

分布式事务中间件--Seata
Seata简介
Seata 是一款开源的分布式事务解决方案,致力于在微服务架构下提供高性能和简单易用的分布式事务服务.
经过多年沉淀与积累,商业化产品先后在阿里云、金融云进行售卖。2019.1 为了打造更加完善的技术生态和普惠技术成果,Seata 正式宣布对外开源,未来 Seata 将以社区共建的形式帮助其技术更加可靠与完备。
Seata 将为用户提供了 AT、TCC、SAGA 和 XA 事务模式,为用户打造一站式的分布式解决方案。
Seata AT模式
Seata AT模式实际上是2PC协议的一种演变方式,也是通过两个阶段的提交或者回滚来保证多节点事务的一致性,它的工作模型如下图所示。

Seata AT模式原理
我们来通过一个简单的示例来说明Seata中AT模式的工作原理。
假设存在一个业务表Product,表结构如下:
| Field | Type | Key |
| id | bigint(20) | |
| name | varchar(100) | |
| since | varchar(100) |
这个表中,有一条对应的数据:
| id | name | since |
|---|---|---|
| 1 | TXC | 2014 |
假设AT模式下的其中一个分支事务的执行业务逻辑对应的sql语句如下:
update product set name = 'GTS' where name = 'TXC';
在Seata的AT模式中,执行的过程如下:
AT模式第一阶段
这个阶段应用系统会把一个业务数据的事务操作和回滚日志记录在同一个本地事务中提交,在提交之前,会向TC(seata server)注册事务分支,并申请针对本次事务操作的表的全局锁。
接着提交本地事务,本地事务会提交业务数据的事务操作以及UNDO LOG,放在一个事务中提交。
具体过程如下:
-
解析前面的Update语句,得到SQL类型(UPDATE)、表(Product)、条件(where name ='TXC')等相关信息。
-
根据解析到的条件信息,生成一条查询语句用来查询修改之前的数据状态
select id , name , since from product where name = 'TXC' -
执行上述的业务SQL,也就是更新name为GTC。
-
在根据第二个步骤查询的主键id定位修改后的数据
select id, name, since from product where id = 1; -
有了更新前后的数据,以及业务SQL有关信息,组成一条回滚日志记录,插入到UNDO_LOG表中。
{ "branchId": 641789253, "undoItems": [{ "afterImage": { "rows": [{ "fields": [{ "name": "id", "type": 4, "value": 1 }, { "name": "name", "type": 12, "value": "GTS" }, { "name": "since", "type": 12, "value": "2014" }] }], "tableName": "product" }, "beforeImage": { "rows": [{ "fields": [{ "name": "id", "type": 4, "value": 1 }, { "name": "name", "type": 12, "value": "TXC" }, { "name": "since", "type": 12, "value": "2014" }] }], "tableName": "product" }, "sqlType": "UPDATE" }], "xid": "xid:xxx" } -
UNDO日志提交之前,会向TC(SEATA-SERVER)注册分支事务,并申请product表中,主键值为1记录的全局锁。
-
业务数据的更新语句(UPDATE)和UNDO LOG一起提交,并将本地事务的提交结果上报到TC。
AT模式第二阶段
这一个阶段会根据参与到同一个XID下所有事务分支在第一个阶段的执行结果来决定事务的提交或者回滚,这个回滚或者提交是TC来决定的,它会告诉当前XID下的所有事务分支,提交或者回滚。
-
如果所有分支事务的执行结果都正常,则提交事务。由于实际上各个本地事务在第一阶段已经提交了,所以只需要异步去删除当前事务分支对应UNDO LOG表中的记录即可。
-
如果存在部分事务分支执行异常的情况,则需要对事务进行回滚,回滚步骤如下
-
收到TC的分支回滚请求,事务参与者开启一个本地事务
-
通过XID和BranchID查找到UNDO LOG中对应的记录
-
拿到数据后,先对数据进行校验,使用UNDO LOG中afterImages(修改后的数据)和当前product表中的数据进行比较,如果发现数据不相同,说明数据被当前全局事务之外的程序修改过,这种情况需要根据配置的策略来进行处理
-
根据UNDO LOG中的beforeImages(修改之前的数据)和业务SQL相关信息生成回滚语句并执行。
update product set name = 'TXC' where id = 1;
-
-
提交本地事务,并把本地事务的执行结果(分支事务的回滚结果)上报给TC。
以上就是Seata AT事务模型的执行流程,其实从整体的实现思路上,类似于把数据库的事务在作用范围内做了一层升华,核心步骤和SQL类似:
-
加锁
-
写事务日志
-
提交事务或回滚事务
在这种事务模型下,它的事务隔离级别是如何实现的呢?
Seata AT模式的事务隔离级别
我们在学习数据库的事务特性时,必须会涉及到的就是事务的隔离级别,不同的隔离级别,会产生一些并发性的问题,比如
-
脏读
-
不可重复读
-
幻读
写隔离
所谓的写隔离,就是多个事务对同一个表的同一条数据做修改的时候,需要保证对于这个数据更新操作的隔离性,在传统事务模型中,我们一般是采用锁的方式来实现。
那么在分布式事务中,如果存在多个全局事务对于同一个数据进行修改,为了保证写操作的隔离,也需要通过一种方式来实现隔离性,自然也是用到锁的方法,具体来说。
-
在第一阶段本地事务提交之前,需要确保先拿到全局锁,如果拿不到全局锁,则不能提交本地事务
-
拿到全局锁的尝试会被限制在一定范围内,超出范围会被放弃并回滚本地事务并释放本地锁。
举一个具体的例子,假设有两个全局事务tx1和tx2,分别对a表的m字段进行数据更新操作,m的初始值是1000。
-
tx1先开始执行,按照AT模式的流程,先开启本地事务,然后更新m=1000-100=900。在本地事务更新之前,需要拿到这个记录的全局锁。
-
如果tx1拿到了全局锁,则提交本地事务并释放本地锁。
-
接着tx2后开始执行,同样先开启本地事务拿到本地锁,并执行m=900-100的更新操作。 在本地事务提交之前,先尝试去获取这个记录的全局锁。而此时tx1全局事务还没提交之前,全局锁的持有者是tx1,所以tx2拿不到全局锁,需要等待

接着, tx1在第二阶段完成事务提交或者回滚,并释放全局锁。此时tx2就可以拿到全局锁来提交本地事务。当然这里需要注意的是,如果tx1的第二阶段是全局回滚,则tx1需要重新获取这个数据的本地锁,然后进行反向补偿更新实现事务分支的回滚。
此时,如果tx2仍然在等待这个数据的全局锁并且同时持有本地锁,那么tx1的分支事务回滚会失败,分支的回滚会一直重试直到tx2的全局锁等待超时,放弃全局锁并回滚本地事务并释放本地锁之后,tx1的分支事务才能最终回滚成功.
由于在整个过程中, 全局锁在tx1结束之前一直被tx1持有,所以并不会发生脏写问题。

读隔离
在数据库本地事务隔离级别读已提交(Read Committed)或以上的基础上,Seata(AT模式)的默认全局隔离级别是 读未提交(Read Uncommitted) 。其实从前面的流程中就可以很显而易见的分析出来,因为本地事务提交之后,这个数据就对外可见,并不用等到tc触发全局事务的提交。
如果在特定场景下,必须要求全局的读已提交,目前Seata的方式只能通过SELECT FOR UPDATE语句来实现。
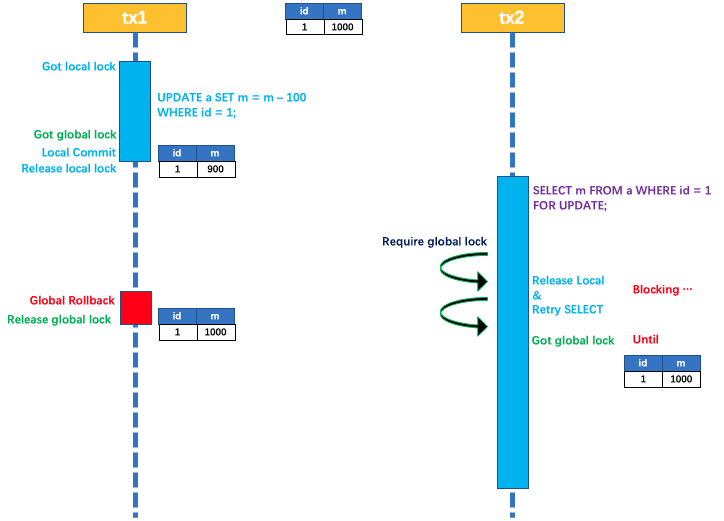
SELECT FOR UPDATE 语句的执行会申请 全局锁 ,如果 全局锁 被其他事务持有,则释放本地锁(回滚 SELECT FOR UPDATE 语句的本地执行)并重试。这个过程中,查询是被block 住的,直到 全局锁 拿到,即读取的相关数据是 已提交 的,才返回。
出于总体性能上的考虑,Seata 目前的方案并没有对所有 SELECT 语句都进行代理,仅针对FOR UPDATE 的 SELECT 语句。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· DeepSeek 开源周回顾「GitHub 热点速览」
· 物流快递公司核心技术能力-地址解析分单基础技术分享
· .NET 10首个预览版发布:重大改进与新特性概览!
· AI与.NET技术实操系列(二):开始使用ML.NET
· 单线程的Redis速度为什么快?