
(本文仅作为学习记录使用) 感谢太白老师和王sir的谆谆教导.
01 昨日内容回顾
昨日主要讲解的是字典。
字典考察字典的增删改查和其他操作。
字典的增加(2种)
1.直接改,按照key改. dic['key'] = 'value'. 有则修改,无则增加.
2.setdefault. dic.setdefault['key','value'] 有则不改,无则添加.
注意,key是唯一的,value是任意的. key必须有,value可以没. value没的话就是none,可以视为set. set是特殊的字典.
字典的删除(4种)
1.pop. 按key删除. dic.pop('key')
2.clear . 清空字典. dic.clear()
3.popitem . 删除最后一个.(Python 3.6以后) dic.popitem()
4.del. 可以按键删除. 也可以删除dic. del dic , del dic['key']
字典的改(2种)
1.直接改.dic['key'] = 'value'. 有则修改,无则增加.
2.update. dic.update('key'='value) dic.update(dic2)
注意,update既可直接修改(用等号,key不用引号),也可直接把一个字典改进去. 而dic.setdefault后面的是逗号.
字典的查(2种)
1.直接查 . 找到dic的key . print(dic['key']) . 如此.
2.用get. dic.get['key'] 获取key对应的value.
其他操作:
1.对key操作的手段很少,只有2种.
1.通过for循环遍历.
demo1:
d = {'k1':'v1','k2':'v2','k3':'v3'}
for i in d :
print(i)
结果:输出key.这个是单个单个的字符串输出.
2.通过list.
demo2:
d = {'k1':'v1','k2':'v2','k3':'v3'}
l = list(d)
print(l)
结果:输出key.这个是输出的列表.
其他,dic.keys() 输出所有key(列表中的元素是字符串)
dic.values() 输出所有value(列表中的元素是字符串)
dic.items() 输出所有key和value(列表中的元素是元组)
链接:https://www.cnblogs.com/smithpath/articles/10486405.html
02 作业讲解
# 1.有如下变量(tu是个元祖),请实现要求的功能 # tu = ("alex", [11, 22, {"k1": 'v1', "k2": ["age", "name"], "k3": (11, 22, 33)}, 44]) # a.讲述元祖的特性 # 元组通常上来说不可变,格式是(,)等(可以隔许多个),是存储大量容器型数据的数据。 # 其他语言中没有元组的概念,只有Python有。 # 元组中的数据不能修改,只能查询。虽然元组不能修改,但是里面的字典、列表等元素可被修改。 # 元组中存储的一般是非常重要的数据,如个人信息等。一般来说元组很少用。 # b.请问tu变量中的第一个元素"alex"是否可被修改? # 不可以.因为是元组. # 尝试: # tu[0] = '1' # print(tu)#tuple是只可读,而不支持写的,所以,在这就出现了关于tuple的问题,就会出现问题。 # c.请问tu变量中的"k2"对应的值是什么类型?是否可以被修改?如果可以,请在其中添加一个元素"Seven" # 对应的是list列表. 可以被修改. # print(tu[1][2]['k2'],type(tu[1][2]['k2'])) #如果不知道dict中是否有key的值 # tu[1][2]['k2'].append('seven') # dict.get(key) # print(tu[1][2]['k2']) #如果用 dict[key] 读取会报KeyError异常 # d.请问tu变量中的"k3"对应的值是什么类型?是否可以被修改?如果可以,请在其中添加一个元素"Seven" # 是元组. 不可以被修改. # print(tu[-1][-2]['k3'],type(tu[-1][-2]['k3'])) # 2.字典dic, dic = {'k1': "v1", "k2": "v2", "k3": [11, 22, 33]} # dic = {'k1': "v1", "k2": "v2", "k3": [11, 22, 33]} # a.请循环输出所有的key # for key in dic : # print(key) # b.请循环输出所有的value # for key in dic : # print(dic[key]) # c.请循环输出所有的key和value # 不美观: # for key in dic : # print(key,dic[key]) # 较美观: # for key in dic: # print('dic[%s]=' % key,dic[key] ) # d.请在字典中添加一个键值对,"k4": "v4",输出添加后的字典 # 法一: # dic['k4'] = 'v4' # print(dic) # 法二: # dic.setdefault('k4','v4') # print(dic) # dic = {'k1': "v1", "k2": "v2", "k3": [11, 22, 33]} # e.请在修改字典中"k1"对应的值为"alex",输出修改后的字典 # 法一: # dic['k1'] = 'alex' # print(dic) # 法二: # dic.update(k1='alex') # print(dic) # f.请在k3对应的值中追加一个元素44,输出修改后的字典 # dic['k3'].append(44) # print(dic) # g.请在k3对应的值的第1个位置插入个元素18,输出修改后的字典 # dic['k3'].insert(0,18) # print(dic) # 3. # av_catalog = { # "欧美": # { # "www.太白.com": ["很多免费的,世界最大的", "质量⼀般"], # "www.alex.com": ["很多免费的,也很大", "质量比yourporn比高点"], # "oldboy.com": ["多是自拍,比高质量图片很多", "资源不多,更新慢"], # "hao222.com": ["质量很高,真的很高", "全部收费,屌丝请绕过"] # }, # "日韩": # { # "tokyo-hot": ["质量怎样不清楚,个人已经不喜欢日韩范了", "verygood"] # }, # "大陆": # { # "1024": ["全部免费,真好,好人⼀生平安", "服务器在国外,慢"] # } # } # a, 给此["很多免费的,世界最大的", "质量⼀般"]列表第⼆个位置插入⼀个元素:'量很大'。 # av_catalog['欧美']['www.太白.com'].insert(1,'量很大') # print(av_catalog) # b, 将此["质量很比高,真的很比高", "全部收费,屌丝请绕过"]列表的"全部收费,屌丝请绕过"删除。 # 法一: # av_catalog['欧美']['hao222.com'].pop(1) # print(av_catalog) # 法二: # av_catalog['欧美']['hao222.com'].remove("全部收费,屌丝请绕过") # print(av_catalog) # 法三: # del av_catalog['欧美']['hao222.com'][1] # print(av_catalog) # c, 将此["质量怎样不清楚,个人已经不喜欢日韩范了", "verygood"]列表的"verygood"全部变成大写。 # av_catalog['日韩']['tokyo-hot'][1] = av_catalog['日韩']['tokyo-hot'][1].upper() # print(av_catalog) # d, 给'大陆'对应的字典添加⼀个键值对'1048': ['⼀天就封了'] # 法一: # av_catalog['大陆']['1048']=['⼀天就封了'] # print(av_catalog) # 法二: # av_catalog['大陆'].setdefault('1048', ['⼀天就封了']) # print(av_catalog) # e.删除该键值对. "oldboy.com": ["多是自拍,高质量图片很多", "资源不多,更新慢"] # del av_catalog['欧美']['oldboy.com'] # print(av_catalog) # f, 给此["全部免费,真好,好人⼀生平安", "服务器在国外,慢"]列表的第⼀个元素,加上⼀句话:'可以爬下来' # av_catalog['大陆']['1024'][0]+=',可以爬下来' # print(av_catalog) # 4.有字符串"k: 1|k1 :2|k2:3 |k3 :4"处理成字典{'k': 1, 'k1': 2....}(升级题) # 法一: # s1 = "k: 1|k1 :2|k2:3 |k3 :4" # l2 = [] # dic1={} # l1 = s1.split('|') # for i in l1: # l2 = i.split(':') # dic1['%s'%l2[0].strip()]= int(l2[1]) # print(dic1) # 法二: # strings = "k: 1|k1 :2|k2:3 |k3 :4" # li2 = [] # dic = {} # # li = strings.split("|") # # for lst in li: # lst = lst.split(":") # li2.append(lst) # # for x, y in li2: # x = x.strip() # y = int(y.strip()) # dic[x] = y # # print(dic) # 5.元素分类有如下值li = [11, 22, 33, 44, 55, 66, 77, 88, 99, 90],将所有大于66的值 # 保存至字典的第一个key中,将小于66的值保存至第二个key的值中。 # 即: {'k1': 大于66的所有值列表, 'k2': 小于66的所有值列表} # 法一: # li = [11, 22, 33, 44, 55, 66, 77, 88, 99, 90] # dic ={'k1':[],'k2':[]} # for i in li : # if int(i) < 66 : # dic['k1'].append(i) # elif int(i) > 66 : # dic['k2'].append(i) # print(dic) # 法二: # li = [11, 22, 33, 44, 55, 66, 77, 88, 99, 90] # d = {} # for e in li: # if e > 66: # # 若bigger键已经存在,就把已经存在的列表取出,然后再把当前元素追加到列表上. # value = d.get('bigger', []) # value.append(e) # d['bigger'] = value # elif e < 66: # # 若smaller键已经存在,就把已经存在的列表取出,然后再把当前元素追加到列表上. # value = d.get('smaller', []) # value.append(e) # d['smaller'] = value # print(d) # 6.输出商品列表,用户输入序号,显示用户选中的商品 # 商品列表: # goods = [{"name": "电脑", "price": 1999}, # {"name": "鼠标", "price": 10}, # {"name": "游艇", "price": 20}, # {"name": "美女", "price": 998}, ] # # 要求: # 1:⻚面显示 序号 + 商品名称 + 商品价格,如: # 1 电脑 1999 # 2 鼠标 10 # … # 2:用户输入选择的商品序号,然后打印商品名称及商品价格 # 3:如果用户输入的商品序号有误,则提示输入有误,并重新输入。 # 4:用户输入Q或者q,退出程序。 # 法一(写错了,题目理解错误): # while True: # num = input('请输入商品序号(1~4,按Q(不区分大小写)退出):').strip() # if num == 'Q' or num == 'q': # break # for i in range(1, len(goods)+1): # if num == str(i): # print( # ''' 序号 商品名称 商品价格 # %s %s %s # ''' % (num, goods[int(i)-1]['name'], goods[int(i)-1]['price'])) # break # else: # if i == len(goods): # print('输入有误,请重新输入') # 法二: # # 输出商品信息 # print("序号\t\t商品\t\t价格") # for i in range(len(goods)): # print(i+1, "\t\t", goods[i]["name"], "\t\t", goods[i]["price"], sep="") # # while True: # 用户选择商品并反馈信息 # buy = input("请输入: ").strip() # if buy.upper() == "Q": # break # # if buy.isdigit() and int(buy) <= len(goods): # # 由于buy是字符串类型, 负数在字符串中由于存在特殊字符"-", 因此不是纯数字组成, 如果用户输入负数, buy.isdigit()返回False # print("商品", "\t\t", "价格", sep="") # print(goods[int(buy) - 1]["name"], "\t\t", goods[int(buy) - 1]["price"], sep="") # else: # print("输入错误, 请重新输入") # 法一: # while 1: # for i in range(len(goods)): # print('序号\tname\tprice\n{}\t{}\t\t{}'.format(i + 1, goods[i]['name'], goods[i]['price'])) # msg = input('请输入序号(1~4),按Q可退出:') # if msg.upper() == 'Q' : # break # for i in range(len(goods)): # if 0< i+1 < len(goods) : # if msg == str(i+1) : # print('name\tprice\n{}\t\t{}'.format(goods[i]['name'], goods[i]['price'])) # break # else : # print('输入错误,请重新输入') # break#isdigit会过滤小数
03 小数据池(了解)
不多解释,只需要注意,同一代码块和不同代码块的缓存机制(驻留机制)不同.
同一代码块的id相同.
s = 'zhangwuji' print(id(s)) # 获取内存地址 # == 判断两个对象的值相同.
is 身份运算:判断的是两个对象的内存地址是否相同.
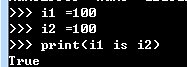
demo3: i1 =1000 i2 = 1000 print(i1 is i2) 输出结果为True.
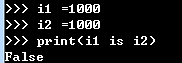
不同代码块参考小数据池(缓存范围是-5~256)即数字在这区间是正确的.
超过该区间则错误.
# 一个文件是一个代码块.(函数,类都是一个代码块.)
# 交互命令中一行就是一个代码块.
# 同一个代码块驻留机制的目的:
'''
1,节省内存空间.
2,提升性能.
'''
# 驻留机制针对的对象: int bool str ()空元组.
# int: 范围 任意数字
# i1 = 1212312312312312312312312
# i2 = 1212312312312312312312312
# print(i1 is i2)
# bool True Fasle
# str:几乎所有的字符串都会符合缓存机制,
# 通过相乘的形式构建的字符串长度不能超过20满足同一代码块的驻留机制.
# 不同的代码块之间: 小数据池.
# 小数据池是针对 不同代码块 之间的缓存机制!!!
# 小数据池的目的:
'''
1,节省内存空间.
2,提升性能.
# 小数据池针对的对象: int bool str ()空元组.
# int: -5 ~256
# str: 一定规则的字符串
# 总结
'''
如果在同一代码块下,则采用同一代码块下的换缓存机制。
如果是不同代码块,则采用小数据池的驻留机制。
04 数据类型的补充
# 数据类型之间的转换
# int bool str list tuple dict set
'''int bool str 三者转化是可以的.'''
# bool 可以与所有的数据类型进行转换.
# 所有为空的数据类型转化成bool都为Fasle.
# 0 '' [] () {} None ----> Fasle
# list ---> str join # list里面的元素全部都是str类型
注意,dic = dict.fromkeys()
坑: 如果你的值是一个可变的数据类型, 他在内存中是一个.id相同.
tuple: 如果元组中只有单个元素并且没有 , 则类型是元素本身的类型.
join的用法. ''.join(list)
l1 = [11, 22, 33, 44, 55]
# 将此列表索引为奇数位对应的元素全部删除.
# 方法一:
# del l1[1::2]
# print(l1)
# 方法二:错误示例:
# 循环一个列表时,不要改变列表的大小.这样会影响你最后的结果.
# for index in range(len(l1)):
# if index % 2 == 1:
# # index 奇数
# l1.pop(index)
# print(l1)
# 方法三
# new_l = []
# for index in range(len(l1)):
# if index % 2 == 0:
# new_l.append(l1[index])
# # print(new_l)
# l1 = new_l
# print(l1)
# 方法三:
# for index in range(len(l1)-1,-1,-1):
# if index % 2 == 1:
# l1.pop(index)
# print(l1)
# 循环一个列表时,最好不要对原列表有改变大小的操作,这样会影响你的最终结果.
#
dic = {'k1': 'v1', 'k2': 'v2', 'k3': 'v3', 'name': 'alex'}
# 将字典中的key中含有k元素的所有键值对删除.
# dictionary changed size during iteration
# for key in dic:
# if 'k' in key:
# dic.pop(key)
# print(dic)
# l1 = []
# for key in dic:
# if 'k' in key:
# l1.append(key)
# # print(l1)
# for key in l1:
# dic.pop(key)
# print(dic)
# 循环一个字典时,不能改变字典的大小,这样会报错.
05 集合(了解即可)
回顾:字典特点:
1.key是唯一的.
2.key必须是可以哈希的(不可变数据类型:字符串,元组,数值)
3.key是无序的.
3.6中dict的元素有序是解释器的特点,不是python源码的特点.
xxx.py
Cpython -> 有序
Jpython -> 无序
集合:set
实际上就是一种特殊的字典.
所有value都是None的字典,就是集合.
对比字典和集合的特点:
|
字典 |
集合 |
|
Key唯一 |
元素唯一 |
|
Key可以哈希 |
元素可以哈希 |
|
Key无序 |
元素无序 |
如何获取集合?
1.手动创建集合.
1.创建空集合
d = {}
创建空集合,只有一种方式:调用set函数.
S = set()
2.创建带元素集合
S = {1,2,3}
从可迭代对象中(字符串,列表,元组,字典)创建集合.
s = set(‘abc’)
S = set([1,2,3])
S = set((1,2,3))
S = set({‘name’:’Andy’,’age’:10})
2.通过方法调用
-> str
-> list
-> set
集合的操作:
查看集合可用的方法:
[x for x in dir(set) if not x.startswith(‘_’)]
['add', 'clear', 'copy', 'difference', 'difference_update', 'discard', 'intersection', 'intersection_update', 'isdisjoint', 'issubset', 'issuperset', 'pop', 'remove', 'symmetric_difference', 'symmetric_difference_update', 'union', 'update']
增:
add:如果元素存在,没有做任何动作.
删:
Pop() :依次从集合中弹出一个元素,如果集合为空,报错
Discard(ele) :从集合中删除指定的元素,如果不存在,什么都不执行
Remove(ele) :从集合中删除指定的元素,如果不存在,报错
Clear() :清空
集合的四大常用操作:
并集:union
交集:intersection
差集:difference
对称差:symmetric_difference
改(更新):
Update :用二者的并集更新当前集合
difference_update:用二者的差集更新当前集合
intersection_update:用二者的交集更新当前集合
symmetric_difference_update:用二者的对称差集更新当前集合
判断功能:
Isdisjoint:判断两个集合是否没有交集
Issubset:判断当前集合是否是后者的子集
Issuperset:判断后者是否是当前集合的子集
查
集合基本没有单独取其中元素的需求.
集合的使用场景:
1.判断一个元素是否在指定的范围之内.
2.方便数学上的集合操作.
并,交,差,对称差
有简化写法:
并:|
交:&
差:-
对称差:^
3.对序列数据类型中的重复元素进行去重
如果想遍历集合中的元素.
通常用for循环.
frozenset:冻结的集合
最大的特点:不可变.
['copy', 'difference', 'intersection', 'isdisjoint', 'issubset', 'issuperset', 'symmetric_difference', 'union']
少了添加,更新的方法.
s = frozenset()
s = frozenset('abcabc')
s = frozenset([1,2,3])
s = frozenset((1,2,3))
s = frozenset({'name':'Andy','age':10})
集合的四大方法:并,交,差,对称差.
set,frozenset是否可以混用?
可以!
总结:
如果两种数据类型混用,方法的主调者的类型决定了最终结果的类型.
frozenset应用场景:
凡是使用到不可改变的数据的场景,都是可以使用frozenset的.
set集合的元素:必须是可以哈希的,set本身不是可以哈希.
但是frozenset是不可变的数据.(可以哈希的),它是可以放到集合中.
set和frozenset可以互相转换.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号