Ceph与Gluster之开源存储的对比
一、Ceph与Gluster的原理对比
Ceph和Gluster是Red Hat旗下的成熟的开源存储产品,Ceph与Gluster在原理上有着本质上的不同。
1、Ceph
Ceph基于一个名为RADOS的对象存储系统,使用一系列API将数据以块(block)、文件(file)和对象(object)的形式展现。Ceph存储系统的拓扑结构围绕着副本与信息分布,这使得该系统能够有效保障数据的完整性。
2、Gluster
Gluster描述为Scale-out NAS和对象存储系统。它使用一个Hash算法来计算数据在存储池中的存放位置,这点跟Ceph很类似。在Gluster中,所有的存储服务器使用Hash算法完成对特定数据实体的定位。于是数据可以很容易的复制,并且没有中心元数据分布式存储无单点故障且不易造成访问瓶颈,这种单点在早期Hadoop上出现,对性能和可靠性造成较大影响。
二、Ceph文件系统架构
RADOS(Reliable, Autonomic、Distributed Object Store)是Ceph系统的基础,这一层本身就是一个完整的对象存储系统,包括Cehp的基础服务(MDS,OSD,Monitor),所有存储在Ceph系统中的用户数据事实上最终都是由这一层来存储的。而Ceph的高可靠、高可扩展、高性能、高自动化等等特性本质上也是由这一层所提供的。
RADOS在物理形态上由大量的存储设备节点组成,每个节点拥有自己的硬件资源(CPU、内存、硬盘、网络),并运行着操作系统和文件系统。基础库librados是对RADOS进行抽象和封装,并向上层提供不同API,以便直接基于RADOS进行原生对象或上层对象、块和文件应用开发。特别要注意的是,RADOS是一个对象存储系统,因此,基于librados实现的API也只是针对对象存储功能的。
RADOS所提供的原生librados API包括C和C++两种。Librados在部署上和基于其上开发的应用位于同一台机器。应用调用本机上的librados API,再由后者通过Socket与RADOS集群中的节点通信并完成各种操作。
这一层包括了RADOS GW(RADOS Gateway)、 RBD(Reliable Block Device)和Ceph FS(Ceph File System)三个高层存储应用接口,其作用是在librados库的基础上提供抽象层次更高、更便于应用或客户端使用的上层接口。
RADOS GW是一个提供与Amazon S3和Swift兼容的RESTful API的Gateway,以供相应的对象存储应用开发使用。RADOS GW提供的API抽象层次更高,但功能则不如librados强大。因此,开发者应针对自己的需求选择使用。
RBD则提供了一个标准的块设备接口,常用于在虚拟化的场景下为虚拟机创建Volume。如前所述,Red Hat已经将RBD驱动集成在KVM/QEMU中,以提高虚拟机访问性能。
CephFS是一个POSIX兼容的分布式文件系统。目前还处在开发状态,因而Ceph官网并不推荐将其用于生产环境中。
Ceph Client是基于Fuse层(User SpacE)和VFS文件系统开发,兼容Posix接口标准。在Ceph存储系统中,Ceph Metadata Daemon 提供了元数据服务器,而Ceph Object Storage Daemon 提供了数据和元数据的实际存储。
Ceph对DFS、Block和Object数据写入和读取,都需Client利用Crush算法(负责集群中的数据放置和检索的算法)完成存储位置计算和数据组装。Ceph架构详细介绍请参考“Ceph存储架构深度分析”文章。
三、Gluster FS系统架构
Gluster FS由Brick Server、Client和NAS网关组成(用来访问存储服务,但是Client只支持Linux,其他系统需要NAS网关提供存储服务),三者可以部署到同一个物理服务器上。NAS网关通过启动GLFS Client提供存储服务。
每个文件通过一定策略分不到不同的Brick Server上,每个Brick Server通过运行不同进程处理数据请求,文件以原始格式以EXT、XFS和ZFS文件系统的保存在本地。
卷(Block)通过位于Client或NAS网关上的卷管理器来提供服务,由卷管理器管理集群中的多个Brick Server。存储节点(Brick Server)对外提供的服务目录称作Brick,一个Brick对应一个本地文件系统,Gluster FS以Brick为单位管理存储。
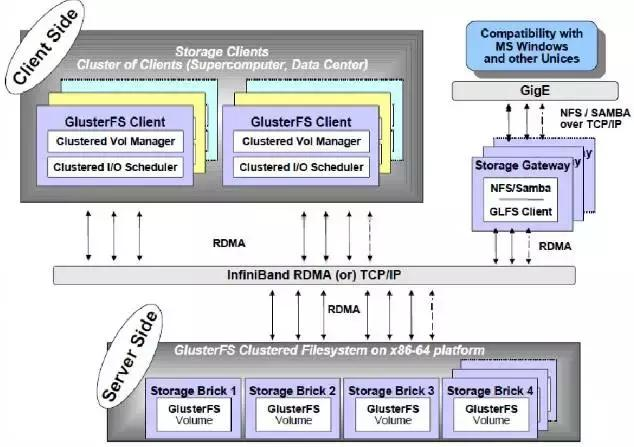
GlusterFS采用模块化、堆栈式的架构,可通过灵活的配置支持高度定制化的应用环境,比如大文件存储、海量小文件存储、云存储、多传输协议应用等。每个功能以模块形式实现,然后以积木方式进行简单的组合,即可实现复杂的功能。比如,Replicate模块可实现RAID1,Stripe模块可实现RAID0,通过两者的组合可实现RAID10和RAID01,同时获得高性能和高可靠性。
各个功能模块就是一个Xlator(translator),不同的xlator在初始化后形成树,每个xlator为这棵树中的节点动态加载,同一个xlaror可以同时在Client/Brick Server上加载。GlusterFS系统详细架构请参看“Gluster FS分布式文件系统”文章。
四、GlusterFS和Ceph对比
1、GlusterFS和Ceph的简单对比
GlusterFS和Ceph是两个灵活的存储系统,有着相似的数据分布能力,在云环境中表现非常出色。在尝试了解GlusterFS与Ceph架构之后,我们来看看两者之间的简单对比。

2、GlusterFS和Ceph的共同点
纵向扩展和横向扩展:在云环境中,必须可以很容易地向服务器添加更多存储空间以及扩展可用存储池。Ceph和GlusterFS都可以通过将新存储设备集成到现有存储产品中,满足扩充性能和容量的要求。
高可用性:GlusterFS和Ceph的复制是同时将数据写入不同的存储节点。这样做的结果是,访问时间增加,数据可用性也提高。在Ceph中,默认情况下将数据复制到三个不同的节点,以此确保备份始终可用性。
商品化硬件:GlusterFS和Ceph是在Linux操作系统之上开发的。因此,对硬件唯一的要求是这些产品具有能够运行Linux的硬件。任何商品化硬件都可以运行Linux操作系统,结果是使用这些技术的公司可以大大减少在硬件上的投资——如果他们这样做的话。然而,实际上,许多公司正在投资专门用于运行GlusterFS或Ceph的硬件,因为更快的硬件可以更快地访问存储。
去中心化:在云环境中,永远不应该有中心点故障。对于存储,这意味着不应该用一个中央位置存储元数据。GlusterFS和Ceph实现了元数据访问去中心化的解决方案,从而降低了存储访问的可用性和冗余性。
3、GlusterFS与Ceph的差异
GlusterFS是来自Linux世界的文件系统,并且遵守所有Portable Operating System Interface标准。尽管你可以将GlusterFS轻松集成到面向Linux的环境中,但在Windows环境中集成GlusterFS很难。
Ceph是一种全新的存储方法,对应于Swift对象存储。在对象存储中,应用程序不会写入文件系统,而是使用存储中的直接API访问写入存储。因此,应用程序能够绕过操作系统的功能和限制。如果已经开发了一个应用程序来写入Ceph存储,那么使用哪个操作系统无关紧要。结果表明Ceph存储在Windows环境中像在Linux环境中一样容易集成。
基于API的存储访问并不是应用程序可以访问Ceph的唯一方式。为了最佳的集成,还有一个Ceph块设备,它可以在Linux环境中用作常规块设备,使你可以像访问常规Linux硬盘一样来使用Ceph。Ceph还有CephFS,它是针对Linux环境编写的Ceph文件系统。
4、GlusterFS与Ceph的速度对比
GlusterFS存储算法更快,并且由于GlusterFS以砖组织存储的方式实现了更多的分层,这在某些场景下(尤其是使用非优化Ceph)可能导致更快的速度。另一方面,Ceph提供了足够的定制功能来使其与GlusterFS一样快。
5、GlusterFS与Ceph的应用
Ceph访问存储的不同方法使其成为更流行的技术。更多的公司正在考虑Ceph技术而不是GlusterFS,而且GlusterFS仍然与Red Hat密切相关。例如,SUSE还没有GlusterFS的商业实施,而Ceph已经被开源社区广泛采用,市场上有各种不同的产品。在某种意义上来说,Ceph确实已经胜过GlusterFS。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号