Java:集合体系
(还有好多没补充)
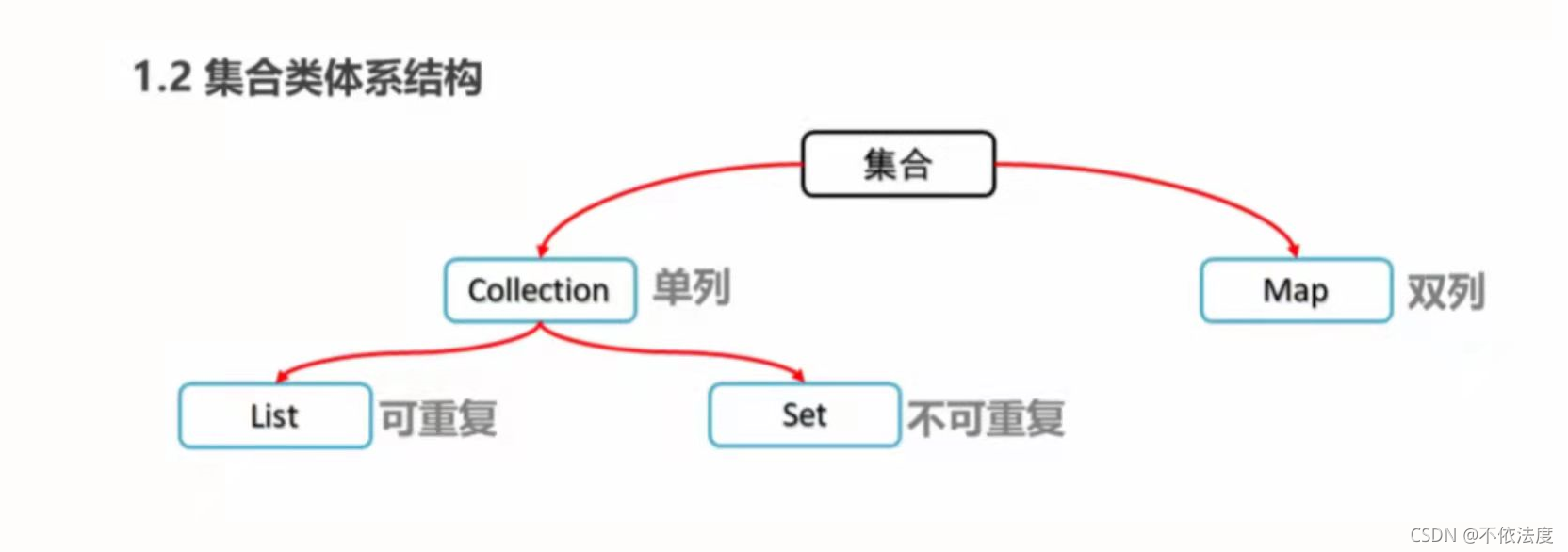
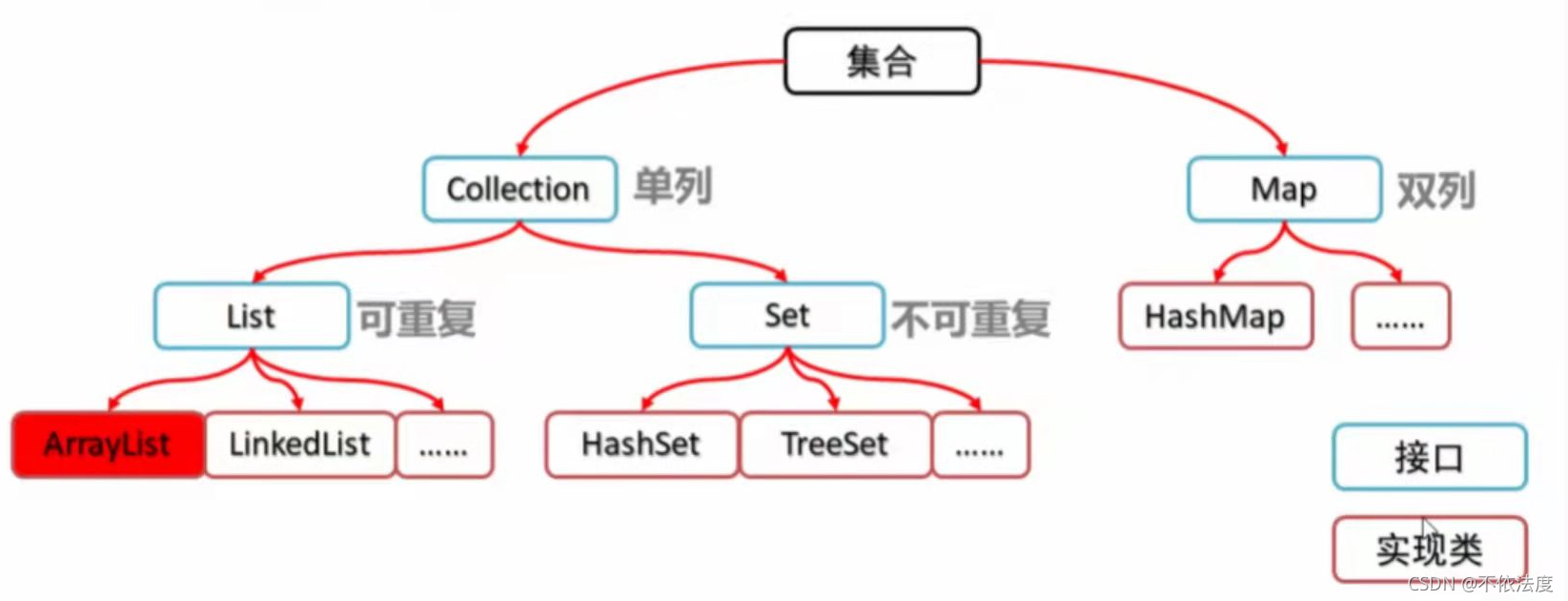
集合体系
迭代器
概述
所有实现了collection接口的集合类都有一个iterator()方法,用以返回一个实现了迭代器的实现类对象
迭代器就是专门取出集合元素的对象,类型数组的下标。Collection接口中定义了获取集合类迭代器的方法iterator(),所以所有的Collection体系集合都可以获取自身的迭代器。
先区分Iterator和iterator
iterator迭代器,是一个接口,我们无法直接使用,使用集合中的方法 iterator()获取迭代器的实现类对象,使用Iterator接口接收(多态)iterator接口的实现类对象。
迭代器的实现类对迭代器进行了方法重写(不知道,还没看源码)
如何获取迭代器
Iterator<Type> iterator = 集合名.iterator();
Interface Iterator接口的方法
import java.util.Iterator; // 引入 Iterator 类
hasNext() next()
(这块关于next的解释感觉不太对,后面会说)
调用 it.next() 会返回迭代器的下一个元素,并且更新迭代器的状态。
Iterator<String> iterator=list.iterator();
// [hello, world, java, hello]
while(iterator.hasNext()){
// hasNext() boolean类型,如果迭代任具有元素,则返回 true
String str=iterator.next();
// next() 返回迭代中的下一个元素。
System.out.println(str);
}
}
}
remove():注意!没有返回值。remove是迭代器的方法,所有是迭代器名.remove()
System.out.println(list);
// [hello, world, java, hello]
Iterator<String>iterator=list.iterator();
while (iterator.hasNext()){
String str=iterator.next();
if(str.equals("world"))
iterator.remove();
}
System.out.println(list);
// [hello, java, hello]
关于hasNext和next
我觉得这个得说一下,看了源码以后觉得和给出的解释不太一样
hasNext()的源码:
public boolean hasNext() {
return cursor != size; }
cursor当作元素下标 (差不多意思)
根据源码应该理解为判断当前元素下标是否等于size,也就是是否到尾巴了,等于返回false,佛则返回true
而不应该是到达当前元素是否还有剩余元素,按这样理解到达最后一个元素就没有剩余元素了,hasNext直接false了,那末尾元素怎么办?
下标范围[0,size-1]
根据下面的next源码,是先用i标记当前元素的下标,然后把下标cursor变成i+1,返回的是下标为i的元素(当前元素)
那么当next返回的是集合的最后一个元素,cursor也就是集合.size,返回false,结束遍历
next()的源码
public E next() {
checkForComodification();
int i = cursor;
// 标记当前元素的下标
if (i >= size)
throw new NoSuchElementException();
Object[] elementData = ArrayList.this.elementData;
//把集合元素放入数组
if (i >= elementData.length)
throw new ConcurrentModificationException();
cursor = i + 1;
//将下标后移一位,也就是迭代器边取值变移动到下一位的关键
return (E) elementData[lastRet = i];
//i 存储的是游标cursor改变之前的值
}
这样看来next也不是返回迭代器的下一个元素
所有我认为这里的next不是下一个的意思,而是类似c语言的指针,一个指向的作用
总结:
hasNext():判断当前指向元素是否为空
next():返回当前指向元素
Collections
Map和HashMap
Map<Type,Type> map = new HashMap<Type,Type>()//多态的写法
HashMap<Type,Type> hashMap=new HashMap<Type,Type>()
先放出来:HashMap和Map
相同:
1.一次存储两个对象,一个键对象,一个值对象
2、键对象在集合中是唯一的,可以通过键来查找值
HashMap
1.HashMap是用哈希表(直接一点可以说数组加单链表)+红黑树实现的map类,HashMap的这种特殊存储结构在获取指定元素前需要把key经过哈希运算,得到目标元素在哈希表中的位置,然后再进行少量比较即可得到元素,这使得 HashMap 的查找效率极高
(使用哈希算法对键去重复,效率高,但无序)
2.HashMap实现了Map所有的方法
3.HashMap不保证插入顺序,但是循环遍历时,输出顺序是不会改变的。
转载
概述:
Map集合的格式 Map<key,value>,key是键值,value是值。Map是一个接口。是将键映射到值的对象,不能包含重复的键;每个键可以映射到最多一个值(函数的本质就是就是映射,一个x只对应一个y,同一个y可以由多个x映射得到)
创建Map集合对象
Map只是一个接口,HashMap重写了Map的方法,所有要采用多态的方式,通过具体的实现类HashMap才能创造对象,实现类的方法。
Map<Type,Type>map=new HashMap<Type,Type>();
Map/HashMap的方法
Map集合的基本方法

Map集合的获取方法
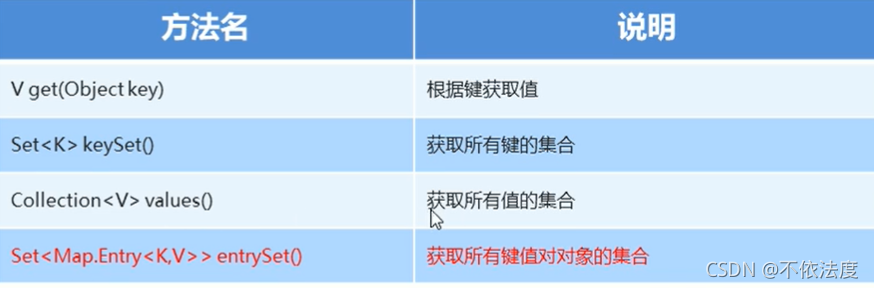
使用show
添加元素:.put(Key,Value)
Map<String,String> map=new HashMap<String,String>();
map.put("mio","smth");
map.put("dw","yscm");
map.put("yyq","hhh");
map.put("yyq","hh");
// 同一个键值只对应一个值,后面的值会将先前的值覆盖
System.out.println(map);
// {yyq=hh, mio=smth, dw=yscm}这里是HashMap重写了toString
移除元素:.remove(Key) 根据键值移除元素
System.out.println(map);
// {yyq=hh, mio=smth, dw=yscm}
map.remove("yyq");
System.out.println(map);
// {mio=smth, dw=yscm}
判断集合是否包含指定键值:.containsKey(Key),boolean类型
判断集合是否包含指定值:.containsValue(Value),boolean类型
System.out.println(map);
// {yyq=hh, mio=smth, dw=yscm}
System.out.println(map.containsKey("dw"));
// true
System.out.println(map.containsKey("hh"));
// false
System.out.println(map.containsValue("smth"));
// true
System.out.println(map.containsValue("mh"));
// false
判断集合是否为空:.isEmpty()
给出集合长度,集合内键值对元素个数:.size()
清除全部元素:.clear()
System.out.println(map);
// {yyq=hh, mio=smth, dw=yscm}
System.out.println(map.size());
// 3
System.out.println(map.isEmpty());
// false
map.clear();
System.out.println(map);
// {}
System.out.println(map.isEmpty());
// true
System.out.println(map.size());
// 0
根据键获取值:.get(Object key)
System.out.println(map);
// {yyq=hh, mio=smth, dw=yscm}
System.out.println(map.get("mio"));
// smth
System.out.println(map.get("h"));
// null
获取键的集合:.keySet()
获取值的集合:.values()
System.out.println(map);
// {yyq=hh, mio=smth, dw=yscm}
System.out.println(map.keySet());
// 键的集合:[yyq, mio, dw]
System.out.println(map.values());
// 值的集合[hh, smth, yscm]
System.out.println(map.entrySet());
// 键值对的集合[yyq=hh, mio=smth, dw=yscm]
遍历
法1:
通过keySet能够得到键的集合,遍历每一个键再通过get(Key)就能够的到对应的Value
System.out.println(map);
// {yyq=hh, mio=smth, dw=yscm}
Set<String> keySet=map.keySet();
for (String key:keySet){
System.out.println(key+" "+map.get(key));
}
// yyq hh
// mio smth
// dw yscm
法2:
先用Map的方法.entrySet()获得键值对集合,通过增强for循环遍历Map.Entry<K,V>(键值对对象类型)的集合,获取每一个Map.Entry<K,V>类型的键值对对象,键值对对象有两个方法,.getValue()和.getKey()可以获得键和值
System.out.println(map);
// {yyq=hh, mio=smth, dw=yscm}
Set<Map.Entry<String,String>> entrySet=map.entrySet();
for (Map.Entry<String,String> ee:entrySet){
System.out.println(ee.getKey()+" "+ee.getValue());
}
// yyq hh
// mio smth
// dw yscm
关于Map/HashMap键值单一的处理:
<String,String>类型会直接进行覆盖,这是因为String的equals不同于其他的对象,进行的是值的比较
(我记得好像是这么说的,以后发现不对再改)
HashMap<Students,String>hashMap=new HashMap<>();
如果是自定义的Object(Students)类:没有重写类的hashCode和equals时,后添加的键值对不会覆盖之前键相同的键值对,因为正常的equals的比较是对地址的比较。
String name;
int age;
public Students(String name,int age){
this.name=name;
this.age=age;
}
HashMap<Students,String>hashMap=new HashMap<>();
hashMap.put(new Students("mio",20),"smth");
hashMap.put(new Students("yscm",22),"hysd");
hashMap.put(new Students("tgcf",29),"bwjj");
hashMap.put(new Students("mio",20),"smt");
Set<Students>setKey=hashMap.keySet();
for (Students students:setKey){
System.out.println(students.name+" "+students.age+" "+hashMap.get(students));
}
// 这时候没有覆盖
// yscm 22 hysd
// mio 20 smt
// mio 20 smth
// tgcf 29 bwjj
对hasCode和equals方法重写以后会进行覆盖:
String name;
int age;
public Students(String name,int age){
this.name=name;
this.age=age;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Students students = (Students) o;
return age == students.age && Objects.equals(name, students.name);
}
@Override
public int hashCode() {
return Objects.hash(name, age);
}
HashMap<Students,String>hashMap=new HashMap<>();
hashMap.put(new Students("mio",20),"smth");
hashMap.put(new Students("yscm",22),"hysd");
hashMap.put(new Students("tgcf",29),"bwjj");
hashMap.put(new Students("mio",20),"smt");
Set<Students>setKey=hashMap.keySet();
for (Students students:setKey){
System.out.println(students.name+" "+students.age+" "+hashMap.get(students));
}
// mio 20 smt
// tgcf 29 bwjj
// yscm 22 hysd
Set
HashSet
LinkedHashSet
TreeSet
List
概述:
List是一个有序(存储和取出的元素顺序一致)的集合(/序列),继承Collections,所有Collections的方法List都有。
用户可以精确控制列标中每一个元素的插入位置,也可以通过整数索引(列表中的位置)访问列表的元素,并搜索列表的元素。
与set集合的差别:list列表允许重复的元素
存储和取出的顺序一样
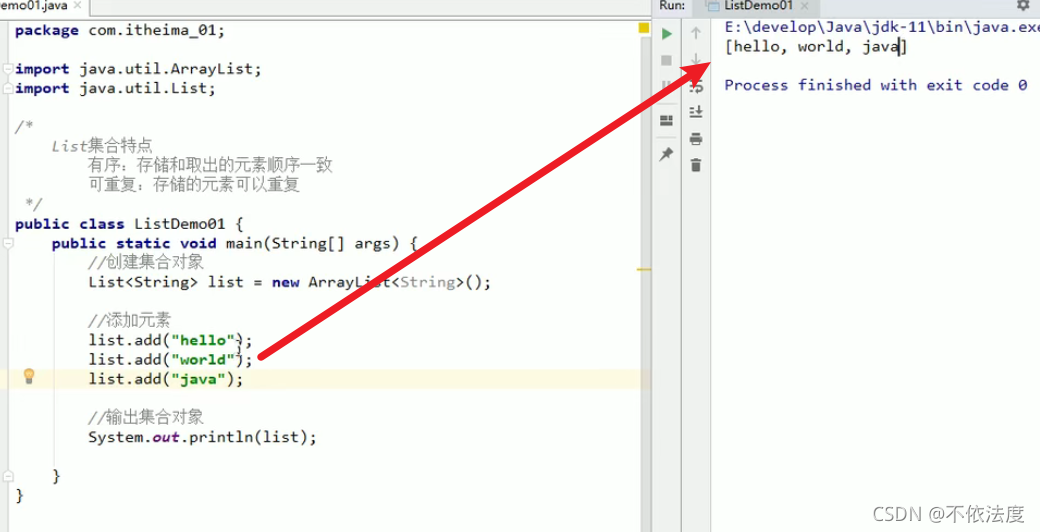
元素可重复
使用
1.构造list
List<Object> 列表名 = new ArrayList<Object>();
2.向list里存储元素:add
列表名.add(new Object())
3.输出list的所有元素可以用System.out.println
4. 遍历
4.1 可以用迭代器
package List;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
public class TestList {
public static void main(String[] args) {
List<String> list=new ArrayList<String>();
list.add("hello");
list.add("world");
list.add("java");
list.add("hello");
Iterator<String> iterator=list.iterator();
// [hello, world, java, hello]
while(iterator.hasNext()){
// hasNext() boolean类型,如果迭代任具有元素,则返回 true
String str=iterator.next();
// next() 返回迭代中的下一个元素。
System.out.println(str);
}
}
}
4.2 也可以 for循环+get(int index)方法
System.out.println(list);
// [hello, world, java, hello]
for(int i=0;i<list.size();i++)
System.out.println(list.get(i));
// hello
// world
// java
// hello
4.3 增强for循环
for(元素数据类型Type 变量名:数组名或者集合名)
System.out.println(list);
// [hello, world, java, hello]
// 内部原理是一个Iterator迭代器
for(String str:list){
System.out.println(str);
}
// hello
// world
// java
// hello
5.List的特有方法
List是Collections的子类,ArrayList是List的子类
下面展示一下List(ArrayList也有)的特有方法:

补充:List.indexOf(Object)
调用list的indexOf接口的时候注意,如果自定义兑现没有重写equals方法,将使用默认的Object中的equals方法。
展示show:
void add(int index,E element):index的范围在[0,List的元素个数],向index插入元素,原index位置的元素及index后面的元素都后移一位,index位置放置新元素。
public static void main(String[] args) {
List<String> list=new ArrayList<String>();
list.add("hello");
list.add("world");
list.add("java");
list.add("hello");
list.add(4,"dw");
System.out.println(list);
// [hello, world, java, hello, dw]
}
E remove(int index):删除元素并返回被删除的元素,index的范围在[0,List的元素个数-1]。
System.out.println(list);
// [hello, world, java, hello, dw]
System.out.println(list.remove(4));
// dw
System.out.println(list);
// [hello, world, java, hello]
E set(int index,E element):修改index位置的元素为element,并返回被删除的index元素,index的范围在[0,List的元素个数-1]。
System.out.println(list);
// [hello, world, java, hello]
System.out.println(list.set(2,"Java"));
// java
System.out.println(list);
// [hello, world, Java, hello]
E get(int index):返回index位置的元素。
System.out.println(list);
// [hello, world, java, hello]
System.out.println(list.get(2));
// java
List.indexOf(Object):返回Object所在的下标- 位置的元素
public static int searchName(List<String>list,String name){
return list.indexOf(name);
// 返回name第一次出现的下标
}
并发修改异常
还没整理–视频连接,要看源码有点麻烦,想起来再整理吧,暂时是理解了
列表迭代器ListIterator
1.简介:ListIterator是List集合特有的迭代器,继承Iterator,也有hasNext()和next()方法
2.与Iterator迭代器的区别:ListIterator允许沿任一方向遍历列表
3.方法:

展示show:
使用ListIterator添加元素
//用ListIterator添加
ListIterator<String>it=list.listIterator();
for (String string:names){
it.add(string);
}
hasNext()hasPrevious()next()previous()
List<String> list=new ArrayList<String>();
list.add("hello");
list.add("world");
list.add("java");
list.add("hello");
// 通过list集合的listIterator得到的,遍历
ListIterator<String> iterator=(list).listIterator();
while (iterator.hasNext()){
String str=iterator.next();
System.out.println(str);
}
System.out.println("反向遍历");
while (iterator.hasPrevious()){
String str=iterator.previous();
System.out.println(str);
}
// hello
// world
// java
// hello
// 反向遍历
// hello
// java
// world
// hello
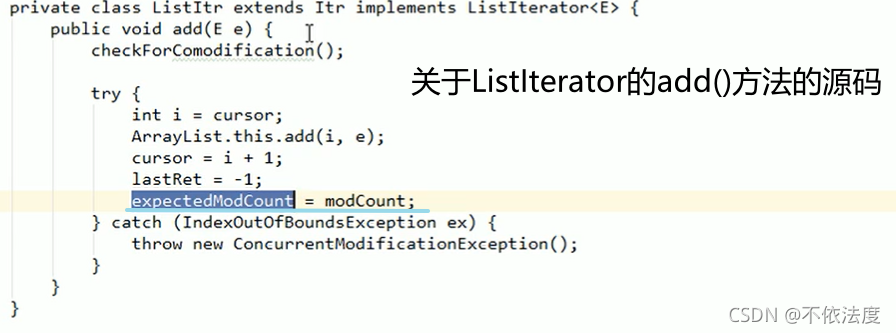
迭代器名.add(E element):在迭代器所指的元素后面加入element (指定位置添加元素)
System.out.println(list);
// [hello, world, java, hello]
// 通过list集合的listIterator得到的
ListIterator<String> iterator=(list).listIterator();
while(iterator.hasNext()){
String str=iterator.next();
if(str.equals("world"))
iterator.add("dw");
}
System.out.println(list);
// [hello, world, dw, java, hello] dw是加在world后面的
之前这样写之间报错
Iterator<String> iterator=(list).iterator();
while(iterator.hasNext()){
String str=iterator.next();
if(str.equals("world"))
list.add("dw");
}
是因为实际操作数与理想操作数的不匹配,因为每次调用next都会调用checkForComodification看一下实际操作数与理想操作数是否匹配,而对应列表调用add后其中一个数++了,接下来继续调用next,也就会调用checkForComodification发现不匹配抛出异常(RunTimeException)
这就是并发修改异常

重点看画线那条,这样调用next,next又调用checkForComodification就不会出现因为实际操作数modCount与理想操作数expectedModCount而不匹配抛出异常(RunTimeException)
不会出现并发修改异常

 浙公网安备 33010602011771号
浙公网安备 33010602011771号