[论文阅读] How do humans sketch objects?
2013-06-15 10:53 smyb000 阅读(2131) 评论(0) 收藏 举报 Do you know how humans sketch objects?
Do you know how humans sketch objects?

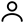



Mathias Eitz (Technische Universitat Berlin), James Hays (Brown University), Marc Alexa (Technische Universitat Berlin)
前言
这篇文章来自Eitz, 此人是SIGGRAPH 2013 Technical Papers Chair ——Marc Alexa的学生,数年来专攻Sketch, 在Sketch-based retrieval& recgnition发表了很多文章。这篇文章发表一年来被引用7次,说明了文章的重要性,挖了个好坑,引众人纷纷跳。作者有三位, 其中James Hays是搞海量图像数据的大神级人物,07年的的‘Scene completion using millions of photographs’ 已被引用超300次,该文章是Eitz同学在布朗大学交流时做的,Eitz做Sketch, Hays做海量数据,于是就诞生了这篇Large-Scale的关于Sketch文章。
文章介绍

图1.文章的teaser
从题目上看,这篇文章就不走寻常路, 题目为“人类怎样画草图”。从题目上并不能看出文章究竟做了什么内容,相当抽象。看Teaser,哦,原来他是探索人类怎么画草图和识别草图,但还是很抽象……的确,这篇文章大篇幅地介绍了怎样得到无偏的草图数据,怎样做实验来得到人类对草图的识别准确率(73%)以及用提出的方法得到机器识别草图的准确度(56%)。文章大量篇幅介绍了实验过程来确保实验的公平合理性,并用小篇幅提出了自己的用于识别的bag-of-features描述子(类似于Dense sift),以及用简单的SVM分类器来分类草图,技术上并没有什么难点。这篇文章是第一个花大量人力物力收集各个类别(250类)的草图,并且第一个雇人做userstudy对草图进行人工识别而且第一个用计算机去识别自己得到的大量草图数据(三个第一)。但这篇文章由于覆盖的范围较广,导致以后做草图的文章无论如何都得引用它。
收集草图
Sec.3,作者介绍了如何收集到了20000个覆盖250类的Sketch( 每类80个)。草图的类别应该具有以下性质:
-
详尽性:类别应覆盖日常的物品,即:给一个草图,能够对应一个类别。
-
可识别性:类别应仅从草图的形状就能识别出来。
-
具体性:类别名称应为具体的词语,例如:动物或者乐器,都是不符合条件的。
首先,定义250个类别关键词:LabelMe关键词+Princeton Shape Benchmark关键词+Caltech关键词-重复关键词+自己实验室的同学想出来的补充关键词。最终得到了250个关键词,这些词覆盖了大部分的常见类别,用作者的话说,已经很难再想出能补充进去的词语。
在收集sketch方面,在Amazon Mechanical Turk上付费请了1350个人对每一类关键词画至多一个sketch,共得到了90*250 = 22500个sketch, 去除一些不符合要求的sketch, 共得到80*250 = 20000个sketch. 同时,对收集到的用户的sketch进行分析,得到一些有意思的统计数据,比如:平均每个sketch耗时86秒,由13个笔画组成。
人类对草图的识别
Sec.4, 进行userstudy,测评人类对收集到的sketch识别的准确度是多少。
在实验中,250个类别的词分为三层结构给用户进行选择,例如: 动物-猫科-加菲猫。最顶层为6大类,中层为27大类。20000个sketch被分成5000个任务,每个任务为识别4个不同类别的sketch,为其选择所属的关键词类别,每个用户可以认领多份任务,每个人至多不超过100个任务。
实验结果为:人类平均识别准确率为73%,其中最差的为2.5%,这是因为sketch和其他类别的sketch很容易混淆,例如图2所示。

图2. 错误分类的例子。其中,第一行为错误分类最严重的类别。对于每一列,下面的三行为对应的第一行误分到的类别。例如,对于误分类到别的类的seagull, 47%被错误分类到flying bird, 24%被分类到standing bird, 14%被分类到pigeon.(standing bird也对嘛 O(∩_∩)O~)
为了得到公正的结果,作者假设用户做过的识别越多,经验就越丰富,结果也就越准确,于是如果有人识别的sketch超过40个,就取40个之后的sketch。 最终得到的准确度为73.9%, 并没有显著的提高。
提取草图特征
Sec.5 作者提出表达sketch的特征,用于机器识别分类。
作者将sketch简单地看做位图(bitmap),忽略每个stroke的时间信息,提取的特征为Bag-of-features特征:
提取bag-of-features特征
- 将sketch依据包围盒缩放到同一尺度(256*256),均匀取28*28=784个兴趣点,每个兴趣点提取一个local feature.
- 对于每一个兴趣点,取一个正方形的patch(包围盒尺寸的1/8), 在这个patch里提取特征。
- 对于每个patch, 提取每个像素点的梯度,按照梯度的方向将其量化到r=4个方向的bin中(假设方向为0-180度,4个bin分别为0-45,45-90,90-135,135-180度)。这样得到了4个相应梯度方向直方图O1O2O3O4 。每个直方图O中再按空间信息分为4*4=16个格子(每个格子中所有像素点的统计值加起来)这个每个Oi就表示成Oi 1Oi 2,…Oi 16。d将所有的4个O图的16维向量连接起来,得到64维向量,进行归一化,得到每个patch的特征d。
这样,对于20000个sketch,就得到了20000*784 = 15,680,000个特征。随机取1,000,000 用在最终的识别算法中。
上面的步骤提取到了sketch的特征,但用于识别,还要更改每个sketch的表达方式:
构建bag-of-words特征
和常规的相似图像检索一样,提取出了bag-of-features特征要转换成bag-of-words的表达方式,给出一个字典dictionary,每个feature用字典中的word来表示,这样每个feature就用word的直方图来表达:
- 设定字典大小,作者用了500个词(个人感觉设的值偏小,在基于局部特征的图像检索中都设的很大,例如100000).
- 用k-means聚类得到聚类中心,并用soft 的量化方法对每个feature特征向量计算到这500个聚类中心的权值Wi i=1,..500,记为W向量。
- 对于每个sketch, 最终的特征向量就为每个patch的W向量相加,并归一化。即每个sketch是一个500维的向量。
非监督学习分析
Sec.6 用特征进行非监督分析, 在这一章节做了两方面的工作,都是基于Sec.5 提出的特征:
- 用mean-shift方法对每一类别进行聚类,提取每个类别里的代表性sketch, 一般每个类别可用1或2个sketch来代表,见图3。
- 用降维方法将每个类别里的所有sketch降维到2维点中,从而直观看到sketch按照相似性的分布,见图4。

图3.类别的代表性sketch.

图4. 每个类别中sketch的分布
用计算机对草图进行识别
Sec.7,作者设计了方法用Sec.5对sketch识别。具体用了两种方法:
- KNN方法,在这20000个sketch中,对需要识别的sketch找到k近邻,统计k近邻所属的类别,大多数所属类别的极为最终类别。
- SVM分类,用高斯核进行训练250个1-vs-all分类器(正例为某一类,负例为所有其他249个类),对于某个sketch,计算250个与超平面的距离,取值最大的超平面所属的类别为识别得到的类别。
KNN的识别率约为45%, SVM为56%。
应用
作者提出了3个应用,但只有第一个有demo, 后两个确实有点生硬:
- 实时草图识别,用训练好的分类器,可以让用户边画边识别,给出前20个候选类别关键词,只需要0.1秒的响应时间,需要注意的是,如果画的sketch歧义很大,可能画到最后,添加一点stroke,识别结果就会不同。如图5所示。视频地址
- 用于草图检索,利用草图识别系统,可以对用户输入的草图先得到最有可能的类别,然后利用关键词直接搜索。
- 历史壁画识别,有些壁画很难确认是什么内容,用草图识别系统就可以搞定。(这个。。。。。)

图5. 实时草图识别demo

 浙公网安备 33010602011771号
浙公网安备 33010602011771号