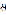LDA详解














PART 1
这个性质被叫做共轭性。共轭先验使得后验概率分布的函数形式与先验概率相同,因此使得贝叶斯分析得到了极⼤的简化。
V:文档集中不重复的词汇的数目
语料库共有m篇文档,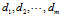 ;
;
对于文档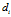 ,由
,由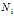 个词汇组成,可重复;
个词汇组成,可重复;
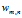 是第m个文档中的第n个词。
是第m个文档中的第n个词。
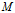 :文档集中文档的总数
:文档集中文档的总数
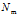 :第m个文档中包含的词汇总数
:第m个文档中包含的词汇总数
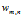 :文档m中第n个词在词典中的序号,属于1到V
:文档m中第n个词在词典中的序号,属于1到V
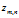 :文档m第n个词汇的主题标号,属于1到k
:文档m第n个词汇的主题标号,属于1到k
 :第k个主题的词汇分布中的参数向量
:第k个主题的词汇分布中的参数向量
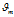 :第m文档的主题分布中的参数向量
:第m文档的主题分布中的参数向量
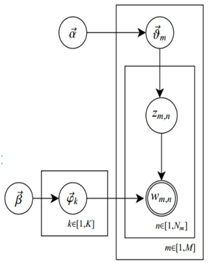
(1) 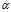 是每个文档下主题的多项式分布的Dirichlet先验参数,
是每个文档下主题的多项式分布的Dirichlet先验参数,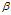 是每个主题下词的多项式分布的Dirichlet先验参数。
是每个主题下词的多项式分布的Dirichlet先验参数。
 一般事先给定,如果取0,1对称的Dirichlet分布,表示在参数学习接收后,期望每篇文档的主题不会十分集中。
一般事先给定,如果取0,1对称的Dirichlet分布,表示在参数学习接收后,期望每篇文档的主题不会十分集中。
(2) 表示第m个文档下的主题分布的分布;
表示第m个文档下的主题分布的分布;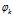 表示第k个主题下的词分布。
表示第k个主题下的词分布。
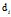 的主题分布是
的主题分布是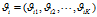 ,是长度为K的向量;
,是长度为K的向量;
对于第i篇文档的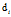 ,在主题分布
,在主题分布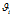 下,可以确定一个具体的主题
下,可以确定一个具体的主题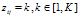 对于第K个主题
对于第K个主题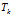 的词分布
的词分布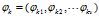 ,是长度为v的向量;
,是长度为v的向量;
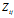 选择
选择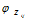 ,表示由词分布
,表示由词分布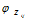 确定词,即得到观测值
确定词,即得到观测值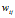 。
。
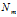 是第m个文档的单词总数。
是第m个文档的单词总数。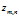 是第m个文档中第n个词的主题
是第m个文档中第n个词的主题
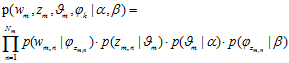
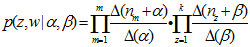
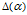 是Dirichlet
是Dirichlet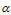 分布的
分布的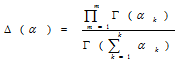
 表示是第 m 篇文档的词汇序列
表示是第 m 篇文档的词汇序列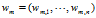
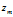 是第 m 篇文档中词汇序列对应的主题序列
是第 m 篇文档中词汇序列对应的主题序列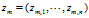
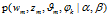 是生成此文档的生成概率
是生成此文档的生成概率
4) 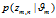 由第 m 篇文章的文档-主题分布
由第 m 篇文章的文档-主题分布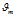 产生第 n 个词汇对应主题的概率;
产生第 n 个词汇对应主题的概率;
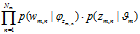 表示由
表示由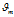 产生第 m 篇文档所有词汇的概率
产生第 m 篇文档所有词汇的概率
Gibbs迭代规则的思想:即不考虑当前词汇的主题分配,据此词汇所在文档的主题分布以及各个主题下词汇分布来计算此词汇被分配到各个主题的概率分布,然后选择以最大概率被分配的主题。
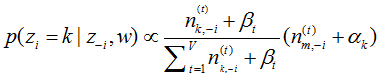
(1)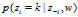 表示排除当前第i个词汇,根据文档集中其他词汇序列的主题分布来计算第i个词汇属于第k个主题的概率
表示排除当前第i个词汇,根据文档集中其他词汇序列的主题分布来计算第i个词汇属于第k个主题的概率
3)t 是第i个词汇对应词汇的字典序列号, 表示排除当前词汇,k个主题中词汇 t 出现次数。
表示排除当前词汇,k个主题中词汇 t 出现次数。
4)m 是当前词汇出现在第 m 篇文档中,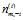 表示排除当前词汇,m 篇文档中出现词汇k的次数。
表示排除当前词汇,m 篇文档中出现词汇k的次数。
当 Gibbs 采样收敛后,跟据每个文档中主题分配次数以及每个主题中词汇分配次数来计算"文档-主题"分布和和"主题-词汇"分布。
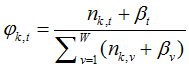
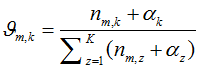
1)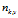 表示标号为v的词语分配到主题 k 的次数,
表示标号为v的词语分配到主题 k 的次数,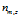 表示文档m 中所有词语分配到主题 z 的个数。
表示文档m 中所有词语分配到主题 z 的个数。
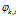 是主题在词汇上分布,式(2-10)中分子的意义是字典中第 t 个词汇分配到主题k下的次数,分母是表示的意义字典中所有词汇被分配到主题k下的次数,
是主题在词汇上分布,式(2-10)中分子的意义是字典中第 t 个词汇分配到主题k下的次数,分母是表示的意义字典中所有词汇被分配到主题k下的次数,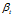 是主题-词汇分布中的先验参数,表示人为认为词汇 t 被分配到主题 k 的次数。所有词汇初始时都是等可能的被分配,以这里都假定
是主题-词汇分布中的先验参数,表示人为认为词汇 t 被分配到主题 k 的次数。所有词汇初始时都是等可能的被分配,以这里都假定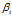 =1。
=1。
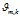 是文档-主题分布,式(2-11)中分子的意义是主题 k 被分配到第 m 篇文档中的次数,分母是表示的意义各个主题被分配到第 m 篇文档中的次数总和,文档m 的长度。
是文档-主题分布,式(2-11)中分子的意义是主题 k 被分配到第 m 篇文档中的次数,分母是表示的意义各个主题被分配到第 m 篇文档中的次数总和,文档m 的长度。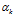 是文档-主题分布中的先验参数,表示主题 k 被分配的次数。所有主题初始时都是等可能的被分配,以这里都假定
是文档-主题分布中的先验参数,表示主题 k 被分配的次数。所有主题初始时都是等可能的被分配,以这里都假定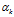 =1
=1
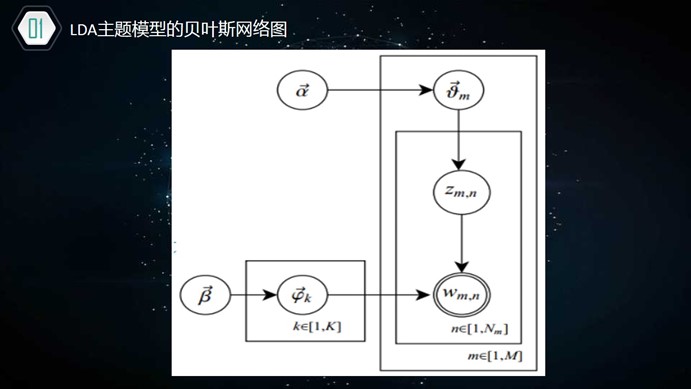
LDA主题模型生成文档语料库的过程如下:(建设生成的语料库包含m篇文档、K个主题)
(1)对于m篇文档,生成"文档-主题"分布。文档主题分布也是一个多项式分布,它的参数服从参数为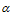 的Dirichlet先验分布。
的Dirichlet先验分布。
(2)获取每个主题下的"主题-词汇"的分布。主题-词汇分布是一个多项式分布,且它的参数变量服从参数为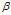 的Dirichlet先验分布。
的Dirichlet先验分布。