
java程序设计基本概念 jvm
JVM

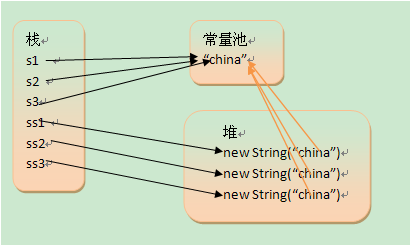
1 String s1 = "china";
2 String s2 = "china";
3 String s3 = "china";
4 String ss1 = new String("china");
5 String ss2 = new String("china");
6 String ss3 = new String("china");
1 int i1 = 9; 2 int i2 = 9; 3 int i3 = 9; 4 public static final int INT1 = 9; 5 public static final int INT2 = 9; 6 public static final int INT3 = 9;

例题详解:
http://www.cnblogs.com/Eason-S/p/5658230.html
http://www.jianshu.com/p/c7f47de2ee80

http://www.cnblogs.com/sunada2005/p/3577799.html
http://www.cnblogs.com/dingyingsi/p/3760447.html
Java异常机制
http://blog.csdn.net/hguisu/article/details/6155636
http://yangshen998.iteye.com/blog/1311682
final、finally和finalize的区别
http://blog.csdn.net/lichaohn/article/details/5424519
反射
java中的反射reflection是java程序开发语言的特点之一,他允许运行中的java程序对自身进行检查,并直接操作程序的内部属性。在实际应用中并不多。
所谓反射,是指在运行状态中,对于任意一个类,都能够知道这个类的所有属性和方法;对于任意一个对象,都能够调用它的任意一个方法和属性。这种动态获取信息以及动态调用对象方法的功能称为java语言的反射机制。
反射有如下的功能:
在运行时判断任意一个对象所属的类;
在运行时构造任意一个类的对象;
在运行时判断任意一个类所具有的成员变量和方法;
在运行时调用任意一个对象的方法;
生成动态代理。
这里的反射主要通过 Class 类来实现。
实例:
java.lang.reflect.Constructor
一、Constructor类是什么
Constructor是一个类,位于java.lang.reflect包下。
在Java反射中 Constructor类描述的是 类的构造方法信息,通俗来讲 有一个类如下:
1 package com.testReflect;
2 public class ConstructorDemo {
3 private int num;
4 private String str;
5
6 public ConstructorDemo(){
7 num = 2;
8 str = "xixi";
9 }
10
11 public ConstructorDemo(int num,String str){
12 this.num = num;
13 this.str = str;
14 }
15
16 @Override
17 public String toString() {
18 return "ConstructorDemo [num=" + num + ", str=" + str + "]";
19 }
20 }
在Java反射中ConstructorDemo类中的构造方法ConstructorDemo()、ConstructorDemo(int num,String str)都是Constructor类的实例,这个Constructor类的实例描述了构造方法的全部信息。(包括:方法修饰符、方法名称、参数列表 等等)
二、如何获取Constructor类对象
一共有4种方法,全部都在Class类中:
- getConstructors():获取类中的公共方法
- getConstructor(Class[] params): 获取类的特定构造方法,params参数指定构造方法的参数类型
- getDeclaredConstructors(): 获取类中所有的构造方法(public、protected、default、private)
- getDeclaredConstructor(Class[] params): 获取类的特定构造方法,params参数指定构造方法的参数类型
三、Constructor类中常用的方法
对于构造方法,我们就是用来创建类的实例的,但是在Java反射中需要注意的是:默认构造函数和带参数的构造方法创建实例的区别。
1 package com.testReflect;
2
3 import java.lang.reflect.Constructor;
4 import java.lang.reflect.Modifier;
5
6 public class ConstructorTest {
7 public static void main(String[] args) throws Exception {
8 //使用反射第一步:获取操作类ConstructorDemo所对应的Class对象
9 Class<?> cls = Class.forName("com.testReflect.ConstructorDemo");
10
11 //获取默认的构造函数
12 Constructor constructor1 = cls.getConstructor(new Class[]{});
13 //获取构造函数信息
14 System.out.println("修饰符: "+Modifier.toString(constructor1.getModifiers()));
15 System.out.println("构造函数名: "+constructor1.getName());
16 System.out.println("参数列表: "+constructor1.getParameterTypes());
17 //通过默认的构造函数创建ConstructorDemo类的实例
18 Object obj = constructor1.newInstance();
19 System.out.println("调用默认构造函数生成实例:"+obj.toString());
20
21 System.out.println("===============================================");
22
23 //获取带参数的构造函数
24 Constructor constructor2 = cls.getConstructor(new Class[]{int.class,String.class});
25 System.out.println("修饰符: "+Modifier.toString(constructor2.getModifiers()));
26 System.out.println("构造函数名: "+constructor2.getName());
27 System.out.println("参数列表: "+constructor2.getParameterTypes());
28 //获取构造函数信息
29 //通过带参数的构造函数创建ConstructorDemo类的实例
30 Object obj2 = constructor2.newInstance(new Object[]{33,"haha"});
31 System.out.println("调用带参数构造函数生成实例:"+obj2.toString());
32 }
33 }
具体实例:
public static void main(String[] args) {
int j = 0;
for(int i = 0 ; i<100; i++ ){
j=j++;
}
System.out.println(j);
}
结果是0
在这里JVM里面有两个存储区,一个是暂存区(以下称为堆栈),另一个是变量区。j=j++是先将j的值(0,原始值)存入堆栈中(对应图中分配一块新的内存空间),然后对自变量区中j自加1,这时j的值确实是1,但随后将堆栈中的值赋给变量区的j,所以最后j=0;
而j=++j,是先对变量区中的j加1,再将自变量区中的j值(1)存入堆栈,最后将堆栈中的值赋给自变量区的j,所以j=1;
0 开头的是八进制数值,0x 开头的是十六进制数。
int a = 5;
System.out.println((a<5) ? 10.9 : 9);
三目运算符<表达式1>?<表达式2>:<表达式3>; "?"运算符的含义是: 先求表达式1的值, 如果为真, 则执行表达式2,并返回表达式2的结果 ; 如果表达式1的值为假, 则执行表达式3 ,并返回表达式3的结果.
以上是三目运算符的基本定义与使用。表面上看来,应该是比较简单。在《Java程序员面试宝典》这本书里,我们见到了了两道比较有意思的题目。
题目1:【中国东北著名软件公司D2009年3月笔试题】
int a=5;
System.out.println("a="+((a<5)?10.9:9));
A. 编译错误
B. 10.9
C. 9
D. 以上答案都不对
也许和大多数人一样,刚开始想当然的以为a<5为false,那么结果就是9了,选C嘛!
仔细想想,这就是题目设置的陷阱。在表达式=(a<5)?10.9:9中有一个10.9,这是java就会根据运算符的精度进行自动类型的转换,由于前面是10.9,那么后面的9也就跟着变为9.0了!
题目2:【中国东北著名软件公司D2009年3月笔试题】
char x='x';
int i=10;
System.out.println(false?i:x);
System.out.println(false?100:x);
A. 120 x
B. 120 120
C. x 120
D. 以上答案都不对
答案为A
解析:System.out.println(false?i:x)与上个题目1相同,x被提升为int类型,所以输出x的ASCII码
而对于第二行,由于100是一个常量表达式。若三目运算符中的两个表达式有一个是常量表达式,另一个是类型T(本题中为char)的表达式,且常量表达式可以被T表示,则输出结果是T类型。因此输出是字符
核心思想:
1.若三目运算符中的两个表达式有一个是常量表达式,另一个是类型T的表达式,且常量表达式可以被T表示,则输出结果是T类型。
2.如果都是常量表达式,用向上类型转换
java.lang.NumberFormatException的意思是数字格式化异常,也就是要把"176//240"这个输入字条转换为一个数字无法转换.
:按照一般常理,定义doSomething方法是定义了ArithmeticException异常,在main方法里面调用了该方法。那么应当继续抛出或者捕获一下。但是ArithmeticException异常是继承RuntimeException运行时异常。 Java里面异常分为两大类:checkedexception(检查异常)和unchecked exception(未检查异常),对于未检查异常也叫RuntimeException(运行时异常),对于运行时异常,java编译器不要求你一定要把它捕获或者一定要继续抛出,但是对checkedexception(检查异常)要求你必须要在方法里面或者捕获或者继续抛出。
Java代码
- public class ExceptionTypeTest {
- public void doSomething()throws ArithmeticException{
- System.out.println();
- }
- public static void main(){
- ExceptionTypeTest ett = new ExceptionTypeTest();
- ett.doSomething();
- }
- }
问题1:上面的程序能否编译通过?并说明理由。
解答:能编译通过。分析:按照一般常理,定义doSomething方法是定义了ArithmeticException异常,在main方法里 里面调用了该方法。那么应当继续抛出或者捕获一下。但是ArithmeticException异常是继承RuntimeException运行时异常。 java里面异常分为两大类:checkedexception(检查异常)和unchecked exception(未检
查异常),对于未检查异常也叫RuntimeException(运行时异常),对于运行时异常,java编译器不要求你一定要把它捕获或者一定要继续抛出,但是对checkedexception(检查异常)要求你必须要在方法里面或者捕获或者继续抛出.
问题2:上面的程序将ArithmeticException改为IOException能否编译通过?并说明理由。
解答:不能编译通过。分析:IOException extends
Exception 是属于checked exception,必须进行处理,或者必须捕获或者必须抛出
总结:java中异常分为两类:checked exception(检查异常)和unchecked exception(未检查异常),对于未检查异常也叫RuntimeException(运行时异常).
对未检查的异常(unchecked exception )的几种处理方式:
1、捕获
2、继续抛出
3、不处理
对检查的异常(checked exception,除了RuntimeException,其他的异常都是checked exception )的几种处理方式:
1、继续抛出,消极的方法,一直可以抛到java虚拟机来处理
2、用try...catch捕获
注意,对于检查的异常必须处理,或者必须捕获或者必须抛出
************************************************************************************************************************************************
异常处理(Exception)
1.异常:程序再运行期间发生的不正常事件,它会打断指令的正常流程。
异常都是发生在程序的运行期,编译出现的问题叫语法错误。
2.异常的处理机制:
1)当程序再运行过程中出现了异常,JVM自动创建一个该类型的异常对象。同时把这个异常对象交给运行时系统。(抛出异常)
2)运行时系统接受到一个异常对象时,它会再产生异常的代码附近查找相应的处理方式。
3)异常的处理方式有两种:
1.捕获并处理:在异常的代码附近显示用try/catch进行处理(不合理),运行时系统捕获后会查询相应的catch处理块,再catch处理块中对该异常进行处理。
2.查看发生异常的方法是否有向上声明异常,有向上声明,向上级查询处理语句,如果没有向上声明,JVM中断程序的运行并处理。用throws向外声明(合理的处理方法)
3.异常的分类:
java.lang.Throwable
|-- Error错误:JVM内部的严重问题。无法恢复。程序人员不用处理。
|--Exception异常:普通的问题。通过合理的处理,程序还可以回到正常执行流程。要求编程人员要进行处理。
|--RuntimeException:也叫非受检异常(unchecked
exception).这类异常是编程人员的逻辑问题。应该承担责任。Java编译器不进行强制要求处理。 也就是说,这类异常再程序中,可以进行处理,也可以不处理。
|--非RuntimeException:也叫受检异常(checked exception).这类异常是由一些外部的偶然因素所引起的。Java编译器强制要求处理。也就是说,程序必须进行对这类异常进行处理。
4.常见异常:
1)非受检的:NullPointerException(空指针异常),ClassCastException(类型转换),ArrayIndexsOutOfBoundsException(数组下标越界),ArithmeticException(算术异常,除0溢出)
2)受检:Exception,FileNotFoundException,IOException,SQLException.
注意:异常和错误的区别:异常能被程序本身可以处理,错误是无法处理。
通常,Java的异常(包括Exception和Error)分为可查的异常(checked exceptions)和不可查的异常(unchecked exceptions)。
可查异常(编译器要求必须处置的异常):正确的程序在运行中,很容易出现的、情理可容的异常状况。可查异常虽然是异常状况,但在一定程度上它的发生是可以预计的,而且一旦发生这种异常状况,就必须采取某种方式进行处理。
除了RuntimeException及其子类以外,其他的Exception类及其子类都属于可查异常。这种异常的特点是Java编译器会检查它,也就是说,当程序中可能出现这类异常,要么用try-catch语句捕获它,要么用throws子句声明抛出它,否则编译不会通过。
不可查异常(编译器不要求强制处置的异常):包括运行时异常(RuntimeException与其子类)和错误(Error)。
Exception 这种异常分两大类运行时异常和非运行时异常(编译异常)。程序中应当尽可能去处理这些异常。
运行时异常:都是RuntimeException类及其子类异常,如NullPointerException(空指针异常)、IndexOutOfBoundsException(下标越界异常)等,这些异常是不检查异常,程序中可以选择捕获处理,也可以不处理。这些异常一般是由程序逻辑错误引起的,程序应该从逻辑角度尽可能避免这类异常的发生。
运行时异常的特点是Java编译器不会检查它,也就是说,当程序中可能出现这类异常,即使没有用try-catch语句捕获它,也没有用throws子句声明抛出它,也会编译通过。
非运行时异常 (编译异常):是RuntimeException以外的异常,类型上都属于Exception类及其子类。从程序语法角度讲是必须进行处理的异常,如果不处理,程序就不能编译通过。如IOException、SQLException等以及用户自定义的Exception异常,一般情况下不自定义检查异常。
在 Java 应用程序中,异常处理机制为:抛出异常,捕捉异常。
1. throws抛出异常
如果一个方法可能会出现异常,但没有能力处理这种异常,可以在方法声明处用throws子句来声明抛出异常。例如汽车在运行时可能会出现故障,汽车本身没办法处理这个故障,那就让开车的人来处理。
throws语句用在方法定义时声明该方法要抛出的异常类型,如果抛出的是Exception异常类型,则该方法被声明为抛出所有的异常。多个异常可使用逗号分割。throws语句的语法格式为:
[java] view plain copy
- methodname throws Exception1,Exception2,..,ExceptionN
- {
- }
方法名后的throws Exception1,Exception2,...,ExceptionN 为声明要抛出的异常列表。当方法抛出异常列表的异常时,方法将不对这些类型及其子类类型的异常作处理,而抛向调用该方法的方法,由他去处理。例如:
[java] view plain copy
- import java.lang.Exception;
- public class TestException {
- static void pop() throws NegativeArraySizeException {
- // 定义方法并抛出NegativeArraySizeException异常
- int[] arr = new int[-3]; // 创建数组
- }
- public static void main(String[] args) { // 主方法
- try { // try语句处理异常信息
- 10. pop(); // 调用pop()方法
- 11. } catch (NegativeArraySizeException e) {
- 12. System.out.println("pop()方法抛出的异常");// 输出异常信息
- 13. }
- 14. }
- 15.
16. }
使用throws关键字将异常抛给调用者后,如果调用者不想处理该异常,可以继续向上抛出,但最终要有能够处理该异常的调用者。
pop方法没有处理异常NegativeArraySizeException,而是由main函数来处理。
Throws抛出异常的规则:
1) 如果是不可查异常(unchecked exception),即Error、RuntimeException或它们的子类,那么可以不使用throws关键字来声明要抛出的异常,编译仍能顺利通过,但在运行时会被系统抛出。
2)必须声明方法可抛出的任何可查异常(checked exception)。即如果一个方法可能出现受可查异常,要么用try-catch语句捕获,要么用throws子句声明将它抛出,否则会导致编译错误
3)仅当抛出了异常,该方法的调用者才必须处理或者重新抛出该异常。当方法的调用者无力处理该异常的时候,应该继续抛出,而不是囫囵吞枣。
final,finally,finalize
final
1, 定义变量
2, 定义方法
3, 定义类
1,定义变量,静态和非静态
1) 在定义的时候初始化
2) final变量可以在初始化块中初始化,不可以在静态初始化块中初始化
3) 静态final变量可以在静态初始化块中初始化,不可以在初始代码块中初始化
4) final变量可以在类的构造器中初始化,静态final变量不可以。
用final修饰的变量(常量)比非final的变量(普通变量)拥有更高的效率,因此我们在实际编程中应该尽可能多的用常量来代替普通变量,这也是一个很好的编程习惯。
2,定义方法
final表示这个方法不可以被子类重写,但是它不影响子类继承
4, 定义类
类中的方法默认为final.
final的类的所有方法都不能被重写,但这并不表示final的类的属性(变量)值也是不可改变的,要想做到final类的属性值不可改变,必须给它增加final修饰。
捕获程序抛出的异常之后,既不加处理,也不继续向上抛出异常,并不是良好的编程习惯,它掩盖了程序执行中发生的错误,这里只是方便演示,请不要学习。
return、continue和break都没能阻止finally语句块的执行。从输出的结果来看,return语句似乎在finally语句块之前执行了,事实真的如此吗?我们来想想看,return语句的作用是什么呢?是退出当前的方法,并将值或对象返回。如果finally语句块是在return语句之后执行的,那么return语句被执行后就已经退出当前方法了,finally语句块又如何能被执行呢?因此,正确的执行顺序应该是这样的:编译器在编译return new ReturnClass();时,将它分成了两个步骤,new ReturnClass()和return,前一个创建对象的语句是在finally语句块之前被执行的,而后一个return语句是在finally语句块之后执行的,也就是说finally语句块是在程序退出方法之前被执行的。同样,finally语句块是在循环被跳过(continue)和中断(break)之前被执行的。
finalize()方法是GC运行机制的一部分
finalize()方法是在GC清理它所属的对象时被调用,如果执行它的过程中抛出无法捕获的异常,GC将终止对该对象的清理,并且该异常会被忽略;直到下一次GC开始清理对象时,被再次调用。
第二块:JVM栈
JVM栈是线程私有的,每个线程创建的同时都会创建JVM栈,JVM栈中存放的为当前线程中局部基本类型的变量(java中定义的八种基本类型:boolean、char、byte、short、int、long、float、double)、部分的返回结果以及Stack Frame,非基本类型的对象在JVM栈上仅存放一个指向堆上的地址。
栈(stack)相对整个系统而言,调用栈(Call stack)相对某个进程而言,栈帧(stack frame)则是相对某个函数而言,调用栈就是正在使用的栈空间,由多个嵌套调用函数所使用的栈帧组成
第三块:堆(Heap)
它是JVM用来存储对象实例以及数组值的区域,可以认为Java中所有通过new创建的对象的内存都在此分配,Heap中的对象的内存需要等待GC进行回收。
类的成员变量是和对象一起存放在堆里的,书中说的基本类型变量放在栈中是指方法中的基本类型变量(局部变量)。
第四块:方法区域(Method Area)
(1)在Sun JDK中这块区域对应的为PermanetGeneration,又称为持久代。
(2)方法区域存放了所加载的类的信息(名称、修饰符等)、类中的静态变量(静态区)、类中定义为final类型的常量、类中的Field信息、类中的方法信息,当开发人员在程序中通过Class对象中的getName、isInterface等方法来获取信息时,这些数据都来源于方法区域,同时方法区域也是全局共享的,在一定的条件下它也会被GC,当方法区域需要使用的内存超过其允许的大小时,会抛出OutOfMemory的错误信息。
第五块:运行时常量池(Runtime Constant Pool)
存放的为类中的固定的常量信息、方法和Field的引用信息等,其空间从方法区域中分配。
第六块:本地方法堆栈(Native Method Stacks)
JVM采用本地方法堆栈来支持native方法的执行,此区域用于存储每个native方法调用的状态。
8. JVM垃圾回收
GC (Garbage Collection)的基本原理:将内存中不再被使用的对象进行回收,GC中用于回收的方法称为收集器,由于GC需要消耗一些资源和时间,Java在对对象的生命周期特征进行分析后,按照新生代、旧生代的方式来对对象进行收集,以尽可能的缩短GC对应用造成的暂停
静态变量与非静态变量的区别如下:
1.内存分配
静态变量在应用程序初始化时,就存在于内存当中,直到它所在的类的程序运行结束时才消亡;
而非静态变量需要被实例化后才会分配内存。
2.生存周期
静态变量生存周期为应用程序的存在周期;
非静态变量的存在周期取决于实例化的类的存在周期。
3.调用方式
静态变量只能通过“类.静态变量名”调用,类的实例不能调用;
非静态变量当该变量所在的类被实例化后,可通过实例化的类名直接访问。
4.共享方式
静态变量是全局变量,被所有类的实例对象共享,即一个实例的改变了静态变量的值,其他同类的实例读到的就是变化后的值;
非静态变量是局部变量,不共享的。
5.访问方式
静态成员不能访问非静态成员;
非静态成员可以访问静态成员。

