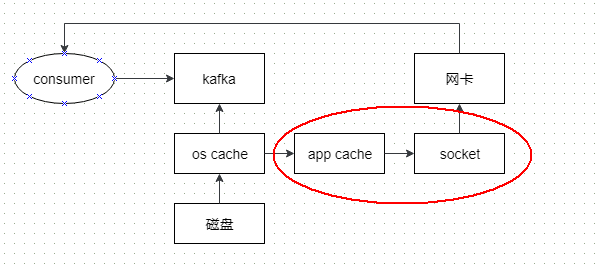
红框内有两次数据拷贝过程,并且是从操作系统层拷贝到应用层,这种操作涉及到多次应用上下文切换,性能耗费较大;
因此,kafka在读取数据的时候采用了“零拷贝技术”,流程如下:
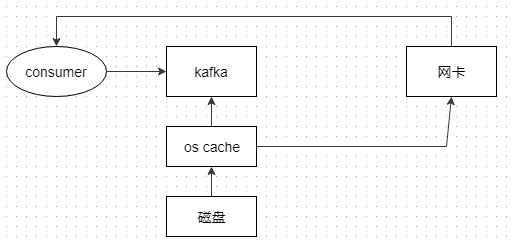
之所以能实现零拷贝,是由于出现了DMA技术,即允许外部设备支持直接从存储器读取数据,而网卡就是一种支持DMA的一种外设
心有猛虎,细嗅蔷薇

 浙公网安备 33010602011771号
浙公网安备 33010602011771号