

Kubernetes v1.18.19二进制部署
k8s v1.18.19版本安装
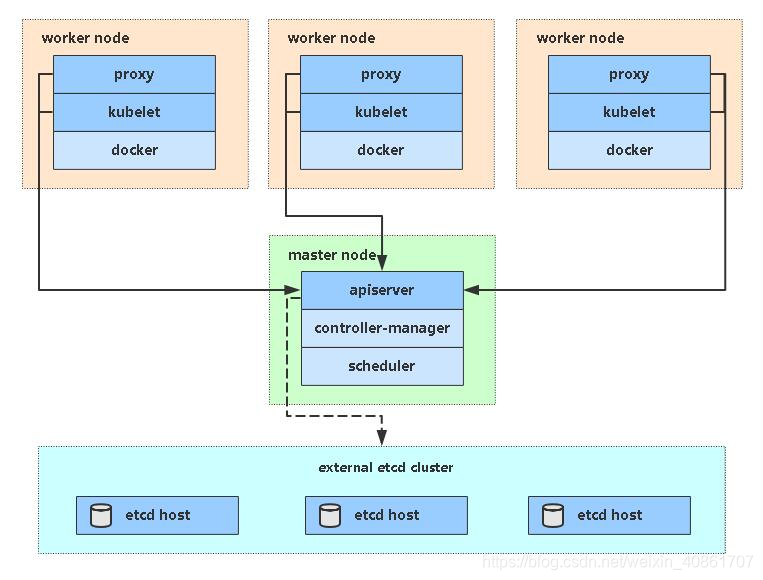
下图为本次构建的单Master架构图
注意事项
1、版本问题
2、apiserver的最大请求数、缓存等都需要自己精调
3、证书的位置
4、关闭swap
5、系统尽可能用英文版安装
6、docker-19-ce ==> k8s-1.18.19
虚拟机配置
| 主机名 | IP | M/U/D | 角色 | 组件 |
|---|---|---|---|---|
| master01.ik8s.com/master01 | 192.168.1.21 | 2G/2U/50G | master01 | kube-apiserver,etcd,kube-scheduler, kube-controller-manager |
| node01.ik8s.com/node01 | 192.168.1.22 | 2G/2U/50G | node01 | kubelet,kube-proxy,docker, etcd |
| node02.ik8s.com/node02 | 192.168.1.23 | 2G/2U/50G | node02 | kubelet,kube-proxy,docker, etcd |
| master02.ik8s.com/master02 | 192.168.1.24 | 2G/2U/50G | master02 | kube-apiserver,etcd,kube-scheduler, kube-controller-manager |
| nginx01.ik8s.com/nginx01 | 192.168.1.25 | 1G/1U/50G | nginx-master | nginx、keepalived |
| nginx02.ik8s.com/nginx02 | 192.168.1.26 | 1G/1U/50G | nginx-slave | nginx、keepalived |
| 192.168.1.27 | VIP |
前期工作
前期工作应在所有节点上做
主机名解析 hostnamectl set-hostname master01 hostnamectl set-hostname node01 hostnamectl set-hostname node02 cat >> /etc/hosts << EOF 192.168.1.21 master01.ik8s.com master01 192.168.1.22 node01.ik8s.com node01 192.168.1.23 node02.ik8s.com node02 192.168.1.24 master02.ik8s.com master02 EOF 关闭防火墙、selinux和关闭swap # 默认OS没安装iptables systemctl stop firewalld && systemctl disable firewalld sed -i "s/^\(SELINUX=\).*/\1disabled/" /etc/selinux/config setenforce 0 swapoff -a sed -ri 's/.*swap.*/#&/' /etc/fstab 将桥接的IPv4流量传递到iptables的链(开启网桥对2层的过滤) cat > /etc/sysctl.d/k8s.conf << EOF net.ipv4.ip_forward = 1 net.bridge.bridge-nf-call-ip6tables = 1 net.bridge.bridge-nf-call-iptables = 1 EOF modprobe br_netfilter sysctl --system 或者 sysctl -p /etc/sysctl.d/k8s.conf Tips: 内核参数vm.swappiness可控制换出运行时内存的相对权重,参数值大小对如何使用swap分区有很大联系。值越大表示越积极使用swap分区,越小表示越积极使用物理内存。 swappiness=0 表示最大限度使用物理内存,然后才用swap空间; vm.swappiness = 1 表示进行最少量的交换,而不禁用交换,内核版本3.5+、Red Hat内核版本2.6.32-303+ vm.swappiness = 10 当系统存在足够内存时,推荐设置为该值以提高性能 swappiness= 60 内存使用率超过 `100-60=40%` 时开始使用交换分区(默认值) swappiness=100 优先使用swap分区,并把内存上的数据及时搬运到swap空间。 内核下载(所有节点) wget https://elrepo.org/linux/kernel/el7/x86_64/RPMS/kernel-ml-5.12.13-1.el7.elrepo.x86_64.rpm https://elrepo.org/linux/kernel/el7/x86_64/RPMS/kernel-ml-devel-5.13.0-1.el7.elrepo.x86_64.rpm kernel-lt(lt=long-term)长期有效 kernel-ml(ml=mainline)主流版本 安装 yum -y install kernel-ml-5.12.13-1.el7.elrepo.x86_64.rpm kernel-ml-devel-5.13.0-1.el7.elrepo.x86_64.rpm 查看系统上的所有可用内核 awk -F\' '$1=="menuentry " {print i++ " : " $2}' /etc/grub2.cfg 更换内核 grub2-set-default 0 reboot uname -r 删除旧内核(可选,该文档为删除) rpm -qa | grep kernel 方法1、yum remove 删除旧内核的 RPM 包 kernel-3.10.0-514.el7.x86_64 kernel-ml-4.18.7-1.el7.elrepo.x86_64 kernel-tools-libs-3.10.0-862.11.6.el7.x86_64 kernel-tools-3.10.0-862.11.6.el7.x86_64 kernel-3.10.0-862.11.6.el7.x86_64 方法2、yum-utils 工具 注:如果安装的内核不多于 3 个,yum-utils 工具不会删除任何一个。只有在安装的内核大于 3 个时才会进行删除旧内核的操作 yum -y install yum-utils package-cleanup --oldkernels IPVS的支持开启(该文档未改为IPVS) cat > /etc/sysconfig/modules/ipvs.modules << EOF #!/bin/bash IPVS_DIR="/usr/lib/modules/$(uname -r)/kernel/net/netfilter/ipvs" for kernel_mod in \$(ls \$IPVS_DIR | grep -o "^[^.]*");do /sbin/modinfo -F filemane \${kernel_mod} > /dev/null 2>&1 if [ 0 -eq 0 ];then /sbin/modprobe \${kernel_mod} fi done EOF chmod 755 /etc/sysconfig/modules/ipvs.modules bash /etc/sysconfig/modules/ipvs.modules lsmod | egrep '^(ip_vs|nf)'
做免密登陆
只在master01节点上执行
[root@master01 ~]# ssh-keygen -t rsa -P '' for i in {1..2};do ssh-copy-id node0$i;done ssh-copy-id master01 ssh-copy-id master01.ik8s.com for i in {1..3};do ssh-copy-id 192.168.1.2$i;done for i in {1..3};do ssh 192.168.1.2$i hostname;done
时间同步
# master01节点同步阿里云时间服务器,其他节点都同步master01节点的时间 [root@master01 ~]# vim /etc/chrony.conf #server 0.centos.pool.ntp.org iburst #server 1.centos.pool.ntp.org iburst #server 2.centos.pool.ntp.org iburst #server 3.centos.pool.ntp.org iburst server ntp.aliyun.com iburst [root@master01 ~]# systemctl restart chronyd && systemctl enable chronyd [root@node01 ~]# vim /etc/chrony.conf #server 0.centos.pool.ntp.org iburst #server 1.centos.pool.ntp.org iburst #server 2.centos.pool.ntp.org iburst #server 3.centos.pool.ntp.org iburst server master01 iburst [root@node01 ~]# systemctl restart chronyd && systemctl enable chronyd
证书制作
cfssl是一个开源的证书管理工具,使用json文件生成证书,相比openssl更方便使用
1、下载生成证书的工具 [root@master01 ~]# cat > 1.sh << EOF #!/bin/bash wget https://github.com/cloudflare/cfssl/releases/download/v1.6.0/cfssl_1.6.0_linux_amd64 -O /usr/bin/cfssl wget https://github.com/cloudflare/cfssl/releases/download/v1.6.0/cfssljson_1.6.0_linux_amd64 -O /usr/bin/cfssljson wget https://github.com/cloudflare/cfssl/releases/download/v1.6.0/cfssl-certinfo_1.6.0_linux_amd64 -O /usr/bin/cfssl-certinfo chmod +x /usr/bin/cfssl* cfssl version EOF [root@master01 ~]# sh 1.sh 2、生成etcd证书 2.1 自签证书颁发机构(CA) [root@master01 ~]# mkdir -p /k8s/{etcd,k8s}/{bin,cfg,ssl,logs} && cd /k8s/etcd/ssl [root@master01 ~]# for i in {1..2};do ssh root@node0$i mkdir -p /k8s/{etcd,k8s}/{bin,cfg,ssl,logs};done (1)自签证书颁发机构 [root@master01 ssl]# cat > ca-config.json <<EOF { "signing": { "default": { "expiry": "175200h" }, "profiles": { "www": { "expiry": "175200h", "usages": [ "signing", "key encipherment", "server auth", "client auth" ] } } } } EOF 制作颁发证书请求文件 [root@master01 ssl]# cat > ca-csr.json <<EOF { "CN": "etcd CA", "key": { "algo": "rsa", "size": 2048 }, "names": [ { "C": "CN", "ST": "Guangzhou", "L": "Guangzhou", "O": "wangzha", "OU": "Kubernetes The Hard Way" } ], "ca": { "expiry": "175200h" } } EOF 释义: C(Country - 国家名称) ST(State - 省份名称) L(Locality - 城市名称) OU(Organization Unit - 组织单位名称) O(Organization - 组织名称) CN(Common Name - 名字与姓氏) 生成CA证书 [root@master01 ssl]# cfssl gencert -initca ca-csr.json | cfssljson -bare ca - [root@master01 cert]# ll -rw-r--r-- 1 root root 296 7月 1 22:38 ca-config.json -rw-r--r-- 1 root root 1045 7月 1 22:43 ca.csr # CA证书签名请求 -rw-r--r-- 1 root root 309 7月 1 22:41 ca-csr.json -rw------- 1 root root 1675 7月 1 22:43 ca-key.pem # CA的key -rw-r--r-- 1 root root 1306 7月 1 22:43 ca.pem # CA证书 2.2 使用自签CA签发Etcd HTTPS证书 制作颁发证书请求文件 [root@master01 ssl]# cat > server-csr.json << EOF { "CN": "etcd", "hosts": [ "127.0.0.1", "192.168.1.1", "192.168.1.21", "192.168.1.22", "192.168.1.23", "192.168.1.24" ], "key": { "algo": "rsa", "size": 2048 }, "names": [ { "C": "CN", "L": "Guangzhou", "ST": "Guangzhou" } ] } EOF 注:上述文件hosts字段中IP为所有etcd节点的集群内部通信IP,一个都不能少!为了方便后期扩容可以多写几个预留的IP。 生成证书 [root@master01 ssl]# cfssl gencert -ca=ca.pem -ca-key=ca-key.pem -config=ca-config.json -profile=www server-csr.json | cfssljson -bare server [root@master01 ssl]# ll | egrep server'(-|.)'*pem -rw------- 1 root root 1679 7月 2 22:27 server-key.pem -rw-r--r-- 1 root root 1419 7月 2 22:27 server.pem
etcd集群的部署
该文档将使用3台机器来做etcd集群,现在master上做好然后将所有文件拷贝到其他node节点上
https://github.com/etcd-io/etcd/releases/tag/v3.4.9
[root@master01 ssl]# cd [root@master01 etcd]# wget https://github.com/etcd-io/etcd/releases/download/v3.4.9/etcd-v3.4.9-linux-amd64.tar.gz [root@master01 etcd]# tar -zxvf etcd-v3.4.9-linux-amd64.tar.gz [root@master01 etcd]# cp etcd-v3.4.9-linux-amd64/{etcd,etcdctl} bin/ [root@master01 etcd]# mv etcd* ~ 创建etcd配置文件 [root@master01 etcd]# cat > /k8s/etcd/cfg/etcd.cfg << EOF #[Member] ETCD_NAME="etcd01" ETCD_DATA_DIR="/var/lib/etcd/default.etcd" ETCD_LISTEN_PEER_URLS="https://192.168.1.21:2380" ETCD_LISTEN_CLIENT_URLS="https://192.168.1.21:2379,https://127.0.0.1:2379" #[Clustering] ETCD_INITIAL_ADVERTISE_PEER_URLS="https://192.168.1.21:2380" ETCD_ADVERTISE_CLIENT_URLS="https://192.168.1.21:2379" ETCD_INITIAL_CLUSTER="etcd01=https://192.168.1.21:2380,etcd02=https://192.168.1.22:2380,etcd03=https://192.168.1.23:2380" ETCD_INITIAL_CLUSTER_TOKEN="etcd-cluster" ETCD_INITIAL_CLUSTER_STATE="new" EOF 释义: • ETCD_NAME #节点名称 • ETCD_DATA_DIR #数据目录 • ETCD_LISTEN_PEER_URLS #集群通信监听地址 • ETCD_LISTEN_CLIENT_URLS #客户端访问监听地址 • ETCD_INITIAL_ADVERTISE_PEER_URLS #集群通告地址 • ETCD_ADVERTISE_CLIENT_URLS #客户端通告地址 • ETCD_INITIAL_CLUSTER #集群节点地址 • ETCD_INITIAL_CLUSTER_TOKEN #集群Token • ETCD_INITIAL_CLUSTER_STATE 加入#集群的当前状态,new是新集群,existing表示加入已有集群 # systemd管理etcd 所有master节点的etcd.service配置文件一样 [root@master01 etcd]# cat > /usr/lib/systemd/system/etcd.service << EOF [Unit] Description=Etcd Server After=network.target After=network-online.target Wants=network-online.target [Service] Type=notify EnvironmentFile=/k8s/etcd/cfg/etcd.cfg ExecStart=/k8s/etcd/bin/etcd \ --cert-file=/k8s/etcd/ssl/server.pem \ --key-file=/k8s/etcd/ssl/server-key.pem \ --peer-cert-file=/k8s/etcd/ssl/server.pem \ --peer-key-file=/k8s/etcd/ssl/server-key.pem \ --trusted-ca-file=/k8s/etcd/ssl/ca.pem \ --peer-trusted-ca-file=/k8s/etcd/ssl/ca.pem Restart=on-failure LimitNOFILE=65536 [Install] WantedBy=multi-user.target EOF 将上面master节点所有生成的文件拷贝到其他node节点上 [root@master01 etcd]# for i in 1 2;do scp -r /k8s/etcd/cfg/* root@node0$i:/k8s/etcd/cfg/;done [root@master01 etcd]# for i in 1 2;do scp -r /k8s/etcd/ssl/{ca,server}*.pem root@node0$i:/k8s/etcd/ssl/;done [root@master01 etcd]# for i in 1 2;do scp /usr/lib/systemd/system/etcd.service root@node0$i:/usr/lib/systemd/system/;done [root@master01 etcd]# for i in 1 2;do scp /k8s/etcd/bin/{etcd,etcdctl} root@node0$i:/k8s/etcd/bin/;done 在所有node节点上分别修改etcd.cfg文件中的节点名称和当前服务器IP: # node01上的配置 [root@node01 ~]# vim /k8s/etcd/cfg/etcd.cfg #[Member] ETCD_NAME="etcd02" ETCD_DATA_DIR="/var/lib/etcd/default.etcd" ETCD_LISTEN_PEER_URLS="https://172.16.186.114:2380" ETCD_LISTEN_CLIENT_URLS="https://172.16.186.114:2379,https://127.0.0.1:2379" #[Clustering] ETCD_INITIAL_ADVERTISE_PEER_URLS="https://172.16.186.114:2380" ETCD_ADVERTISE_CLIENT_URLS="https://172.16.186.114:2379" ETCD_INITIAL_CLUSTER="etcd01=https://172.16.186.111:2380,etcd02=https://172.16.186.114:2380,etcd03=https://172.16.186.115:2380" ETCD_INITIAL_CLUSTER_TOKEN="etcd-cluster" ETCD_INITIAL_CLUSTER_STATE="new" # node02上的配置 [root@node02 ~]# vim /k8s/etcd/cfg/etcd.cfg #[Member] ETCD_NAME="etcd03" ETCD_DATA_DIR="/var/lib/etcd/default.etcd" ETCD_LISTEN_PEER_URLS="https://172.16.186.115:2380" ETCD_LISTEN_CLIENT_URLS="https://172.16.186.115:2379,https://127.0.0.1:2379" #[Clustering] ETCD_INITIAL_ADVERTISE_PEER_URLS="https://172.16.186.115:2380" ETCD_ADVERTISE_CLIENT_URLS="https://172.16.186.115:2379" ETCD_INITIAL_CLUSTER="etcd01=https://172.16.186.111:2380,etcd02=https://172.16.186.114:2380,etcd03=https://172.16.186.115:2380" ETCD_INITIAL_CLUSTER_TOKEN="etcd-cluster" ETCD_INITIAL_CLUSTER_STATE="new" 配置文件配置完成后,所有节点启动etcd并设置开机启动 systemctl daemon-reload systemctl enable etcd systemctl start etcd #注意: 这里如果单节点首次启动的话,需要等待比较长的时间,最后状态是失败.这是正常情况(可以想象3个节点的ZK集群,如果只有一个节点启动,集群也是不可用的) # 任意节点上查看etcd的状态 [root@master01 etcd]# systemctl status etcd ● etcd.service - Etcd Server Loaded: loaded (/usr/lib/systemd/system/etcd.service; enabled; vendor preset: disabled) Active: active (running) since 五 2021-07-02 23:07:25 EDT; 28s ago Main PID: 18385 (etcd) CGroup: /system.slice/etcd.service └─18385 /k8s/etcd/bin/etcd --cert-file=/k8s/etcd/ssl/server.pem --key-file=/k8s/etcd/ssl/server-key.pem --peer-cert-file=/k8s/etcd/ssl/server.pe... 7月 02 23:07:25 master01 etcd[18385]: raft2021/07/02 23:07:25 INFO: raft.node: 53e17f386c3a5d6c elected leader 53e17f386c3a5d6c at term 2 7月 02 23:07:25 master01 etcd[18385]: published {Name:etcd01 ClientURLs:[https://172.16.186.111:2379]} to cluster ddcf7374f4c0555f 7月 02 23:07:25 master01 etcd[18385]: ready to serve client requests 7月 02 23:07:25 master01 etcd[18385]: serving client requests on 172.16.186.111:2379 7月 02 23:07:25 master01 etcd[18385]: ready to serve client requests 7月 02 23:07:25 master01 etcd[18385]: serving client requests on 127.0.0.1:2379 7月 02 23:07:25 master01 systemd[1]: Started Etcd Server. 7月 02 23:07:25 master01 etcd[18385]: setting up the initial cluster version to 3.4 7月 02 23:07:25 master01 etcd[18385]: set the initial cluster version to 3.4 7月 02 23:07:25 master01 etcd[18385]: enabled capabilities for version 3.4 任意节点查看集群状态 [root@master01 etcd]# /k8s/etcd/bin/etcdctl --cacert=/k8s/etcd/ssl/ca.pem --cert=/k8s/etcd/ssl/server.pem --key=/k8s/etcd/ssl/server-key.pem --endpoints="https://192.168.1.21:2379,https://192.168.1.22:2379,https://192.168.1.22:2379" endpoint health [root@master01 etcd]# /k8s/etcd/bin/etcdctl --cacert=/k8s/etcd/ssl/ca.pem --cert=/k8s/etcd/ssl/server.pem --key=/k8s/etcd/ssl/server-key.pem --endpoints="https://192.168.1.21:2379,https://192.168.1.22:2379,https://192.168.1.22:2379" member list [root@master01 ~]# /k8s/etcd/bin/etcdctl --cacert=/k8s/etcd/ssl/ca.pem --cert=/k8s/etcd/ssl/server.pem --key=/k8s/etcd/ssl/server-key.pem --endpoints="https://192.168.1.21:2379,https://192.168.1.22:2379,https://192.168.1.23:2379" endpoint status --write-out=table 如需排错 systemctl status etcd.service # 查看节点etcd状态 journalctl -u etcd journalctl -xe
安装docker
该文档采用二进制方式在所有节点上安装docker
下载docker安装包 https://download.docker.com/linux/static/stable/x86_64/ [root@master01 etcd]# cd [root@master01 ~]# wget https://download.docker.com/linux/static/stable/x86_64/docker-19.03.11.tgz [root@master01 ~]# tar -zxvf docker-19.03.11.tgz [root@master01 ~]# cp docker/* /usr/local/bin/ [root@master01 ~]# docker --version Docker version 19.03.11, build 42e35e61f3 发送到其他所有node节点上 [root@master01 ~]# for i in 1 2;do scp docker/* root@node0$i:/usr/local/bin/;done systemd管理docker [root@master01 ~]# cat > /usr/lib/systemd/system/docker.service << EOF [Unit] Description=Docker Application Container Engine Documentation=https://docs.docker.com After=network-online.target firewalld.service Wants=network-online.target [Service] Type=notify ExecStart=/usr/local/bin/dockerd --data-root /apps/docker ExecReload=/bin/kill -s HUP \$MAINPID LimitNOFILE=infinity LimitNPROC=infinity TimeoutStartSec=0 Delegate=yes KillMode=process Restart=on-failure StartLimitBurst=3 StartLimitInterval=60s [Install] WantedBy=multi-user.target EOF 发送到其他所有node节点上 [root@master01 ~]# for i in 1 2;do scp /usr/lib/systemd/system/docker.service root@node0$i:/usr/lib/systemd/system/docker.service;done 修改docker文件驱动(所有节点修改) [root@master01 ~]# for i in {1..3};do ssh root@192.168.1.2$i mkdir /etc/docker/;done [root@master01 ~]# cat > /etc/docker/daemon.json << EOF { "registry-mirrors" : [ "https://registry.docker-cn.com", "https://docker.mirrors.ustc.edu.cn", "http://hub-mirror.c.163.com", "https://cr.console.aliyun.com/", "https://0trl8ny5.mirror.aliyuncs.com" ], "exec-opts": ["native.cgroupdriver=systemd"] } EOF [root@master01 ~]# for i in 1 2;do scp /etc/docker/daemon.json root@node0$i:/etc/docker/;done 所有节点启动docker systemctl daemon-reload systemctl start docker && systemctl enable docker 所有节点确认 [root@master01 ~]# for i in {1..3};do systemctl status docker | grep "Active";done [root@master01 ~]# for i in {1..3};do docker info | grep "Cgroup Driver";done
部署Master 节点
生成kube-apiserver证书
自签证书颁发机构(CA) [root@master01 ~]# cd /k8s/k8s/ssl/ [root@master01 ssl]# cat > ca-config.json <<EOF { "signing": { "default": { "expiry": "175200h" }, "profiles": { "kubernetes": { "expiry": "175200h", "usages": [ "signing", "key encipherment", "server auth", "client auth" ] } } } } EOF 制作颁发证书请求文件 [root@master01 ~]# cat > ca-csr.json <<EOF { "CN": "kubernetes", "key": { "algo": "rsa", "size": 2048 }, "names": [ { "C": "CN", "ST": "Guangzhou", "L": "Guangzhou", "O": "wangzha" } ], "ca": { "expiry": "175200h" } } EOF 生成证书: [root@master01 ssl]# cfssl gencert -initca ca-csr.json | cfssljson -bare ca - [root@master01 ssl]# ll -rw-r--r-- 1 root root 296 7月 7 22:00 ca-config.json -rw-r--r-- 1 root root 1033 7月 7 22:00 ca.csr -rw-r--r-- 1 root root 291 7月 7 22:00 ca-csr.json -rw------- 1 root root 1679 7月 7 22:00 ca-key.pem -rw-r--r-- 1 root root 1285 7月 7 22:00 ca.pem 使用自签CA签发kube-apiserver HTTPS证书 [root@master01 ssl]# pwd /k8s/k8s/ssl 制作颁发证书请求文件 [root@master01 ssl]# cat > server-csr.json << EOF { "CN": "kubernetes", "hosts": [ "10.0.0.1", "127.0.0.1", "192.168.1.1", "192.168.1.21", "192.168.1.22", "192.168.1.23", "192.168.1.24", "192.168.1.25", "kubernetes", "kubernetes.default", "kubernetes.default.svc", "kubernetes.default.svc.cluster", "kubernetes.default.svc.cluster.local" ], "key": { "algo": "rsa", "size": 2048 }, "names": [ { "C": "CN", "L": "Guangzhou", "ST": "Guangzhou", "O": "k8s", "OU": "System" } ] } EOF 注:上述文件hosts字段中IP为所有k8s集群服务器的地址,为了方便后期扩容可多写几个作为预留IP #生成证书 [root@master01 ssl]# cfssl gencert -ca=ca.pem -ca-key=ca-key.pem -config=ca-config.json -profile=kubernetes server-csr.json | cfssljson -bare server [root@master01 ssl]# ll -rw-r--r-- 1 root root 296 7月 7 22:00 ca-config.json -rw-r--r-- 1 root root 1033 7月 7 22:00 ca.csr -rw-r--r-- 1 root root 291 7月 7 22:00 ca-csr.json -rw------- 1 root root 1679 7月 7 22:00 ca-key.pem -rw-r--r-- 1 root root 1285 7月 7 22:00 ca.pem -rw-r--r-- 1 root root 1289 7月 7 22:02 server.csr -rw-r--r-- 1 root root 623 7月 7 22:02 server-csr.json -rw------- 1 root root 1679 7月 7 22:02 server-key.pem -rw-r--r-- 1 root root 1647 7月 7 22:02 server.pem
配置 k8s组件
https://github.com/kubernetes/kubernetes/blob/master/CHANGELOG/CHANGELOG-1.18.md#server-binaries-1
如无法下载可执行该步 https://k8s.io.ipaddress.com/dl.k8s.io ===> /etc/hosts
# 下载k8s的安装包 [root@master01 ssl]# cd [root@master01 ~]# pwd /k8s/k8s [root@master01 ~]# wget https://dl.k8s.io/v1.18.19/kubernetes-server-linux-amd64.tar.gz [root@master01 ~]# tar -zxvf kubernetes-server-linux-amd64.tar.gz [root@master01 ~]# cp kubernetes/server/bin/{kube-apiserver,kube-scheduler,kube-controller-manager} /k8s/k8s/bin/ [root@master01 ~]# cp kubernetes/server/bin/kubectl /usr/local/bin/ 部署kube-apiserver 1、创建配置文件 [root@master01 ~]# cat > /k8s/k8s/cfg/kube-apiserver.cfg << EOF KUBE_APISERVER_OPTS="--logtostderr=false \\ --v=2 \\ --log-dir=/k8s/k8s/logs \\ --etcd-servers=https://192.168.1.21:2379,https://192.168.1.22:2379,https://192.168.1.23:2379 \\ --bind-address=192.168.1.21 \\ --secure-port=6443 \\ --advertise-address=192.168.1.21 \\ --allow-privileged=true \ --service-cluster-ip-range=10.0.0.0/24 \\ --enable-admission-plugins=NamespaceLifecycle,LimitRanger,ServiceAccount,ResourceQuota,NodeRestriction \\ --authorization-mode=RBAC,Node \\ --enable-bootstrap-token-auth=true \\ --token-auth-file=/k8s/k8s/cfg/token.csv \\ --service-node-port-range=30000-32767 \\ --kubelet-client-certificate=/k8s/k8s/ssl/server.pem \\ --kubelet-client-key=/k8s/k8s/ssl/server-key.pem \\ --tls-cert-file=/k8s/k8s/ssl/server.pem \\ --tls-private-key-file=/k8s/k8s/ssl/server-key.pem \\ --client-ca-file=/k8s/k8s/ssl/ca.pem \\ --service-account-key-file=/k8s/k8s/ssl/ca-key.pem \\ --etcd-cafile=/k8s/etcd/ssl/ca.pem \\ --etcd-certfile=/k8s/etcd/ssl/server.pem \\ --etcd-keyfile=/k8s/etcd/ssl/server-key.pem \\ --audit-log-maxage=30 \\ --audit-log-maxbackup=3 \\ --audit-log-maxsize=100 \\ --audit-log-path=/k8s/k8s/logs/k8s-audit.log" EOF # 参数说明 --logtostderr:启用日志 ---v:日志等级 --log-dir:日志目录 --etcd-servers:etcd集群地址 --bind-address:监听地址 --secure-port:https安全端口 --advertise-address:集群通告地址 --allow-privileged:启用授权 --service-cluster-ip-range:Service虚拟IP地址段 --enable-admission-plugins:准入控制模块 --authorization-mode:认证授权,启用RBAC授权和节点自管理 --enable-bootstrap-token-auth:启用TLS bootstrap机制 --token-auth-file:bootstrap token文件 --service-node-port-range:Service nodeport类型默认分配端口范围 --kubelet-client-xxx:apiserver访问kubelet客户端证书 --tls-xxx-file:apiserver https证书 --etcd-xxxfile:连接Etcd集群证书 --audit-log-xxx:审计日志
启用 TLS Bootstrapping 机制
1、首先生成自己的token [root@master01 ~]# head -c 16 /dev/urandom | od -An -t x | tr -d ' ' 12c940e938c533cf294ac01370cde146 2、创建上述配置文件中token文件 [root@master01 k8s]# cat > /k8s/k8s/cfg/token.csv << EOF 12c940e938c533cf294ac01370cde146,kubelet-bootstrap,10001,"system:node-bootstrapper" EOF # 格式:token,用户名,UID,用户组
systemd管理apiserver
[root@master01 ~]# cat > /usr/lib/systemd/system/kube-apiserver.service << EOF [Unit] Description=Kubernetes API Server Documentation=https://github.com/kubernetes/kubernetes [Service] EnvironmentFile=/k8s/k8s/cfg/kube-apiserver.cfg ExecStart=/k8s/k8s/bin/kube-apiserver \$KUBE_APISERVER_OPTS Restart=on-failure [Install] WantedBy=multi-user.target EOF 启动并设置开机启动 [root@master01 ~]# systemctl daemon-reload systemctl enable kube-apiserver systemctl start kube-apiserver 注意:这里启动时可能会失败! 并且有时不会给出提示,所以要确认kube-apiserver是否启动成功 [root@master01 ~]# systemctl status kube-apiserver ● kube-apiserver.service - Kubernetes API Server Loaded: loaded (/usr/lib/systemd/system/kube-apiserver.service; enabled; vendor preset: disabled) Active: active (running) since 三 2021-07-07 22:06:13 EDT; 11s ago Docs: https://github.com/kubernetes/kubernetes Main PID: 2459 (kube-apiserver) Tasks: 10 Memory: 317.2M CGroup: /system.slice/kube-apiserver.service └─2459 /k8s/k8s/bin/kube-apiserver --logtostderr=false --v=2 --log-dir=/k8s/k8s/log... 7月 07 22:06:13 master01 systemd[1]: Started Kubernetes API Server. 7月 07 22:06:17 master01 kube-apiserver[2459]: E0707 22:06:17.350834 2459 controller.go:...g: Hint: Some lines were ellipsized, use -l to show in full. Tips: 1、如启动失败需使用下面或逐行检查/var/log/messages cat /var/log/messages|grep kube-apiserver|egrep '(error|no such)' 2、多次执行systemctl status kube-apiserver命令会看到如下提示,这里没有影响 Unable to remove old endpoints from kubernetes service: StorageError: key not found, Code: 1, Key: /registry/masterleases/172.16.186.111, ResourceVersion: 0, AdditionalErrorMsg: [root@master01 ~]# netstat -anpt | egrep '(8080|6443)' tcp 0 0 192.168.1.21:6443 0.0.0.0:* LISTEN 2459/kube-apiserver tcp 0 0 127.0.0.1:8080 0.0.0.0:* LISTEN 2459/kube-apiserver tcp 0 0 192.168.1.21:6443 192.168.1.21:57568 ESTABLISHED 2459/kube-apiserver tcp 0 0 192.168.1.21:57568 192.168.1.21:6443 ESTABLISHED 2459/kube-apiserver 授权kubelet-bootstrap用户允许请求证书 [root@master01 ~]# kubectl create clusterrolebinding kubelet-bootstrap \ --clusterrole=system:node-bootstrapper \ --user=kubelet-bootstrap 回显: clusterrolebinding.rbac.authorization.k8s.io/kubelet-bootstrap created
部署kube-controller-manager
1、创建配置文件 [root@master01 ~]# cat > /k8s/k8s/cfg/kube-controller-manager.conf << EOF KUBE_CONTROLLER_MANAGER_OPTS="--logtostderr=false \\ --v=2 \\ --log-dir=/k8s/k8s/logs \\ --leader-elect=true \\ --master=127.0.0.1:8080 \\ --bind-address=127.0.0.1 \\ --allocate-node-cidrs=true \\ --cluster-cidr=10.244.0.0/16 \\ --service-cluster-ip-range=10.0.0.0/24 \\ --cluster-signing-cert-file=/k8s/k8s/ssl/ca.pem \\ --cluster-signing-key-file=/k8s/k8s/ssl/ca-key.pem \\ --root-ca-file=/k8s/k8s/ssl/ca.pem \\ --service-account-private-key-file=/k8s/k8s/ssl/ca-key.pem \\ --experimental-cluster-signing-duration=87600h0m0s" EOF 注: --master:通过本地非安全本地端口8080连接apiserver。 --leader-elect:当该组件启动多个时,自动选举(HA) --cluster-signing-cert-file/--cluster-signing-key-file:自动为kubelet颁发证书的CA,与apiserver 保持一致 systemd管理controller-manager [root@master01 ~]# cat > /usr/lib/systemd/system/kube-controller-manager.service << EOF [Unit] Description=Kubernetes Controller Manager Documentation=https://github.com/kubernetes/kubernetes [Service] EnvironmentFile=/k8s/k8s/cfg/kube-controller-manager.conf ExecStart=/k8s/k8s/bin/kube-controller-manager \$KUBE_CONTROLLER_MANAGER_OPTS Restart=on-failure [Install] WantedBy=multi-user.target EOF 启动并设置开机启动 [root@master01 ~]# systemctl daemon-reload systemctl enable kube-controller-manager systemctl start kube-controller-manager
存在的问题
没影响继续往下操作,暂未找到解决方法
[root@master01 k8s]# systemctl status kube-controller-manager kube-apiserver -l ● kube-controller-manager.service - Kubernetes Controller Manager Loaded: loaded (/usr/lib/systemd/system/kube-controller-manager.service; enabled; vendor preset: disabled) Active: active (running) since 三 2021-07-07 22:12:34 EDT; 32s ago Docs: https://github.com/kubernetes/kubernetes Main PID: 2581 (kube-controller) Tasks: 9 Memory: 28.0M CGroup: /system.slice/kube-controller-manager.service └─2581 /k8s/k8s/bin/kube-controller-manager --logtostderr=false --v=2 --log-dir=/k8s/k8s/logs --leader-elect=true --master=127.0.0.1:8080 --bind-address=127.0.0.1 --allocate-node-cidrs=true --cluster-cidr=10.244.0.0/16 --service-cluster-ip-range=10.0.0.0/24 --cluster-signing-cert-file=/k8s/k8s/ssl/ca.pem --cluster-signing-key-file=/k8s/k8s/ssl/ca-key.pem --root-ca-file=/k8s/k8s/ssl/ca.pem --service-account-private-key-file=/k8s/k8s/ssl/ca-key.pem --experimental-cluster-signing-duration=87600h0m0s 7月 07 22:12:34 master01 systemd[1]: Started Kubernetes Controller Manager. 7月 07 22:12:36 master01 kube-controller-manager[2581]: E0707 22:12:36.360749 2581 core.go:89] Failed to start service controller: WARNING: no cloud provider provided, services of type LoadBalancer will fail 7月 07 22:12:46 master01 kube-controller-manager[2581]: E0707 22:12:46.378024 2581 core.go:229] failed to start cloud node lifecycle controller: no cloud provider provided 注:上2行有提示... ● kube-apiserver.service - Kubernetes API Server Loaded: loaded (/usr/lib/systemd/system/kube-apiserver.service; enabled; vendor preset: disabled) Active: active (running) since 三 2021-07-07 22:06:13 EDT; 6min ago Docs: https://github.com/kubernetes/kubernetes Main PID: 2459 (kube-apiserver) Tasks: 10 Memory: 294.8M CGroup: /system.slice/kube-apiserver.service └─2459 /k8s/k8s/bin/kube-apiserver --logtostderr=false --v=2 --log-dir=/k8s/k8s/logs --etcd-servers=https://192.168.1.21:2379,https://192.168.1.22:2379,https://192.168.1.23:2379 --bind-address=192.168.1.21 --secure-port=6443 --advertise-address=192.168.1.21 --allow-privileged=true --service-cluster-ip-range=10.0.0.0/24 --enable-admission-plugins=NamespaceLifecycle,LimitRanger,ServiceAccount,ResourceQuota,NodeRestriction --authorization-mode=RBAC,Node --enable-bootstrap-token-auth=true --token-auth-file=/k8s/k8s/cfg/token.csv --service-node-port-range=30000-32767 --kubelet-client-certificate=/k8s/k8s/ssl/server.pem --kubelet-client-key=/k8s/k8s/ssl/server-key.pem --tls-cert-file=/k8s/k8s/ssl/server.pem --tls-private-key-file=/k8s/k8s/ssl/server-key.pem --client-ca-file=/k8s/k8s/ssl/ca.pem --service-account-key-file=/k8s/k8s/ssl/ca-key.pem --etcd-cafile=/k8s/etcd/ssl/ca.pem --etcd-certfile=/k8s/etcd/ssl/server.pem --etcd-keyfile=/k8s/etcd/ssl/server-key.pem --audit-log-maxage=30 --audit-log-maxbackup=3 --audit-log-maxsize=100 --audit-log-path=/k8s/k8s/logs/k8s-audit.log 7月 07 22:06:13 master01 systemd[1]: Started Kubernetes API Server. 7月 07 22:06:17 master01 kube-apiserver[2459]: E0707 22:06:17.350834 2459 controller.go:152] Unable to remove old endpoints from kubernetes service: StorageError: key not found, Code: 1, Key: /registry/masterleases/192.168.1.21, ResourceVersion: 0, AdditionalErrorMsg: 注:上2行有提示... [root@master01 ~]# tail -n150 /var/log/messages Jul 3 01:33:21 master01 kube-apiserver: E0703 01:33:21.104424 19654 controller.go:152] Unable to remove old endpoints from kubernetes service: StorageError: key not found, Code: 1, Key: /registry/masterleases/172.16.186.111, ResourceVersion: 0, AdditionalErrorMsg: Jul 3 01:33:47 master01 kube-controller-manager: E0703 01:33:47.479521 19647 core.go:89] Failed to start service controller: WARNING: no cloud provider provided, services of type LoadBalancer will fail Jul 3 01:33:47 master01 kube-controller-manager: E0703 01:33:47.491278 19647 core.go:229] failed to start cloud node lifecycle controller: no cloud provider provided
部署scheduler
创建配置文件 [root@master01 ~]# cat > /k8s/k8s/cfg/kube-scheduler.cfg << EOF KUBE_SCHEDULER_OPTS="--logtostderr=false \\ --v=2 \\ --log-dir=/k8s/k8s/logs \\ --leader-elect \\ --master=127.0.0.1:8080 \\ --bind-address=127.0.0.1" EOF # 配置说明 --master:通过本地非安全本地端口8080连接apiserver。 --leader-elect:当该组件启动多个时,自动选举(HA) systemd管理scheduler [root@master01 ~]# cat > /usr/lib/systemd/system/kube-scheduler.service << EOF [Unit] Description=Kubernetes Scheduler Documentation=https://github.com/kubernetes/kubernetes [Service] EnvironmentFile=/k8s/k8s/cfg/kube-scheduler.cfg ExecStart=/k8s/k8s/bin/kube-scheduler \$KUBE_SCHEDULER_OPTS Restart=on-failure [Install] WantedBy=multi-user.target EOF 启动并设置开机启动 [root@master01 ~]# systemctl daemon-reload systemctl enable kube-scheduler systemctl start kube-scheduler [root@master01 k8s]# systemctl status kube-scheduler -l ● kube-scheduler.service - Kubernetes Scheduler Loaded: loaded (/usr/lib/systemd/system/kube-scheduler.service; enabled; vendor preset: disabled) Active: active (running) since 三 2021-07-07 22:16:17 EDT; 4s ago Docs: https://github.com/kubernetes/kubernetes Main PID: 2637 (kube-scheduler) Tasks: 9 Memory: 11.8M CGroup: /system.slice/kube-scheduler.service └─2637 /k8s/k8s/bin/kube-scheduler --logtostderr=false --v=2 --log-dir=/k8s/k8s/logs --leader-elect --master=127.0.0.1:8080 --bind-address=127.0.0.1 7月 07 22:16:17 master01 systemd[1]: Started Kubernetes Scheduler. 7月 07 22:16:17 master01 kube-scheduler[2637]: I0707 22:16:17.427067 2637 registry.go:150] Registering EvenPodsSpread predicate and priority function 7月 07 22:16:17 master01 kube-scheduler[2637]: I0707 22:16:17.427183 2637 registry.go:150] Registering EvenPodsSpread predicate and priority function 注:上面的输出中会看到问题,不过没影响往下的操作 查看集群状态 [root@master01 k8s]# kubectl get cs NAME STATUS MESSAGE ERROR controller-manager Healthy ok scheduler Healthy ok etcd-0 Healthy {"health":"true"} etcd-1 Healthy {"health":"true"} etcd-2 Healthy {"health":"true"}
部署Worker Node节点
下面的操作如果没有特别强调,还是在Master Node上进行,master节点也当作一个node节点
以下2条命令在master节点上执行 [root@master01 ~]# cp kubernetes/server/bin/{kubelet,kube-proxy} /k8s/k8s/bin/ 部署kubelet 参数说明 --hostname-override:显示名(唯一性),就是本机的主机名,如写成其他则启动时将找不到 --network-plugin:启用CNI --kubeconfig:空路径,会自动生成,后面用于连接apiserver --bootstrap-kubeconfig:首次启动向apiserver申请证书 --config:配置参数文件 --cert-dir:kubelet证书生成目录 --pod-infra-container-image:管理Pod网络容器的镜像 注:注意下一个命令中的hostname-override选项 [root@master01 ~]# cat > /k8s/k8s/cfg/kubelet.cfg << EOF KUBELET_OPTS="--logtostderr=false \\ --v=2 \\ --log-dir=/k8s/k8s/logs \\ --hostname-override=master01 \\ --network-plugin=cni \\ --kubeconfig=/k8s/k8s/cfg/kubelet.kubeconfig \\ --bootstrap-kubeconfig=/k8s/k8s/cfg/bootstrap.kubeconfig \\ --config=/k8s/k8s/cfg/kubelet-config.yml \\ --cert-dir=/k8s/k8s/ssl \\ --pod-infra-container-image=lizhenliang/pause-amd64:3.0" EOF \# registry.access.redhat.com/rhel7/pod-infrastructure:latest 配置参数文件 [root@master01 ~]# cat > /k8s/k8s/cfg/kubelet-config.yml << EOF kind: KubeletConfiguration apiVersion: kubelet.config.k8s.io/v1beta1 address: 0.0.0.0 port: 10250 readOnlyPort: 10255 cgroupDriver: systemd clusterDNS: - 10.0.0.2 clusterDomain: cluster.local failSwapOn: false authentication: anonymous: enabled: false webhook: cacheTTL: 2m0s enabled: true x509: clientCAFile: /k8s/k8s/ssl/ca.pem authorization: mode: Webhook webhook: cacheAuthorizedTTL: 5m0s cacheUnauthorizedTTL: 30s evictionHard: imagefs.available: 15% memory.available: 100Mi nodefs.available: 10% nodefs.inodesFree: 5% maxOpenFiles: 1000000 maxPods: 110 EOF 生成bootstrap.kubeconfig文件 [root@master01 ~]# KUBE_APISERVER="https://192.168.1.21:6443" # apiserver IP:PORT [root@master01 ~]# TOKEN="12c940e938c533cf294ac01370cde146" # 与token.csv里保持一致 注:如更换了窗口则需要重新定义KUBE_APISERVER和TOKEN的变量,然后重新生成 kubelet bootstrap kubeconfig 配置文件 ### 生成 kubelet bootstrap kubeconfig 配置文件 注:生成bootstrap.kubeconfig文件时一定要在/k8s/k8s/cfg/kubelet.cfg文件中--bootstrap-kubeconfig项定义的目录中执行,不然就得mv到--bootstrap-kubeconfig项指的位置,这里要注意 [root@master01 ~]# cd /k8s/k8s/cfg/ [root@master01 cfg]# kubectl config set-cluster kubernetes \ --certificate-authority=/k8s/k8s/ssl/ca.pem \ --embed-certs=true --server=${KUBE_APISERVER} \ --kubeconfig=bootstrap.kubeconfig [root@master01 cfg]# kubectl config set-credentials "kubelet-bootstrap" \ --token=${TOKEN} --kubeconfig=bootstrap.kubeconfig # 设置上下文 [root@master01 cfg]# kubectl config set-context default --cluster=kubernetes \ --user="kubelet-bootstrap" --kubeconfig=bootstrap.kubeconfig # 切换上下文 [root@master01 cfg]# kubectl config use-context default --kubeconfig=bootstrap.kubeconfig systemd管理kubelet [root@master01 cfg]# cat > /usr/lib/systemd/system/kubelet.service << EOF [Unit] Description=Kubernetes Kubelet After=docker.service [Service] EnvironmentFile=/k8s/k8s/cfg/kubelet.cfg ExecStart=/k8s/k8s/bin/kubelet \$KUBELET_OPTS Restart=on-failure LimitNOFILE=65536 [Install] WantedBy=multi-user.target EOF 启动并设置开机启动 [root@master01 cfg]# systemctl daemon-reload systemctl enable kubelet systemctl start kubelet [root@master01 cfg]# systemctl status kubelet ● kubelet.service - Kubernetes Kubelet Loaded: loaded (/usr/lib/systemd/system/kubelet.service; enabled; vendor preset: disabled) Active: active (running) since 三 2021-07-07 23:45:49 EDT; 3min 24s ago Main PID: 17793 (kubelet) Tasks: 9 Memory: 19.9M CGroup: /system.slice/kubelet.service └─17793 /k8s/k8s/bin/kubelet --logtostderr=false --v=2 --log-dir=/k8s/k8s/logs --hostname-override=master01 --n... 7月 07 23:45:49 master01 systemd[1]: Started Kubernetes Kubelet. 批准kubelet证书申请并加入集群 1、查看kubelet证书请求 [root@master01 k8s]# kubectl get csr NAME AGE SIGNERNAME REQUESTOR CONDITION node-csr-ELAp2OgRZbZc2pXjrzaRh 4m2s kubernetes.io/kube-apiserver-client-kubelet kubelet-bootstrap Pending 注:该请求NAME列太长,在排版时进行了删减过,NAME列全称如下 NAME列的名字全称是:node-csr-ELAp2OgRZbZc2pXjrzaRh4LZQt9n_eCVMVGB3sTYB6Q 批准申请 [root@master01 k8s]# kubectl certificate approve node-csr-ELAp2OgRZbZc2pXjrzaRh4LZQt9n_eCVMVGB3sTYB6Q 再来查看kubelet证书请求 状态已经从Pending变为了Approved,Issued [root@master01 k8s]# kubectl get csr NAME AGE SIGNERNAME REQUESTOR CONDITION node-csr-ELAp2OgRZbZc2pXjrzaRh 4m59s kubernetes.io/kube-apiserver-client-kubelet kubelet-bootstrap Approved,Issued [root@master01 k8s]# kubectl get nodes NAME STATUS ROLES AGE VERSION master01 NotReady <none> 108s v1.18.19 注:由于网络插件还没有部署,上面的STATUS列会是 NotReady
部署kube-proxy
[root@master01 cfg]# cat > /k8s/k8s/cfg/kube-proxy.cfg << EOF KUBE_PROXY_OPTS="--logtostderr=false \\ --v=2 \\ --log-dir=/k8s/k8s/logs \\ --config=/k8s/k8s/cfg/kube-proxy-config.yml" EOF 配置上面提到的kube-proxy.conf参数文件 [root@master01 cfg]# cat > /k8s/k8s/cfg/kube-proxy-config.yml << EOF kind: KubeProxyConfiguration apiVersion: kubeproxy.config.k8s.io/v1alpha1 bindAddress: 0.0.0.0 metricsBindAddress: 0.0.0.0:10249 clientConnection: kubeconfig: /k8s/k8s/cfg/kube-proxy.kubeconfig hostnameOverride: master01 clusterCIDR: 10.0.0.0/24 EOF 生成kube-proxy.kubeconfig文件 [root@master01 cfg]# cd /k8s/k8s/ssl/ 创建证书请求文件 [root@master01 ssl]# cat > kube-proxy-csr.json << EOF { "CN": "system:kube-proxy", "hosts": [], "key": { "algo": "rsa", "size": 2048 }, "names": [ { "C": "CN", "L": "Guangzhou", "ST": "Guangzhou", "O": "k8s", "OU": "System" } ] } EOF 生成kube-proxy证书 [root@master01 ssl]# cfssl gencert -ca=ca.pem -ca-key=ca-key.pem -config=ca-config.json -profile=kubernetes kube-proxy-csr.json | cfssljson -bare kube-proxy # 查看证书 [root@master01 ssl]# ll kube-proxy*pem -rw------- 1 root root 1679 7月 3 03:01 kube-proxy-key.pem -rw-r--r-- 1 root root 1395 7月 3 03:01 kube-proxy.pem 生成kubeconfig文件: [root@master01 ssl]# KUBE_APISERVER="https://172.16.186.111:6443" 注:该变量在生成bootstrap.kubeconfig文件时已定义过,这里不再重复执行,执行前需确定该变量是否存在:echo $KUBE_APISERVER [root@master01 ssl]# kubectl config set-cluster kubernetes \ --certificate-authority=/k8s/k8s/ssl/ca.pem \ --embed-certs=true \ --server=${KUBE_APISERVER} \ --kubeconfig=kube-proxy.kubeconfig 注:该命令执行后会在当前目录中生成一个名为 kube-proxy.kubeconfig 的文件,需要注意 [root@master01 ssl]# kubectl config set-credentials kube-proxy \ --client-certificate=/k8s/k8s/ssl/kube-proxy.pem \ --client-key=/k8s/k8s/ssl/kube-proxy-key.pem \ --embed-certs=true \ --kubeconfig=kube-proxy.kubeconfig [root@master01 ssl]# kubectl config set-context default \ --cluster=kubernetes \ --user=kube-proxy \ --kubeconfig=kube-proxy.kubeconfig [root@master01 ssl]# kubectl config use-context default --kubeconfig=kube-proxy.kubeconfig 拷贝kube-proxy.kubeconfig文件到指定路径 [root@master01 ssl]# mv kube-proxy.kubeconfig /k8s/k8s/cfg/ [root@master01 ssl]# cd .. systemd管理kube-proxy [root@master01 ~]# cat > /usr/lib/systemd/system/kube-proxy.service << EOF [Unit] Description=Kubernetes Proxy After=network.target [Service] EnvironmentFile=/k8s/k8s/cfg/kube-proxy.cfg ExecStart=/k8s/k8s/bin/kube-proxy \$KUBE_PROXY_OPTS Restart=on-failure LimitNOFILE=65536 [Install] WantedBy=multi-user.target EOF 启动并设置开机启动 [root@master01 ~]# systemctl daemon-reload systemctl enable kube-proxy systemctl start kube-proxy [root@master01 k8s]# systemctl status kube-proxy ● kube-proxy.service - Kubernetes Proxy Loaded: loaded (/usr/lib/systemd/system/kube-proxy.service; enabled; vendor preset: disabled) Active: active (running) since 三 2021-07-07 23:55:45 EDT; 4s ago Main PID: 19058 (kube-proxy) Tasks: 8 Memory: 11.5M CGroup: /system.slice/kube-proxy.service └─19058 /k8s/k8s/bin/kube-proxy --logtostderr=false --v=2 --log-dir=/k8s/k8s/logs --config=/k8s/k8s/cfg/kube-pr... 7月 07 23:55:45 master01 systemd[1]: Started Kubernetes Proxy.
部署CNI网络
注: 如无法下载下面的kube-flannel.yml则需打开 https://githubusercontent.com.ipaddress.com/raw.githubusercontent.com 把解析到的地址(一般为4个)放到自己电脑的hosts文件中,格式如:185.199.108.133 raw.githubusercontent.com
合集下载地址:https://github.com/containernetworking/plugins/releases # cni的默认目录为/opt/cni/bin,所有节点的都应将cni-plugins-linux-amd64-v0.8.6.tgz解压至/opt/cni/bin目录中 [root@master01 ~]# for i in {1..3};do ssh root@192.168.1.2$i mkdir -p /opt/cni/bin;done #所有节点执行 [root@master01 ~]# wget https://github.com/containernetworking/plugins/releases/download/v0.8.6/cni-plugins-linux-amd64-v0.8.6.tgz [root@master01 ~]# tar zxvf cni-plugins-linux-amd64-v0.8.6.tgz -C /opt/cni/bin [root@master01 ~]# for i in {1..2};do scp /opt/cni/bin/* root@node0$i:/opt/cni/bin/;done [root@master01 ~]# wget https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml [root@master01 ~]# cp kube-flannel.yml{,.bak} [root@master01 ~]# ll -h kube-flannel.yml -rw-r--r-- 1 root root 4813 7月 8 00:01 kube-flannel.yml [root@master01 ~]# sed -i -r "s#quay.io/coreos/flannel:v0.14.0#lizhenliang/flannel:v0.14.0#g" kube-flannel.yml 为避免网络异常,这里先手动将flannel:v0.14.0镜像先pull下来 [root@master01 ~]# docker pull lizhenliang/flannel:v0.14.0 [root@master01 ~]# kubectl apply -f kube-flannel.yml podsecuritypolicy.policy/psp.flannel.unprivileged created clusterrole.rbac.authorization.k8s.io/flannel created clusterrolebinding.rbac.authorization.k8s.io/flannel created serviceaccount/flannel created configmap/kube-flannel-cfg created daemonset.apps/kube-flannel-ds created 查看pod详细信息 [root@master01 ~]# kubectl get pods -n kube-system -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES kube-flannel-ds-njsnc 1/1 Running 0 52m 192.168.1.21 master01 <none> <none> 5分钟后... [root@master01 ~]# kubectl get pods -n kube-system -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES kube-flannel-ds-qtm49 1/1 Running 0 4m48s 172.16.186.111 master01 <none> <none> ==================== 参考项 =============================== kubectl describe pods -n kube-system kubectl get pods --all-namespaces -o wide kubectl get pods -n 命名空间 -o wide Tips:Pod状态 CrashLoopBackOff: 容器退出,kubelet正在将它重启 InvalidImageName: 无法解析镜像名称 ImageInspectError: 无法校验镜像 ErrImageNeverPull: 策略禁止拉取镜像 ImagePullBackOff: 正在重试拉取 RegistryUnavailable: 连接不到镜像中心 ErrImagePull: 通用的拉取镜像出错 CreateContainerConfigError: 不能创建kubelet使用的容器配置 CreateContainerError: 创建容器失败 m.internalLifecycle.PreStartContainer 执行hook报错 RunContainerError: 启动容器失败 PostStartHookError: 执行hook报错 ContainersNotInitialized: 容器没有初始化完毕 ContainersNotReady: 容器没有准备完毕 ContainerCreating:容器创建中 PodInitializing:pod 初始化中 DockerDaemonNotReady:docker还没有完全启动 NetworkPluginNotReady: 网络插件还没有完全启动 kubectl explain pods: 查看pod帮助选项 =============================================================
授权apiserver访问kubelet
[root@master01 ~]# cd /k8s/k8s/cfg/ [root@master01 cfg]# pwd /k8s/k8s/cfg [root@master01 cfg]# cat > apiserver-to-kubelet-rbac.yaml << EOF apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: annotations: rbac.authorization.kubernetes.io/autoupdate: "true" labels: kubernetes.io/bootstrapping: rbac-defaults name: system:kube-apiserver-to-kubelet rules: - apiGroups: - "" resources: - nodes/proxy - nodes/stats - nodes/log - nodes/spec - nodes/metrics - pods/log verbs: - "*" --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: name: system:kube-apiserver namespace: "" roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: system:kube-apiserver-to-kubelet subjects: - apiGroup: rbac.authorization.k8s.io kind: User name: kubernetes EOF [root@master01 cfg]# kubectl apply -f apiserver-to-kubelet-rbac.yaml clusterrole.rbac.authorization.k8s.io/system:kube-apiserver-to-kubelet created clusterrolebinding.rbac.authorization.k8s.io/system:kube-apiserver created
新增加Worker Node
拷贝已部署好的Node相关文件到新节点 [root@master01 cfg]# for i in 1 2;do scp -r /k8s/k8s/bin/{kubelet,kube-proxy} root@node0$i:/k8s/k8s/bin/;done [root@master01 cfg]# for i in 1 2;do scp -r /k8s/k8s/cfg/* root@node0$i:/k8s/k8s/cfg/;done [root@master01 cfg]# for i in 1 2;do scp -r /k8s/k8s/ssl/ca.pem root@node0$i:/k8s/k8s/ssl/;done [root@master01 cfg]# for i in 1 2;do scp -r /usr/lib/systemd/system/{kubelet,kube-proxy}.service root@node0$i:/usr/lib/systemd/system/;done 在所有worker node上删除kubelet证书和kubeconfig文件(以node01节点为例) 注:这几个文件是证书申请审批后自动生成的,每个Node不同,必须删除重新生成。 [root@node01 ~]# rm -rf /k8s/k8s/cfg/kubelet.kubeconfig [root@node01 ~]# rm -rf /k8s/k8s/ssl/kubelet* 在所有worker node节点上修改配置文件中的主机名(以node01节点为例) [root@node01 ~]# vim /k8s/k8s/cfg/kubelet.cfg --hostname-override=node01 [root@node01 ~]# vim /k8s/k8s/cfg/kube-proxy-config.yml hostnameOverride: node01 在所有worker node节点上启动kubelet和kube-proxy并设置开机启动 [root@node01 ~]# systemctl daemon-reload systemctl enable kube-proxy systemctl enable kubelet systemctl start kubelet systemctl start kube-proxy [root@node01 ~]# systemctl status kubelet kube-proxy ● kubelet.service - Kubernetes Kubelet Loaded: loaded (/usr/lib/systemd/system/kubelet.service; enabled; vendor preset: disabled) Active: active (running) since 六 2021-07-03 18:08:57 CST; 47s ago Main PID: 12547 (kubelet) Tasks: 9 Memory: 17.9M CGroup: /system.slice/kubelet.service └─12547 /k8s/k8s/bin/kubelet --logtostderr=false --v=2 --log-dir=/k8s/k8s/logs --hostname-override=node01 --network-plugin=cni --kubeconfi... 7月 03 18:08:57 node01 systemd[1]: Started Kubernetes Kubelet. ● kube-proxy.service - Kubernetes Proxy Loaded: loaded (/usr/lib/systemd/system/kube-proxy.service; enabled; vendor preset: disabled) Active: active (running) since 六 2021-07-03 18:09:13 CST; 31s ago Main PID: 12564 (kube-proxy) Tasks: 7 Memory: 10.8M CGroup: /system.slice/kube-proxy.service └─12564 /k8s/k8s/bin/kube-proxy --logtostderr=false --v=2 --log-dir=/k8s/k8s/logs --config=/k8s/k8s/cfg/kube-proxy-config.yml 7月 03 18:09:13 node01 systemd[1]: Started Kubernetes Proxy. 7月 03 18:09:13 node01 kube-proxy[12564]: E0703 18:09:13.601671 12564 node.go:125] Failed to retrieve node info: nodes "node01" not found 7月 03 18:09:14 node01 kube-proxy[12564]: E0703 18:09:14.771792 12564 node.go:125] Failed to retrieve node info: nodes "node01" not found 7月 03 18:09:17 node01 kube-proxy[12564]: E0703 18:09:17.116482 12564 node.go:125] Failed to retrieve node info: nodes "node01" not found 7月 03 18:09:21 node01 kube-proxy[12564]: E0703 18:09:21.626704 12564 node.go:125] Failed to retrieve node info: nodes "node01" not found 7月 03 18:09:30 node01 kube-proxy[12564]: E0703 18:09:30.468243 12564 node.go:125] Failed to retrieve node info: nodes "node01" not found 注:这里的报错暂时未影响到,原因是master节点上还没通过批准 回到Master上批准新Node kubelet证书申请 [root@master01 cfg]# kubectl get csr NAME AGE SIGNERNAME REQUESTOR CONDITION node-csr-I5zG32aMCCevmo7WLLxS6vv0N43tzuCqvOGHdAQ3qSE 13m kubernetes.io/kube-apiserver-client-kubelet kubelet-bootstrap Pending node-csr-_54g7zto6pfzu8VSnTqfYIw63TX48u8WwcPtzhMFKMg 49s kubernetes.io/kube-apiserver-client-kubelet kubelet-bootstrap Pending 批准 [root@master01 cfg]# kubectl certificate approve node-csr-I5zG32aMCCevmo7WLLxS6vv0N43tzuCqvOGHdAQ3qSE [root@master01 cfg]# kubectl certificate approve node-csr-_54g7zto6pfzu8VSnTqfYIw63TX48u8WwcPtzhMFKMg 再来查看请求 [root@master01 cfg]# kubectl get csr NAME AGE SIGNERNAME REQUESTOR CONDITION node-csr-I5zG32aMCCevmo7WLLxS6vv0 14m kubernetes.io/kube-apiserver-client-kubelet kubelet-bootstrap Approved,Issued node-csr-_54g7zto6pfzu8VSnTqfYIw6 97s kubernetes.io/kube-apiserver-client-kubelet kubelet-bootstrap Approved,Issued 注: 因排版问题上图进行了删减 查看Node状态 [root@master01 cfg]# kubectl get node NAME STATUS ROLES AGE VERSION master01 Ready <none> 34m v1.18.19 node01 NotReady <none> 2m25s v1.18.19 node02 NotReady <none> 2m20s v1.18.19 注:执行该命令第一时间节点的状态可能为NotReady,这不一定是有问题,过一段时间刷新即可! ============================================================================== 如长时间未未变为Ready可单独查看某台node的,命令: [root@master01 cfg]# kubectl describe nodes node01 ============================================================================== 5分钟后.... [root@master01 cfg]# kubectl get nodes NAME STATUS ROLES AGE VERSION master01 Ready <none> 63m v1.18.19 node01 Ready <none> 31m v1.18.19 node02 Ready <none> 31m v1.18.19 [root@master01 cfg]# kubectl get pod -n kube-system NAME READY STATUS RESTARTS AGE kube-flannel-ds-dxvtn 1/1 Running 0 114m kube-flannel-ds-njsnc 1/1 Running 4 3h7m kube-flannel-ds-v2gcr 1/1 Running 0 58m 查看整体情况时会看到部分报错 systemctl status kube-apiserver kube-controller-manager kube-scheduler kubelet kube-proxy etcd
部署Dashboard和CoreDNS
1、在master节点上部署Dashboard [root@master01 cfg]# wget https://raw.githubusercontent.com/kubernetes/dashboard/v2.0.0-beta8/aio/deploy/recommended.yaml 默认Dashboard只能集群内部访问,修改Service为NodePort类型,暴露到外部: [root@master01 cfg]# vim recommended.yaml .... .... kind: Service apiVersion: v1 metadata: labels: k8s-app: kubernetes-dashboard name: kubernetes-dashboard namespace: kubernetes-dashboard spec: ports: - port: 443 targetPort: 8443 nodePort: 30001 type: NodePort selector: k8s-app: kubernetes-dashboard ---
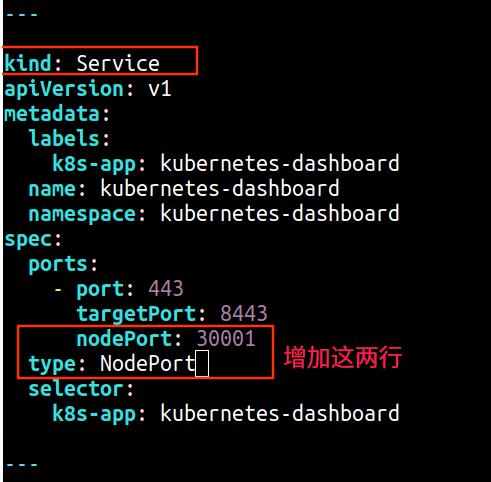
[root@master01 cfg]# kubectl apply -f recommended.yaml namespace/kubernetes-dashboard created serviceaccount/kubernetes-dashboard created service/kubernetes-dashboard created secret/kubernetes-dashboard-certs created secret/kubernetes-dashboard-csrf created secret/kubernetes-dashboard-key-holder created configmap/kubernetes-dashboard-settings created role.rbac.authorization.k8s.io/kubernetes-dashboard created clusterrole.rbac.authorization.k8s.io/kubernetes-dashboard created rolebinding.rbac.authorization.k8s.io/kubernetes-dashboard created clusterrolebinding.rbac.authorization.k8s.io/kubernetes-dashboard created deployment.apps/kubernetes-dashboard created service/dashboard-metrics-scraper created deployment.apps/dashboard-metrics-scraper created [root@master01 cfg]# kubectl get pods,svc -n kubernetes-dashboard NAME READY STATUS RESTARTS AGE pod/dashboard-metrics-scraper-694557449d-hvzhv 0/1 ContainerCreating 0 6s pod/kubernetes-dashboard-9774cc786-tls7t 0/1 ContainerCreating 0 6s NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE service/dashboard-metrics-scraper ClusterIP 10.0.0.200 <none> 8000/TCP 6s service/kubernetes-dashboard NodePort 10.0.0.16 <none> 443:30001/TCP 6s 注:上图显示正在创建容器,稍等一会再查看 5分钟后.... [root@master01 cfg]# kubectl get pods,svc -n kubernetes-dashboard NAME READY STATUS RESTARTS AGE pod/dashboard-metrics-scraper-694557449d-hvzhv 1/1 Running 0 5m41s pod/kubernetes-dashboard-9774cc786-tls7t 1/1 Running 0 5m41s NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE service/dashboard-metrics-scraper ClusterIP 10.0.0.200 <none> 8000/TCP 5m41s service/kubernetes-dashboard NodePort 10.0.0.16 <none> 443:30001/TCP 5m41s 访问地址:https://NodeIP:30001 注:这里现在能打开了页面了,但不建议下载登陆,待执行完下面service account并绑定默认cluster-admin管理员集群角色后再登陆 创建service account并绑定默认cluster-admin管理员集群角色 [root@master01 ~]# kubectl create serviceaccount dashboard-admin -n kube-system serviceaccount/dashboard-admin created [root@master01 ~]# kubectl create clusterrolebinding dashboard-admin --clusterrole=cluster-admin --serviceaccount=kube-system:dashboard-admin clusterrolebinding.rbac.authorization.k8s.io/dashboard-admin created [root@master01 ~]# kubectl describe secrets -n kube-system $(kubectl -n kube-system get secret | awk '/dashboard-admin/{print $1}') Name: dashboard-admin-token-lltwn Namespace: kube-system Labels: <none> Annotations: kubernetes.io/service-account.name: dashboard-admin kubernetes.io/service-account.uid: 850a3785-8f94-49a0-a844-b963dab7e236 Type: kubernetes.io/service-account-token Data ==== ca.crt: 1285 bytes namespace: 11 bytes token: eyJhbGciOiJSUzI1NiIsImtpZCI6Iko4aDhNUzdraHQ1TzZ6dVh4aEpXM3ZFVVNxbzAzOU1PMUNCdmRUV0JqTjQifQ.eyJpc3MiOiJrdWJlcm5ldGVzL3NlcnZpY2VhY2NvdW50Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9uYW1lc3BhY2UiOiJrdWJlLXN5c3RlbSIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VjcmV0Lm5hbWUiOiJkYXNoYm9hcmQtYWRtaW4tdG9rZW4tbGx0d24iLCJrdWJlcm5ldGVzLmlvL3NlcnZpY2VhY2NvdW50L3NlcnZpY2UtYWNjb3VudC5uYW1lIjoiZGFzaGJvYXJkLWFkbWluIiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9zZXJ2aWNlLWFjY291bnQudWlkIjoiODUwYTM3ODUtOGY5NC00OWEwLWE4NDQtYjk2M2RhYjdlMjM2Iiwic3ViIjoic3lzdGVtOnNlcnZpY2VhY2NvdW50Omt1YmUtc3lzdGVtOmRhc2hib2FyZC1hZG1pbiJ9.CxUJ8En7nwU-03ghy49fv_bZnbRDPFCgvr7iov3pIWqcy9NGNSJKH6j6LXLmmWmv5PQbK4a4xRCAuIsMsbsmsJOO0Hg6eFi0_oZhQBY9dYbZdzpdJHJ9HsKHJ5yTfrlc7hJaVmpNkpnj8BT0qVb6Buc-w1QUoW34lW5N-94JYiE7q4puXsw3p3IJLzelTccFOCu67weMLpwWEpunN3C3eWNX3DguInsaWXbBPbfYFzUr9Nccj8fXYBdasGlvfOtr475vAmu9_zLybwtkv_bbTB7dDobREs-CjR4SzTrDOu4xlVJ-eXoZpmz4_Rryz4FKCzvx2psAmV2jKPMyogkCFA 使用上面输出的token登录Dashboard,下图点"高级"也没用....
Data ==== ca.crt: 1285 bytes namespace: 11 bytes token: eyJhbGciOiJSUzI1NiIsImtpZCI6IkVMQ2xlbzRKQThabHZCTWU2M2Q2aWlCdV9oaGl6Z3BuUUdZREtxSDJFckUifQ.eyJpc3MiOiJrdWJlcm5ldGVzL3NlcnZpY2VhY2NvdW50Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9uYW1lc3BhY2UiOiJrdWJlLXN5c3RlbSIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VjcmV0Lm5hbWUiOiJkYXNoYm9hcmQtYWRtaW4tdG9rZW4tdzhweGwiLCJrdWJlcm5ldGVzLmlvL3NlcnZpY2VhY2NvdW50L3NlcnZpY2UtYWNjb3VudC5uYW1lIjoiZGFzaGJvYXJkLWFkbWluIiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9zZXJ2aWNlLWFjY291bnQudWlkIjoiZTk1OWZjNjItYWM0MC00OTMzLWFiNmEtMmNjMzY0ZjFhNzUzIiwic3ViIjoic3lzdGVtOnNlcnZpY2VhY2NvdW50Omt1YmUtc3lzdGVtOmRhc2hib2FyZC1hZG1pbiJ9.MGP3UR3FfCQmbx8rnFYHnZsQnUfFfv1c12p3_M636Bj1GfWNw0Yv3PmlqcYdE_OB3hfkzfqApp37ZL0BAs-FRYA2EwgRefzkbVcX_Af5lNIGKETDoFnYWRhCwXhijwUHIpzLsMx_AtMdx00-Cq5ppuaQNPWrezJUiCaiG8uEsjD1Enbvbfeayvu4c3Q8aH-1klksVSV_Lwyi_AZ56o408aDKw-9Kd1j2jYJSvU3zuDuVa2e0_59sdIBUO9nAODeVBVMKpGqdypdzmj61LVO4bMkSAOspQYbgqlcngkSLKG6PNml3hbXukphzxolOwst43UGZs-uf90SdiVeA8isdAg
部署CoreDNS
CoreDNS用于集群内部Service名称解析
[root@master01 ~]# kubectl apply -f coredns.yaml
serviceaccount/coredns created
clusterrole.rbac.authorization.k8s.io/system:coredns created
clusterrolebinding.rbac.authorization.k8s.io/system:coredns created
configmap/coredns created
deployment.apps/coredns created
service/kube-dns created
[root@master01 ~]# kubectl get pods -n kube-system -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
coredns-5ffbfd976d-lwgvt 1/1 Running 0 75s 10.244.1.3 node01
kube-flannel-ds-dxvtn 1/1 Running 0 171m 192.168.1.23 node02
kube-flannel-ds-njsnc 1/1 Running 4 4h4m 192.168.1.21 master01
kube-flannel-ds-v2gcr 1/1 Running 0 116m 192.168.1.22 node01
DNS解析测试:
[root@master01 ~]# kubectl run -it --rm dns-test --image=busybox:1.28.4 sh
If you don't see a command prompt, try pressing enter.
/ # nslookup kubernetes # 这里输入
Server: 10.0.0.2
Address 1: 10.0.0.2 kube-dns.kube-system.svc.cluster.local # 解析结果
Name: kubernetes
Address 1: 10.0.0.1 kubernetes.default.svc.cluster.local
/ # exit
Session ended, resume using 'kubectl attach dns-test -c dns-test -i -t' command when the pod is running
pod "dns-test" deleted
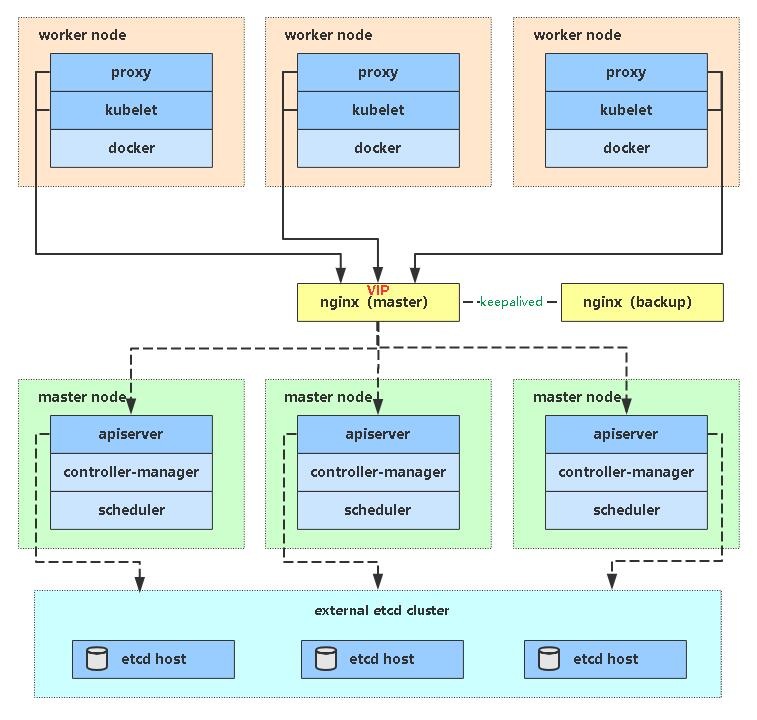
高可用架构(扩容多Master架构)
Kubernetes作为容器集群系统,通过健康检查+重启策略实现了Pod故障自我修复能力,通过调度算法实现将Pod分布式部署,并保持预期副本数,根据Node失效状态自动在其他Node拉起Pod,实现了应用层的高可用性。 针对Kubernetes集群,高可用性还应包含以下两个层面的考虑:Etcd数据库的高可用性和Kubernetes Master组件的高可用性。 而Etcd我们已经采用3个节点组建集群实现高可用,本节将对Master节点高可用进行说明和实施。 Master节点扮演着总控中心的角色,通过不断与工作节点上的Kubelet和kube-proxy进行通信来维护整个集群的健康工作状态。如果Master节点故障,将无法使用kubectl工具或者API做任何集群管理。 Master节点主要有三个服务kube-apiserver、kube-controller-manager和kube-scheduler,其中kube-controller-manager和kube-scheduler组件自身通过选择机制已经实现了高可用,所以Master高可用主要针对kube-apiserver组件,而该组件是以HTTP API提供服务,因此对他高可用与Web服务器类似,增加负载均衡器对其负载均衡即可,并且可水平扩容。
多Master架构图:
master02上操作
前期工作 中的所有都得挨着做一遍
1、升级内核 关闭防火墙、selinux、swap 将桥接的IPv4流量传递到iptables的链 升级内核 2、安装Docker 和master01一样,从master01上将所以需要的文件发送到master02节点上 [root@master01 ~]# scp ~/docker/* root@192.168.1.24:/usr/local/bin/ [root@master01 ~]# scp /usr/lib/systemd/system/docker.service root@192.168.1.24:/usr/lib/systemd/system/ 2.1 在master02上启动docker 2.1.1、从master01节点上发送docker相关文件 [root@master01 ~]# ssh root@192.168.1.24 mkdir /etc/docker [root@master01 ~]# scp /etc/docker/daemon.json root@192.168.1.24:/etc/docker/ 在master02节点上启动docker systemctl daemon-reload systemctl start docker && systemctl enable docker 3、部署Master2(192.168.1.24) Master2 与已部署的Master1所有操作一致。所以我们只需将Master1所有K8s文件拷贝过来,再修改下服务器IP和主机名启动即可。 3.1、在Master2创建etcd证书目录 [root@master02 ~]# mkdir -p /k8s/{etcd,k8s}/{bin,cfg,ssl,logs} 3.2、从master01上拷贝文件 [root@master01 ~]# scp -r /k8s/k8s/{bin,cfg,ssl} root@192.168.1.24:/k8s/k8s [root@master01 ~]# scp -r /k8s/etcd/ssl root@192.168.1.24:/k8s/etcd/ [root@master01 ~]# scp -r /opt/cni/ root@192.168.1.24:/opt [root@master01 ~]# scp /usr/lib/systemd/system/kube* root@192.168.1.24:/usr/lib/systemd/system [root@master01 ~]# scp /usr/local/bin/kubectl root@192.168.1.24:/usr/bin 3.3、在master02上删除证书文件 [root@master02 ~]# rm -rf /k8s/k8s/cfg/kubelet.kubeconfig [root@master02 ~]# rm -rf /k8s/k8s/ssl/kubelet* 3.4、在master上修改配置文件中的IP和主机名 [root@master02 ~]# vim /k8s/k8s/cfg/kube-apiserver.cfg --bind-address=192.168.1.24 \ --advertise-address=192.168.1.24 \ [root@master02 ~]# vim /k8s/k8s/cfg/kubelet.cfg --hostname-override=master02 \ [root@master02 ~]# vim /k8s/k8s/cfg/kube-proxy-config.yml hostnameOverride: master02 3.5、在master上启动所有组件设置开机启动 systemctl daemon-reload systemctl enable kube-apiserver kube-controller-manager kube-scheduler kubelet kube-proxy systemctl start kube-apiserver kube-controller-manager kube-scheduler kubelet kube-proxy systemctl status kube-apiserver kube-controller-manager kube-scheduler kubelet kube-proxy 3.6、在master上查看集群状态 [root@master02 ~]# kubectl get cs NAME STATUS MESSAGE ERROR scheduler Healthy ok controller-manager Healthy ok etcd-1 Healthy {"health":"true"} etcd-2 Healthy {"health":"true"} etcd-0 Healthy {"health":"true"} 3.7、在master上批准kubelet证书申请 [root@master02 ~]# kubectl get csr NAME AGE SIGNERNAME REQUESTOR CONDITION node-csr-mviArpM4DRc1WC3MQZZX9KQF1G 72s kubernetes.io/kube-apiserver-client-kubelet kubelet-bootstrap Pending 注:因排版问题,上一行被裁剪了部分,全称为node-csr-mviArpM4DRc1WC3MQZZX9KQF1G7AKp156Th7GFDAcvU 批准 [root@master02 ~]# kubectl certificate approve node-csr-mviArpM4DRc1WC3MQZZX9KQF1G7AKp156Th7GFDAcvU certificatesigningrequest.certificates.k8s.io/node-csr-mviArpM4DRc1WC3MQZZX9KQF1G7AKp156Th7GFDAcvU approved [root@master02 ~]# kubectl get csr NAME AGE SIGNERNAME REQUESTOR CONDITION node-csr-mviArpM4DRc1WC3MQZZX9K 2m40s kubernetes.io/kube-apiserver-client-kubelet kubelet-bootstrap Approved,Issued master01或master02节点上查看node [root@master02 ~]# kubectl get nodes NAME STATUS ROLES AGE VERSION master01 Ready <none> 5h39m v1.18.19 master02 NotReady <none> 10s v1.18.19 node01 Ready <none> 4h9m v1.18.19 node02 Ready <none> 4h9m v1.18.19 5分钟后.... [root@master02 ~]# kubectl get nodes NAME STATUS ROLES AGE VERSION master01 Ready <none> 5h47m v1.18.19 master02 Ready <none> 8m22s v1.18.19 node01 Ready <none> 4h17m v1.18.19 node02 Ready <none> 4h17m v1.18.19
部署nginx及nginx高可用
Nginx是一个主流Web服务和反向代理服务器,这里用四层实现对apiserver实现负载均衡。
Keepalived是一个主流高可用软件,基于VIP绑定实现服务器双机热备,在上述拓扑中,Keepalived主要根据Nginx运行状态判断是否需要故障转移(偏移VIP),例如当Nginx主节点挂掉,VIP会自动绑定在Nginx备节点,从而保证VIP一直可用,实现Nginx高可用。
1、nginx01和nginx02节点上安装软件包(以nginx01为例) [root@nginx01 ~]# yum -y install epel-release [root@nginx01 ~]# yum -y install nginx keepalived 2、nginx01和nginx02节点上配置nginx(nginx主备一样) [root@nginx01 ~]# mv /etc/nginx/nginx.conf{,.bak} [root@nginx01 ~]# vim /etc/nginx/nginx.conf user nginx; worker_processes auto; error_log /var/log/nginx/error.log; pid /run/nginx.pid; include /usr/share/nginx/modules/*.conf; events { worker_connections 1024; } # 四层负载均衡,为两台Master apiserver组件提供负载均衡 # stream_mudule: http://nginx.org/en/docs/stream/ngx_stream_core_module.html stream { log_format main '$remote_addr $upstream_addr - [$time_local] $status $upstream_bytes_sent'; access_log /var/log/nginx/k8s-access.log main; upstream k8s-apiserver { server 192.168.1.21:6443; # Master1 APISERVER IP:PORT server 192.168.1.24:6443; # Master2 APISERVER IP:PORT } server { listen 6443; proxy_pass k8s-apiserver; } } http { log_format main '$remote_addr - $remote_user [$time_local] "$request" ' '$status $body_bytes_sent "$http_referer" ' '"$http_user_agent" "$http_x_forwarded_for"'; access_log /var/log/nginx/access.log main; sendfile on; tcp_nopush on; tcp_nodelay on; keepalive_timeout 65; types_hash_max_size 2048; include /etc/nginx/mime.types; default_type application/octet-stream; server { listen 80 default_server; server_name _; location / { } } } 3、nginx01节点上配置keepalived [root@nginx01 ~]# mv /etc/keepalived/keepalived.conf{,.bak} [root@nginx01 ~]# vim /etc/keepalived/keepalived.conf global_defs { notification_email { acassen@firewall.loc failover@firewall.loc sysadmin@firewall.loc } notification_email_from Alexandre.Cassen@firewall.loc smtp_server 127.0.0.1 smtp_connect_timeout 30 router_id NGINX_MASTER } vrrp_script check_nginx { script "/etc/keepalived/check_nginx.sh" } vrrp_instance VI_1 { state MASTER interface ens33 virtual_router_id 51 # VRRP 路由 ID实例,每个实例是唯一的 priority 100 # 优先级,备服务器设置 90 advert_int 1 # 指定VRRP 心跳包通告间隔时间,默认1秒 authentication { auth_type PASS auth_pass 1111 } # 虚拟IP virtual_ipaddress { 192.168.1.27/24 } track_script { check_nginx } } 释义: vrrp_script:指定检查nginx工作状态脚本(根据nginx状态判断是否故障转移) virtual_ipaddress:虚拟IP(VIP) 检查nginx状态脚本: [root@nginx01 ~]# cat > /etc/keepalived/check_nginx.sh << EOF #!/bin/bash count=\$(ps -ef | grep nginx | egrep -cv "grep | \$\$") if [ "\$count" -eq 0 ];then exit 1 else exit 0 fi EOF [root@nginx01 ~]# chmod +x /etc/keepalived/check_nginx.sh nginx01节点启动nginx和keepalived并设置开机启动 systemctl daemon-reload systemctl enable nginx systemctl enable keepalived systemctl start nginx systemctl start keepalived 注:如启动时nginx报stream的错,则需看 https://www.cnblogs.com/smlile-you-me/p/14986179.html [root@nginx01 ~]# systemctl status nginx keepalived ● nginx.service - The nginx HTTP and reverse proxy server Loaded: loaded (/usr/lib/systemd/system/nginx.service; enabled; vendor preset: disabled) Active: active (running) since 四 2021-07-08 21:37:15 CST; 28min ago Process: 24693 ExecStart=/usr/sbin/nginx (code=exited, status=0/SUCCESS) Process: 24690 ExecStartPre=/usr/sbin/nginx -t (code=exited, status=0/SUCCESS) Process: 24689 ExecStartPre=/usr/bin/rm -f /run/nginx.pid (code=exited, status=0/SUCCESS) Main PID: 24695 (nginx) CGroup: /system.slice/nginx.service ├─24695 nginx: master process /usr/sbin/nginx └─24696 nginx: worker process 7月 08 21:37:15 nginx01 systemd[1]: Starting The nginx HTTP and reverse proxy server... 7月 08 21:37:15 nginx01 nginx[24690]: nginx: the configuration file /etc/nginx/nginx.conf syntax is ok 7月 08 21:37:15 nginx01 nginx[24690]: nginx: configuration file /etc/nginx/nginx.conf test is successful 7月 08 21:37:15 nginx01 systemd[1]: Failed to parse PID from file /run/nginx.pid: Invalid argument 7月 08 21:37:15 nginx01 systemd[1]: Started The nginx HTTP and reverse proxy server. ● keepalived.service - LVS and VRRP High Availability Monitor Loaded: loaded (/usr/lib/systemd/system/keepalived.service; enabled; vendor preset: disabled) Active: active (running) since 四 2021-07-08 22:05:48 CST; 15s ago Process: 26111 ExecStart=/usr/sbin/keepalived $KEEPALIVED_OPTIONS (code=exited, status=0/SUCCESS) Main PID: 26112 (keepalived) CGroup: /system.slice/keepalived.service ├─26112 /usr/sbin/keepalived -D ├─26113 /usr/sbin/keepalived -D └─26114 /usr/sbin/keepalived -D 7月 08 22:05:55 nginx01 Keepalived_vrrp[26114]: Sending gratuitous ARP on ens33 for 192.168.1.27 7月 08 22:05:55 nginx01 Keepalived_vrrp[26114]: Sending gratuitous ARP on ens33 for 192.168.1.27 7月 08 22:05:55 nginx01 Keepalived_vrrp[26114]: Sending gratuitous ARP on ens33 for 192.168.1.27 7月 08 22:05:55 nginx01 Keepalived_vrrp[26114]: Sending gratuitous ARP on ens33 for 192.168.1.27 7月 08 22:06:00 nginx01 Keepalived_vrrp[26114]: Sending gratuitous ARP on ens33 for 192.168.1.27 7月 08 22:06:00 nginx01 Keepalived_vrrp[26114]: VRRP_Instance(VI_1) Sending/queueing gratuitous ARPs on ens33 for 192.168.1.27 7月 08 22:06:00 nginx01 Keepalived_vrrp[26114]: Sending gratuitous ARP on ens33 for 192.168.1.27 7月 08 22:06:00 nginx01 Keepalived_vrrp[26114]: Sending gratuitous ARP on ens33 for 192.168.1.27 7月 08 22:06:00 nginx01 Keepalived_vrrp[26114]: Sending gratuitous ARP on ens33 for 192.168.1.27 7月 08 22:06:00 nginx01 Keepalived_vrrp[26114]: Sending gratuitous ARP on ens33 for 192.168.1.27 [root@nginx01 ~]# ip a show ens33 2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000 link/ether 00:0c:29:89:e3:dd brd ff:ff:ff:ff:ff:ff inet 192.168.1.25/24 brd 192.168.1.255 scope global noprefixroute ens33 valid_lft forever preferred_lft forever inet 192.168.1.27/24 scope global secondary ens33 valid_lft forever preferred_lft forever inet6 fe80::b77e:df59:787b:674b/64 scope link noprefixroute valid_lft forever preferred_lft forever 4、nginx02节点上配置keepalived [root@nginx02 ~]# mv /etc/keepalived/keepalived.conf{,.bak} [root@nginx02 ~]# vim /etc/keepalived/keepalived.conf global_defs { notification_email { acassen@firewall.loc failover@firewall.loc sysadmin@firewall.loc } notification_email_from Alexandre.Cassen@firewall.loc smtp_server 127.0.0.1 smtp_connect_timeout 30 router_id NGINX_BACKUP } vrrp_script check_nginx { script "/etc/keepalived/check_nginx.sh" } vrrp_instance VI_1 { state BACKUP interface ens33 virtual_router_id 51 # VRRP 路由 ID实例,每个实例是唯一的 priority 90 advert_int 1 authentication { auth_type PASS auth_pass 1111 } virtual_ipaddress { 192.168.1.27/24 } track_script { check_nginx } } 检查nginx状态脚本: [root@nginx02 ~]# cat > /etc/keepalived/check_nginx.sh << EOF #!/bin/bash count=\$(ps -ef | grep nginx | egrep -cv "grep | \$\$") if [ "\$count" -eq 0 ];then exit 1 else exit 0 fi EOF [root@nginx02 ~]# chmod +x /etc/keepalived/check_nginx.sh 注:keepalived根据脚本返回状态码(0为工作正常,非0不正常)判断是否故障转移。 nginx0节点启动nginx和keepalived并设置开机启动 systemctl daemon-reload systemctl enable nginx systemctl enable keepalived systemctl start nginx systemctl start keepalived 注:如启动时nginx报stream的错,则需看 https://www.cnblogs.com/smlile-you-me/p/14986179.html [root@nginx02 ~]# systemctl status nginx keepalived ● nginx.service - The nginx HTTP and reverse proxy server Loaded: loaded (/usr/lib/systemd/system/nginx.service; enabled; vendor preset: disabled) Active: active (running) since 四 2021-07-08 22:21:21 CST; 12s ago Process: 15716 ExecStart=/usr/sbin/nginx (code=exited, status=0/SUCCESS) Process: 15713 ExecStartPre=/usr/sbin/nginx -t (code=exited, status=0/SUCCESS) Process: 15711 ExecStartPre=/usr/bin/rm -f /run/nginx.pid (code=exited, status=0/SUCCESS) Main PID: 15718 (nginx) Tasks: 2 Memory: 1.5M CGroup: /system.slice/nginx.service ├─15718 nginx: master process /usr/sbin/nginx └─15719 nginx: worker process 7月 08 22:21:21 nginx02 systemd[1]: Starting The nginx HTTP and reverse proxy server... 7月 08 22:21:21 nginx02 nginx[15713]: nginx: the configuration file /etc/nginx/nginx.conf syntax is ok 7月 08 22:21:21 nginx02 nginx[15713]: nginx: configuration file /etc/nginx/nginx.conf test is successful 7月 08 22:21:21 nginx02 systemd[1]: Failed to parse PID from file /run/nginx.pid: Invalid argument 7月 08 22:21:21 nginx02 systemd[1]: Started The nginx HTTP and reverse proxy server. ● keepalived.service - LVS and VRRP High Availability Monitor Loaded: loaded (/usr/lib/systemd/system/keepalived.service; enabled; vendor preset: disabled) Active: active (running) since 四 2021-07-08 22:21:22 CST; 12s ago Process: 15726 ExecStart=/usr/sbin/keepalived $KEEPALIVED_OPTIONS (code=exited, status=0/SUCCESS) Main PID: 15727 (keepalived) Tasks: 3 Memory: 5.5M CGroup: /system.slice/keepalived.service ├─15727 /usr/sbin/keepalived -D ├─15728 /usr/sbin/keepalived -D └─15729 /usr/sbin/keepalived -D 7月 08 22:21:22 nginx02 Keepalived_vrrp[15729]: Registering gratuitous ARP shared channel 7月 08 22:21:22 nginx02 Keepalived_vrrp[15729]: Opening file '/etc/keepalived/keepalived.conf'. 7月 08 22:21:22 nginx02 Keepalived_vrrp[15729]: WARNING - default user 'keepalived_script' for script execution...eate. 7月 08 22:21:22 nginx02 Keepalived_vrrp[15729]: SECURITY VIOLATION - scripts are being executed but script_secu...bled. 7月 08 22:21:22 nginx02 Keepalived_vrrp[15729]: VRRP_Instance(VI_1) removing protocol VIPs. 7月 08 22:21:22 nginx02 Keepalived_vrrp[15729]: Using LinkWatch kernel netlink reflector... 7月 08 22:21:22 nginx02 Keepalived_vrrp[15729]: VRRP_Instance(VI_1) Entering BACKUP STATE 7月 08 22:21:22 nginx02 Keepalived_vrrp[15729]: VRRP sockpool: [ifindex(2), proto(112), unicast(0), fd(10,11)] 7月 08 22:21:22 nginx02 Keepalived_vrrp[15729]: VRRP_Script(check_nginx) succeeded 7月 08 22:21:22 nginx02 Keepalived_healthcheckers[15728]: Opening file '/etc/keepalived/keepalived.conf'. Hint: Some lines were ellipsized, use -l to show in full. [root@nginx02 ~]# ip a show ens33 2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000 link/ether 00:0c:29:b4:34:4f brd ff:ff:ff:ff:ff:ff inet 192.168.1.26/24 brd 192.168.1.255 scope global noprefixroute ens33 valid_lft forever preferred_lft forever inet6 fe80::d588:e427:12e7:ce21/64 scope link noprefixroute valid_lft forever preferred_lft forever ## Nginx+Keepalived高可用测试 关闭主节点Nginx,测试VIP是否漂移到备节点服务器。 在Nginx Master执行 pkill nginx 在Nginx Backup,ip addr命令查看已成功绑定VIP。 [root@nginx01 ~]# ip a show ens33 2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000 link/ether 00:0c:29:89:e3:dd brd ff:ff:ff:ff:ff:ff inet 192.168.1.25/24 brd 192.168.1.255 scope global noprefixroute ens33 valid_lft forever preferred_lft forever inet 192.168.1.27/24 scope global secondary ens33 valid_lft forever preferred_lft forever inet6 fe80::b77e:df59:787b:674b/64 scope link noprefixroute valid_lft forever preferred_lft forever [root@nginx01 ~]# pkill nginx [root@nginx01 ~]# ip a show ens33 2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000 link/ether 00:0c:29:89:e3:dd brd ff:ff:ff:ff:ff:ff inet 192.168.1.25/24 brd 192.168.1.255 scope global noprefixroute ens33 valid_lft forever preferred_lft forever inet6 fe80::b77e:df59:787b:674b/64 scope link noprefixroute valid_lft forever preferred_lft forever [root@nginx02 ~]# ip a show ens33 2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000 link/ether 00:0c:29:b4:34:4f brd ff:ff:ff:ff:ff:ff inet 192.168.1.26/24 brd 192.168.1.255 scope global noprefixroute ens33 valid_lft forever preferred_lft forever inet 192.168.1.27/24 scope global secondary ens33 valid_lft forever preferred_lft forever inet6 fe80::d588:e427:12e7:ce21/64 scope link noprefixroute valid_lft forever preferred_lft forever 访问负载均衡器测试 找K8s集群中任意一个节点,使用curl查看K8s版本测试,使用VIP访问: [root@nginx02 ~]# curl -k https://192.168.1.27:6443/version { "major": "1", "minor": "18", "gitVersion": "v1.18.19", "gitCommit": "ac0cc736d0018d817c763083945e4db863168d12", "gitTreeState": "clean", "buildDate": "2021-05-12T11:21:54Z", "goVersion": "go1.13.15", "compiler": "gc", "platform": "linux/amd64" 可以正确获取到K8s版本信息,说明负载均衡器搭建正常。 该请求数据流程:curl -> vip(nginx) -> apiserver
修改所有Worker Node(非2个master节点)连接LB VIP
虽然增加了Master2和负载均衡器,但我们是从单Master架构扩容的,也就是说目前所有的Node组件连接都还是Master1,如果不改为连接VIP走负载均衡器,那么Master还是单节点集群。
因此接下来就是要改所有Node组件配置文件,由原来192.168.1.21修改为192.168.1.27(VIP):
| 角色 | IP |
|---|---|
| master01 | 192.168.1.21 |
| master02 | 192.168.1.24 |
| node01 | 192.168.1.22 |
| node02 | 192.168.1.23 |
| 也就是通过kubectl get node命令查看到的节点。 |
在上述所有Worker Node执行:
在node01节点上
sed -i 's/192.168.1.22:6443/192.168.1.27:6443/' /k8s/k8s/cfg/*
systemctl restart kubelet
systemctl restart kube-proxy
在node02节点上
sed -i 's/192.168.1.23:6443/192.168.1.27:6443/' /k8s/k8s/cfg/*
systemctl restart kubelet
systemctl restart kube-proxy
检查节点状态
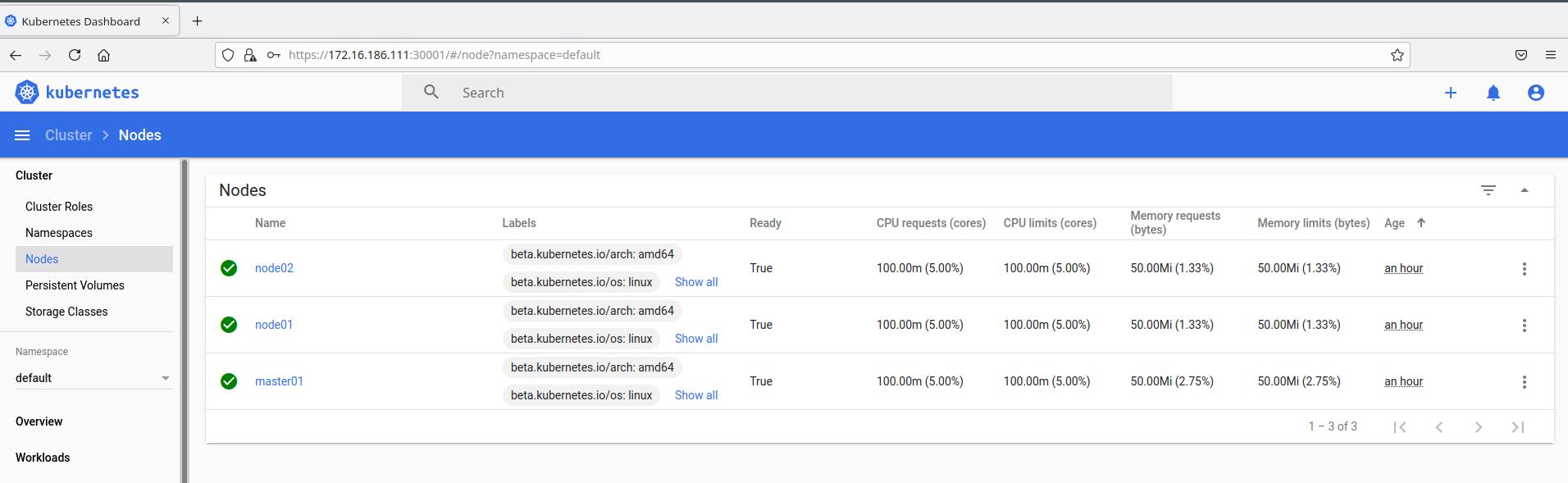
[root@master01 ~]# kubectl get node
NAME STATUS ROLES AGE VERSION
master01 Ready
master02 Ready
node01 Ready
node02 Ready
至此,一套完整的 Kubernetes 高可用集群就部署完成了!
PS:如果你是在公有云上,一般都不支持keepalived,那么你可以直接用它们的负载均衡器产品(内网就行,还免费~),架构与上面一样,直接负载均衡多台Master kube-apiserver即可!
.
.
.
.
游走在各发行版间老司机QQ群:905201396
不要嫌啰嗦的新手QQ群:756805267
Debian适应QQ群:912567610


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· winform 绘制太阳,地球,月球 运作规律
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 上周热点回顾(3.3-3.9)
· AI 智能体引爆开源社区「GitHub 热点速览」