
Redis客户端和数据的一致性
官方链接
官网推荐的Java客户端有3个:Jedis, Redisson和Luttuce。
| 配置 | 作用 |
|---|---|
| Jedis | A blazingly small and sane redis java client (体系非常小,但是功能很完善) |
| lettuce | Advanced Redis client for thread-safe sync, async, and reactive usage. Supports Cluster, Sentinel, Pipelining, and codecs.(高级客户端,支持线程安全、异步、反应式编程、支持集群、哨兵、 pipeline、编解码) |
| Redisson | distributed and scalable Java data structures on top of Redis server (基于 Redis 服务实现的 Java 分布式可扩展的数据结构) |
Spring 操作 Redis 提供了一个模板方法,RedisTemplate。 这个是不是Spring官方开发的一个客户端呢?实际上并没有。
Spring定义了定义了一个连接工厂接口: RedisConnectionFactory。这个接口有很多实现, 例如:JedisConnectionFactory、 JredisConnectionFactory、LettuceConnectionFactory. SrpConnectionFactory。
也就是说,RedisTemplate对其他现成的客户端再进行了一层封装而已。
在Spring Boot 2.x版本之前,RedisTemplate默认使用Jedis。2.x版本之后,默认使用Lettuce。
数据一致性
缓存使用场景
针对读多写少的高并发场景,我们可以使用缓存来提升查询速度。
当我们使用Redis作为缓存的时候,一般流程是这样的:
1、如果数据在Redis存在,应用就可以直接从Redis拿到数据,不用访问数据库。
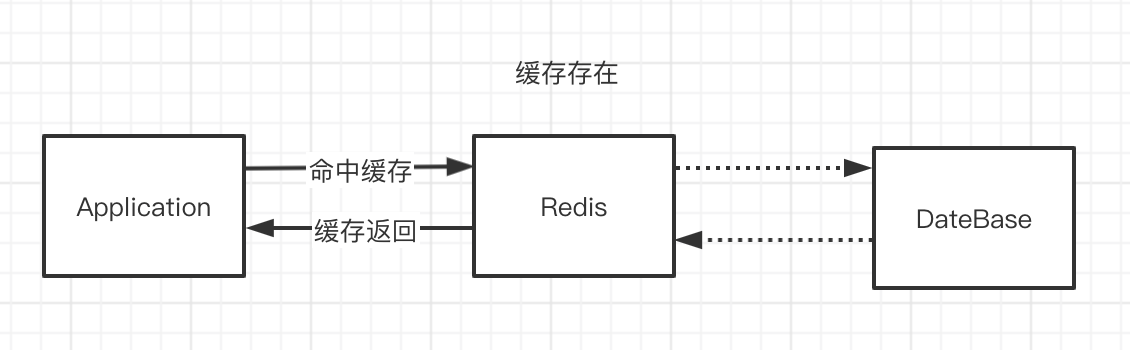
2、应用新增了数据,只保存在数据库中,这个时候Redis没有这条数据。 如果Redis里面没有,先到数据库查询,然后写入到Redis,再返回给应用。
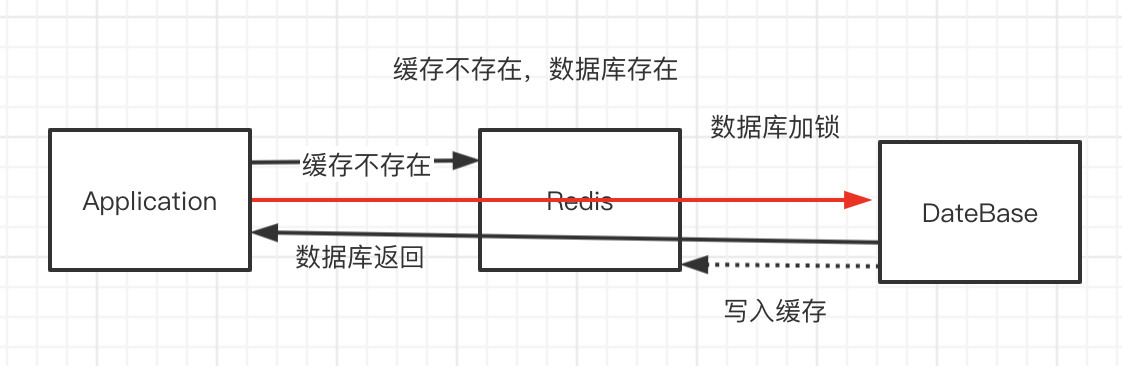
一致性问题的定义
因为数据最终是以数据库为准的(这是我们的原则),如果Redis没有数据,就不 存在这个问题。当Redis和数据库都有同一条记录,而这条记录发生变化的时候,就可 能岀现一致性的问题。
—旦被缓存的数据发生变化(比如修改、删除)的时候,我们既要操作数据库的数据,也要操作Redis的数据,才能让Redis和数据库保持一致。所以问题来了。现在我 们有两种选择:
1、先操作Redis的数据再操作数据库的数据
2、先操作数据库的数据再操作Redis的数据
到底选哪一种?
首先需要明确的是,不管选择哪一种方案,我们肯定是希望两个操作要么都成功, 要么都一个都不成功。但是,Redis的数据和数据库的数据是不可能通过事务达到统一的, 我们只能根据相应的场景和所需要付出的代价来采取一些措施降低数据不一致的问题出现的概率,在数据一致性和性能之间取得一个权衡。
比如,对于数据库的实时性一致性要求不是特别高的场合,比如T+1的报表,可以采用定时任务查询数据库数据同步到Redis的方案。
由于我们是以数据库的数据为准的,所以给缓存设置一个过期时间,删除Redis的数据,也能保证最终一致性。
我们既然提到了 Redis和数据库一致性的问题,一般是希望尽可能靠近实时一致性, 操作延迟带来的不一致的时间越少越好。
方案选择
Redis删除还是更新?
这里我们先要补充一点,当存储的数据发生变化,Redis的数据也要更新的时候,我们有两种方案,一种就是直接更新Redis数据,调用set;还有一种是直接删除Redis数据,让应用在下次查询的时候重新写入。
这两种方案怎么选择呢?这里我们主要考虑更新缓存的代价。
更新缓存之前,是不是要经过其他表的查询、接口调用、计算才能得到最新的数据, 而不是直接从数据库拿到的值。如果是的话,建议直接删除缓存,这种方案更加简单, 而且避免了数据库的数据和缓存不一致的情况。在一般情况下,我们也推荐使用删除的方案。
所以,更新操作和删除操作,只要数据变化,都用删除。
这一点明确之后,现在我们就剩一个问题:
1、到底是先更新数据库,再删除缓存
2、还是先删除缓存,再更新数据库
我们先看第一种方案。
先更新数据库,再删除缓存
正常情况:
更新数据库,成功。
删除缓存,成功。
异常情况:
1、更新数据库失败,程序捕获异常,不会走到下一步,所以数据不会出现不一致。
2、更新数据库成功,删除缓存失败。数据库是新数据,缓存是旧数据,发生了不一致的情况。
这种问题怎么解决呢?我们可以提供一个重试的机制。
比如:如果删除缓存失败,我们捕获这个异常,把需要删除的key发送到消息队列。 然后自己创建一个消费者消费,尝试再次删除这个key。这种方式有个缺点,会对业务代码造成入侵。
所以我们又有了第二种方案(异步更新缓存):
因为更新数据库时会往binlog写入日志,所以我们可以通过一个服务来监听binlog 的变化(比如阿里的canal),然后在客户端完成删除key的操作。如果删除失败的话, 再发送到消息队列。
总之,对于后删除缓存失败的情况,我们的做法是不断地重试删除,直到成功。 无论是重试还是异步删除,都是最终一致性的思想。
先删除缓存,再更新数据库
正常情况:
删除缓存,成功。
更新数据库,成功。
异常情况:
1、删除缓存,程序捕获异常,不会走到下一步,所以数据不会出现不一致。
2、删除缓存成功,更新数据库失败。因为以数据库的数据为准,所以不存在数据 不一致的情况。
看起来好像没问题,但是如果有程序并发操作的情况下:
1)线程A需要更新数据,首先删除了 Redis缓存
2)线程B查询数据,发现缓存不存在,到数据库查询旧值,写入Redis,返回
3)线程A更新了数据库
这个时候,Redis是旧的值,数据库是新的值,发生了数据不一致的情况。
这个是由于线程并发造成的问题。能不能让对同一条数据的访问串行化呢?
代码肯定保证不了,因为有多个线程,即使做了任务队列也可能有多个应用实例(应用做了集群部署)。
数据库也保证不了,因为会有多个数据库的连接。只有一个数据库只提供一个连接的情况下,才能保证读写的操作是串行的,或者我们把所有的读写请求放到同一个内存队列当中,但是强制串行操作,吞吐量太低了。
怎么办呢?删一次不放心,隔一段时间再删一次。
所以我们有一种延时双删的策略,在写入数据之后,再删除一次缓存。
A线程:
1)删除缓存
2)更新数据库
3)休眠500ms (这个时间,依据读取数据的耗时而定)
4)再次删除缓存

