
问题说明
线上服务器运行过程中突然失联,没有自动重启,维护人员进入机房后,接上显示器和鼠标均没反应。重新上电后,没有发现core文件,
检查messages日志没有什么发现,系统coredump设置也没问题。现场最近升级过一个安全版本,可能与这个版本有关系,但是没有core文件,
无法确认问题根本原因。
维护人员重新启动所有版本,不到一天三台机器有两台又出现异常,其中一台有core文件,打开vmcore-dmesg.txt文件,发现有进程发生死锁了。
从vmcore-dmesg.txt获取的异常信息如下:

图1 系统挂死日志
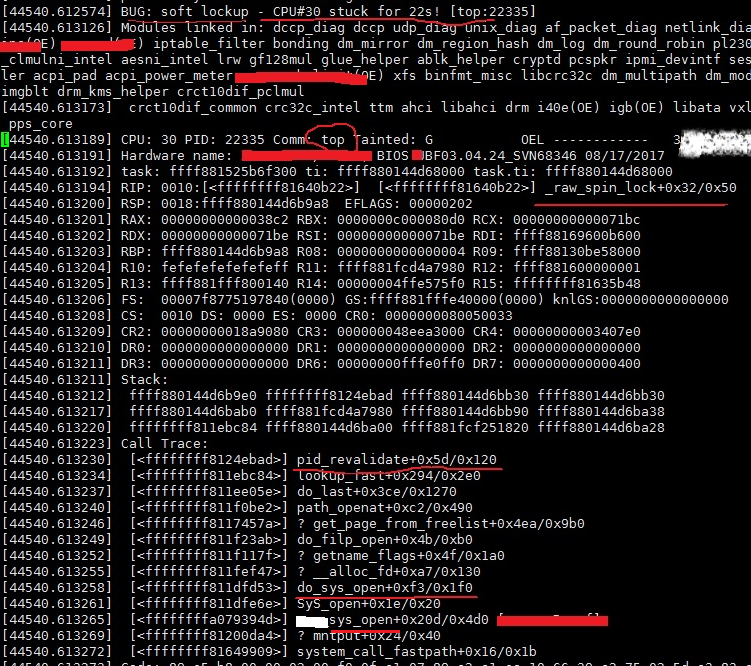
图2 top阻塞堆栈信息
死锁分析
首先确认死锁是在Sys_open函数调用序列上,调用pid_revalidate函数时出现的。
通过反汇编地址,代码如下:
crash> dis -l ffffffff8124ebad
/usr/src/debug/kernel-3.10.0-327.22.2.el7/linux-3.10.0-327.22.2.el7.x86_64/fs/proc/internal.h: 106
0xffffffff8124ebad <pid_revalidate+93>: mov 0x468(%rbx),%rdi
内核代码如下:

图3 阻塞代码
结合堆栈来看,top进程应该是阻塞在task_lock函数中,该函数获取进程的alloc_lock锁被阻塞。该锁用于保护进程数据结构的fs,files,
mm,group_info,以及comm等数据。
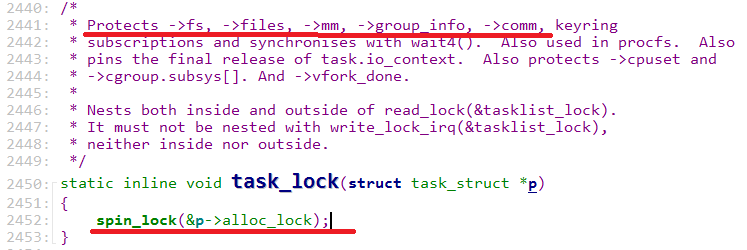
图4 阻塞函数task_lock
为什么top进程被阻塞呢?top进程调用pid_revalidate函数获取alloc_lock失败失败原因是什么?我们从被阻塞进程的堆栈信息开始分析。
再次把top进程的堆栈打印出来,把要分析的重要寄存器用红线标记出来。
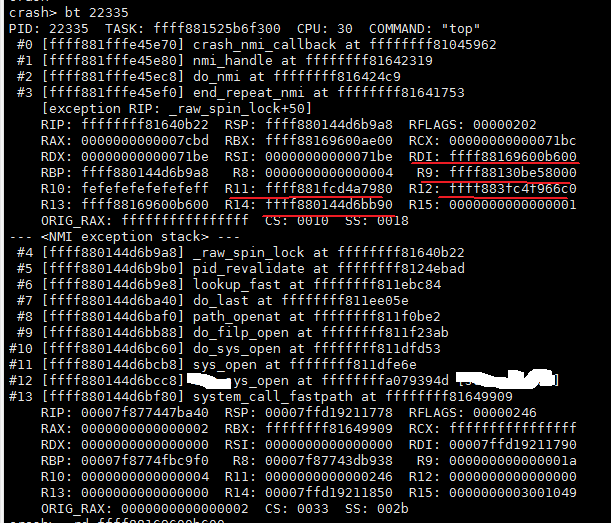
图5 top进程堆栈回溯
RDI寄存器信息:
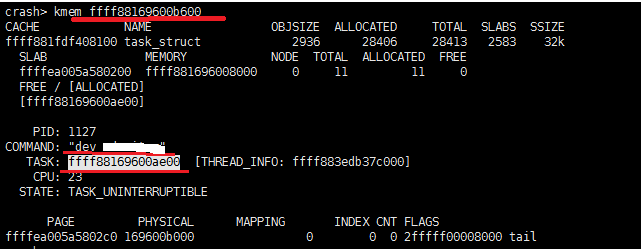
图6 RDI寄存器信息
RDI寄存器保存了进程ID为1127的一个进程(准确说是一个线程)的一个成员地址,从下图运算结果,我们可以知道,
RDI寄存器保存的是进程数据结构中的alloc_lock地址,这个alloc_lock是top进程要获取的锁吗?我们稍后分析证明,先
查看一下其他的寄存器信息。
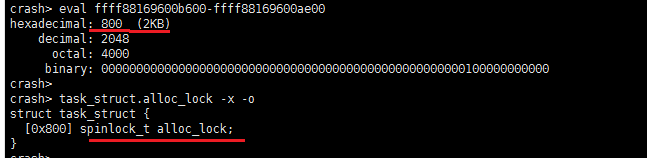
图7 task_struct成员alloc_lock偏移
R9寄存器保存地址的内存信息:
通过读取R9寄存器保存地址的内容,发现地址0xffff88130be58020开始,其内容为/proc/38484/task/1127/stat,
其中进程1127 正是寄存器RDI保存的成员地址所属的进程。我们离真相又进了一步。
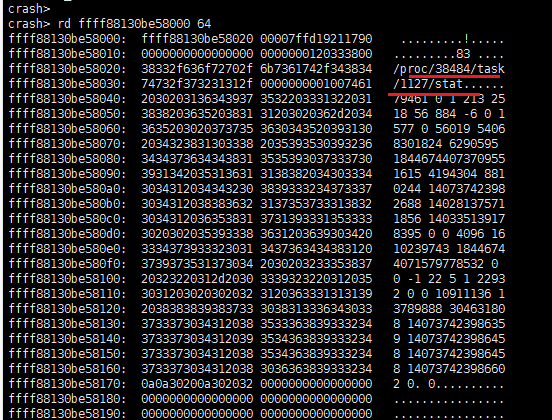
图8 R9寄存器指向的内存信息
这个时候,pid 1127线程在做什么事情呢? 打印1127线程的堆栈信息如下:
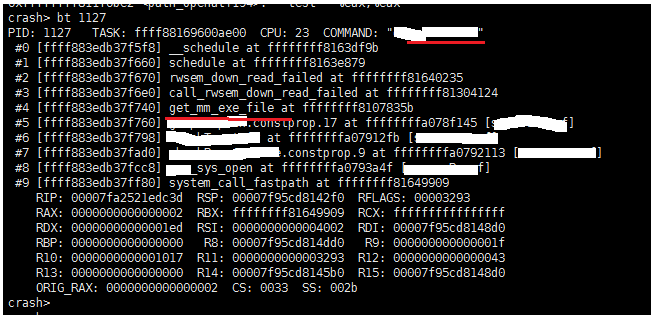
图9 PID 1127线程堆栈回溯
pid 1127线程堆栈信息显示,该进程在调用xxx_sys_open函数(劫持了系统sys_open函数)时调用了get_mm_exe_file函数。
get_mm_exe_file函数定义如下:
1 struct file *get_mm_exe_file(struct mm_struct *mm)
2 {
3 struct file *exe_file;
4
5 /* We need mmap_sem to protect against races with removal of exe_file */
6 down_read(&mm->mmap_sem);
7 exe_file = mm->exe_file;
8 if (exe_file)
9 get_file(exe_file);
10 up_read(&mm->mmap_sem);
11 return exe_file;
12 }
get_mm_exe_file调用堆栈:
get_mm_exe_file
-->down_read ## kernel/rwsem.c
-->__down_read ## arch/alpha/include/asm/rwsem.h
-->call_rwsem_down_read_failed ## arch/x86/lib/rwsem.S
-->rwsem_down_read_failed ## lib/rwsem.c
-->schedule
-->__schedule
从get_mm_exe_file调用堆栈分析,这一过程并没有对task->alloc_lock上锁。再回到1127进程的堆栈,并结合模块代码分析,
发现在调用get_mm_exe_file函数之前,已经获取了alloc_lock锁,代码如下:
1 static struct file *task_exefile(struct task_struct *task)
2 {
3 struct file *exe_file = NULL;
4 struct mm_struct *mm;
5
6 task_lock(task); // 获取task alloc_lock锁
7 mm = task->mm;
8 if (mm) {
9 if (!(task->flags & PF_KTHREAD))
10 {
11 if(get_mm_exe_file_ptr)
12 {
13 exe_file = get_mm_exe_file_ptr(mm); //获取进程可执行文件
14 }
15 else
16 {
17 printk(ERR "get_mm_exe_file_ptr(%p) maybe NULL\n", get_mm_exe_file_ptr);
18 }
19 }
20 }
21 task_unlock(task);
22 return exe_file;
23 }
自此,系统产生死锁的脉络终于清晰了:
pid 1127进程打开文件时被业务内核模块劫持,走到task_exefile函数时,获取了task->alloc_lock锁;然后调用get_mm_exe_file函数时,
主动进行进程调度,可能已经让出cpu;此时另外一个pid为22335的进程(也就是top进程),需要获取task->alloc_lock锁,由于pid 1127线程
长时间没有释放alloc_lock锁,导致pid 22335进程阻塞。最终引起系统异常复位。
那么问题来了,怎么证明pid 22335进程希望获取pid 1127线程的alloc_lock锁呢?我们还是从pid 22335进程的堆栈backtrace分析。
从上述堆栈分析,top进程阻塞在 task_dumpable函数中,该函数由pid_revalidate函数调用。
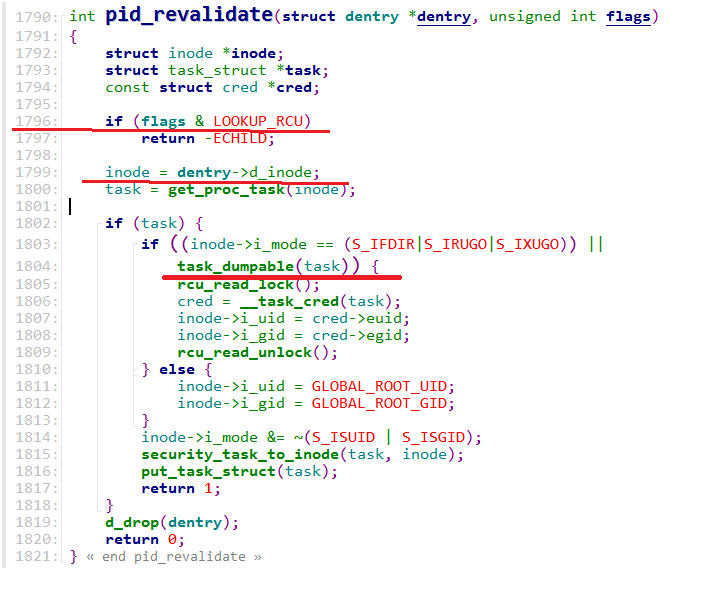
反汇编pid_revalidate函数并分析如下:
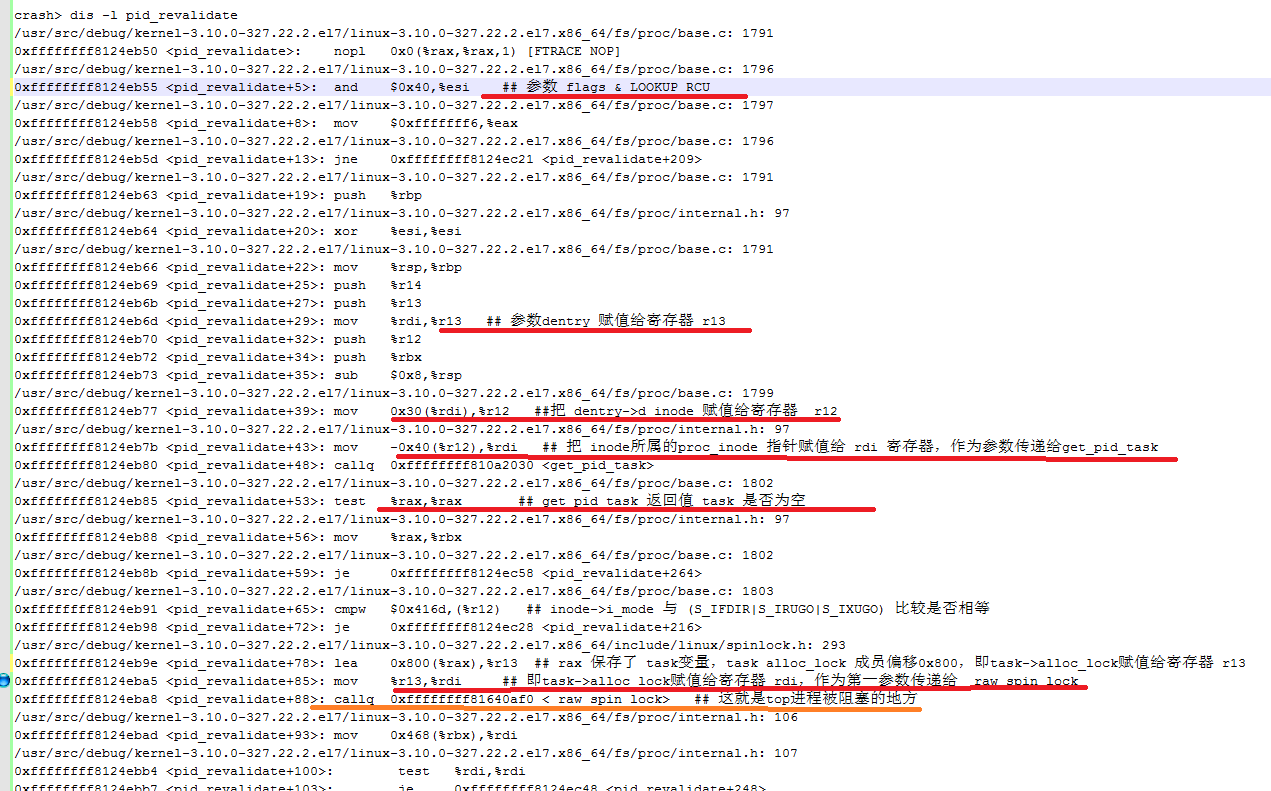
地址为0xffff88169600ae00的task_struct PID和state信息如下:

结合堆栈分析,rdi和r13寄存器保存了同一个值0xffff88169600b600,该值就是task_struct的成员编译alloc_lock值。
通过计算可以得到task值为0xffff88169600ae00(如图6所示)。
由此,我们可以明确得到问题原因:
在业务内核模块调用task_exefile函数时持有 PID 1127线程的alloc_lock锁,且处于TASK_UNINTERRUPTIBLE状态,
top进程在获取PID 1127线程的alloc_lock锁时,就被阻塞了。
您的支持是对博主最大的鼓励👍,感谢您的认真阅读。
本博客持续更新,欢迎您关注和交流!
本文版权归作者所有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。
