Django路由层
目录
Django路由
- 路由简单的来说就是根据用户请求的 URL 链接来判断对应的处理程序,并根据对应视图层的功能返回处理结果,也就是 URL 与 Django 的视图建立映射关系。
- Django 路由在 urls.py 配置,urls.py 中的每一条配置对应相应的处理方法。
- Django 不同版本 urls.py 配置略有不同
django 1.x版本
from django.conf.urls import url
urlpatterns = [
url(正则表达式, views视图函数,参数,别名),
]
django 2.x之后的版本
from django.urls import path
urlpatterns = [
path('articles/2003/', views.special_case_2003),
path('articles/<int:year>/', views.year_archive),
path('articles/<int:year>/<int:month>/', views.month_archive),
path('articles/<int:year>/<int:month>/<slug:slug>/', views.article_detail),
]
路由匹配的原理
读取路由层中的urlpatterns列表中的配置,由上到下逐个匹配。第一次会进行完名匹配,也就是路由中输入什么就匹配什么,比如“index”路由,django会去列表中匹配,如果匹配不成功,会返回301重定向状态码,之后会在末尾添加 / 符号,也就是以“index/”重新再一次进行匹配。
注意:所有版本django都自带末尾加“/”符号功能,默认开启,也可以取消。取消方法如下:
# 在settings.py中添加:
APPEND_SLASH = False
# 注意这样用户体验不会很好
path
- 正常情况下,很多网站都会有非常多的相似的网址,如果每个网址都开设一个路由,这样很不合理。比如博客地址,每篇博客都有一个地址,每个用户都会写很多博客,这样路由层配置就会过多,非常不合理。这时就需要无名有名分组。
Django自带url参数转换器
str: 除了斜杠/以外所有的字符都是可以的。
int: 只有是一个或者多个的阿拉伯数字。
path:所有的字符都是满足的。
uuid:只有满足uuid.uuid4()这个函数返回的字符串的格式。
slug:英文中的横杆或者英文字符或者阿拉伯数字或者下划线才满足。
ps: Django还支持自定义转转换器,自己写正则表达示匹配更加细化的功能,但这个功能并没有re_path好用。
url转换器具体使用方法
- django 2.x以上版本可以使用转换器
# 转换器:将对应位置匹配到的数据,转换为固定的数据类型
path('index/<str:info>/', views.func_name)
# 后台需要接收info关键字函数,注意info可以随便改为其它名字
# views层配置函数
def func_name(request, info):
HttpResponse('我是测试转换器页面')
测试页面:http://127.0.0.1:8000/index/abcd
# 可以匹配多个转换器参数
path('index/<str:info>/<int:num>/, views.func_name')
# 这时候配置函数
def func_name(request, info, num)
HttpResponse('我来测试两个参数')
测试页面:http://127.0.0.1:8000/index/abcd/123
re_path
django 2.x以上版本有re_path,在列表中,第一个参数为正则
- 导入模块
from django.urls import re_path
- 在urlpatterns列表中使用,写法如下
re_path('正则', views.test_func),
路由匹配冲突
- 下面的正则如何匹配?
re_path('test', views.test_func),
re_path('testadd', views.testadd_func),
'''
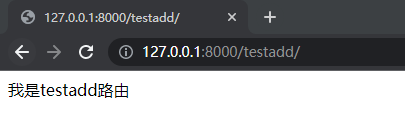
当在浏览器中输入127.0.0.1:8000/testadd/时,上面的路由会匹配到test,而不是testadd,顺序如下:
1. 正则由上到下匹配
2. 匹配到test后,去testadd路由里面匹配
3. 在testadd中匹配到了test
4. 路由最终走到test路由就算是匹配成功。
总结,re_path匹配是按正则进行匹配的,只要第一个正则表达式能够从用户输入的路由中匹配到数据就算匹配成功,此时会立即停止路由层其他匹配,直接执行对应的视图函数。
示例二:
re_path('ccc',views.ccc_func),
re_path('abccc', views.abccc_func),
'''
- 浏览器中输入abccc,我还有一个路由是ccc,而abccc中正好包含了ccc,而ccc正好还在abccc上面,那么它就会与ccc匹配成功,如下图:
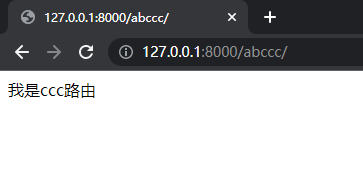
- 这时,我们可以尝试使用在路由结尾添加斜杠处理
re_path('test/', views.test_func),
re_path('testadd/', views.testadd_func),
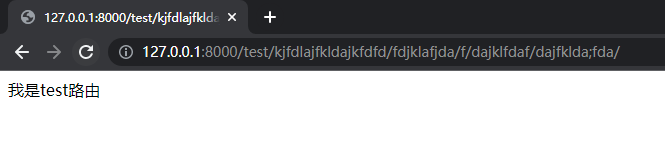
- 但发现使用上述方法会导致其它路由冲突的问题,比如下图:

- 上面的冲突显然不是我们想看到的,任何一个网站也不可能路由在中间时也算是匹配成功,为了解决这个问题,我们又想到了使用其他方法,比如以test/开头才算匹配成功,示例如下:
re_path('^test/', views.test_func),
re_path('^testadd/', views.testadd_func),
这样只能限制开头,但是无法限制结尾

re_path无名有名分组
无名分组
需求:匹配test路由后,再加其它一些数字
re_path('^test/\d{4}/', views.test_func),
上面匹配的规则是,test路由后,再加4位数数字以斜杠结尾。不输入4位数字会报错。
如:http://127.0.0.1:8000/test/1234/
但上面的方法,匹配到的内容不会传给对应的视图函数。如果需要传给视图函数,就需要使用分组功能
# 下面的方法会将括号内正则匹配到的内容当作位置参数传递给视图函数
re_path('^test/(\d{4})/', views.test_func)
# 视图函数就需要传入相应的参数
def test_func(request, args):
print(args) # 此时的args就是浏览器中输入的四位的数字
return HttpResponse('我是test路由')
上面的方法与path的不同的是,它更加灵活,使用正则可以随便定义匹配规则。
有名分组
- 有名分组其实就是把正则分组后的内容起一个别名,方法如下
# ?P<别名>(正则)
re_path('^test/?P<number>(\d{4})/', views.test_func)
# 注意,这时向视图函数传参时,会以 “number=正则内容”,视图函数需要接入传入的关键字了
def test_func(request, number): # 此时这里就不能传入args参数了,只能传路由中定义的别名
return HttpResponse('我是test路由')
注意: 无名有名分组不能混合使用!!!!!
反向解析
反向解析静态路由
- 我得理解是,为一个路由定义一个别名,最终通过别名解析到路由,最终执行对应的视图函数。
# 使用方法
# 1. 在路由层配置路由,指定name参数
path('test/', test_func, name='mytest'),
# 2. 前端使用定义的别名,比如a标签
<a href="{% url 'mytest' %}">测试别名</a> # 这时后台修改路由名也不会影响调用
# 3. 后端使用定义的别名
# 3.1 需要先导入模块
from django.shortcuts import reverse
# 3.2 使用reverse反向解析
reverse('mytest') # 解析出的结果是实际的路由,在本例中为“/test/”
反向解析动态路由
# 比如有一个路由:
path('test/<str:info>/', views.test_func, name='mytest')
# 前台语法
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<span>我是test,用来测试反向解析</span>
<a href="{% url 'mytest2' 123 %}">aaa</a>
<a href="{% url 'mytest2' abc %}">bbb</a>
<a href="{% url 'mytest2' ddd %}">333</a>
</body>
</html>
# <a href="{% url 'mytest2' 123 %}">aaa</a> 中,需要在别名后面指出动态解析出的部分是什么。
# 后端的反向解析
from django.shortcuts import reverse
reverse('mytest', args=('xxx', )) # 注意逗号,因为是元组
- 总结:当反向解析的时候,需要告诉前台动态解析的部分是什么,这里在实际应用中,一般可以使用用户的主键值。如果有多个动态解析的内容,就用空格隔开即可。
使用主键值的例子
# 路由层
path('update_user/<int:pk>/', views.update_user_func, name='update_user'),
# 模板层
{% for user_obj in userlist %}
<a href="{% url 'update_user' user_obj.pk %}" class="btn btn-success text-center">编辑</a>
{% endfor %}
路由分发
- django支持,每个app都有自己独立的路由层、静态文件、模板层。
- 在项目下的urls.py称为总路由,在每个app下还可以有自己独立的urls.py(手工创建),称为子路由。子路由最终由总路由整合到一起。
# app01下的urls.py(手工创建)
from django.urls import path
urlpatterns = [
path('index/', views.index_func)
]
# 对应视图函数
def index_func(request):
return HttpResponse('我来测试路由分发系统')
# 总路由配置
# 需要导入include模块
from django.urls import path, include
urlpatterns = [
path('app01/', include('app01.urls'))
# 如果有多个路由,只要全部include进去即可
]
此时需要访问的地址为:http://127.0.0.1:8000/app01/index/
- 效果如下

名称空间
当使用了路由分发之后,再使用相同的别名会造成冲突,导致解析发生混乱。如有app01、app02、app03多个app,
from django.urls import path
urlpatterns = [
path('index/', views.index_func, name='index') # app01/app02/app03三个app都使用index别名
]
# 总路由配置如下
from django.urls import path, include
urlpatterns = [
path('app01/', include('app01.urls'))
path('app02/', include('app02.urls'))
path('app03/', include('app03.urls'))
# 如果有多个路由,只要全部include进去即可
]
- 解决办法1:
# 在总路由的配置中声名一下名称空间
from django.urls import path, include
urlpatterns = [
path('app01/', include(('app01.urls'), namespace='app01'))
path('app02/', include(('app02.urls'), namespace='app02'))
path('app03/', include(('app03.urls'), namespace='app03'))
# 如果有多个路由,只要全部include进去即可
]
- 解决办法2:
只要在起别名的时候不要冲突就可以了,比如使用自己的app加前缀。此种方法简单。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号