《Web安全深度剖析》读书笔记——基础篇(1)
Web安全简介
服务器是如何被入侵的
攻击者若想要对计算机进行渗透,有一个条件是必需的,就是攻击者的计算机与服务器必须能够进行正常通信。服务器通过不同的端口提供各种服务供给客户端使用,攻击者的入侵也是依赖于端口,或者说是计算机提供的服务。
Web现在如此强大的原因离不开一下四个因素:数据库、编程语言、Web容器和优秀的Web应用程序设计者。优秀的设计人员设计出个性化的应用程序,编程语言将这些设计变成真实的存在,并且通过代码实现与数据库的连接,让数据库将用用程序中的数据存储下来,而Web容器作为终端解析用户请求以及脚本语言。当用户通过统一资源定位符(就是我们常说的URL)访问web应用程序时,最终看到的内容就是经过Web容器处理的HTML文档。
Web服务默认运行在服务器的80端口上,这也是服务器所提供的服务之一。Web攻击的方式非常多,同时Web也是脆弱的,导致这一问题的原因有很多方面。首先是开发人员,很多开发人员没有安全意识,总认为黑客的存在很神秘,自己根本接触不到;其次,开发者并不知道哪里的代码存在BUG,这是的BUG并不是代码的某些功能不完善,而是代码层面出现了漏洞。另外,当项目上线之后的服务器环境可能会变化,本来没有问题的代码可能就变得有问题了。再比如管理员密码泄露、一些配置性错误都会导致安全问题的产生。所以说,原因是多方面的,没有哪个网站是绝对安全的,可能只是还没有发现问题而已。
那么攻击者到底是如何攻陷服务器的呢?如下图所示,既是一张服务器的风险点示意图,攻击者入侵服务器可能就是从一些这些方面入手的:
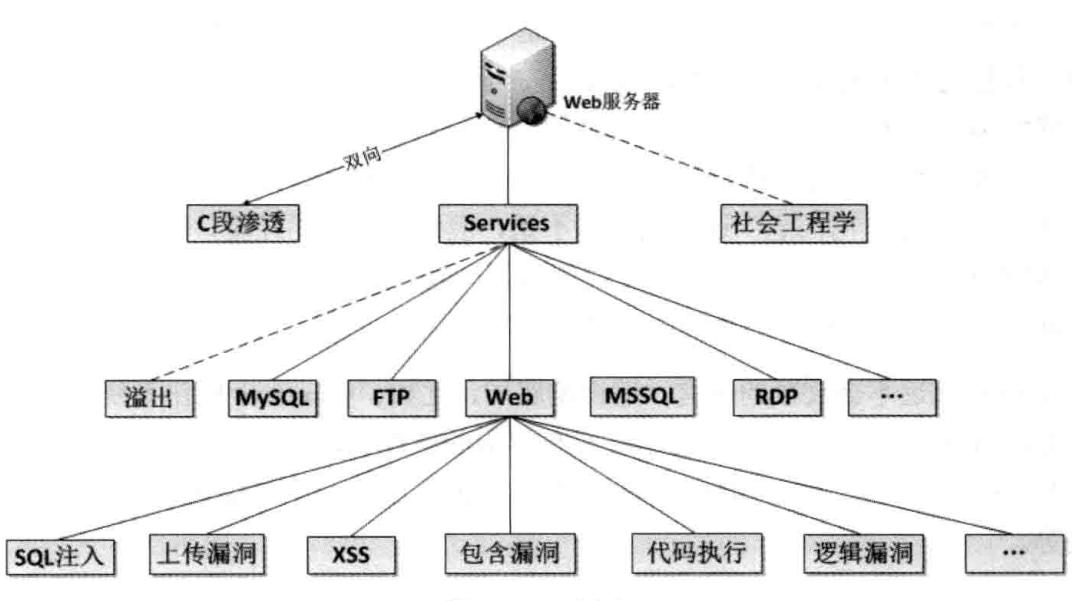
攻击者在渗透服务器时,直接对目标下手一般有三种手段,只有当我们充分了解攻击者的手段之后,才能更好的对攻击行为进行防御:
- C段渗透:攻击者通过渗透同一网段内的一台主机对目标主机进行ARP等手段的渗透。
- 社会工程学:社会工程学是高端攻击者碧血掌握的一个技能,渗透服务器有时候不仅仅只靠技术。
- Services:很多传统的攻击方式是直接对服务进行溢出的,至今一些软件仍存在溢出漏洞。像之前的MySql就出现过缓冲区溢出漏洞。当然,对这类服务还有其他入侵方式,这些方式也经常用于内网的渗透中。
如何更好地学习web安全
相关编程语言介绍:
- C/C++:永远不会衰败的语言,适合偏底层,比如,Windows操作系统80%以上都是由C/C++完成的,C/C++也经常用于写应用层C/S架构的软件。如果想研究缓冲区溢出,或者针对底层协议写一些软件,那么非C/C++莫属。例如:NC、LCX、DNSSniffer、Hydra、溢出程序、远程控制等。
- JAVA:真正跨平台的语言,“一次编译,到处运行”就是JAVA的口号。Java适合应用层的开发,无论是C/S架构还是B/S架构,Java都能够做到,但在国内使用Java(JSP)做B/S架构居多,很多大型企业都采用了Java作为Web开发的首选。例如:Burp Suite、reDuh、Paros Proxy、WebScarab、OWASP Zap等。
- C#:与Java有70%的雷同,同样适用于开发应用层程序,无论是C/S架构还是架构B/S,C#都可以做到,拥有强大的.NET Framework 支持,但是不能跨平台。例如: Pangolin、 Jsky、微软官网等。
- PHP:跨平台的语言,脚本语言,无须编译,但PHP的能力仅限于Web, 速度较慢,也不支持多线程。作为一名Web安全研究者,几乎所有的人都会学习它。
- Python:号称“大蟒蛇”,跨平台,脚本语言,无须编译,适用于一些Shel操作,最近Python也在Web领域取得了一些成就, 开发较快,运行速度较慢 (相对于CIC++来说), 不过很多安全研究者都比较喜欢Python.例如: SQLMap、 W3af、Python 编写的安全工具太多了,在渗透测试平台“Backtrack"下到处都可以看到Python的身影。
- HTML:属于前端语言之一,是渗透测试人员必备的语言。
- JavaScript: 属于前端语言之一, 掌握JavaScript后,可以帮助渗透测试人员更好地理解XSS跨站脚本攻击。
- 数据库:数据库分为很多种,有Oracle、 MySQL、SQL Server、 DB2等,操作数据库的语言即SQL语句,掌握一门SQL语言是必需的,因为几乎没有网站不使用数据库。
虽然说渗透测试时,没有代码基础也能出色的完成任务,但是相对来说,掌握语言的基础是非常有帮助的,因为在渗透测试过程中无法避免有针对性地编写一些代码。
深入HTTP请求流程
随着Web2.0时代的到来,互联网从传统的C/S架构转变为更加方便快捷的B/S架构。B/S即浏览器/服务器结构,就像我们访问过的所有网站,客户端上只需要一个浏览器即可上网。当客户端与Web服务器进行交互时,就存在Web请求,这种请求都基于统一的应用协议(HTTP协议)交互数据。
HTTP协议解析
HTTP协议,即超文本传输协议,是一种详细规定了浏览器和万维网服务器之间互相通信的规则,它是万维网交换信息的基础,它允许将HTML(超文本标记语言)文档从Web服务器传送到Web浏览器。
发起HTTP请求
当在浏览器的地址栏中输入一个URL,并按下回车键后就发起了这个HTTP请求,很快就会看到这个请求返回的结果。
URL(统一资源定位符)也被称为网页网址,是互联网标准的地址。
标准格式:“协议://服务器IP[:端口]/路径/[?查询]”
借助curl工具可以不使用浏览器来快速发起一次HTTP请求,如下图所示:
HTTP协议详解
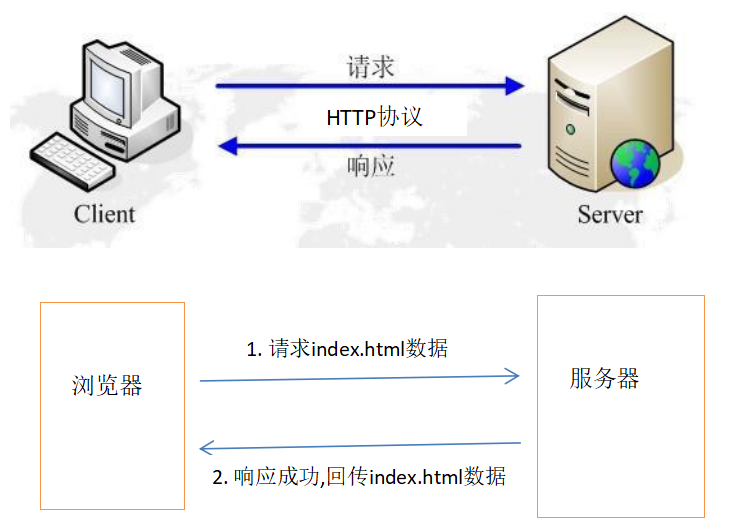
HTTP协议目前的版本是1.1,HTTP是一种无状态的协议。无状态是指Web浏览器与Web服务器之间不需要建立持久的连接,这意味着当一个客户端向服务器端发出请求,然后Web服务器返回响应(Response),连接就被关闭了,在服务端不保留连接的有关信息。也就是说,HTTP请求只能由客户端发起,而服务器不能主动向客户端发送数据。
HTTP遵循请求(Request)/应答(Response)模型,Web浏览器向Web服务器发送请求时,Web服务器处理请求并返回适当的应答,如下图所示:
下面通过实例来观察HTTP的请求与响应。
- HTTP请求与响应
(1)HTTP请求
HTTP请求包括三个部分,分别是:请求行(请求方法)、请求头和请求正文。下面是HTTP请求的一个例子。
POST /login.php HTTP/1.1 //请求行
HOST: www.test.com //请求头
User-Agent: Mozilla/5.0 (Windows NT 6.1;rv:15.0) Gecko/20100101 Firefox/15.0
//空白行,代表请求头结束
Username=admin&Password=admin //请求正文
HTTP请求行的第一行即为请求行,请求行由三部分组成,该行的第一部分说明了该请求是POST请求;该行的第二部分是一个斜杠(/login.php),用来说明请求的是该域名根目录下的login.php;该行的最后一部分说明使用的是HTTP 1.1版本(另一个可选项是1.0)。
第二行至空白行为HTTP中的请求头(也被称为消息头)。其中,HOST代表请求的主机地址,User-Agent代表浏览器的标识。请求头由客户端自行设定。
HTTP请求的最后一行为请求正文,请求正文是可选的,它最常出现在POST请求方法中。
(2)HTTP响应
与HTTP请求对应的是HTTP响应,HTTP响应也由三部分内容组成,分别是响应行、响应头(消息包头)、响应正文(消息主题)。如下所示:
HTTP/1.1 200 OK //响应行
DATE: Thu, 28 Feb 2019 07:36:47 GMT //响应头
Server: BWS/1.0
Content-Encoding: gzip
Content-Length: 12563
Content-Type: text/html; charset=utf-8
Cache-Control: private
Exprires: Thu, 28 Feb 2019 07:36:47 GMT
Content-Encoding: gzip
Set-Cookie: PHPSESSID=cvq0qt7cgee6kntuamlil7l59v; Hm_lvt_c28bc0ecf7d4c8b69eafd431fdf653e0=1585123765; Hm_lpvt_c28bc0ecf7d4c8b69eafd431fdf653e0=1585123765
Connection: Keep-Alive
//空白行,代表响应头结束
<html> //响应正文或者叫消息主题
<head><title>Index.html</title></head>
......
HTTP响应的第一行为响应行,其中包括HTTP版本(HTTP/1.1)、状态码(200)以及消息“OK”。
第二行至末尾空白行为响应头(消息报头),由服务器向客户端发送。
消息报头之后是响应正文,是服务器向客户端发送到HTML数据。
- HTTP请求方法
(1)GET
GET方法用于获取请求页面的指定信息(以实体的格式)。如果请求资源为动态脚本(非HTML),那么返回文本是Web容器解析后的HTML源代码,而不是源文件。例如请求index.jsp,返回的不是index.jsp源文件,而是经过解析之后的HTML代码。如下HTTP请求:
GET /index.php?id=1 HTTP/1.1
HOST: www.test.com
使用GET请求index.php,并且id参数为1,在服务器端脚本语言中可以选择型地接收这些参数,比如id=1&name=admin,一般都是由开发者内定好的参数项目才会接收,比如开发者直接收id参数项目,若加入了其他参数,如:index.php?id=1&username=admin,服务器脚本不会处理你加入的内容,依然只会接收id参数,并且去查询数据,最终向服务器端发送解析过的HTML数据,不会因为你的干扰而乱套。
(2)HEAD
HEAD方法除了服务器不能在响应里返回消息主题外,其他都与GET方法相同。此方法经常被用来测试超文本链接的有效性、可访问性和最近的改变。攻击者编写扫描工具时,就经常使用此方法,因为只测试资源是否存在,而不用返回消息主体,所以速度一定是最快的。一个经典的HTTP HEAD请求如下:
HEAD /index.php HTTP/1.1
HOST: www.test.com
(3)POST
POST方法也与GET方法类似,但最大的区别在于,GET方法没有请求内容,而POST是有请求内容的。POST请求最多用于向服务器发送大量的数据。GET虽然也能发送数据,但是有大小(长度)的限制,并且GET请求会将发送的内容显示在浏览器端,二POST则不会,所以相对来说安全性高一点。
例如:上传文件、提交留言等,只要是向服务器传输大量的数据,通常都会使用POST请求。一个经典的HTTP POST请求如下:
POST /login.php HTTP/1.1
Host: www.test.com
Content-Length: 26
Acceptp: text/html,application/xhtml+xml,application/xml;9,*/*;q=0.8
Origin: http://www.xxxx.com
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.122 Safari/537.36
Content-Type: application/x-www-form-urlencodeed
Accept-Language: Zh-CN,zh;q=0.8
Accept-Charset: GBK,utf-8;q=0.7,*;q=0.3
username=admin&password=admin
用POST方法向服务器请求login.php,并且传递参数username=admin&password=admin。
(4)PUT
PUT方法用于请求服务器把请求中的实体存储在请求资源下,如果请求资源已经在服务器中存在,那么将会用此请求中的数据替换原先的数据,作为指定资源的最新修改版。如果请求指定的资源不存在,将会创建这个资源,且数据位请求正文,请求如下:
PUT /input.txt
HOST: www.test.com
Content-Length: 6
123456
这段HTTP PUT请求将会在主机根目录下创建input.txt,内容为123456。通常情况下,服务器都会关闭PUT方法,因为他会为服务器建立文件,属于危险的方法之一。
(5)DELETE
DELETE方法用于请求源服务器删除请求的指定资源。服务器般都会 关闭此方法,因为客户端可以进行删除文件操作,属于危险方法之一。
(6)TRACE
TRACE方法被用于激发一个远程的应用层的请求消息回路,也就是说,回显服务器收到的请求。TRACE方法允许客户端去了解数据被请求链的另一端接收的情况,并且利用那些数据信息去测试或诊断。但此方法非常少见。
(7)CONNECT
HTTP1.1协议规范保留了CONNECT方法,此方法是为了用于能动态切换到隧道的代理。
(8)OPTIONS
OPTIONS方法是用于请求获得由URI标识的资源在请求刷应的通信过程中可以使用的功能选项。通过这个方法,客户端可以在采取具体资源请求之前,决定对该资源采取何种必要措施,或者了解服务器的性能。HTTP OPTIONS请求如下:
OPTIONS / HTTP/1.1
HOST: www.test.com
HTTP/1.1 200 OK
Allow: OPTIONS, TRACE, GET, HEAD, POST
Server: Microsoft-IIS/7.5
Public: OPTIONS, TRACE, GET, HEAD, POST
X- Powered-By: ASP.NET
Date: Sun, 14 Jul 2013 15:50:58 GMT
Content-Length: C
以上为HTTP/1.1 标准方法,详情请参照“http://ww.w3.or/rotocotolsfo2616/6/2616-sec9.html",但HTTP中的请求方法还不止这些,例如WebDAV。WebDAV (Web based DistributedAuthoring ard Versioning)是一种基于 HTTP/1.1 协议的通信协议,它扩展了HTTP 1.1,在GET、POST、HEAD等几个HTTP标准方法以外添加了一些新的方法,使应用程序可直接对Web Server进行读写,并支持写文件锁定(Locking)和解锁(Unlock)、文件复制(Copy)、文件移动(Move)。另外,还可以支持文件的版本控制。
- HTTP状态码
-
1xx: 信息提示,表示请求已被成功接收,继续处理。其范围为100~ 101。2xx:成功,服务器成功地处理了请求。其范围为200~ 206.
-
3xx:重定向,重定向状态码用于告诉浏览器客户端,它们访问的资源已被移动,并告诉客户端新的资源地址位置。这时,浏览器将重新对新资源发起请求。其范围为300~305。
-
4xx:客户端错误状态码,有时客户端会发送一些服务器无法处理的东西,比如格式错误的请求,或者最常见的是,请求一个不存在的URL.其范围为400 ~415.
-
5xx: 有时候客户端发送了一-条有效请求,但Web服务器自身却出错了,可能是Web服务器运行出错了,或者网站都挂了。5XX就是用来描述服务器内部错误的,其范围为500~ 505。
常见的状态码描述如下。
200:客户端请求成功,是最常见的状态。
302:重定向。
404:请求资源不存在,是最常见的状态。
400:客户端请求有语法错误,不能被服务器所理解。
401:请求未经授权。
403:服务器收到请求,但是拒绝提供服务。
500:服务器内部错误,是最常见的状态。
503:服务器当前不能处理客户端的请求,一段时间后可能恢复正常
- HTTP消息
HTTP消息又称为HTTP头(HTTP header),由四部分组成,分别是请求头、响应头、普通头和实体头。从名称上看,就可以大概知道它们的位置。
(1)请求头
请求头只出现在HTTP请求中,请求报头允许客户端向服务器传递请求的附加信息和客户端自身的信息。常用的HTTP请求头如下:
①Host
Host请求报头域主要用于指定被请求资源的Internet主机和端口号,例如:Host: www.test.com:81。
②User-Agent
User-Agent允许客户端将它的操作系统、浏览器和其他属性告诉服务器。登陆一些网站时,很多时候都可以见到显示我们的浏览器、系统信息,这些都是User-Agent的作用,如:User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.122 Safari/537.36。
③Referer
Referer包含一个URL,代表当前访问URL的上一个URL,也就是说, 用户是从什么地方来到本页面。如: Referer: www.test.com/login.php,代表用户从login.php来到当前页面。
④Cookie
Cookie是非常重要的请求头,它是一段文本,常用来表示请求者身份等。
⑤Range
Range可以请求实体的部分内容,多线程下载定会用到此请求头。 例如: 表示头500字节: bytes=0~499
表示第二个500字节: bytes=500~ 999表示最后500字节: bytes-500
表示500字节以后的范围: bytes-500-
⑥X-forward-for
x-forward-for即XXF头,它代表请求端的IP,可以有多个,中间以逗号隔开。
⑦Accept
Accept请求报头域用于指定客户端接收哪些MIME类型的信息,如Accept: text/html, 表明客户端希望接收HTML文本。
⑧Accept Charset
Accept- Charset请求报头域用于指定客户端接收的字符集。例如: Acept-Charset:iso 8859-1,gb2312。如果在请求消息中没有设置这个域,默认是任何字符集都可以接收。
(2)响应头
响应头是服务器根据请求向客户端发送的HTTP头。常见的HTTP响应头如下。
①Server
服务器所使用的Web服务器名称,如Server:Apache/1.3.6(Unix),攻击者通过查看此头,可以探测Web服务器名称。所以,建议在服务器端进行修改此头的信息。
②Set-Cookie
向客户端设置Cookie,通过查看此头,可以清楚地看到服务器向客户端发送的Cookie信息。
③Last-Modified
服务器通过这个头告诉浏览器,资源的最后修改时间。
④Location
服务器通过这个头告诉浏览器去访问哪个页面,浏览器接收到这个请求之后,通常会立刻访问Location头所指向的页面。这个头通常配合302状态码使用。
⑤Refresh
服务器通过Refresh头告诉浏览器定时刷新浏览器。
(3)普通头
在普通报头中,有少数报头域用于所有的请求和响应消息,但并不用于被传输的实体,只用于传输的消息。例如: Date, 表示消息产生的日期和时间。Connection,允许发送指定连接的选项。例如,指定连接是连续的,或者指定“close"选项,通知服务器,在响应完成后,关闭连接。Cache-Control,用于指定缓存指令,缓存指令是单向的,且是独立的。
普通报头作为了解即可。
(4)实体头
请求和响应消息都可以传送一一个实体头。 实体头定义了关于实体正文和请求所标识的资源的元信息。元信息也就是实体内容的属性,包括实体信息类型、长度、压缩方法、最后一-次修改时间等。常见的实体头如下:
①Content-Type
Content-Type实体头用于向接收方指示实体的介质类型。
②Content-Encoding
Content-Encoding头被用作媒体类型的修饰符,它的值指示了已经被应用到实体正文的附加内容的编码,因而要获得Content-Type报头域中所引用的媒体类型,必须采用相应的解码机制。
③Content-Length
Content-Length实体报头用于指明实体正文的长度,以字节方式存储的十进制数字来表示。
④Last-Modified
Last-Modified实体报头用于指示资源的最后修改日期和时间。
HTTP协议与HTTPS协议的区别
HTTPS协议的全称为Hypertext Transfer Protocol over Secure Socket Layer,它是以安全为目标的HTTP通道,其实就是HTTP的“升级”版本,只是它比单纯的HTTP协议更加安全。
HTTPS的安全基础是SSL,即在HTTP下加入SSL层。也就是HTTPS通过安全传输机制进行传送数据,这种机制可保护网络传送的所有数据的隐秘性与完整性,可以降低非侵入性拦截攻击的可能性。
既然是在HTTP的基础上进行构建的HTTPS协议,所以,无论怎么样,HTTP 请求与响应都是以相同的方式进行工作的。
HTTP协议与HTTPS协议的主要区别如下。
- HTTP是超文本传输协议,信息是明文传输,HTTPS 则是具有安全性的SSL加密传输协议。
- HTTP与HTTP协议使用的是完全不同的连接方式,HTTP 采用80端口连接,而HTTP 则是443端口。
- HTTPS协议需要到ca申请证书,一般免费证 书很少,需要交费,也有些Web容器提供,如TOMCAT。而HTTP协议却不需要。
- HTTP 连接相对简单,是无状态的,而HTTPS协议是由SSL+HTTP协议构建的可进行加密传输、身份认证的网络协议,相对来说,它要比HTTP协议更安全。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号