
一、存入csv
上次爬取到了所需要的内容,但是没有存入到csv中,这次存入了csv文件中,代码如下:
import requests from bs4 import BeautifulSoup import csv import io import sys sys.stdout=io.TextIOWrapper(sys.stdout.buffer,encoding='gb18030') def get_url():#得到A-Z所有网站 urls=[] for i in range(1,27): i = chr(i+96) urls.append('http://www.thinkbabynames.com/start/0/%s'%i) return urls pass def get_text(url):#得到所有名字以及连接,爬取所需内容 headers = {'Cookie':"User-Agent:Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Mobile Safari/537.36"} docx=requests.get(url) soup=BeautifulSoup(docx.content,'html.parser') c_txt1=soup.find('section',{'id':'index'}).findAll('b') for x in c_txt1: s=[] if x.find('a'): name=x.find('a')['href'].split("/")[-1]#使用正则表达式获得所有名字 #url.append('http://www.thinkbabynames.com/meaning/0/%s'%i)#获得所有名字详情页链接 if name: r=requests.get('http://www.thinkbabynames.com/meaning/0/%s'%name) result=r.text bs=BeautifulSoup(result,'html.parser') li=bs.find('div',class_='content').find('h1') Enname=li.text[8::1]#使用切片语法获得详情页名字(s[x:y:z]x为起始,y为终止,z为步长) Gender=li.text[1:8:1]#使用切片语法获得详情页名字性别 li1=bs.find('section',id='meaning').find('p') Description=li1.text #保存名字,性别,简介到s中 s.append(Enname) s.append(Gender) s.append(Description) save_text(s) return s pass def save_text(s):#保存到csv中 with open('text.csv','a',encoding='utf_8_sig',newline='')as f: writer = csv.writer(f) writer.writerow(s) if __name__ == '__main__': urls=get_url(); for url in urls: get_text(url)
如上把得到的名字,性别,以及简介存入s中,再把s存到csv中。
二、csv文件截图

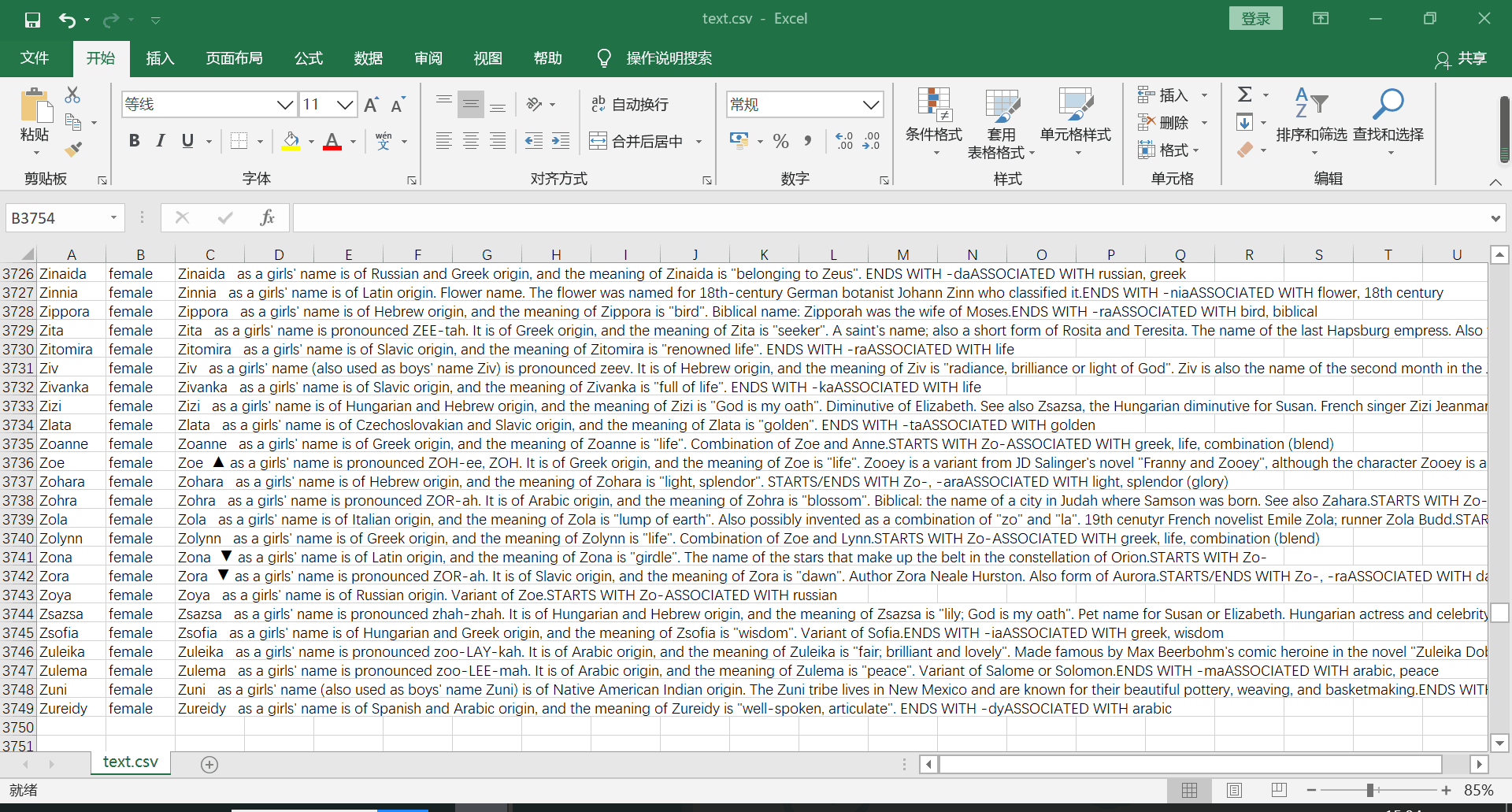
三、遇到的问题及解决方案
(1)爬取到所有名字时不能获得文本内容
解决方案:选择合适的正则表达式
docx=requests.get(url) soup=BeautifulSoup(docx.content,'html.parser') c_txt1=soup.find('section',{'id':'index'}).findAll('b') for x in c_txt1: s=[] if x.find('a'): name=x.find('a')['href'].split("/")[-1]#使用正则表达式获得所有名字
(2)获取名字详情页内容时,名字和性别在一起。
解决方案:使用切片语法分别获得名字和姓名分开存取
li=bs.find('div',class_='content').find('h1') Enname=li.text[8::1]#使用切片语法获得详情页名字(s[x:y:z]x为起始,y为终止,z为步长) Gender=li.text[1:8:1]#使用切片语法获得详情页名字性别
(3)在笔记本上运行时,访问量大
解决方案:分开来爬

如上图,改变range()函数中的数字来选择爬取部分网站以减少访问量。
这样既能够满足爬取要求,也不会被网站禁止爬取。
 posted on
posted on

 浙公网安备 33010602011771号
浙公网安备 33010602011771号