
数据结构基础
存储结构分为:
1,随机存取,即可随意直接存取任意一个元素,通过下标直接存取出任何一个元素;通过地址直接访问任意一个空间
2,顺序存取,只能从前往后逐个访问。
3,索引存取,为某个关键字建立索引表,从表中取得地址。索引存取多用在数据管理过程中。
4,散列存取。
有1千万条重复的短信,以文本形式保存,一行一条,有重复。请在5分钟时间内找出重复出现最多的10条短信?
答:用哈希表的方法。
1)将1千万条短信分成若干组,进行边扫描边建散列表的方法。第一次扫描,取首字节、尾字节、中间任意两个字节作为hash code,插入到Hash table中,并记录其地址、信息长度和重复次数。同Hash code且等长就疑似为相同,比较一下,若相同则加1次Hash table,将重复次数加1。一次扫描后,已经记录了各自的重复次数,进行第2次hash table的处理。用线性时间选择可在O(n)的级别上完成前10条的寻找。分组后每组中的top10必须保证各不相同,可用hash来保证,也可以用hash值来保证。
深度优先遍历(DFS)类似于树的前序遍历。
广度优先遍历(BFS)类似于树的按层次遍历。
哈夫曼编码:abcdabaa,a编码0(1位),b编码10(2位),c编码110(3位),d编码111(3位),总长度:1*4+2*2+3*1+3*1=14
http://www.cnblogs.com/huangxincheng/archive/2012/11/25/2788268.html
Trie树,又称为单词查找树、字典树。经常用于搜索引擎系统用于文本词频统计。
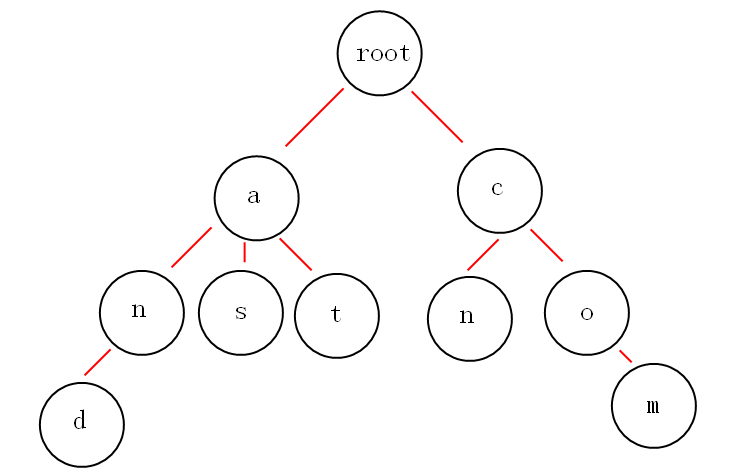
从上面的图中,我们或多或少的可以发现一些好玩的特性。
第一:根节点不包含字符,除根节点外的每一个子节点都包含一个字符。
第二:从根节点到某一节点,路径上经过的字符连接起来,就是该节点对应的字符串。
第三:每个单词的公共前缀作为一个字符节点保存。
二:使用范围
既然学Trie树,我们肯定要知道这玩意是用来干嘛的。
第一:词频统计。
可能有人要说了,词频统计简单啊,一个hash或者一个堆就可以打完收工,但问题来了,如果内存有限呢?还能这么
玩吗?所以这里我们就可以用trie树来压缩下空间,因为公共前缀都是用一个节点保存的。
第二: 前缀匹配
就拿上面的图来说吧,如果我想获取所有以"a"开头的字符串,从图中可以很明显的看到是:and,as,at,如果不用trie树,
你该怎么做呢?很显然朴素的做法时间复杂度为O(N2) ,那么用Trie树就不一样了,它可以做到h,h为你检索单词的长度,
可以说这是秒杀的效果。
快速排序的空间复杂度?为什么比堆排序优秀?
1)归并排序每次递归都要用到一个辅助表,长度与待排序的表长度相同,虽然递归次数是O(log2n),但每次递归都会释放掉所占的辅助空间,所以下次递归的栈空间和辅助空间与这部分释放的空间就不相关了,因而空间复杂度还是O(n)。
快速排序空间复杂度只是在通常情况下才为O(log2n),如果是最坏情况的话,很显然就要O(n)的空间了。当然,可以通过随机化选择pivot来将空间复杂度降低到O(log2n)。
2)堆排序中的每次比较对问题集的划分没有快排效率高,平均下来则需要更多比较次数来找到最后结果,虽然复杂度是一样的。
printf主要是继承了C语言的printf的一些特性,可以进行格式化输出
print就是一般的标准输出,但是不换行
println和print基本没什么差别,就是最后会换行

