

Java限流及常用解决方案
前言
随着微服务的流行,服务和服务之间的依赖越来越强,调用关系越来越复杂,服务和服务之间的稳定性越来越重要。在遇到突发的请求量激增,恶意的用户访问,亦或请求频率过高给下游服务带来较大压力时,我们常常需要通过缓存、限流、熔断降级、负载均衡等多种方式保证服务的稳定性。
为什么要限流
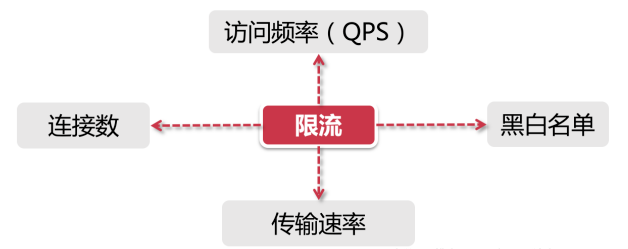
限流顾名思义,就是对请求或并发数进行限制;通过对一个时间窗口内的请求量进行限制来保障系统的正常运行。如果我们的服务资源有限、处理能力有限,就需要对调用我们服务的上游请求进行限制,以防止自身服务由于资源耗尽而停止服务。
限流就是限制系统的输入和输出流量已达到保护系统的目的。
在限流中有两个概念需要了解:
-
阈值(访问资源的限制):在一个单位时间内允许的请求量。如 QPS 限制为10,说明 1 秒内最多接受 10 次请求。
-
拒绝策略(限流规则):超过阈值的请求的拒绝策略,常见的拒绝策略有直接拒绝、排队等待等。
如何实现限流
限流就是在某个时间窗口对资源访问做限制,比如设定每秒最多100个访问请求。但在真正的场景里,我们不止设置一种限流规则,而是会设置多个限流规则共同作用,主要的几种限流规则如下:
- QPS和连接数控制
- 可设定IP维度的限流,也可以设置基于单个服务器的限流
- 传输速率
- 资源的下载速度
- 黑白名单
- 分布式环境
- 网关层限流
常见的限流算法
-
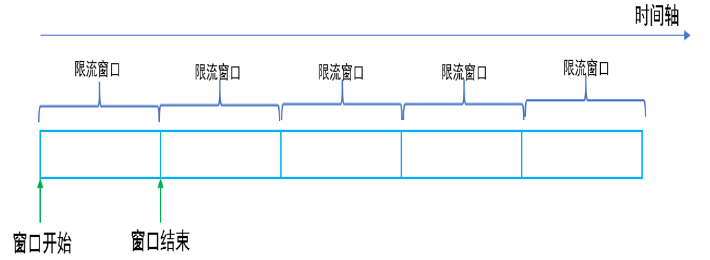
固定窗口计数法(Semaphore )
-
将时间划分为固定的窗口大小,例如1s
-
在窗口时间段内,每来一个请求,对计数器加1
-
当计数器达到设定限制后,该窗口时间内的之后的请求都被丢弃处理。
-
该窗口时间结束后,计数器清零,从新开始计数。如上图所示,10s内限制1000个请求,在第11s的时候计数器会从0重新开始计数。
优点:实现简单,并且内存占用小,我们只需要存储时间窗口中的计数即可;
缺点:流量曲线可能不够平滑,有“突刺现象”(2N)
突刺现象的具体表现:
-
一段时间内(不超过时间窗口)系统服务不可用。
例如:窗口大小为1s,限流大小为100,然后恰好在某个窗口的第1ms来了100个请求,然后第2ms-999ms的请求就都会被拒绝,这段时间用户会感觉系统服务不可用。 -
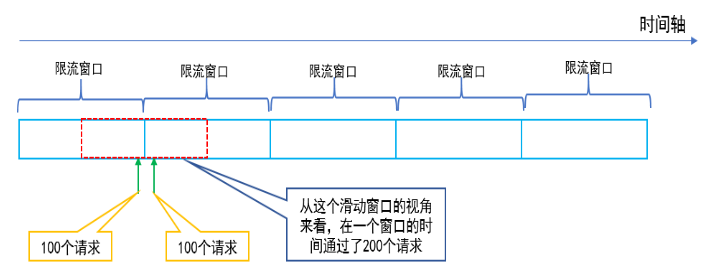
瞬时流量的临界问题:窗口切换时可能会产生两倍于阈值流量的请求
例如:窗口大小为1s,限流大小为100,然后恰好在某个窗口的第999ms来了100个请求,窗口前期没有请求,所以这100个请求都会通过。再恰好,下一个窗口的第1ms有来了100个请求,也全部通过了,那也就是在2ms之内通过了200个请求,而我们设定的阈值是100,通过的请求达到了阈值的两倍。
-
-
滑动窗口(Hystrix)
固定窗口计数器算法 由于其存在的临界问题(尖峰问题),可能在时间窗口的重置节点处接收大量流量,从而造成服务崩溃,为解决这个问题,我们引入了 滑动窗口计数法。
TCP协议中数据包的传输,同样也是采用滑动窗口来进行流量控制。
算法原理
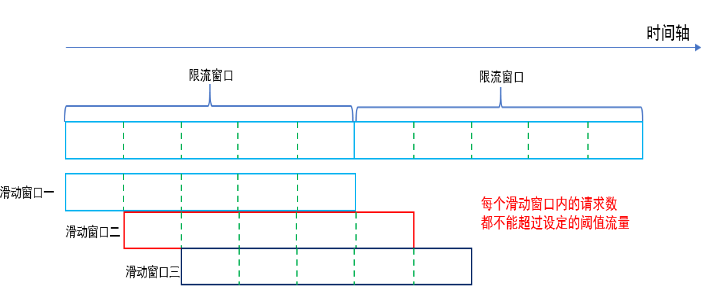
滑动窗口算法在固定窗口的基础上,将一个计时窗口分成了若干个小窗口,然后每个小窗口维护一个独立的计数器。当请求的时间大于当前窗口的最大时间时,则将计时窗口向前平移一个小窗口。
平移时,将第一个小窗口的数据丢弃,然后将第二个小窗口设置为第一个小窗口,同时在最后面新增一个小窗口,将新的请求放在新增的小窗口中。
同时要保证整个窗口中所有小窗口的请求数目之后不能超过设定的阈值。
在线演示地址:https://www2.tkn.tu-berlin.de/teaching/rn/animations/gbn_sr/
很明显,当滑动窗口的格子划分的越多,那么滑动窗口的滚动就越平滑,限流的统计就会越精确。
总结滑动窗口计数法的思路是:
将时间划分为细粒度的区间,每个区间维持一个计数器,每进入一个请求则将计数器加一。
多个区间组成一个时间窗口,每流逝一个区间时间后,则抛弃最老的一个区间,纳入新区间。
若当前窗口的区间计数器总和超过设定的限制数量,则本窗口内的后续请求都被丢弃。优点:能够完美的解决 固定窗口的“突刺现象” 现象
缺点:
- 不能解决请求分布不均的问题,即无法平滑流量
- 实现更复杂,需要维护时间窗口,占用内存更多,计算时间复杂度也相应变大。
- 从严格意义上来讲 滑动窗口算法 相当于是记录访问日志,如果设置 超长时间窗口 和 超大量阈值 则会占用大量的内存或存储空间,进而在计算时会导致计算市场增加。例如在 30分钟 内允许 800万次 的访问,这样就必须至少保存 30分钟 的访问数据,保留的记录数可能会达到 800万条 以上,这样每次计算的时间可能会非常长。
-
漏桶
- 漏桶算法的后半程是有鲜明特色的,它永远只会以一个恒定的速率将数据包从桶内流出。打个比方,如果我设置了漏桶可以存放100个数据包,然后流出速度是1s一个,那么不管数据包以什么速率流入桶里,也不管桶里有多少数据包,漏桶能保证这些数据包永远以1s一个的恒定速度被处理。 如图:
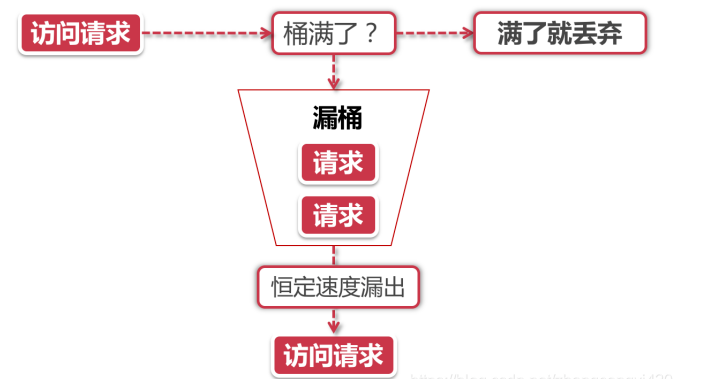
-
令牌桶
-
Token Bucket令牌桶算法是目前应用最为广泛的限流算法,顾名思义,它有以下两个关键角色:
令牌 获取到令牌的Request才会被处理,其他Requests要么排队要么被直接丢弃
桶 用来装令牌的地方,所有Request都从这个桶里面获取令牌
用图简单描述如下:
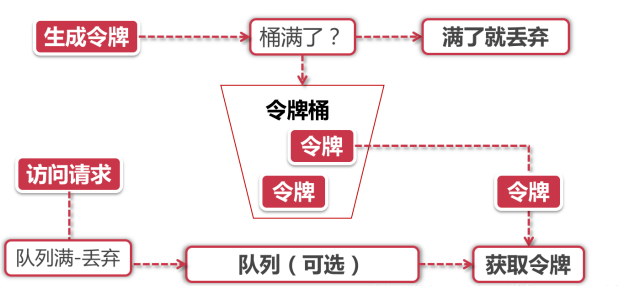
假如令牌的数量少,而访问请求较多的情况下,一部分请求自然无法获取到令牌,那么这个时候我们可以设置一个“缓冲队列”来暂存这些多余的令牌,
如果队列也也满了的情况下,这部分访问请求将被丢弃。在实际应用中我们还可以给这个队列加一系列的特效,比如设置队列中请求的存活时间,或者将队列改造为PriorityQueue,根据某种优先级排序,而不是先进先出。
-
漏桶 vs 令牌桶
这两种算法都有一个“恒定”的速率和“不定”的速率,令牌桶是以恒定速率创建令牌,但是访问请求获取令牌的速率“不定”,反正有多少令牌发多少,令牌没了就干等。而漏桶是以“恒定”的速率处理请求,但是这些请求流入桶的速率是“不定”的。
从这两个特点来说,漏桶的天然特性决定了它不会发生突发流量,就算每秒1000个请求到来,那么它对后台服务输出的访问速率永远恒定。而令牌桶则不同,其特性可以“预存”一定量的令牌,因此在应对突发流量的时候可以在短时间消耗所有令牌,其突发流量处理效率会比漏桶高,但是导向后台系统的压力也会相应增多。
具体的实现限流的方式
1)Tomcat 使用 maxThreads 来实现限流。
2)Nginx 的 limit_req_zone 和 burst 来实现速率限流。
3)Nginx 的 limit_conn_zone 和 limit_conn 两个指令控制并发连接的总数。
4)时间窗口算法借助 Redis 的有序集合可以实现。
5)漏桶算法可以使用 Redis-Cell 来实现。
6)令牌算法可以解决Google的guava包来实现。
限流按照规模来分类:
1)单节点限流:限流的方案仅适用于单节点规模,在大规模集群下不适用
2)分布式系统限流:适用于大规模集群限流,当然单节点也支持,例如:redis、zookeeper、Sentinel
需要注意的是借助Redis实现的限流方案可用于分布式系统,而guava实现的限流只能应用于单机环境。
参考资料:
https://blog.csdn.net/budongfengqing/article/details/124437962
https://blog.csdn.net/u013735734/article/details/123494680
https://blog.csdn.net/sshduanzhijun/article/details/115019205
