
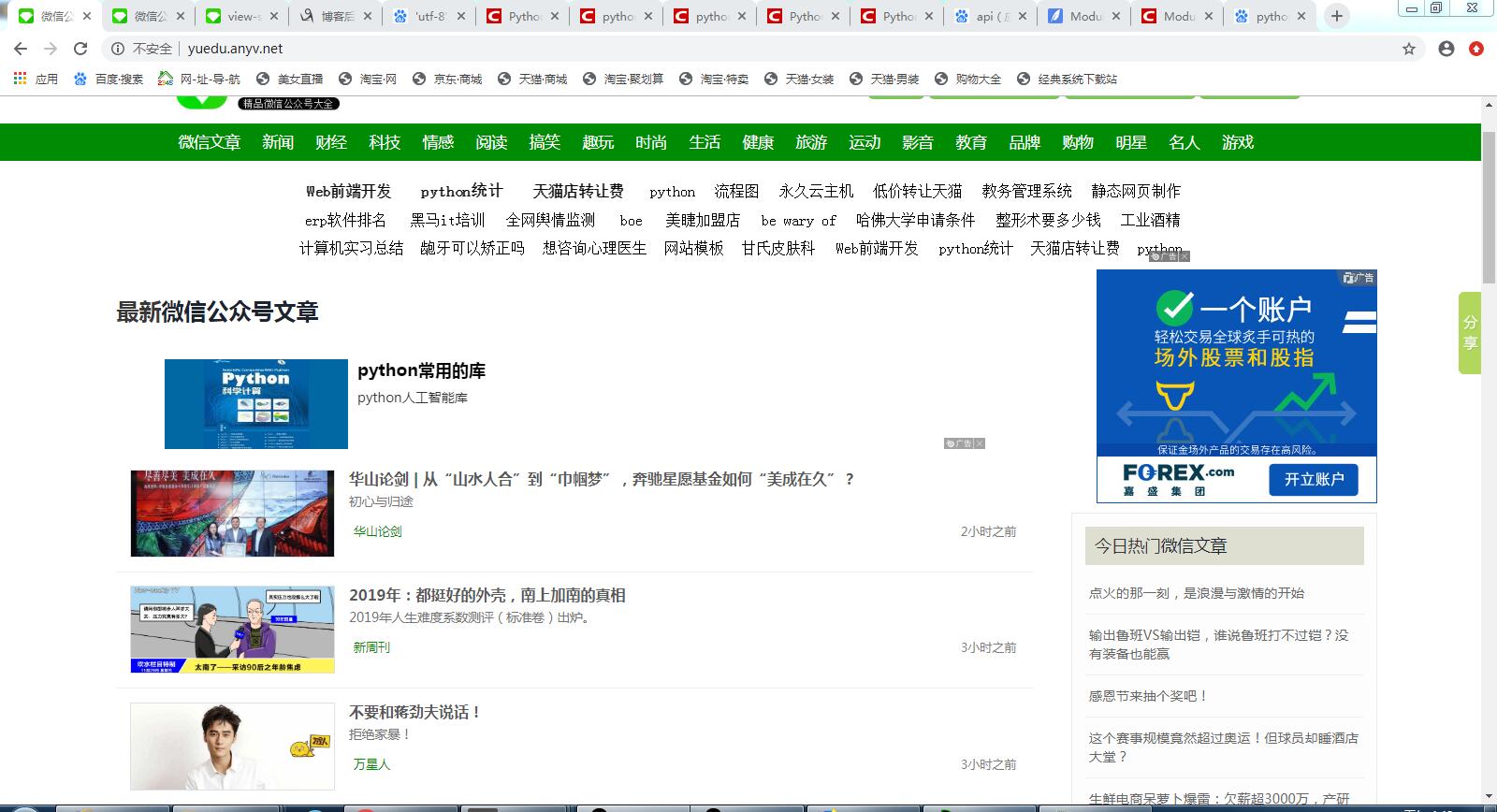
练习要求爬取http://yuedu.anyv.net/网址的最大页码数和文章标题和链接
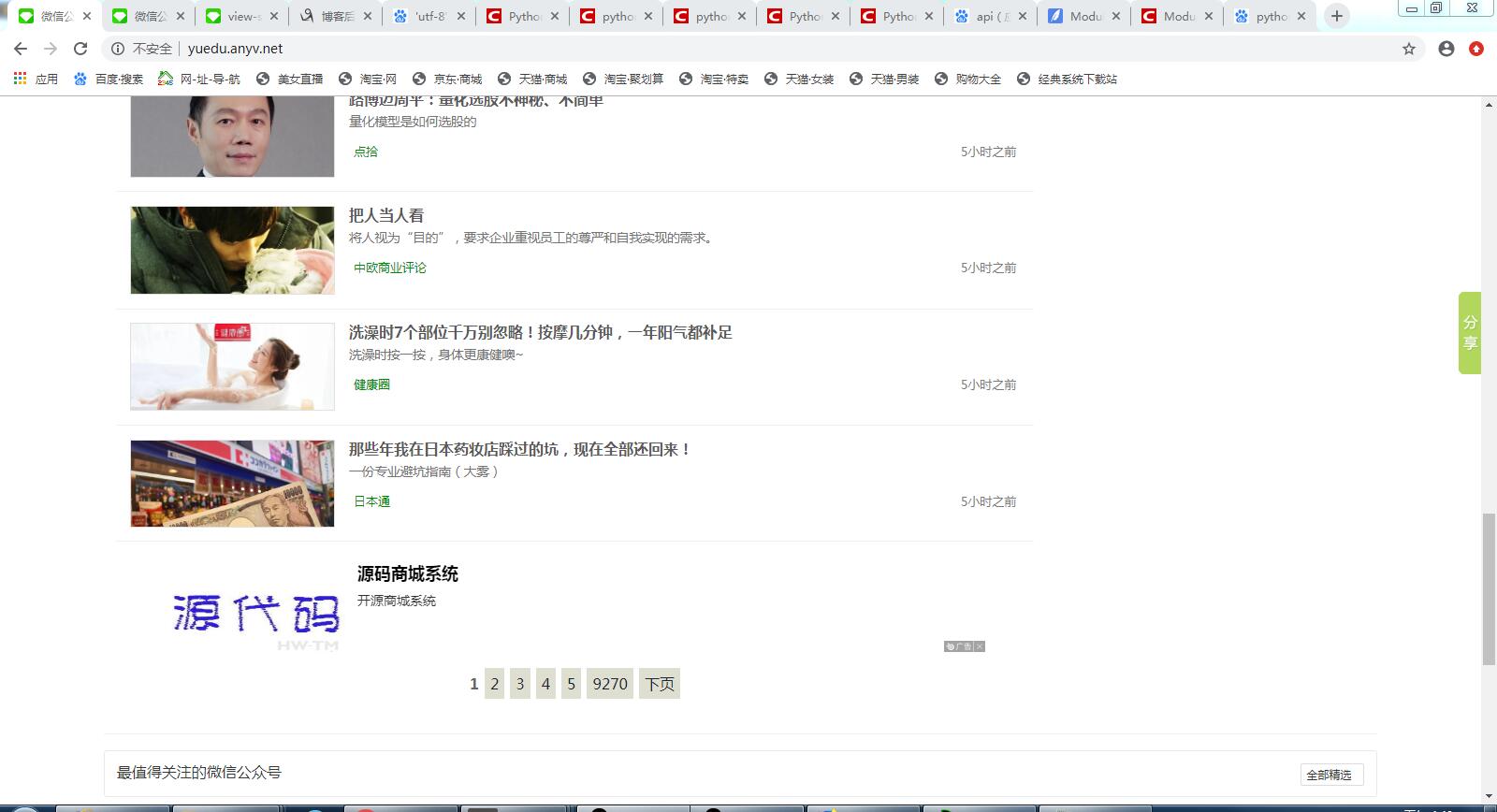
网址页面截图:
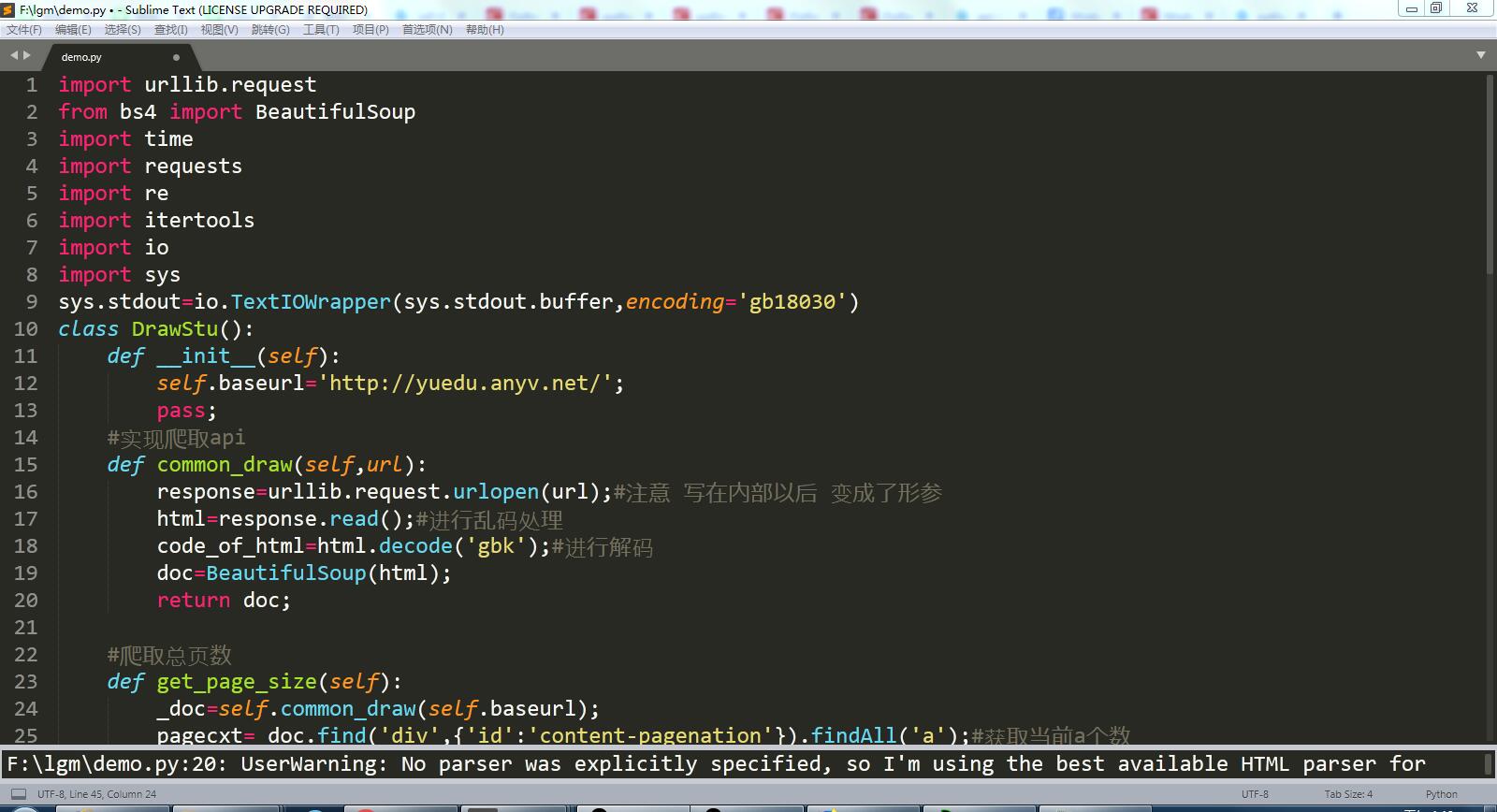
代码截图:

完整代码:
根据网页显示页码的方式,爬取的所有页码中倒数第二个页码是最大页码。
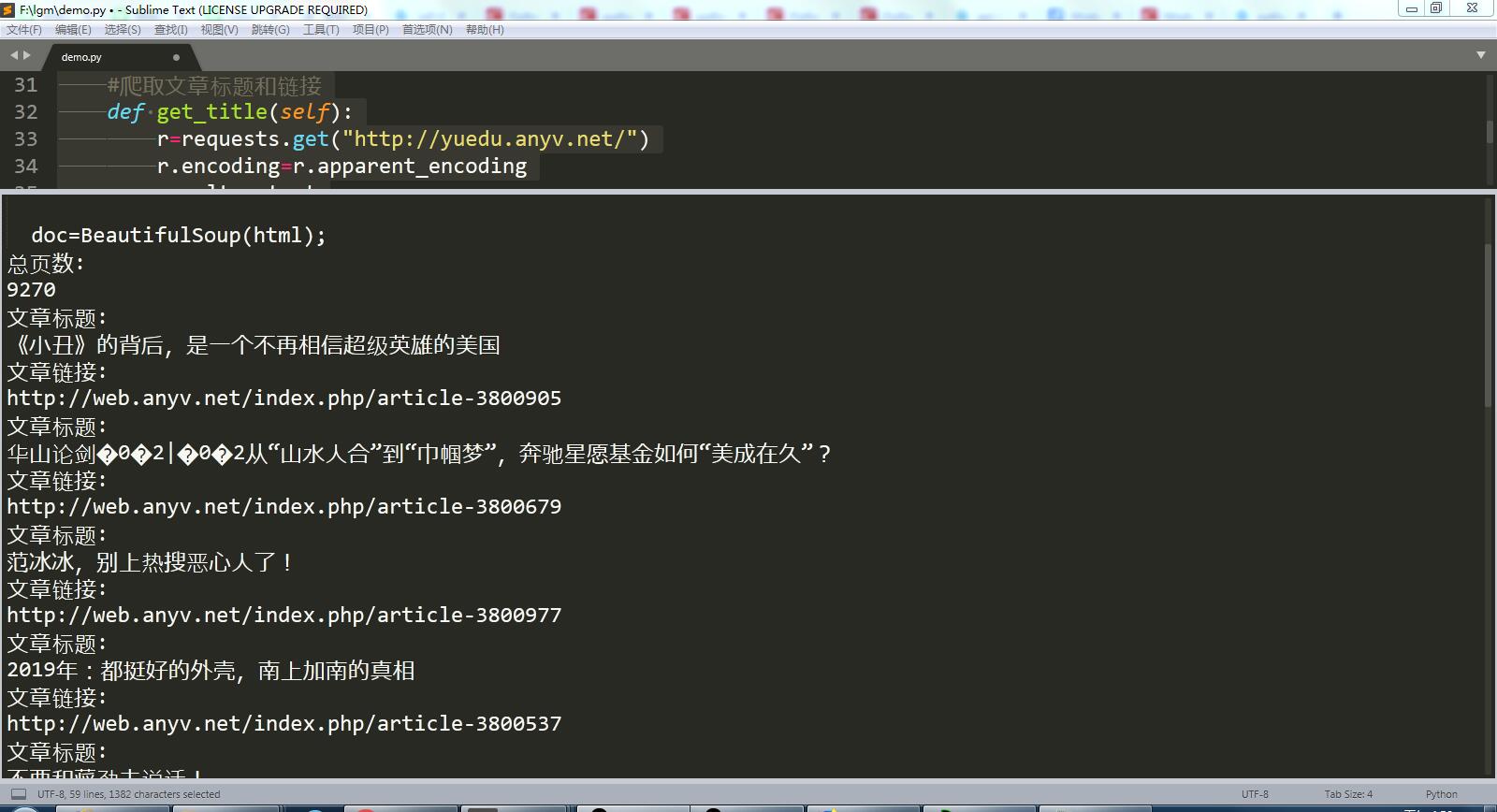
import urllib.request from bs4 import BeautifulSoup import time import requests import re import itertools import io import sys sys.stdout=io.TextIOWrapper(sys.stdout.buffer,encoding='gb18030') class DrawStu(): def __init__(self): self.baseurl='http://yuedu.anyv.net/'; pass; #实现爬取api def common_draw(self,url): response=urllib.request.urlopen(url);#注意 写在内部以后 变成了形参 html=response.read();#进行乱码处理 code_of_html=html.decode('gbk');#进行解码 doc=BeautifulSoup(html); return doc; #爬取总页数 def get_page_size(self): _doc=self.common_draw(self.baseurl); pagecxt=_doc.find('div',{'id':'content-pagenation'}).findAll('a');#获取当前a个数 size=len(pagecxt); maxsize=pagecxt[size-2].text;#获取倒数第二个进行获取里面值就是最大值 maxsize=int(maxsize) return maxsize; #爬取文章标题和链接 def get_title(self): r=requests.get("http://yuedu.anyv.net/") r.encoding=r.apparent_encoding result=r.text bs=BeautifulSoup(result,'html.parser') pagecxt=bs.find('div',{'class':'content'}).findAll('div',{'class':'image group'}); for x in pagecxt: pageinfo=x.find('div',{'class':'grid news_desc'}); title=pageinfo.find('h3').find('a').text; print("文章标题:") print(title) link=pageinfo.find('h3').find('a').get('href'); print("文章链接:") print(link) D=DrawStu(); if __name__ == '__main__': size=D.get_page_size(); print("总页数:") print(size) title=D.get_title(); print(title)
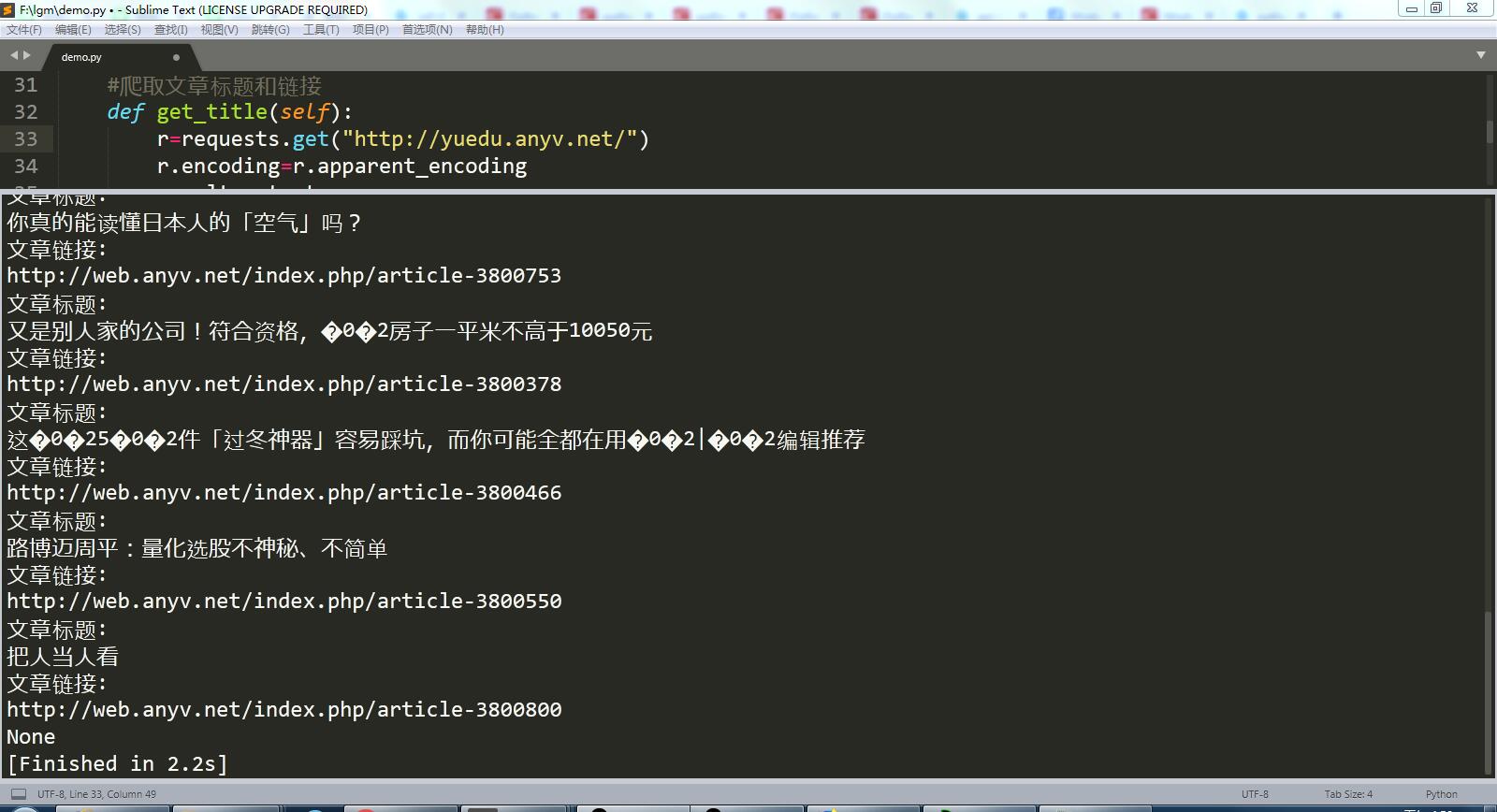
运行结果截图:
 posted on
posted on

 浙公网安备 33010602011771号
浙公网安备 33010602011771号