环境介绍
| Hostname |
IP |
CPU/Mem/Disk |
OS |
Role |
|
|
| master1.lab.example.com |
192.168.1.111/24 |
2C/4G/60G |
Ubuntu22.04.1 |
Master/etcd |
|
|
| master2.lab.example.com |
192.168.1.112/24 |
2C/4G/60G |
Ubuntu22.04.1 |
Master/etcd |
|
|
| master3.lab.example.com |
192.168.1.113/24 |
2C/4G/60G |
Ubuntu22.04.1 |
Master/etcd |
|
|
| node1.lab.example.com |
192.168.1.114/24 |
2C/4G/60G |
Ubuntu22.04.1 |
node |
|
|
| node2.lab.example.com |
192.168.1.115/24 |
2C/4G/60G |
Ubuntu22.04.1 |
node |
|
|
| node3.lab.example.com |
192.168.1.116/24 |
2C/4G/60G |
Ubuntu22.04.1 |
node |
|
|
| ha1.lab.example.com |
192.168.1.117/24 |
1C/2G/60G |
Ubuntu22.04.1 |
keepalived
haproxy |
|
|
| ha2.lab.example.com |
192.168.1.118/24 |
1C/2G/60G |
Ubuntu22.04.1 |
keepalived
haproxy |
|
|
| VIP |
192.168.1.119/24 |
|
|
|
|
|
忘记root密码后
| # 在 Ubuntu 22.04 / 20.04 LTS 中重新设置 sudo 密码 |
| 启动时按下 SHIFT + ESC 键,进入 GRUB 引导加载器页面 |
| 接着会出现几种模式,分别是高级模式、内存测试 |
| 选择第一个选项Advanced options for Ubuntu(进入高级模式),选择Ubuntym with Kubyx 5.15.0-52-generic (注意,非带recovery mode字样的项)并按 e 键进入编辑模式 |
| 在以 linux 开头的一行末尾,删除字符串 $vt_handoff 并添加字符串 ro quiet splash systemd.unit=rescue.target |
| 做完修改后,按 Ctrl + X 或 F10 在救援模式下启动 |
| 进到(or press Control-D to continue): 界面是按回车即可 |
| sudo passwd # 密码必须是大小写字母、数字、特殊字符的组合 |
| 修改完后执行systemctl reboot进行重启 |
| |
前期配置
| # 配置IP |
| sudo vim /etc/netplan/00-installer-config.yaml |
| network: |
| ethernets: |
| ens33: |
| dhcp4: false |
| dhcp6: false |
| addresses: |
| - 172.16.186.111/24 |
| routes: |
| - to: default |
| via: 172.16.186.2 |
| nameservers: |
| addresses: [172.16.186.2] |
| version: 2 |
| |
| # 是配置文件生效 |
| sudo netplan apply |
| |
| |
| # 配置主机名 |
| hostnamectl set-hostname master1.lab.example.com |
| |
| |
| # 允许root用户远程登录 |
| sudo vim /etc/ssh/sshd_config |
| PermitRootLogin yes |
| |
| # 重启sshd服务 |
| sudo systemctl restart sshd |
| |
| |
| # 先安装ansible,将master1作为控制节点,其他节点作为被控节点(使用自带的源) |
| root@master1:~# |
| ssh-keygen -t rsa -P '' |
| for i in {1..8};do ssh-copy-id rambo@172.16.186.11$i;done |
| for i in {1..8};do ssh-copy-id root@172.16.186.11$i;done |
| echo "rambo ALL=(ALL) NOPASSWD: ALL" > /etc/sudoers.d/rambo |
| for i in {2..8};do scp /etc/sudoers.d/rambo root@172.16.186.11$i:/etc/sudoers.d/;done |
| apt install -y ansible |
| mkdir /etc/ansible |
| |
| # 新建该文件 |
| root@master1:~# vim /etc/ansible/ansible.cfg |
| [defaults] |
| inventory = ./inventory |
| host_key_checking = False |
| remote_user = rambo |
| ask_pass = False |
| |
| [privilege_escalation] |
| become=true |
| become_method=sudo |
| become_user=root |
| become_ask_pass=False |
| |
| |
| root@master1:~# vim /etc/ansible/inventory |
| [master] |
| 172.16.186.11[1:3] |
| [master1] |
| 172.16.186.11[2:3] |
| [node] |
| 172.16.186.11[4:6] |
| [lb] |
| 172.16.186.11[7:8] |
| |
| |
| root@master1:~# ansible all -m ping |
| |
| |
| # 配置hosts |
| root@master1:~# vim /etc/hosts |
| 172.16.186.111 master1.lab.example.com master1 |
| 172.16.186.112 master2.lab.example.com master2 |
| 172.16.186.113 master3.lab.example.com master3 |
| 172.16.186.114 node1.lab.example.com node1 |
| 172.16.186.115 node2.lab.example.com node2 |
| 172.16.186.116 node3.lab.example.com node3 |
| 172.16.186.117 ha1.lab.example.com ha1 |
| 172.16.186.118 ha2.lab.example.com ha2 |
| |
| root@master1:~# ansible master1,node,lb -m copy -a "src=/etc/hosts dest=/etc/ backup=yes" |
| |
| |
| # 关闭swap |
| root@master1:~# ansible all -m shell -a "sed -ri '/swap/s/^/#/' /etc/fstab && swapoff -a && systemctl mask swap.target" |
| |
| # 安装常用软件 |
| root@master1:~# |
| ansible all -m apt -a "name=net-tools,vim,bash-completion state=present" |
| # ansible all -m shell -a "source /usr/share/bash-completion/bash_completion" |
| |
| |
| # 配置时间同步 |
| root@master1:~# |
| ansible all -m apt -a "name=chrony state=present" |
| cp /etc/chrony/chrony.conf . |
| |
| root@master1:~# vim /etc/chrony/chrony.conf |
| #pool ntp.ubuntu.com iburst maxsources 4 |
| #pool 0.ubuntu.pool.ntp.org iburst maxsources 1 |
| #pool 1.ubuntu.pool.ntp.org iburst maxsources 1 |
| #pool 2.ubuntu.pool.ntp.org iburst maxsources 2 |
| pool ntp.aliyun.com iburst |
| |
| |
| root@master1:~# vim chrony.conf |
| #pool ntp.ubuntu.com iburst maxsources 4 |
| #pool 0.ubuntu.pool.ntp.org iburst maxsources 1 |
| #pool 1.ubuntu.pool.ntp.org iburst maxsources 1 |
| #pool 2.ubuntu.pool.ntp.org iburst maxsources 2 |
| pool 172.16.186.111 iburst |
| |
| root@master1:~# |
| ansible master1,node,lb -m copy -a "src=/root/chrony.conf dest=/etc/chrony/ backup=yes" |
| ansible all -m service -a "name=chronyd state=restarted" |
| ansible all -m shell -a "chronyc sources|tail -n1" |
| |
高可用安装
安装haproxy
| # 修改内核参数(所有装haproxy的节点上执行) |
| root@ha*:~# sudo cat >> /etc/sysctl.conf <<-EOF |
| net.ipv4.ip_nonlocal_bind = 1 |
| EOF |
| |
| sysctl -p |
| |
| # 安装配置haproxy |
| root@master1:~# ansible lb -m apt -a "name=haproxy state=present" |
| |
| # 追加以下代码而不是覆盖 |
| [root@lb1 ~]# cat >> /etc/haproxy/haproxy.cfg <<-EOF |
| listen stats |
| mode http |
| bind 0.0.0.0:8888 |
| stats enable |
| log global |
| stats uri /status |
| stats auth admin:123456 |
| |
| listen kubernetes-api-6443 |
| mode tcp |
| bind 172.16.186.119:6443 |
| server master1.lab.example.com 172.16.186.111:6443 check inter 3s fall 3 rise 3 |
| server master2.lab.example.com 172.16.186.112:6443 check inter 3s fall 3 rise 3 |
| server master3.lab.example.com 172.16.186.113:6443 check inter 3s fall 3 rise 3 |
| EOF |
| |
| # 启动haproxy |
| root@master1:~# |
| ansible lb -m service -a "name=haproxy state=restarted enabled=yes" |
| ansible lb -m shell -a "systemctl status haproxy | grep Active" |
| ansible all -m apt -a "name=net-tools state=present" |
| |
| |
| root@master1:~# ansible lb -m shell -a "ss -tlun | egrep '(6443|8888)'" |
| 172.16.186.118 | CHANGED | rc=0 >> |
| tcp LISTEN 0 4096 0.0.0.0:8888 0.0.0.0:* # haproxy的IP |
| tcp LISTEN 0 4096 172.16.186.119:6443 0.0.0.0:* # VIP |
| 172.16.186.117 | CHANGED | rc=0 >> |
| tcp LISTEN 0 4096 172.16.186.119:6443 0.0.0.0:* |
| tcp LISTEN 0 4096 0.0.0.0:8888 0.0.0.0:* |
| |
安装keepalived
| root@master1:~# ansible lb -m apt -a "name=keepalived state=present" |
| # lb1配置keepalived master节点 |
| root@master1 ~# cat > keepalived-lb1.conf << EOF |
| ! Configuration File for keepalived |
| |
| global_defs { |
| router_id lb1.lab.example.com |
| } |
| vrrp_script chk_haproxy { |
| script "/etc/keepalived/check_haproxy.sh" |
| interval 5 |
| weight -5 |
| fall 2 |
| rise 1 |
| } |
| vrrp_instance VI_1 { |
| state MASTER |
| interface ens33 |
| garp_master_delay 10 |
| smtp_alert |
| virtual_router_id 66 |
| priority 100 |
| advert_int 2 |
| authentication { |
| auth_type PASS |
| auth_pass 123456 |
| } |
| virtual_ipaddress { |
| 172.16.186.119/24 dev ens33 label ens33:0 |
| } |
| track_script { |
| chk_haproxy |
| } } |
| EOF |
| |
| root@master1 ~# ansible 172.16.186.117 -m copy -a "src=/root/keepalived-lb1.conf dest=/etc/keepalived/keepalived.conf backup=yes" |
| |
| # lb2配置keepalived backup节点 |
| root@master1 ~# cat > keepalived-lb2.conf << EOF |
| ! Configuration File for keepalived |
| |
| global_defs { |
| router_id lb3.lab.example.com |
| } |
| vrrp_script chk_haproxy { |
| script "/etc/keepalived/check_haproxy.sh" |
| interval 5 |
| weight -5 |
| fall 2 |
| rise 1 |
| } |
| vrrp_instance VI_1 { |
| state BACKUP |
| interface ens33 |
| garp_master_delay 10 |
| smtp_alert |
| virtual_router_id 66 |
| priority 80 |
| advert_int 2 |
| authentication { |
| auth_type PASS |
| auth_pass 123456 |
| } |
| virtual_ipaddress { |
| 172.16.186.119/24 dev ens33 label ens33:0 |
| } |
| track_script { |
| chk_haproxy |
| } } |
| EOF |
| |
| [root@master1 ~]# ansible 172.16.186.118 -m copy -a "src=/root/keepalived-lb2.conf dest=/etc/keepalived/keepalived.conf backup=yes" |
| |
| |
| |
| # 健康检查脚本配置(两台lb主机) |
| root@master1 ~# cat > check_haproxy.sh <<-EOF |
| #!/bin/bash |
| /usr/bin/killall -0 haproxy || systemctl restart haproxy |
| EOF |
| |
| [root@master1 ~]# ansible lb -m copy -a "src=/root/check_haproxy.sh dest=/etc/keepalived/ mode=0755" |
| |
| # 启动服务 |
| root@master1 ~# |
| ansible lb -m systemd -a "daemon-reload=yes" |
| ansible lb -m service -a "name=haproxy state=restarted enabled=yes" |
| ansible lb -m service -a "name=keepalived state=restarted enabled=yes" |
| ansible lb -m shell -a "systemctl status haproxy | grep Active" |
| ansible lb -m shell -a "systemctl status keepalived | grep Active" |
| |
| root@master1:~# ansible lb -m shell -a "hostname -I" |
| 172.16.186.118 | CHANGED | rc=0 >> |
| 172.16.186.118 fd15:4ba5:5a2b:1008:20c:29ff:fe09:8be2 |
| 172.16.186.117 | CHANGED | rc=0 >> |
| 172.16.186.117 172.16.186.119 fd15:4ba5:5a2b:1008:20c:29ff:feaf:d5c1 # VIP在117这台机上 |
k8s配置(基于docker)
所有节点安装docker
| root@master1:~# ansible master,node -m apt -a "name=docker.io state=present" |
| root@master1:~# cat > /etc/docker/daemon.json <<-EOF |
| { |
| "registry-mirrors":[ |
| "https://docker.mirrors.usts.edu.cn", |
| "https://hub-mirror.c.163.com", |
| "https://reg-mirror.qiniu.com", |
| "https://registry.docker-cn.com" |
| ], |
| "exec-opts": ["native.cgroupdriver=systemd"] |
| } |
| EOF |
| |
| root@master1:~# ansible master1,node -m copy -a "src=/etc/docker/daemon.json dest=/etc/docker/" |
| root@master1:~# ansible master,node -m service -a "name=docker state=restarted" |
| root@master1:~# ansible master,node -m shell -a "systemctl status docker | grep Active" |
所有节点安装kubeadm、kubelet、kubectl
| kubeadm: 实现创建集群用的工具 |
| kubelet: 在某台主机上实现控制容器的一个工具 |
| kubectl: 管理工具 |
| |
| |
| root@master1:~# echo ' |
| curl https://mirrors.aliyun.com/kubernetes/apt/doc/apt-key.gpg | apt-key add - |
| |
| cat >> /etc/apt/sources.list.d/kubernetes.list <<-EOF |
| deb https://mirrors.aliyun.com/kubernetes/apt/ kubernetes-xenial main |
| EOF' > sources.sh |
| |
| root@master1:~# ansible master,node -m copy -a "src=/root/sources.sh dest=/root/ mode='0755'" |
| root@master1:~# ansible master,node -m shell -a "bash /root/sources.sh" |
| root@master1:~# ansible master,node -m shell -a "apt update" |
| |
| # 查看可安装的版本 |
| root@master1:~# apt-cache madison kubeadm | head |
| root@master1:~# apt-cache madison {kubeadm,kubelet,kubectl} | head |
| |
| # 安装指定版本(该文档用的该方法安装1.25.5-00) |
| root@master1:~# ansible master,node -m shell -a "apt install -y kubeadm=1.25.5-00 kubelet=1.25.5-00 kubectl=1.25.5-00" |
| |
| # 安装最新版本 |
| root@master1:~# ansible master,node -m yum -a "name=kubeadm,kubelet,kubectl state=present" |
| |
所有主机安装cri-docker
| k8s从1.24开始移除了对docker-shim的支持,而docker Engine默认又不支持CRI规范,因而二者直接完成整合,为此mirantis和docker联合创建了cri-dockerd项目,用于为docker Enginx提供一个能够支持到CRI规范的垫片,从而能够让k8s基于cri控制docker |
| |
| # 方法1(能科 o 学上网的情况) |
| root@master1:~# curl -LO https://github.com/Mirantis/cri-dockerd/releases/download/v0.2.5/cri-dockerd_0.2.5.3-0.ubuntu-focal_amd64.deb |
| root@master1:~# ansible master1,node -m copy -a "src=/root/cri-dockerd_0.2.5.3-0.ubuntu-focal_amd64.deb dest=/root/" |
| root@master1:~# ansible master,node -m shell -a "dpkg -i /root/cri-dockerd_0.2.5.3-0.ubuntu-focal_amd64.deb" |
| 注:安装完后相应的服务cri-dockerd.service会自动启动 |
| |
| |
| # 所有主机配置cri-dockerd |
| 注:由于cri-dockerd在下载镜像的时候要从国外下载镜像,所以要改成国内的下载地址 |
| root@master1:~# vim /lib/systemd/system/cri-docker.service |
| [Service] |
| Type=notify |
| ExecStart=/usr/bin/cri-dockerd --container-runtime-endpoint fd:// --pod-infra-container-image registry.aliyuncs.com/google_containers/pause:3.7 |
| 注:加上--pod-infra-container-image registry.aliyuncs.com/google_containers/pause:3.7这一句 |
| |
| # 将改过的配置文件发送到其他master、node节点 |
| root@master1:~# ansible master1,node -m copy -a "src=/lib/systemd/system/cri-docker.service dest=/lib/systemd/system/" |
| |
| # 所有节点起服务 |
| root@master1:~# |
| ansible master,node -m systemd -a "daemon-reload=yes" |
| ansible master,node -m service -a "name=cri-docker state=restarted" |
| ansible master,node -m shell -a "systemctl status cri-docker | grep Active" |
| |
| # 提前准备k8s初始化所需镜像 |
| # 查看国内镜像 |
| root@master1:~# kubeadm config images list --image-repository registry.aliyuncs.com/google_containers |
| I1228 04:11:28.768956 17697 version.go:256] remote version is much newer: v1.26.0; falling back to: stable-1.25 |
| registry.aliyuncs.com/google_containers/kube-apiserver:v1.25.5 |
| registry.aliyuncs.com/google_containers/kube-controller-manager:v1.25.5 |
| registry.aliyuncs.com/google_containers/kube-scheduler:v1.25.5 |
| registry.aliyuncs.com/google_containers/kube-proxy:v1.25.5 |
| registry.aliyuncs.com/google_containers/pause:3.8 |
| registry.aliyuncs.com/google_containers/etcd:3.5.6-0 |
| registry.aliyuncs.com/google_containers/coredns:v1.9.3 |
| |
| |
| # 从国内镜像拉取镜像,1.24以上还需要指定--cri-socket路径 |
| kubeadm config images pull --kubernetes-version=v1.25.5 --image-repository registry.aliyuncs.com/google_containers --cri-socket unix:///run/cri-dockerd.sock |
| |
| # pull镜像,这里有可能失败,需要一台一台pull,一台一台也有可能失败,多pull几次 |
| root@master1:~# ansible master1,node -m shell -a "kubeadm config images pull --kubernetes-version=v1.25.5 --image-repository registry.aliyuncs.com/google_containers --cri-socket unix:///run/cri-dockerd.sock" |
| |
| |
| # 导出镜像(可选) |
| root@master1:~# docker image save `docker image ls --format "{{.Repository}}:{{.Tag}}"` -o k8s-images-v1.25.5.tar |
| root@master1:~# ll -h k8s-images-v1.25.5.tar |
| -rw------- 1 root root 667M Dec 28 05:21 k8s-images-v1.25.5.tar |
| |
初始化k8s集群
| # 实现kubectl命令补全 |
| kubectl completion bash > /etc/profile.d/kubectl_completion.sh |
| source /etc/profile.d/kubectl_completion.sh |
| |
| |
| |
| --kubernetes-version: kubernete组件的版本号,它必须要与安装的kubelet程序包的版本相同 |
| --control-plane-endpoint: 多主节点必选项,用于指定控制平面的因定访问地址,可是IP地址或DNS名称,会被用于集群管理员及集群组的kubeconfig配置文件的API Server的访问地址,如果是单主节点的控制平面部署时不使用该选项,注能: kubeadhm不支持将没有--contrc-plane-endpoint 参数的单个控制平面集群转换为高可用性集 |
| --pod-network-cidr: Pod网络的地址范围,其值为CIDR格式的网络地址,通常情况下F1anne1网络插件的默认为10.244.0.0/16, Calico网络插件的默认值为192.168.0.0/16 |
| --service-cidr: service的网络地址范围,其值为CIDR格式的网络地址,默认为10.96.0.0/12:通常,仅Flanne1一类的网络插件需要手动指定该地址 |
| --service-dns-domain <string>: 指定k8s集群城名,默认是cluster.1oca1,会自动通过相应的DNS服务实现解析 |
| --apiserver-advertise-address: API服务器所公布的其正在监听的IP地址。如果未设置则使用默认网路接口。 apiserver通告给其他组件的IP地址,一般应该为Master节点的用于集群内部通信的IP地址,0.0.0.0表示此节点上所有可用地址,非必选项 |
| --image-repository <string>: 设置镜像仓库地址,默认为k8s.gcr.io ,此地址国内可能无法访问,可以指向国内的镜像地址 |
| --token-ttl: 共令牌(token)的过期时长,默认为24小时,0表示水不过期:为防止不安全存留等原因导致的令牌泄露危及集群安全。建议为其设定过期时长。未设定该选项时,在token过期后,若期望再向集群中加入其它节点,可使用如下命令重新创建token并生成节点加集群, |
| 命令: kubeadm token create --print-join-command |
| --ignore-preflight-errors=Swap: 若各节点未禁用Swap设备,还需附加该选项从而让kubeadm忽略该错误 |
| --upload-certs: 将控制平面证书上传到 kubeadm-certs Secret |
| --cri-socket: v1.24版之后需要指定连接cri的socket文件路径,注意;不同的CRI连接文件不同 |
| #如果是 cRI 是containerd ,则使用﹣-cri-socket unix:///run/containerd/containerd.sock |
| #如果是 cRI 是docker,则使用﹣-cri-socket unix:///var/run/cri-dockerd.sock |
| #如果是 CRI 是 CRI-o ,则使用﹣-cri-socket unix:///var/run/crio/crio.sock |
| 注意: CRI-o 与 containerd 的容器管理机制不一样,所以镜像文件不能通用 |
| |
| |
| # 初始化集群 |
| root@master1:~# kubeadm init --control-plane-endpoint="172.16.186.119" --kubernetes-version=v1.25.5 --pod-network-cidr=10.244.0.0/16 --service-cidr=10.96.0.0/12 --token-ttl=0 --cri-socket unix:///run/cri-dockerd.sock --image-repository registry.aliyuncs.com/google_containers --upload-certs |
| 注:不支持\换行,以下是回显 |
| |
| .... |
| .... |
| [addons] Applied essential addon: CoreDNS |
| [addons] Applied essential addon: kube-proxy |
| |
| Your Kubernetes control-plane has initialized successfully! |
| |
| To start using your cluster, you need to run the following as a regular user: |
| |
| mkdir -p $HOME/.kube |
| sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config |
| sudo chown $(id -u):$(id -g) $HOME/.kube/config |
| |
| Alternatively, if you are the root user, you can run: |
| |
| export KUBECONFIG=/etc/kubernetes/admin.conf |
| |
| You should now deploy a pod network to the cluster. |
| Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at: |
| https://kubernetes.io/docs/concepts/cluster-administration/addons/ |
| |
| You can now join any number of the control-plane node running the following command on each as root: |
| |
| kubeadm join 172.16.186.119:6443 --token 9uizwb.m1a1jvjw9fcf9zmr \ |
| --discovery-token-ca-cert-hash sha256:f388a7588aa0030e8cd12e9e243b10c6854718f3df7f3adfbed9f6486d7c7c9e \ |
| --control-plane --certificate-key 4d6278111bc612b5267afbc2eb0a613fd662a6694d81a71931b95b3d536381e8 |
| |
| Please note that the certificate-key gives access to cluster sensitive data, keep it secret! |
| As a safeguard, uploaded-certs will be deleted in two hours; If necessary, you can use |
| "kubeadm init phase upload-certs --upload-certs" to reload certs afterward. |
| |
| Then you can join any number of worker nodes by running the following on each as root: |
| |
| kubeadm join 172.16.186.119:6443 --token 9uizwb.m1a1jvjw9fcf9zmr \ |
| --discovery-token-ca-cert-hash sha256:f388a7588aa0030e8cd12e9e243b10c6854718f3df7f3adfbed9f6486d7c7c9e |
| |
| |
| # 在第一个master节点生成kubectl命令的授权文件 |
| root@master1:~# |
| mkdir -p $HOME/.kube |
| sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config |
| sudo chown $(id -u):$(id -g) $HOME/.kube/config |
| |
| |
| # 在其他节master节点上执行以下命令,就是将其他主节点加入到集群(一台一台在其他master节点上执行,多台节点同时加入有可能会出问题) |
| kubeadm join 172.16.186.119:6443 --token 9uizwb.m1a1jvjw9fcf9zmr \ |
| --discovery-token-ca-cert-hash sha256:f388a7588aa0030e8cd12e9e243b10c6854718f3df7f3adfbed9f6486d7c7c9e \ |
| --control-plane --certificate-key 4d6278111bc612b5267afbc2eb0a613fd662a6694d81a71931b95b3d536381e8 \ |
| --cri-socket unix:///run/cri-dockerd.sock |
| |
| 注1:--cri-socket unix:///run/cri-dockerd.sock是手动添加上去的,必须项 |
| 注2:按回显中提示的创建.kube目录并给权限 |
| mkdir -p $HOME/.kube |
| sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config |
| sudo chown $(id -u):$(id -g) $HOME/.kube/config |
| |
| 注3: |
| 报错 missing optional cgroups: blkio |
| 解决:再执行一次,找到报错,将提示的端口杀掉,提示的文件也删掉,而后再执行一次 |
| |
| |
| |
| |
| # 将其他node节点加入到集群(一台一台在其他所有node节点上执行,多台节点同时加入有可能会出问题) |
| kubeadm join 172.16.186.119:6443 --token 9uizwb.m1a1jvjw9fcf9zmr \ |
| --discovery-token-ca-cert-hash sha256:f388a7588aa0030e8cd12e9e243b10c6854718f3df7f3adfbed9f6486d7c7c9e \ |
| --cri-socket unix:///run/cri-dockerd.sock |
| 注1: |
| 报错 missing optional cgroups: blkio |
| 解决:再执行一次,找到报错,将提示的端口杀掉,提示的文件也删掉,而后再执行一次 |
| |
| |
| # 在master节点上查看各node节点 |
| root@master1:~# kubectl get nodes |
| NAME STATUS ROLES AGE VERSION |
| master1.lab.example.com NotReady control-plane 3h23m v1.25.5 |
| master2.lab.example.com NotReady control-plane 3h1m v1.25.5 |
| master3.lab.example.com NotReady control-plane 3h v1.25.5 |
| node1.lab.example.com NotReady <none> 9m58s v1.25.5 |
| node2.lab.example.com NotReady <none> 155m v1.25.5 |
| node3.lab.example.com NotReady <none> 148m v1.25.5 |
| |
| |
| |
| # 在第一个master节点上配置网络组件 |
| root@master1:~# wget https://files.cnblogs.com/files/smlile-you-me/kube-flannel.yml.sh |
| root@master1:~# mv kube-flannel.yml.sh kube-flannel.yml |
| root@master1:~# kubectl apply -f kube-flannel.yml |
| 注:这里需要等10分钟左右,待docker images | grep flan查看有flannel镜像后再查看nodes就会变成Ready状态 |
| |
| root@master1:~# kubectl get nodes |
| NAME STATUS ROLES AGE VERSION |
| master1.lab.example.com Ready control-plane 3h54m v1.25.5 |
| master2.lab.example.com Ready control-plane 3h32m v1.25.5 |
| master3.lab.example.com Ready control-plane 3h31m v1.25.5 |
| node1.lab.example.com Ready <none> 41m v1.25.5 |
| node2.lab.example.com Ready <none> 3h6m v1.25.5 |
| node3.lab.example.com Ready <none> 3h v1.25.5 |
| |
| |
| # 测试应用编排及服务访问 |
| root@master1:~# kubectl create deployment testapp --image=ikubernetes/demoapp:v1.0 --replicas=3 |
| root@master1:~# kubectl get pod -o wide |
| NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES |
| testapp-c88bfb9f7-6vxcb 1/1 Running 0 3m13s 10.244.4.4 node2.lab.example.com <none> <none> |
| testapp-c88bfb9f7-kffjr 1/1 Running 0 3m13s 10.244.3.2 node1.lab.example.com <none> <none> |
| testapp-c88bfb9f7-vl785 1/1 Running 0 3m13s 10.244.5.2 node3.lab.example.com <none> <none> |
| |
| |
| # 前端创建一个service(集群端口:pod端口) |
| root@master1:~# kubectl create service nodeport testapp --tcp=80:80 |
| # 确定service的地址 |
| root@master1:~# kubectl get svc |
| NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR |
| kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 103m <none> |
| testapp NodePort 10.97.162.178 <none> 80/TCP 19m app=testapp # 上面手动创建的service的IP |
| 释义: |
| 当访问10.102.225.131这个service的地址将会被调度到后端node1、2、3节点上 |
| |
| |
| # 测试轮训效果 |
| root@master1:~# for((i=1;i<5;i++));do curl 10.97.162.178;sleep 3;done |
| iKubernetes demoapp v1.0 !! ClientIP: 10.244.0.0, ServerName: testapp-c88bfb9f7-6vxcb, ServerIP: 10.244.4.4! |
| iKubernetes demoapp v1.0 !! ClientIP: 10.244.0.0, ServerName: testapp-c88bfb9f7-vl785, ServerIP: 10.244.5.2! |
| iKubernetes demoapp v1.0 !! ClientIP: 10.244.0.0, ServerName: testapp-c88bfb9f7-6vxcb, ServerIP: 10.244.4.4! |
| iKubernetes demoapp v1.0 !! ClientIP: 10.244.0.0, ServerName: testapp-c88bfb9f7-kffjr, ServerIP: 10.244.3.2! |
| |
| |
| root@master1:~# curl 10.97.162.178/hostname |
| ServerName: testapp-c88bfb9f7-kffjr |
| |
| |
| |
| |
| |
| # 扩容 |
| root@master1:~# kubectl scale deployment testapp --replicas=5 |
| # 缩容 |
| root@master1:~# kubectl scale deployment testapp --replicas=2 |
报错
| # 浏览器访问报错如下也和下图一样 |
| |
| 注意:以下处理方法在安装dashboard时可能还会生成新的证书,该点暂且未做测试!!! |
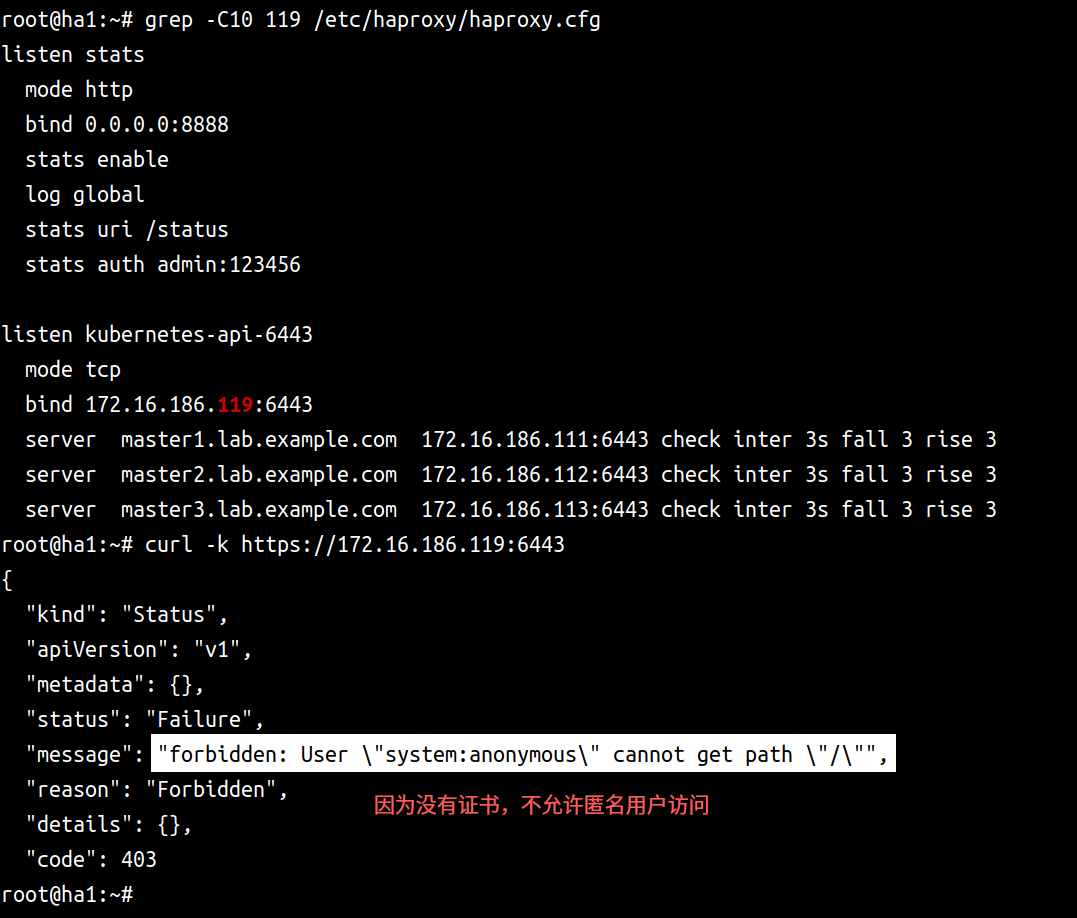
| 证书问题,添加证书 |
| 使用client-certificate-data和client-key-data生成一个p12文件,生产中应有ca颁发的证书,这里仅做演示所以自颁发证书 |
| |
| # 生成client-certificate-data |
| root@master1:~# grep 'client-certificate-data' ~/.kube/config | head -n 1 | awk '{print $2}' | base64 -d >> kubecfg.crt |
| # 生成client-key-data |
| root@master1:~# grep 'client-key-data' ~/.kube/config | head -n 1 | awk '{print $2}' | base64 -d >> kubecfg.key |
| # 生成p12 |
| root@master1:~# openssl pkcs12 -export -clcerts -inkey kubecfg.key -in kubecfg.crt -out kubecfg.p12 -name "kubernetes-client" |
| Warning: -clcerts option ignored with -export # 这个报错不管 |
| Enter Export Password: # 这里不输入密码,直接按回车即可 |
| Verifying - Enter Export Password |
| |
| |
| |
| |
| root@master1:~# ll kubecfg.* |
| -rw-r--r-- 1 root root 1147 Dec 29 10:36 kubecfg.crt |
| -rw-r--r-- 1 root root 1679 Dec 29 10:36 kubecfg.key |
| -rw------- 1 root root 2662 Dec 29 10:44 kubecfg.p12 |
| |
| # 接下来将生成的p12证书导入到浏览器中 |
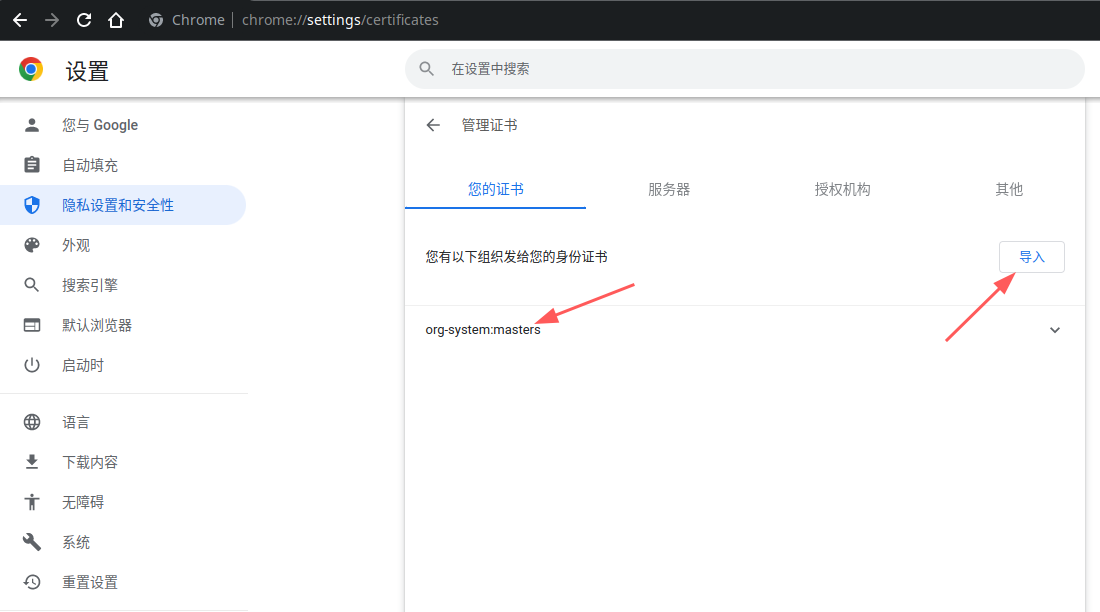
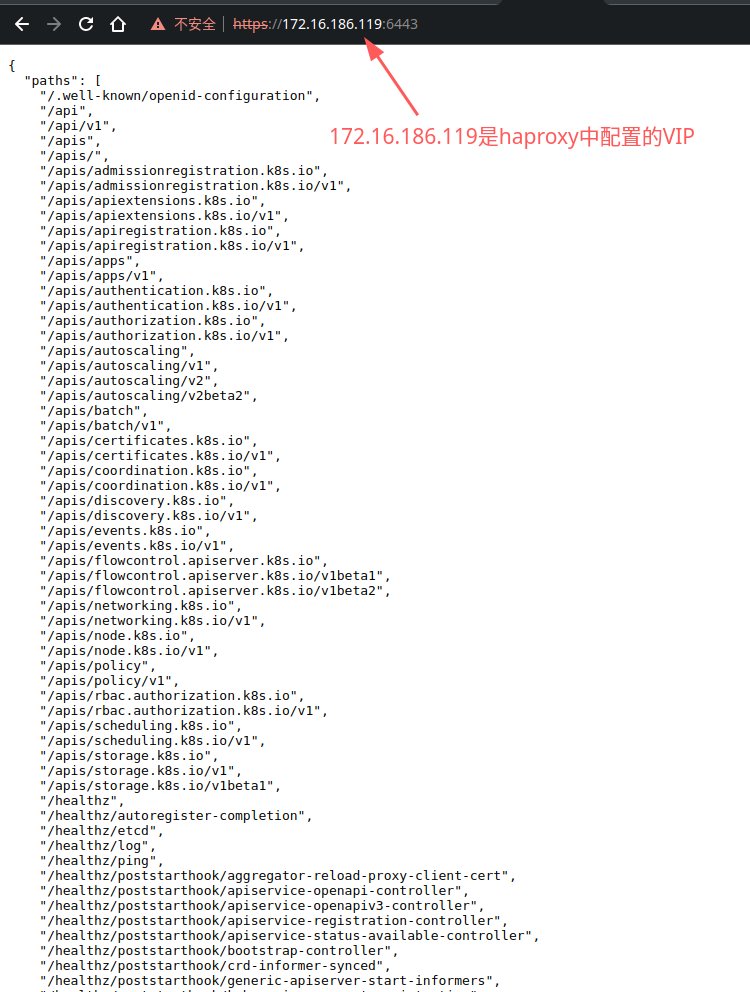
以下每一个api都可以和https://172.16.186.119:6443/进行拼接,比如https://172.16.186.119:6443/api
| { |
| "paths": [ |
| "/.well-known/openid-configuration", |
| "/api", |
| "/api/v1", |
| "/apis", |
| "/apis/", |
| "/apis/admissionregistration.k8s.io", |
| "/apis/admissionregistration.k8s.io/v1", |
| "/apis/apiextensions.k8s.io", |
| "/apis/apiextensions.k8s.io/v1", |
| "/apis/apiregistration.k8s.io", |
| "/apis/apiregistration.k8s.io/v1", |
| "/apis/apps", |
| "/apis/apps/v1", |
| "/apis/authentication.k8s.io", |
| "/apis/authentication.k8s.io/v1", |
| "/apis/authorization.k8s.io", |
| "/apis/authorization.k8s.io/v1", |
| "/apis/autoscaling", |
| "/apis/autoscaling/v1", |
| "/apis/autoscaling/v2", |
| "/apis/autoscaling/v2beta2", |
| "/apis/batch", |
| "/apis/batch/v1", |
| "/apis/certificates.k8s.io", |
| "/apis/certificates.k8s.io/v1", |
| "/apis/coordination.k8s.io", |
| "/apis/coordination.k8s.io/v1", |
| "/apis/discovery.k8s.io", |
| "/apis/discovery.k8s.io/v1", |
| "/apis/events.k8s.io", |
| "/apis/events.k8s.io/v1", |
| "/apis/flowcontrol.apiserver.k8s.io", |
| "/apis/flowcontrol.apiserver.k8s.io/v1beta1", |
| "/apis/flowcontrol.apiserver.k8s.io/v1beta2", |
| "/apis/networking.k8s.io", |
| "/apis/networking.k8s.io/v1", |
| "/apis/node.k8s.io", |
| "/apis/node.k8s.io/v1", |
| "/apis/policy", |
| "/apis/policy/v1", |
| "/apis/rbac.authorization.k8s.io", |
| "/apis/rbac.authorization.k8s.io/v1", |
| "/apis/scheduling.k8s.io", |
| "/apis/scheduling.k8s.io/v1", |
| "/apis/storage.k8s.io", |
| "/apis/storage.k8s.io/v1", |
| "/apis/storage.k8s.io/v1beta1", |
| "/healthz", |
| "/healthz/autoregister-completion", |
| "/healthz/etcd", |
| "/healthz/log", |
| "/healthz/ping", |
| "/healthz/poststarthook/aggregator-reload-proxy-client-cert", |
| "/healthz/poststarthook/apiservice-openapi-controller", |
| "/healthz/poststarthook/apiservice-openapiv3-controller", |
| "/healthz/poststarthook/apiservice-registration-controller", |
| "/healthz/poststarthook/apiservice-status-available-controller", |
| "/healthz/poststarthook/bootstrap-controller", |
| "/healthz/poststarthook/crd-informer-synced", |
| "/healthz/poststarthook/generic-apiserver-start-informers", |
| "/healthz/poststarthook/kube-apiserver-autoregistration", |
| "/healthz/poststarthook/priority-and-fairness-config-consumer", |
| "/healthz/poststarthook/priority-and-fairness-config-producer", |
| "/healthz/poststarthook/priority-and-fairness-filter", |
| "/healthz/poststarthook/rbac/bootstrap-roles", |
| "/healthz/poststarthook/scheduling/bootstrap-system-priority-classes", |
| "/healthz/poststarthook/start-apiextensions-controllers", |
| "/healthz/poststarthook/start-apiextensions-informers", |
| "/healthz/poststarthook/start-cluster-authentication-info-controller", |
| "/healthz/poststarthook/start-kube-aggregator-informers", |
| "/healthz/poststarthook/start-kube-apiserver-admission-initializer", |
| "/healthz/poststarthook/storage-object-count-tracker-hook", |
| "/livez", |
| "/livez/autoregister-completion", |
| "/livez/etcd", |
| "/livez/log", |
| "/livez/ping", |
| "/livez/poststarthook/aggregator-reload-proxy-client-cert", |
| "/livez/poststarthook/apiservice-openapi-controller", |
| "/livez/poststarthook/apiservice-openapiv3-controller", |
| "/livez/poststarthook/apiservice-registration-controller", |
| "/livez/poststarthook/apiservice-status-available-controller", |
| "/livez/poststarthook/bootstrap-controller", |
| "/livez/poststarthook/crd-informer-synced", |
| "/livez/poststarthook/generic-apiserver-start-informers", |
| "/livez/poststarthook/kube-apiserver-autoregistration", |
| "/livez/poststarthook/priority-and-fairness-config-consumer", |
| "/livez/poststarthook/priority-and-fairness-config-producer", |
| "/livez/poststarthook/priority-and-fairness-filter", |
| "/livez/poststarthook/rbac/bootstrap-roles", |
| "/livez/poststarthook/scheduling/bootstrap-system-priority-classes", |
| "/livez/poststarthook/start-apiextensions-controllers", |
| "/livez/poststarthook/start-apiextensions-informers", |
| "/livez/poststarthook/start-cluster-authentication-info-controller", |
| "/livez/poststarthook/start-kube-aggregator-informers", |
| "/livez/poststarthook/start-kube-apiserver-admission-initializer", |
| "/livez/poststarthook/storage-object-count-tracker-hook", |
| "/logs", |
| "/metrics", |
| "/openapi/v2", |
| "/openapi/v3", |
| "/openapi/v3/", |
| "/openid/v1/jwks", |
| "/readyz", |
| "/readyz/autoregister-completion", |
| "/readyz/etcd", |
| "/readyz/etcd-readiness", |
| "/readyz/informer-sync", |
| "/readyz/log", |
| "/readyz/ping", |
| "/readyz/poststarthook/aggregator-reload-proxy-client-cert", |
| "/readyz/poststarthook/apiservice-openapi-controller", |
| "/readyz/poststarthook/apiservice-openapiv3-controller", |
| "/readyz/poststarthook/apiservice-registration-controller", |
| "/readyz/poststarthook/apiservice-status-available-controller", |
| "/readyz/poststarthook/bootstrap-controller", |
| "/readyz/poststarthook/crd-informer-synced", |
| "/readyz/poststarthook/generic-apiserver-start-informers", |
| "/readyz/poststarthook/kube-apiserver-autoregistration", |
| "/readyz/poststarthook/priority-and-fairness-config-consumer", |
| "/readyz/poststarthook/priority-and-fairness-config-producer", |
| "/readyz/poststarthook/priority-and-fairness-filter", |
| "/readyz/poststarthook/rbac/bootstrap-roles", |
| "/readyz/poststarthook/scheduling/bootstrap-system-priority-classes", |
| "/readyz/poststarthook/start-apiextensions-controllers", |
| "/readyz/poststarthook/start-apiextensions-informers", |
| "/readyz/poststarthook/start-cluster-authentication-info-controller", |
| "/readyz/poststarthook/start-kube-aggregator-informers", |
| "/readyz/poststarthook/start-kube-apiserver-admission-initializer", |
| "/readyz/poststarthook/storage-object-count-tracker-hook", |
| "/readyz/shutdown", |
| "/version" |
| ] |
| |
| |
| |
| |
| |
| |
| 上面都测试完后将其删除,和下一个ingress对接 |
| root@master1:~# kubectl delete deployment testapp |
| root@master1:~# kubectl delete svc testapp |
| |
| |
Ingress
Ingress释义与示例
| service只能通过四层负载就是ip+端口的形式来暴露 |
| • NodePort:会占用集群机器的很多端口,当集群服务变多的时候,这个缺点就越发明显 |
| • LoadBalancer:每个Service都需要一个LB,比较麻烦和浪费资源,并且需要 k8s之外的负载均衡设备支持 |
Ingress概述
| Ingress 是对集群中服务的外部访问进行管理的 API 对象,典型的访问方式是 HTTP和HTTPS。 |
| Ingress 可以提供负载均衡、SSL、基于名称的虚拟托管。 |
| 必须具有 ingress 控制器【例如 ingress-nginx】才能满足 Ingress 的要求。仅创建 Ingress 资源无效。 |
| Ingress 公开了从集群外部到集群内 services 的 HTTP 和 HTTPS 路由。 流量路由由 Ingress 资源上定义的规则控制。 |
| |
| 可以将 Ingress 配置为提供服务外部可访问的 URL、负载均衡流量、 SSL / TLS,以及提供基于名称的虚拟主机。 |
| Ingress 控制器 通常负责通过负载均衡器来实现 Ingress,也可以配置边缘路由器 或 其他前端来帮助处理流量。 |
| |
| Ingress 不会公开任意端口或协议。若将 HTTP 和 HTTPS 以外的服务公开到 Internet 时,通常使用 Service.Type=NodePort 或者 Service.Type=LoadBalancer 类型的服务。 |
| |
| |
| |
| |
| # Ingress示例架构图 |
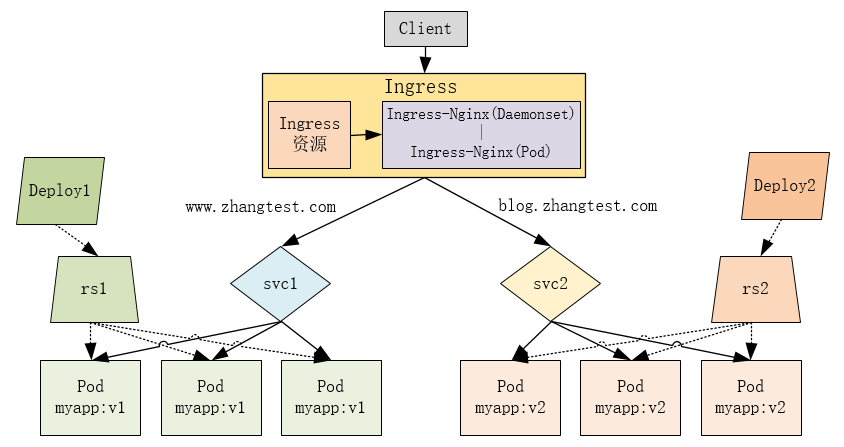
ingress安装
| root@master1:~# cat >> pull-image.sh <<-EOF |
| #!/bin/bash |
| docker pull registry.cn-hangzhou.aliyuncs.com/yutao517/ingress_nginx_controller:v1.1.0 |
| docker tag registry.cn-hangzhou.aliyuncs.com/yutao517/ingress_nginx_controller:v1.1.0 k8s.gcr.io/ingress-nginx/controller:v1.1.1 |
| |
| docker pull registry.cn-hangzhou.aliyuncs.com/yutao517/kube_webhook_certgen:v1.1.1 |
| docker tag registry.cn-hangzhou.aliyuncs.com/yutao517/kube_webhook_certgen:v1.1.1 k8s.gcr.io/ingress-nginx/kube-webhook-certgen:v1.1.1 |
| EOF |
| |
| |
| |
| |
| root@master1:~# bash /root/pull-image.sh |
| root@master1:~# ansible master1,node -m copy -a "src=/root/pull-image.sh dest=/root/" |
| root@master1:~# ansible master1,node -m shell -a "bash /root/pull-image.sh" |
| |
| |
| |
| |
| # 下载deploy.yaml文件 |
| root@master1:~# wget https://download.yutao.co/mirror/deploy.yaml |
| |
| # 将文件中的,依赖 ingress_nginx_controller:v1.1.0 镜像的版本,修改 为 ingress_nginx_controller:v1.1.1 |
| root@master1:~# vim deploy.yaml |
| .... |
| .... |
| 296 --- |
| 297 # Source: ingress-nginx/templates/controller-deployment.yaml |
| 298 apiVersion: apps/v1 |
| 299 kind: Deployment |
| 300 metadata: |
| 301 labels: |
| 302 helm.sh/chart: ingress-nginx-4.0.10 |
| 303 app.kubernetes.io/name: ingress-nginx |
| 304 app.kubernetes.io/instance: ingress-nginx |
| 305 app.kubernetes.io/version: 1.1.0 |
| 306 app.kubernetes.io/managed-by: Helm |
| 307 app.kubernetes.io/component: controller |
| 308 name: ingress-nginx-controller |
| 309 namespace: ingress-nginx |
| 310 spec: |
| 311 selector: |
| 312 matchLabels: |
| 313 app.kubernetes.io/name: ingress-nginx |
| 314 app.kubernetes.io/instance: ingress-nginx |
| 315 app.kubernetes.io/component: controller |
| 316 revisionHistoryLimit: 10 |
| 317 minReadySeconds: 0 |
| 318 template: |
| 319 metadata: |
| 320 labels: |
| 321 app.kubernetes.io/name: ingress-nginx |
| 322 app.kubernetes.io/instance: ingress-nginx |
| 323 app.kubernetes.io/component: controller |
| 324 spec: |
| 325 dnsPolicy: ClusterFirst |
| 326 containers: |
| 327 - name: controller |
| 328 image: k8s.gcr.io/ingress-nginx/controller:v1.1.0 # 修改这里,原本是v1.1.0,需要修改成v1.1.1,因为pull下来的镜像是v1.1.1 |
| 329 imagePullPolicy: IfNotPresent |
| .... |
| .... |
| |
| |
| |
| # |
| root@master1:~# kubectl apply -f deploy.yaml |
| namespace/ingress-nginx created |
| serviceaccount/ingress-nginx created |
| configmap/ingress-nginx-controller created |
| clusterrole.rbac.authorization.k8s.io/ingress-nginx created |
| clusterrolebinding.rbac.authorization.k8s.io/ingress-nginx created |
| role.rbac.authorization.k8s.io/ingress-nginx created |
| rolebinding.rbac.authorization.k8s.io/ingress-nginx created |
| service/ingress-nginx-controller-admission created |
| service/ingress-nginx-controller created |
| deployment.apps/ingress-nginx-controller created |
| ingressclass.networking.k8s.io/nginx created |
| validatingwebhookconfiguration.admissionregistration.k8s.io/ingress-nginx-admission created |
| serviceaccount/ingress-nginx-admission created |
| clusterrole.rbac.authorization.k8s.io/ingress-nginx-admission created |
| clusterrolebinding.rbac.authorization.k8s.io/ingress-nginx-admission created |
| role.rbac.authorization.k8s.io/ingress-nginx-admission created |
| rolebinding.rbac.authorization.k8s.io/ingress-nginx-admission created |
| job.batch/ingress-nginx-admission-create created |
| job.batch/ingress-nginx-admission-patch created |
| |
| |
| # 查看 ingress 相关service |
| root@master1:~# kubectl get svc -n ingress-nginx |
| NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE |
| ingress-nginx-controller NodePort 10.97.157.99 <none> 80:31481/TCP,443:30167/TCP 2m49s |
| ingress-nginx-controller-admission ClusterIP 10.105.196.203 <none> 443/TCP 2m49s |
| |
| # 查看ingress 相关pod |
| root@master1:~# kubectl get pods -n ingress-nginx |
| NAME READY STATUS RESTARTS AGE |
| ingress-nginx-admission-create-gbl78 0/1 Completed 0 2m21s |
| ingress-nginx-admission-patch-gxh9c 0/1 Completed 1 2m21s |
| ingress-nginx-controller-58656f96f7-2nk2s 1/1 Running 0 2m22s |
ingress 简单示例(基于端口)
| root@master1:~# vim test_deplpyment.yml |
| apiVersion: apps/v1 |
| kind: Deployment |
| metadata: |
| name: dp-test-for-ingress |
| spec: |
| replicas: 1 |
| selector: |
| matchLabels: |
| app: testapp # 创建出来的Deployment要匹配的labels |
| template: |
| metadata: |
| labels: |
| app: testapp # 模板自定义的labels,要和上面要匹配的labels名相同 |
| spec: |
| containers: |
| - image: nginx # 创建容器需要使用的的镜像,未指定tag就是用最新的 |
| name: test # 创建出来容器的名字 |
| ports: |
| - containerPort: 80 |
| resources: |
| requests: |
| cpu: 1 |
| limits: |
| cpu: 1 |
| --- |
| apiVersion: v1 |
| kind: Service # 创建的类型是svc |
| metadata: |
| name: svc-test-for-ingress # svc的名字 |
| spec: |
| ports: |
| - name: myngx # ports的名字 |
| port: 2280 |
| targetPort: 80 |
| selector: |
| app: testapp # 要匹配的后端svc名字 |
| type: NodePort # 指定service的 type 类型为 NodePort |
| |
| |
| |
| # 应用deployment文件 |
| kubectl apply -f test_deplpyment.yml |
| |
| # 查看Service状态和信息 |
| root@master1:~# kubectl get svc -o wide |
| NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR |
| kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 20h <none> |
| svc-test-for-ingress NodePort 10.99.197.166 <none> 2280:31031/TCP 42m app=testapp # 这里的31031是宿主机上的 |
| |
| |
| # 查看Deploy状态和信息 |
| root@master1:~# kubectl get deploy -o wide |
| NAME READY UP-TO-DATE AVAILABLE AGE CONTAINERS IMAGES SELECTOR |
| dp-test-for-ingress 1/1 1 1 43m test nginx app=testapp |
| |
| root@master1:~# kubectl get rs -o wide |
| NAME DESIRED CURRENT READY AGE CONTAINERS IMAGES SELECTOR |
| dp-test-for-ingress-5fb974bdf5 1 1 1 43m test nginx app=testapp,pod-template-hash=5fb974bdf5 |
| |
| |
| root@master1:~# kubectl get pod -o wide --show-labels |
| NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES LABELS |
| dp-test-for-ingress-5fb974bdf5-ktk6q 1/1 Running 0 43m 10.244.5.8 node3.lab.example.com <none> <none> app=testapp,pod-template-hash=5fb974bdf5 |
创建ingress
root@master1:~# vim rule-test.yaml
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: ing-test1 # Ingress的名字
spec:
rules:
- host: www.opoptest.com # 外网要访问的域名
http:
paths:
- pathType: Prefix
path: "/"
backend:
service:
name: testapp # 后端的svc(openshift中叫路由),外网访问上述域名后会通过svc来找到对应的pod
port:
number: 2280
ingressClassName: nginx # 一定要指定ingressClassName
注意:ingressClassName 一定要配置,如果不配置,创建的ingress的,无法找到class 和 无法分配Address
root@master1:~# kubectl apply -f rule-test.yaml
查看ingress
| root@master1:~# kubectl get ingress |
| NAME CLASS HOSTS ADDRESS PORTS AGE |
| ing-test1 nginx www.opoptest.com 10.97.157.99 80 47m |
| |
| |
| root@master1:~# kubectl describe ingress ing-test1 |
| Name: ing-test1 |
| Labels: <none> |
| Namespace: default |
| Address: 10.97.157.99 |
| Ingress Class: nginx |
| Default backend: <default> |
| Rules: |
| Host Path Backends |
| ---- ---- -------- |
| www.opoptest.com |
| / testapp:2280 (<error: endpoints "testapp" not found>) |
| Annotations: <none> |
| Events: |
| Type Reason Age From Message |
| ---- ------ ---- ---- ------- |
| Normal Sync 57m (x2 over 57m) nginx-ingress-controller Scheduled for sync |
| |
外部访问
| # 在宿主机上 |
| rambo@p360:~$ echo '172.16.186.112 www.opoptest.com' >> /etc/hosts |
| 浏览器访问:http://www.opoptest.com:31031/ |
| |
| 释义1: |
| 172.16.xx.xx: 是宿主机的ip地址 |
| www.opoptest.com: 是ingress暴露的服务名,外部可以通过这个服务名访问 |
| |
| 释义2: |
| 访问时使用NodeIP: NodePort方式访问。 而NodeIP就是在/etc/hosts文件中配置的宿主机上的IP地址 |
| 访问时使用的是ingress-nginx-controller这个service的NodePort端口号,即为:31031 |
ingress 简单示例(基于域名)
基于名称的虚拟托管, 基于名称的虚拟主机支持将针对多个主机名的 HTTP 流量路由到同一个IP地址上
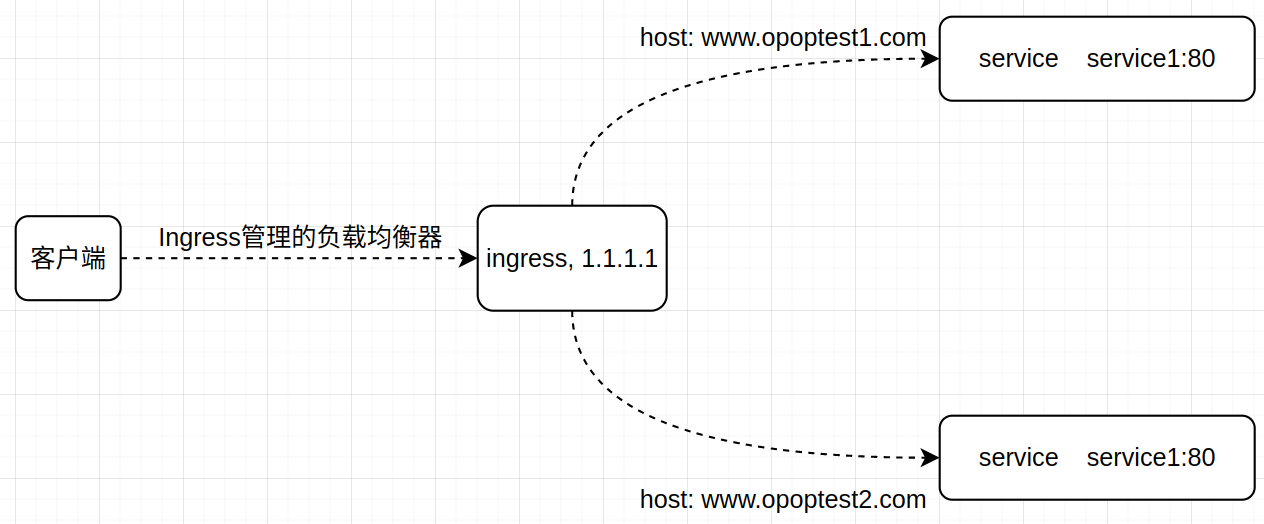
ingress 配置
| root@master1:~# kubectl create deployment test10 --image=ikubernetes/demoapp:v1.0 --replicas=2 |
| root@master1:~# kubectl create deployment test20 --image=ikubernetes/demoapp:v1.0 --replicas=2 |
| root@master1:~# kubectl create service nodeport test10 --tcp=80:80 |
| root@master1:~# kubectl create service nodeport test20 --tcp=80:80 |
| root@master1:~# kubectl get svc -o wide |
| NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR |
| kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 21h <none> |
| test10 NodePort 10.107.197.163 <none> 80:31338/TCP 8m3s app=test10 |
| test20 NodePort 10.106.240.90 <none> 80:31424/TCP 4s app=test20 |
| |
| |
| |
| |
| root@master1:~# vim domain.yml |
| apiVersion: networking.k8s.io/v1 |
| kind: Ingress |
| metadata: |
| name: test # Ingress的名字 |
| spec: |
| ingressClassName: ingress1 |
| rules: |
| - host: www.opoptest10.com # 外网访问的域名 |
| http: |
| paths: |
| - pathType: Prefix |
| path: "/" |
| backend: |
| service: |
| name: test10 # service的名字 |
| port: |
| number: 2180 |
| - host: www.opoptest20.com |
| http: |
| paths: |
| - pathType: Prefix |
| path: "/" |
| backend: |
| service: |
| name: test20 |
| port: |
| number: 2280 |
| |
| |
| root@master1:~# kubectl apply -f domain.yml |
| root@master1:~# kubectl get ingress |
| NAME CLASS HOSTS ADDRESS PORTS AGE |
| ing-test1 nginx www.opoptest.com 10.97.157.99 80 117m |
| test ingress1 www.opoptest10.com,www.opoptest20.com 80 5s |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 上周热点回顾(3.3-3.9)
· AI 智能体引爆开源社区「GitHub 热点速览」
2018-12-29 mac修改本机mysql的root密码