

深度学习概述
强化学习
强化学习能解决的问题:序贯决策问题
序贯决策问题:连续不断的作出决策,才能实现最终目标的问题。
强化学习如何解决问题?
类比,强化学习和监督学习的异同点:
共同点:两者都需要大量的数据进行训练
不同点:两者所需的数据类型不同。监督学习需要的是多样化的标签数据,强化学习需要的是带有回报的交互数据。
由于输入的数据类型不同,这使得强化学习算法有他自己的获取数据,利用数据的独特方法。
强化学习的分类:
-
根据是否依赖模型,分为:基于模型和无模型的
-
根据策略的更新,分类:基于值函数的强化学习,基于直接策略的搜索,AC方法(联合前两种)
值函数:值函数最大的动作为最策略
直接策略:是将策略参数化,实现目标最优参数
-
根据环境返回的回报函数是否已知,分为正向强化学习和逆向强化学习。回报函数指定的强化学习算法称为正向强化学习。
机器学习分为监督、无监督和强化学习。
eg:基于深度强化学习的对话生成。
参考《推荐系统与深度学习》2.2.4节
深度学习
-
网络参数的初始化
深度学习的模型参数都是采用梯度下降算法来更新的,本质上,它是一种迭代更新算法,需要在迭代更新前对每个参数进行初始化。选择合适的方法初始化网络参数十分重要。
初始化网络参数的几种方法,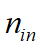 为如数神经元数量,
为如数神经元数量,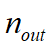 为输出神经元数量。
为输出神经元数量。
例如:Relu激活函数,权重的初始化。
链接:https://blog.csdn.net/u014157632/article/details/78206970
高斯分布初始化:
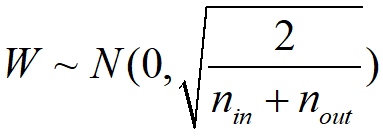
均匀分布初始化:
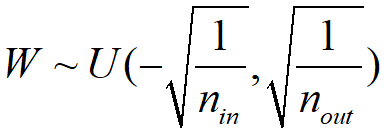
Xavier初始化
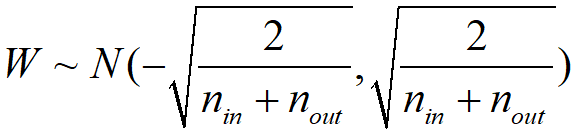
-
学习率的选择
除了网络参数初始化问题,选择合适的学习率也十分重要。
1)模拟退火算法
深度网络通常采用模拟退火算法在训练期间动态调整学习率。
包括反向衰减学习率和指数衰减学习率:
反向衰减学习率:初始学习率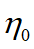 ,
,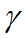 为衰减系数,t为迭代次数
为衰减系数,t为迭代次数
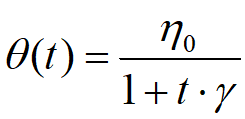
指数衰减学习率:
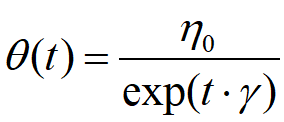
固定衰减的模拟退火方法不能直接泛化到多个数据集上,为了不希望采用相同的评率和步长更新所有的网路参数,可自适应调整学习率Adadelta被提出。
2)动量方法
动量方法采用累计梯度来替代当前时刻的梯度,直观上说,动量方法类似于把球推下山,球在下坡时积累动力,在途中速度会变得越来越快。动量方法可以快速地收敛并减少目标函数的震荡。
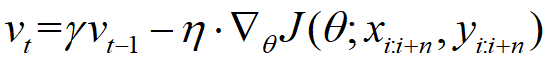
动量参数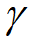 通常设置成0.9,
通常设置成0.9, 是梯度更新的步长。
是梯度更新的步长。
-
RMsprop
该方法可以自适应调整每个参数的学习率,可以克服学习率过早衰减问题。
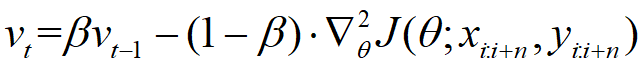
 是衰减系数,通常为0.9
是衰减系数,通常为0.9
梯度更新公式:

-
自适应矩估计
该方法可以自适应的调整每个参数的学习率,可以看成是动量方法和RMSprop的结合。

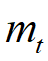 和
和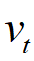 分别是梯度一阶矩(均值)和二阶矩(方差)的估计。
分别是梯度一阶矩(均值)和二阶矩(方差)的估计。
卷积神经网络
特点:
1)第L+1层神经元和第L层的局部区域相连接,该区域执行卷积操作和非线性变换生成L+1层神经元。
2)整个网络可以表示成可微分的端到端函数f(x),卷积网络通过损失函数,比如交叉熵来优化网络参数。
3)CNN具有更少的参数,可以有效地训练非常深的架构。
卷积神经网络的图层可以分成三种类型、卷积层,池化层和全连接层。
卷积层:
用来提取局部区域的特征。卷积层有多种不同的卷积核,局部区域和这些卷积核经过卷积运算生成不同的特征。不同的卷积核可以看成不同的特征提取器。
池化层:
子采样层,被用在连接的卷积层之间,类似于特征选择的功能,其作用是减少特征和参数数量,减少网络计算量,从而控制过拟合。
池化方式分为:最大池化和平均池化
常见的网络结构:
LetNet-5,AlexNet,VGGNet,ResNet
循环神经网络
循环神经网络是序列模式的一个变体。序列模型包括隐藏状态,隐藏状态保存序列在每个时刻的动态性,所以它会根据不同时刻的动态变化预测下一个结果。
RNN的目标函数,通过最大似然或最小化负对数似然估计模型。
-
如果梯度消失,可以采用把RNN的
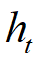 更新方式改成累加模型。
更新方式改成累加模型。 -
如果帝都爆炸,可以采用梯度截断来解决。
对于梯度消失和梯度爆炸问题,LSTM可以进行解决。
生成对抗网络
GAN包括生成器G和判别器D。
模型训练判别器D以最大化将正确标签分配给训练样本和来自生成器G的样本的概率。
同时以最小化log(1-D(G(z))为训练目标,从而得到生成器G。判别器和生成器在博弈一个最大最小问题。
常见的生成对抗网络:
-
CGAN(conditional GAN),给图像生成加上额外的条件,改进CycleGAN,DualGAN
-
DCGAN(deep convolutional generative Adversarial Networks)采用深度卷积网络作为生成器和判别器的基础组件,改进StackGAN.
-
WGAN(wasserstein距离)
Wasserstein距离作为一种在D区域上两个概率分布距离的度量,又名Earth-Mover距离,用于衡量两个分布之间的距离。
WGAN提出新的距离度量函数,使得GAN的稳定性,鲁棒性更好。
-
SeqGAN
SeqGAN利用增强学习来解决生成离散数据时不可导的问题,生成器通过生成完整的句子再获得判别器的奖励以更新生成器,这种增强学习方式为GAN生成离散文本序列的训练提供了可能性,使得GAN在NLP上得以应用。
Texygen平台,Pix2pix项目。
常见的深度学习框架
TensorFlow:谷歌开发,人工智能学习系统
Keras;极简主义
Caffe:计算机视觉
Theano:适合数值计算优化
MXNet:亚马逊开发
Torch:Facebook,lua编程
pyTorch:动态图模型,caffz并入
DL4J:支持Java,Scala
Cognitive-toolkit:微软开发
Lasagne:在Theano基础上开发
DSSTNE:致力于推荐系统框架
ONNX(open neural network exchange)开源人工智能项目
TensorFlow
"Tensor"(张量)意味着N维数组
"Flow"(流)意味着数据流图的计算
TensorFlow为张量从数据流图的一端流动到另一端的计算过程。
TensorFlow中用于构建计算的方式是数据流图。数据流图由节点和边组成,其中,节点代表数值操作(比如加法,乘法,卷积和池化),边代表流动的张量。一次计算由输入节点开始,产生的张量在图中流动,经过不同操作节点时进行各种数值计算,最后产生张量结果输出。
TensorFlow是将复杂的数据结果传输至人工智能神经网络中进行分析和处理的系统。
TensorFlow不是一个严格的神经网络库,只要你可以将计算表示为数据流图,就可以使用Tensorflow。你通过构建图,描写驱动计算的内部循环,Tensorflow就可以提供有用的工具帮你组装子图,当然用户也可以在Tensorflow上写自己的上层库。
