


HITS
HITS
1 概述
HITS(hypertext induced topic search)超链接归纳主题搜索是由kleinbers在90年代提出的基于链接分析的网页排名算法。Hits算法是利用HubAuthority的搜索方法,即中心权威的思想。
Hits算法的基本思想:
- 好的中心网页拥有很多的链出链接,这些链接都指向权威网页。
- 好的权威网页拥有很多的链入链接,这些链接都来自中心网页。
即:一个优秀的中心页必然会指向很多优秀的权威页,一个优秀的权威页必然会被很多优秀的中心页指向。
2 网页收集
在算法描述前,先描述HITS算法是如何收集待评级的网页的。HITS将根据如下描述来搜索页面集合:
- 它将搜搜字段q送至搜索引擎系统,然后收集t个排名最高的网页,这些网页都是与查询字段q高度相关的。该集合称为根集W。
- 然后它通过将指向W集合内部的网页或者W集内部网页指向的外部网页加入W集的方式来扩充W。这就得到了一个更大的集合,我们称为集合S,S被称为基本集。然而,这个集合可能相当的大,算需要通过相纸每个W集内部的网页,仅允许它们最多将K个指向自己的网页加入S来限制S集的大小。
接着HITS对S集内部的每张网页进行处理,对每张S集内部的网页指定一个权威分值和中心分值。
3 HITS算法
HITS算法的求解过程如下:
- 收集根集页面
- 将所有根集页面的A(Authority Score)和H(hub Score)赋予初值
- 根据公式计算新一轮的H和A的值
- 规范化结果
- 重复(3)(4),直到结果收敛。
具体操作:
假设待考察的网页数目为n。我们用G=(V,E)来表示S的有向链接图。V是网页集,E是有向边集。我们用L来表示图的邻接矩阵。
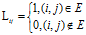
每张网页i的权威分值被表示为a(i),中心分值被表示为h(i)。两种分值的相互增益关系为:
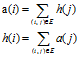
将它们写成矩阵形式,用a表示所有权威分值的列向量, ,
,
用h表示所有中心分值的列向量, ,
,

计算权威分值和中心分值采用幂迭代方法。迭代公式如下:

初始情况如下:
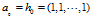
在每次迭代后,数据要进行归一化处理。满足:
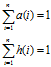
当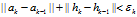 时,停止迭代。
时,停止迭代。
4 HITS算法和PageRank算法比较
相同:
两种算法那都利用了特征向量作为理论基础和收敛基础。这也是超链接环境下此类算法的共同特征。
不同:
- 权值的传播角度:HITS算法是将权威网页的权值经过中心网页的传递进行传播;PageRank算法是将网页的权值直接从权威网页传递给权威网页。
- 算法思想角度:HITS算法的权威值只是相对于某个检索主题的权重;PageRank算法独立于搜索主题
- 处理的数据量及用户端的等待时间角度:HITS算法对所需排序的网页数量需求少,一般为1000到5000,但由于需要从基于内容分析的搜索引擎中提取根集并扩充基本集,耗时长;PageRank算法处理的数据远远多于HITS。
- 从两者处理的对象角度:HITS处理的对象是搜索引擎针对具体查询主题所返回的记过,从几百个页面到几千个页面;PageRank处理的对象是一个搜索引擎上当前搜索下来的所有网页,一般在几千万以上。
- 从具体应用的角度:THIS一般用于全文本所有引擎的客户端,对于宽主题的所有相当有效,可以用于自动编撰万维网分类目录或者元搜索引擎的网页排序;PageRank一般用于搜索引擎的服务端,直接用于标题查询并获得较好的结果。
参考文献:
[1] [1]常庆,周明全,耿国华. 基于PageRank和HITS的Web搜索[J]. 计算机技术与发展,2008,(07):77-79.
[2] http://blog.csdn.net/androidlushangderen/article/details/43311943

