

2-1如何在列表、字典、集合中根据条件筛选数据
2-1-1要实现的功能有:
1、过滤掉列表中[1,5,-3,-2,6,8,9]的负数
2、筛出字典中值高于90的项
3、筛选出集合中能被3整除的元素


最通用的做法就是迭代,如:

>>> data = [1,5,-3,-2,6,8,9] >>> res = [] #建立空列表,用于存储筛选出的值 >>> for x in data: if x>= 0: res.append(x) #逐项迭代原列表中的元素,符合条件的增加到新列表中 >>> res [1, 5, 6, 8, 9] >>> data [1, 5, -3, -2, 6, 8, 9] >>>
简洁高效方案:
列表: filter函数: filter(lamda x :x>=0, data)
列表解析(列表生成式、列表推导式):[x for x in data if x>0]
字典: 字典解析:{k:v for k,v in d.iteritems() if v>90
集合:集合解析:{x for x in s if x%3 == 0}
2-1-2、具体实现方法
2-1-2-1列表过滤
1、实现方法
>>> from random import randint >>> data = [randint(-10,10) for _ in xrange(10)] #随机生成-10到10的整数的10个元素的列表 >>> data [-2, -1, 1, -6, 8, -5, 8, 2, 3, -10]
(1)使用filter函数
>>> newdata = filter(lambda x:x>=0,data) >>> newdata [1, 8, 8, 2, 3]
(2)使用列表解析
>>> newdata = [x for x in data if x>=0] >>> newdata [1, 8, 8, 2, 3]
2扩展说明:
2.1列表生成式相于普通的语句:
>>> data = [-1, 0,2,-3,4,5] >>> [x for x in data if x>0] [2, 4, 5] >>> L=[] >>> for x in data: if x>0: L.append(x) >>> L [2, 4, 5]
2.2使用timeit模块测试时间
在py2中列表解析效率比filter函数要快近一倍。
>>> t1 = timeit.Timer('list(filter(lambda x:x>0,[10, 0, 1, 2, 9, -3, -10, -4, 0, -8]))') >>> print(t1.timeit()) 1.69277145874 >>> t2 = timeit.Timer("[x for x in [10, 0, 1, 2, 9, -3, -10, -4, 0, -8] if x>0]") >>> t2.timeit() 0.5856884314145816
2.3注意
1、filter函数在py3,返回的是个生成式(迭代器)。
filter与列表解析的比较:
在py2使用列表生成式效率高,在py3使用filter过滤器会效率高
2、在py2中range()返回列表 ,xrange()返回的是个生成式(迭代器),在py3中没有了xrang()函数,range()即实现了py2中的xrange()功能。
3、两种方式都速度都远快于普通的迭代方式。
2.4filter()函数说明:
>>> help(filter)
Help on built-in function filter in module __builtin__:
filter(...)
filter(function or None, sequence) -> list, tuple, or string
Return those items of sequence for which function(item) is true. If
function is None, return the items that are true. If sequence is a tuple
or string, return the same type, else return a list.
filter()函数是 Python 内置的另一个有用的高阶函数,filter()函数接收一个函数 f 和一个list,这个函数 f 的作用是对每个元素进行判断,返回 True或 False,filter()根据判断结果自动过滤掉不符合条件的元素,返回由符合条件元素组成的新list。
例如,要从一个list [1, 4, 6, 7, 9, 12, 17]中删除偶数,保留奇数,首先,要编写一个判断奇数的函数:
def is_odd(x): return x % 2 == 1
然后,利用filter()过滤掉偶数:
>>>filter(is_odd, [1, 4, 6, 7, 9, 12, 17])
结果:
[1, 7, 9, 17]
利用filter(),可以完成很多有用的功能,例如,删除 None 或者空字符串:
def is_not_empty(s): return s and len(s.strip()) > 0 >>>filter(is_not_empty, ['test', None, '', 'str', ' ', 'END'])
结果:
['test', 'str', 'END']
2.4.1 str.strip()简要说明
>>> help(str.strip)
Help on method_descriptor:
strip(...)
S.strip([chars]) -> string or unicode
Return a copy of the string S with leading and trailing
whitespace removed.
If chars is given and not None, remove characters in chars instead.
If chars is unicode, S will be converted to unicode before stripping
注意: s.strip(rm) 删除 s 字符串中开头、结尾处的 rm 序列的字符。
当rm为空时,默认删除空白符(包括'\n', '\r', '\t', ' '),如下:
>>> a = ' 123' >>> a.strip() '123' >>> a = '\t\t123\r\n' >>> a.strip() '123'
备注:python中filter()函数引用http://www.cnblogs.com/Lambda721/p/6128424.html
2.5Lambda用法
Lambda是一个表达式,也可以说它是一个匿名函数。
表达式及定义
lambda [ arg1 [arg2, arg3, … argN] ] : expression
– 《Python核心编程》
从《Python核心编程》书本中包含了以上lambda表达式的表述。也就是说在lambda右侧的式子中,冒号左边的为参数值,右边的为计算表达式。
现在假设需要对两个数进行求和运算。对于正常的逻辑代码,不难写出如下代码:
def sum(x, y):
return x + y
而在lambda中,我们可以这样来写:
p = lambda x, y: x + y
代码简洁了许多,可是因为缺少方法名对此步操作进行描述,也让我们对这个求和的Lambda表达式有一些疑问,也就是它在程序中目的是什么,我们难以揣测。
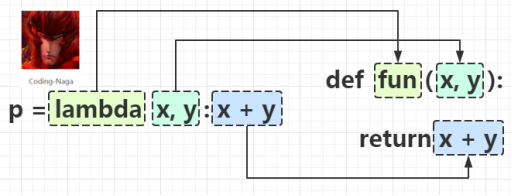
备注:引自http://blog.csdn.net/lemon_tree12138/article/details/50774827
Lambda表达式是Python中一类特殊的定义函数的形式,使用它可以定义一个匿名函数。与其它语言不同,Python的Lambda表达式的函数体只能有唯一的一条语句,也就是返回值表达式语句。其语法如下:
lambda 形参列表 : 函数返回值表达式语句
下面是个Lambda表达式的例子:
#!/usr/bin/envpython li=[{"age":20,"name":"def"},{"age":25,"name":"abc"},{"age":10,"name":"ghi"}] li=sorted(li,key=lambda x:x["age"]) print(li)
如果不用Lambda表达式,而要写成常规的函数,那么需要这么写:
#!/usr/bin/envpython def comp(x): return x["age"] li=[{"age":20,"name":"def"},{"age":25,"name":"abc"},{"age":10,"name":"ghi"}] li=sorted(li,key=comp) print(li)
C#、java、C++(ISO C++ 11)也含有该表达式。
备注:引自:百度百科
2.5.1 sorted()和list.sort()用法比较
>>> help(sorted)
Help on built-in function sorted in module __builtin__:
sorted(...)
sorted(iterable, cmp=None, key=None, reverse=False) --> new sorted list
>>> help(list.sort)
Help on method_descriptor:
sort(...)
L.sort(cmp=None, key=None, reverse=False) -- stable sort *IN PLACE*;
cmp(x, y) -> -1, 0, 1
对给定的List L进行排序,Python提供了两个方法
方法1.用List的成员函数sort进行排序
方法2.用built-in函数sorted进行排序(从2.4开始)
sorted()函数
iterable:是可迭代类型;
cmp:用于比较的函数,比较什么由key决定,有默认值,迭代集合中的一项;
key:用列表元素的某个属性和函数进行作为关键字,有默认值,迭代集合中的一项;
返回值:是一个经过排序的可迭代类型,与iterable一样。
注:一般来说,cmp和key可以使用lambda表达式。
List的sort()函数与sorted()的不同在于,sort是在原位重新排列列表,而sorted()是产生一个新的列表。
Sorting basic: >>> print sorted([5, 2, 3, 1, 4]) [1, 2, 3, 4, 5] >>> L = [5, 2, 3, 1, 4] >>> L.sort() >>> print L [1, 2, 3, 4, 5] Sorting cmp: >>>L = [('b',2),('a',1),('c',3),('d',4)] >>>print sorted(L, cmp=lambda x,y:cmp(x[1],y[1])) [('a', 1), ('b', 2), ('c', 3), ('d', 4)]
Lambda参数x和y 是两个参数,表达式中x[1]和y[1]是x和y第1个参数(从0左始)。就是对x[1]和y[1]比较大小。
Sorting keys: >>>L = [('b',2),('a',1),('c',3),('d',4)] >>>print sorted(L, key=lambda x:x[1])) [('a', 1), ('b', 2), ('c', 3), ('d', 4)] >>> L = [("u",1),(1,5),([25,33],4),({"j":1},6)] >>> newl = sorted(L,key = lambda x:x[1]) >>> newl [('u', 1), ([25, 33], 4), (1, 5), ({'j': 1}, 6)] Sorting reverse: >>> print sorted([5, 2, 3, 1, 4], reverse=True) [5, 4, 3, 2, 1] >>> print sorted([5, 2, 3, 1, 4], reverse=False) [1, 2, 3, 4, 5]
注:效率key>cmp(key比cmp快)
在Sorting Keys中:我们看到,此时排序过的L是仅仅按照第二个关键字来排的,如果我们想用第二个关键字
排过序后再用第一个关键字进行排序呢?
>>> L = [('d',2),('a',4),('b',3),('c',2)] >>> print sorted(L, key=lambda x:(x[1],x[0])) >>>[('c', 2), ('d', 2), ('b', 3), ('a', 4)] >>> L = [("d",1),("d",2),("c",5),("c",2),("u",2),("u",7)] >>> newl = sorted(L,key = lambda x:x[1]) >>> newl [('d', 1), ('d', 2), ('c', 2), ('u', 2), ('c', 5), ('u', 7)]
这里的从第二和第三个元组的第一个元素可以看出 d在c的前面
>>> new2 = sorted(L,key = lambda x:(x[1],x[0])) >>> new2 [('d', 1), ('c', 2), ('d', 2), ('u', 2), ('c', 5), ('u', 7)]
这里从第二和第三个元组的第一个元素可以看出,c在d前面了。
注:引自:http://www.cnblogs.com/65702708/archive/2010/09/14/1826362.html
2.6timeit 模块
- timeit 模块定义了接受两个参数的 Timer 类。两个参数都是字符串。 第一个参数是你要计时的语句或者函数。 传递给 Timer 的第二个参数是为第一个参数语句构建环境的导入语句。 从内部讲, timeit 构建起一个独立的虚拟环境, 手工地执行建立语句,然后手工地编译和执行被计时语句。
- 一旦有了 Timer 对象,最简单的事就是调用 timeit(),它接受一个参数为每个测试中调用被计时语句的次数,默认为一百万次;返回所耗费的秒数。
- Timer 对象的另一个主要方法是 repeat(), 它接受两个可选参数。 第一个参数是重复整个测试的次数,第二个参数是每个测试中调用被计时语句的次数。 两个参数都是可选的,它们的默认值分别是 3 和1000000。 repeat() 方法返回以秒记录的每个测试循环的耗时列表。Python 有一个方便的 min 函数可以把输入的列表返回成最小值,如: min(t.repeat(3, 1000000))
- 你可以在命令行使用 timeit 模块来测试一个已存在的 Python 程序,而不需要修改代码。
- 具体可参见文档:python3文档 http://docs.python.org/library/timeit.html
- Python2文档https://docs.python.org/2.7/library/timeit.html
使用方法如本例中:
>>> t1 = timeit.Timer('list(filter(lambda x:x>0,[10, 0, 1, 2, 9, -3, -10, -4, 0, -8]))') >>> print(t1.timeit()) 1.69277145874 >>> t2 = timeit.Timer("[x for x in [10, 0, 1, 2, 9, -3, -10, -4, 0, -8] if x>0]") >>> t2.timeit() 0.5856884314145816
在python2.7中Timer参数没有globals参数
>>> from timeit >>> data = [10,0,1,2,-3,-8] >>> t3 = timeit.Timer("[x for x in data if x>0]",setup='data = "data"') >>> t3.timeit() 0.736482371831471
读官方文档真的很重要,本例就是通过查看官方文档的方法,实验成功。
2.6 列表相关知识
2.6.1列表的append()方法
append(...) L.append(object) -- append object to end >>> L = [1,2,3] >>> L.append([3,4,5]) >>> L [1, 2, 3, [3, 4, 5]]
2.6.2列表的extend()方法
extend(...) L.extend(iterable) -- extend list by appending elements from the iterable >>> L = [1,2,3] >>> L.extend([3,4,5]) >>> L [1, 2, 3, 3, 4, 5] >>> t = [1,2,3] >>> t.extend("890") >>> t [1, 2, 3, '8', '9', '0']
2.6.3列表的pop()方法
pop(...) L.pop([index]) -> item -- remove and return item at index (default last). Raises IndexError if list is empty or index is out of range. >>> L = [1,2,3,4,6] >>> L.pop() 6 >>> L [1, 2, 3, 4] >>> L = [1,2,3,4,5] >>> L.pop(1) 2 >>> L [1, 3, 4, 5]
2.6.4列表的insert()方法
insert(...) L.insert(index, object) -- insert object before index >>> L = [1,2,3,4,5] >>> L.insert(6) Traceback (most recent call last): File "<pyshell#16>", line 1, in <module> L.insert(6) TypeError: insert() takes exactly 2 arguments (1 given)
提示函数应有两个参数,现在只传了一个
>>> L.insert(6,9) >>> L [1, 2, 3, 4, 5, 9] >>> L.insert(0,10) >>> L [10, 1, 2, 3, 4, 5, 9] >>> L.insert(11,20) >>> L [10, 1, 2, 3, 4, 5, 9, 20]
可以看出当给出的要插入的序号大于列表的长度,把要插入的元素放在列表尾
>>> L.insert(-1,50) >>> L [10, 1, 2, 3, 4, 5, 9, 50, 20]
索引-1原来是列表的第7位,那么插入也是插入的第7位,也就是原来的最后一位,现在仍然是最后一位,新插入的在倒数第二位
>>> L.insert(-20,66) >>> L [66, 10, 1, 2, 3, 4, 5, 9, 50, 100, 20]
当传入的索引在第一个元素之前,那么新插入的值就插在列表首
>>> L = [1,2,3] >>> L.insert(1,[3,4,5]) >>> L [1, [3, 4, 5], 2, 3]
2.6.5列表的remove()方法
| remove(...) | L.remove(value) -- remove first occurrence of value. | Raises ValueError if the value is not present. >>> L = [1,2,3,4,5] >>> L.remove(8) Traceback (most recent call last): File "<pyshell#37>", line 1, in <module> L.remove(8) ValueError: list.remove(x): x not in list
remove()参数是列表中的元素,而不是索引,当要删除的元素,列表中不存在时,抛出异常
>>> L.remove(3) >>> L [1, 2, 4, 5]
2.6.6列表的count()方法
| count(...) | L.count(value) -> integer -- return number of occurrences of value >>> L = ["abc","bbb","c","dd","dd"] >>> L.count("abc") 1 >>> L.count("c") 1 >>> L.count("dd") 2
2.6.7列表的index()方法
| index(...)
| L.index(value, [start, [stop]]) -> integer -- return first index of value.
| Raises ValueError if the value is not present.
返回元素的序号索引
>>> L = ['a','c','d','a','b','e','a','u'] >>> L.index('a') 0 >>> L.index('a',1) 3 >>> L.index('a',0) 0 >>> L.index('a',4,-1) 6
2.6.8列表的reverse()方法
| reverse(...)
| L.reverse() -- reverse *IN PLACE*
队列元素反序
>>> L = [1,3,2] >>> L.reverse() >>> L [2, 3, 1]
列表的sort方法和sorted()方法中的参数reverse=True时也是对列表排完序后再反序。
2.6.6 del()方法
L = [1,2,4,5] >>> del(L[2]) >>> L [1, 2, 5] >>> del(L) >>> L Traceback (most recent call last): File "<pyshell#45>", line 1, in <module> L NameError: name 'L' is not defined
del(L)是把L对象(列表类的一个实例,也就是一个列表,Python一切皆是对象)从内存中清除,再次使用L时会抛出异常
2-1-2-2字典过滤
1、实现方法
>>> from random import randint >>> D = {x : randint(60,100) for x in xrange(1,21)} #创建学号为1到20的学生成绩为60到100的随机成绩的字典 >>> D {1: 63, 2: 63, 3: 85, 4: 98, 5: 71, 6: 68, 7: 75, 8: 94, 9: 93, 10: 99, 11: 71, 12: 85, 13: 70, 14: 65, 15: 81, 16: 91, 17: 93, 18: 100, 19: 66, 20: 63}
(1)使用字典解析
>>> {k:v for k,v in D.iteritems() if v>90}
{4: 98, 8: 94, 9: 93, 10: 99, 16: 91, 17: 93, 18: 100}
>>> {k:v for k,v in D.iteritems() if v>90} #要生成字典,所以要键和值,一起迭代,要作用字典的D.iteritems()
{4: 98, 8: 94, 9: 93, 10: 99, 16: 91, 17: 93, 18: 100}
>>>
2字典扩展知识
2.1根据键获取值
2.1.1


>>> d = {'Michael': 95, 'Bob': 75, 'Tracy': 85}
>>> d["Bob"]
75
>>> d["kobe"] #当字典中没有此键时,会抛出异常
Traceback (most recent call last):
File "<pyshell#36>", line 1, in <module>
d["kobe"]
KeyError: 'kobe'
2.1.2 通过dict提供的get方法,如果key不存在,可以返回None,或者自己指定的value:
>>> d.get("Tracy") 85 >>> d.get('thomas') >>> d.get('thomas',-1) -1 >>>
2.1.3 删除字典键值
>>> d.pop('Michael') 95 >>>d {'Bob': 75, 'Tracy': 85}
请务必注意,dict内部存放的顺序和key放入的顺序是没有关系的。
和list比较,dict有以下几个特点:
查找和插入的速度极快,不会随着key的增加而变慢;
需要占用大量的内存,内存浪费多。
而list相反:
查找和插入的时间随着元素的增加而增加;
占用空间小,浪费内存很少。
所以,dict是用空间来换取时间的一种方法。
需要牢记的第一条就是dict的key必须是不可变对象。
这是因为dict根据key来计算value的存储位置,如果每次计算相同的key得出的结果不同,那dict内部就完全混乱了。这个通过key计算位置的算法称为哈希算法(Hash)。
要保证hash的正确性,作为key的对象就不能变。在Python中,字符串、整数等都是不可变的,因此,可以放心地作为key。而list是可变的,就不能作为key:
2-1-2-3集合过滤
1、使用集合生成式
>>> data = [1,2,1,2,-3,5,6,9,9] >>> setData = set(data) >>> setData set([1, 2, 5, 6, 9, -3]) >>> {x for x in setData if x%3 ==0} set([9, -3, 6]) >>> newSetData = {x for x in setData if x%3 ==0} >>> newSetData set([9, -3, 6])
2、集合扩展知识
2.1将列表变成集合
>>> s = set([1, 1, 2, 2, 3, 3]) >>> s set([1, 2, 3])
注:集合是无序的。在py3中输出{1,2,3}
2.2.集合中增加元素
>>> s.add(4) >>> s set([1, 2, 3, 4])
2.3集合中删除指定元素
>>> s.remove(3) >>> s set([1, 2, 4]) >>>
posted on 2018-02-07 14:32 石中玉smulngy 阅读(817) 评论(0) 编辑 收藏 举报


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步