Stratum挖矿协议&XMR挖矿流量分析
前言
之前参与了一个关于“挖矿行为检测”的大创训练项目,在这里记录一下我关于挖矿相关内容的学习。
区块链和挖矿相关概念
区块链
首先需要了解一些关于区块链的内容。注意,区块链和挖矿是两个紧密相关但又各自独立的概念,它们并不是同一件事。
区块链是一种分布式账本技术,它通过去中心化的方式安全地记录交易数据。每个区块包含一组交易记录,并通过加密的方式与前一个区块链接起来,形成一个不可篡改的链式结构。这种设计使得区块链具有很高的安全性和透明性。
简单地说,区块链就好比一个公共的账簿,任何人都可以查看账簿中的记录,但一旦记录被写入,就很难更改或删除。这本账簿由网络中的许多人共同维护,每个人都持有账簿的副本。如果想要修改某一条记录,那么就要修改所有的人手中账簿的记录,这是很难做到的。因此很难对其进行篡改。
区块链的几个核心特点:去中心化、不可篡改、透明性、共识机制、智能合约等。
区块
区块链的一个核心组成部分就是区块,区块链也可以说是由多个区块按照时间顺序连接形成的链式数据结构。
每个区块通常包含以下内容:
-
区块头(Block Header):区块头包含了区块的元数据:
版本号:表示区块遵循的协议版本
前一区块的哈希值:前一区块的哈希值确保了区块的顺序和不可篡改性
Merkle根:一种哈希树的根节点,它代表了区块中所有交易的集合,通过它可以快速验证区块中交易的存在性和有效性
时间戳:记录区块被创建的时间
难度目标(Target):挖矿难度的表示,用于挖矿过程中的工作量证明
Nonce(随机数):挖矿过程中使用的一个随机数,用于生成满足特定条件的区块哈希值 -
交易列表(Transaction List):区块中包含的交易,它们是区块的主体部分:
发送者和接收者的公钥或地址
交易金额
交易的附加信息,如交易费用、时间戳等 -
区块大小:区块中所有交易数据的总大小,这个大小通常有最大限制,以保证网络的效率
-
区块哈希(Block Hash):区块头通过哈希函数加密后得到的哈希值,代表了整个区块的独特标识
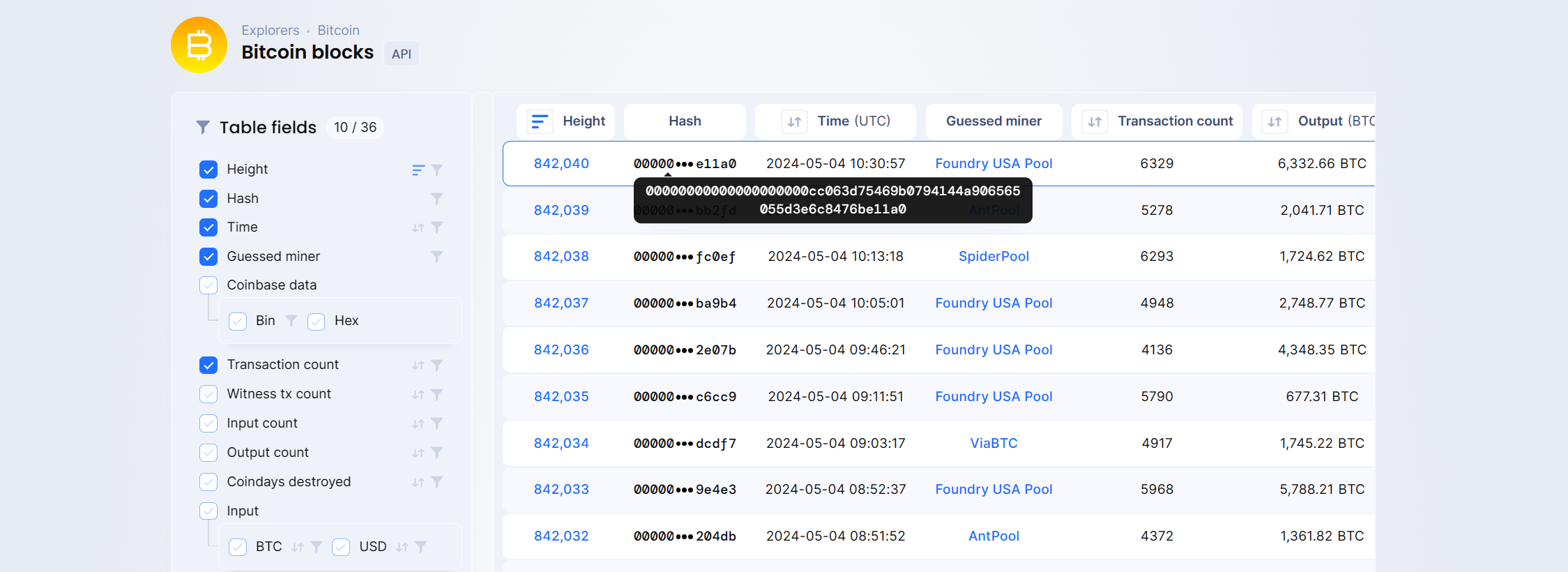
访问这个网站:https://blockchair.com/ 可以浏览各类加密货币的区块情况。
比如下图中的Bitcoin blocks,可以清晰的看到此时最新的一个比特币块为842040,这个块的哈希值为00000...e11a0,时间戳为2024-05-04 10:30:57UTC,由矿工Foundry USA Pool挖到。
区块链相关概念就了解这么多,接下来看看挖矿是怎么回事。
挖矿相关术语
-
矿机:矿机是专门用于挖矿的硬件设备,矿机通常有强大的计算能力。
-
矿池:是一群矿工联合起来共同挖矿的平台,通过提供他们的计算能力合作解决问题,然后按贡献的大小分配奖励。
-
钱包:在区块链和加密货币领域,钱包是用于管理用户的公有和私有密钥、发送和接受数字货币、查看余额等。
挖矿和区块产生的过程密切相关,其实就是个将待确认的交易数据打包成区块并添加到区块链中的过程。
挖矿的目的是什么?
挖矿的主要目的是验证并记录加密货币交易的信息,并且通过这一过程来创建新的加密货币。比如比特币就只能通过挖矿的行为产生,系统通过将比特币作为奖励激励矿工参与记账,挖掘产生新的区块。
说白了挖矿就是通过计算一个难题,优先获得记账权利,从而获得奖励。
下面这个脚本大致描述了一个挖矿的过程:
# 挖矿函数示例(共识算法:工作量证明PoW)
#
def mine_block(version, previous_block_hash, merkle_root_hash, time_stamp, difficulty):
'''
挖矿的过程:通过不断重复计算找到一个使整个区块的哈希值能够小于区块头中难度目标的理想nonce值
version 版本
previous_block_hash 前一个区块头的哈希值
merkle_root_hash 当前块默克尔树根的哈希值,当前区块所有交易产生的默克尔树根节点的哈希值
time_stamp 时间戳
difficulty 当前区块PoW算法的难度值
nonce 随机数
'''
# 根据当前难度值计算出一个目标值(控制的计算量)
# 难度值是一个动态值,会根据网络上的总计算能力进行自动调整,控制在大约10分钟产生一个新区块
target = calculate_target(difficulty)
nonce = 0
while True:
# 构建区块头数据
block_header = f"{version}{previous_block_hash}{merkle_root_hash}{time_stamp}{difficulty}{nonce}".encode('utf-8')
# 计算SHA-256哈希值(两次)
hash_temp = hashlib.sha256(block_header).hexdigest()
hash_result = hashlib.sha256(hash_temp.encode()).hexdigest()
# 将哈希值转换为大整数与target比较,是否达到目标
hash_int = int(hash_result, 16)
if hash_int < target:
print("Nonce:", nonce)
print("Hash:", hash_result)
break
# 随机数+1(根据现在的比特币网络难度,矿工至少需要尝试10^15次)
nonce += 1
简单地说,挖矿就是不断修改区块头中的参数,并计算区块头的哈希值,直到其哈希值与目标难度相匹配的过程。散列函数的结果无法提前得知,所以这个过程十分消耗计算资源。
说了这么多,区块链和挖矿的这些概念其实大概了解就行,下面谈谈本次的重点,挖矿流量的检测分析。
挖矿木马
市面上除了比特币,还有很多其他加密货币。比如以太坊(ETH)、莱特币(LTC)、门罗币(XMR)等。
挖矿木马的常见样本
-
CoinHive:这是最常见的挖矿病毒之一,它通过JavaScript在用户的浏览器中运行来挖取Monero。
-
XMRig:此病毒通常以开源软件的形式提供,用于CPU挖矿,专门针对Monero加密货币。
-
WannaMine:这是一种基于WannaCry勒索软件的挖矿病毒。它使用EternalBlue漏洞来传播,并在受感染的机器上秘密挖矿。
还有非常多各种类型的挖矿木马,这里就不全部介绍了。
挖矿木马控制机器挖矿的方式
-
可执行文件:存储在机器上的典型恶意程序,通常通过设置计划任务或修改注册表项实现持久化,长期进行加密货币的挖矿作业。
-
基于浏览器的挖矿木马:使用JavaScript(或类似技术)的挖矿木马是在浏览器中执行。只要浏览器打开被植入挖矿木马的网站,就会执行挖矿执行,持续消耗资源。
-
无文件挖矿木马:利用如PowerShell等合法工具在机器的内存中执行挖矿作业,具有不落地、难检测等特点。
挖矿木马行为特征
挖矿木马显著的行为特征就是极大的占用CPU及GPU资源。主要包括:CPU和GPU使用率高、响应速度慢、 崩溃或频繁重新启动、系统过热、异常网络活动。其次是在网络流量中,挖矿木马通信过程采用专门的通信协议,因此存在一定的网络通信特征。
检测方法
-
方法1 网络侧检测:通信内容检测和矿池地址域名请求DNS请求历史记录检测。
-
方法2 主机侧检测:对应进程CPU使用率长时间居高不下,部分挖矿木马采用多方式隐藏进程,且具备多种持久化驻留方式。
我们采用的是基于网络侧检测的方案,主要是分析挖矿数据包中的一些特征值进行检测。
挖矿协议Stratum
Stratum协议在2012年被提出,目的是扩展对矿池挖矿的支持,并取代了旧的getwork协议。Stratum协议允许矿机通过TCP连接与矿池使用 JSON-RPC 2.0 消息编码进行通信,从而接收挖矿任务并提交工作证明。
Stratum工作过程
1. 矿机连接服务器
矿机使用 mining.subscribe 方法连接矿池,订阅当前连接。
{
"id": 1,
"method": "mining.subscribe",
"params": []
}
矿池返回相关信息,需要矿工记录在本地。
{
"id": 1,
"result": [
[
"mining.set_difficulty",
"subscription id 1"
],
[
"mining.notify",
"subscription id 2"
]
],
"08000002": 4,
"error": null
}
mining.set_difficulty:用于矿池去设置矿机当前提交任务的最大难度值。
mining.notify:用于矿池向矿机发送新的挖矿任务。
extranonce1:十六进制编码,每个连接唯一的字符串,稍后将用于创建生成的事务。
extranonce2_size:指定在挖矿过程中使用的额外随机数(extranonce2)的大小。
在上面这个示例 "08000002": 4 其中 08000002 表示extranonce1的值,4 表示extranonce2的长度为4字节。
2. 矿工认证
矿机使用 mining.authorize 方法向矿池提供登录凭证,矿池根据提供的信息验证矿工的权限。
{
"id": 2,
"params": [
"miner",
"password"
],
"method": “mining.authorize”
}
矿池返回授权。
{
"error": null,
"id": 2,
"result": true
}
注意这里的这个id号是用来区矿工和矿池的应答消息的,并不是矿工的id。因为矿池的应答消息结构有些很类似,矿机就是通过消息的id来区别这些消息是对应哪个发送消息的应答。
还有通过 jsonrpc 方式登录的,下面会提到。
3. 矿池向矿机下发挖矿工作任务
当矿池在被订阅之后,会使用 mining.notify 方法给矿机发送最少一个工作任务。
{
"params": [
"bf",
"4d16b6f85af6e2198f44ae2a6de67f78487ae5611b77c6c0440b921e00000000",
"01000000010000000000000000000000000000000000000000000000000000000000000000ffffffff20020862062f503253482f04b8864e5008",
"072f736c7573682f000000000100f2052a010000001976a914d23fcdf86f7e756a64a7a9688ef9903327048ed988ac00000000",
[],
"00000002",
"1c2ac4af",
"504e86b9",
false
],
"id": null,
"method": "mining.notify"
}
按顺序描述 params 中每个字段:
-
job_id:任务号id,每一次任务都有唯一的标识符
-
prevhash:前一个区块的hash值
-
coinb1:coinbase币基交易的最初部分
-
coinb2:coinbase币基交易的最后部分
-
merkle_branch:交易列表(hash),用于计算merkle根
-
version:区块版本号
-
nbits:当前区块难度,也是当前每个矿池全网的难度
-
ntime:当前的时间戳
-
clean_jobs:如果为true,矿工应该退出当前工作,立即开始新的工作,如果为false,矿工仍然可以继续当前的挖矿工作
4. 矿机开始挖矿
4.1 构建 coinbase 信息
为什么需要构造coinbase信息?
coinbase交易的存在是网络共识算法的一部分,coinbase交易是每个新区块中的第一个交易,它确认了区块的创建和挖矿过程的成功。在挖矿过程中,矿工需要找到一个特定的哈希值,就修改coinbase交易中的Nonce字段并重新计算区块哈希。
总之,构造coinbase信息对于挖矿过程至关重要,它不仅是矿工获得奖励的手段,也是维护区块链安全性和完整性的关键环节。
构建coinbase信息要用到的数据:coinb1,extranonce1,extranonce2_size,coinb2
在上面的交互过程中已知extranonce2_size,所以能够产生有效的extranonce2。构造coinbase只需要把这几个部分拼接起来:
coinbase = coinb1 + extranonce1 + extranonce2 + coinb2
当然这个conbase还需要进行2次hash运行,投入后面的使用:
# python脚本示例
import hashlib
import binascii
coinbase_hash_bin = hashlib.sha256(hashlib.sha256(binascii.unhexlify(coinbase)).digest()).digest()
4.2 计算 Merkle 根
基本的coinbase构建完毕了,现在就需要把区块中的其他交易给联系起来,需要计算一个merkleroot。
为什么是Merkle根?
Merkle树(也称为二叉哈希树)是一种数据结构,从区块内所有交易的哈希值开始构建,将这些哈希值配对,然后计算每个配对的哈希值,形成第二层。这个过程递归地重复,直到生成单个哈希值,即Merkle根(Merkle Root)。Merkle树允许通过Merkle证明快速验证区块中单个交易的存在性,任何对树中数据的更改都会导致Merkle根的变化。
所以说只要Merkle根没变,区块中的交易就没变。想要证明某个交易是区块的一部分时,就只需要提供Merkle根,无需提供整个区块的数据,这大大提高了效率。
构建Merkle根,利用 coinbase 和 merkle_branch 两两配对,然后把配对完成后进行2次hash运算,得到上一层的结果,然后重复上面的过程,继续配对计算,最终得到Merkle根。
# python脚本示例
import binascii
def build_merkle_root(self, merkle_branch, coinbase_hash_bin):
merkle_root = coinbase_hash_bin
for h in self.merkle_branch:
merkle_root = doublesha(merkle_root + binascii.unhexlify(h))
return binascii.hexlify(merkle_root)
4.3 构建区块头
填充余下的 5 个字段:
block_header = version + prevhash + merkle_root_hash + ntime + nbits + nonce
5. 矿机向矿池提交工作量
当矿工发现符合请求难度的任务,会使用 mining.submit 方法提交给矿池这样的share:
{
"params": [
"miner",
"bf",
"00000001",
"504e86ed",
"b2957c02"
],
"id": 4,
"method": "mining.submit"
}
按顺序描述 params 中每个字段:
-
worker_name:之前认证过的账号
-
job_id:任务号id
-
extranonce2:随机数extranonce2的值
-
ntime:时间戳
-
nonce:随机值
矿池拿到以上5个字段后,首先根据任务号id找出之前分配任务前存储的信息,然后重构区块,再验证share难度,对于符合难度要求的share,在检测是否符合全网难度。
默认share难度是1(难度1的目标是0x00000000ffff0000000000000000000000000000000000000000000000000000),矿池偶尔可以要求矿工更改share难度:
{
"id": null,
"method": "mining.set_difficulty",
"params": [2]
}
这意味着收到服务器工作任务的矿工下一条任务讲改为难度2,这个数字的意思是派给矿机的任务难度是1个单位难度值的2倍。
关于更多Stratum的内容参考:https://en.bitcoin.it/wiki/Stratum_mining_protocol#Protocol
XMR挖矿流量分析
我们首选的加密货币是门罗币(Monero)。门罗币可以使用CPU或GPU进行挖矿,具有隐蔽性强,灵活性高等特点,是挖矿木马的首选,平常实际遇见的挖矿木马挖取的加密货币也几乎都是门罗币。
环境搭建
XMRig挖矿程序下载地址:https://xmrig.com/download
安装好以后,进入xmrig目录,键入 vim config.json 进入编辑模式,把user换成你的钱包地址,url为默认矿池地址,可以不更换。pass为矿机名。

保存并退出,键入 ./xmring 就可以开始愉快的挖矿了。
通过参数指定启动也可以:./xmrig -u 钱包地址 -p 矿机名称 -o 矿池地址
流量分析
需要使用的工具有 tcodump 和 Wireshark 这两个。其中tcodump负责在linux抓包保存为pacp文件,Wireshark负责静态流量分析。
捕获前 10000 个经过 eth0 接口的数据包:
tcpdump -i eth0 -c 10000 -nn -w xmr_capture.pcap
将保存的pacp包使用Wireshark打开,使用过滤器筛选出矿池端口的流量,然后右键追踪流 -> TCP Stream
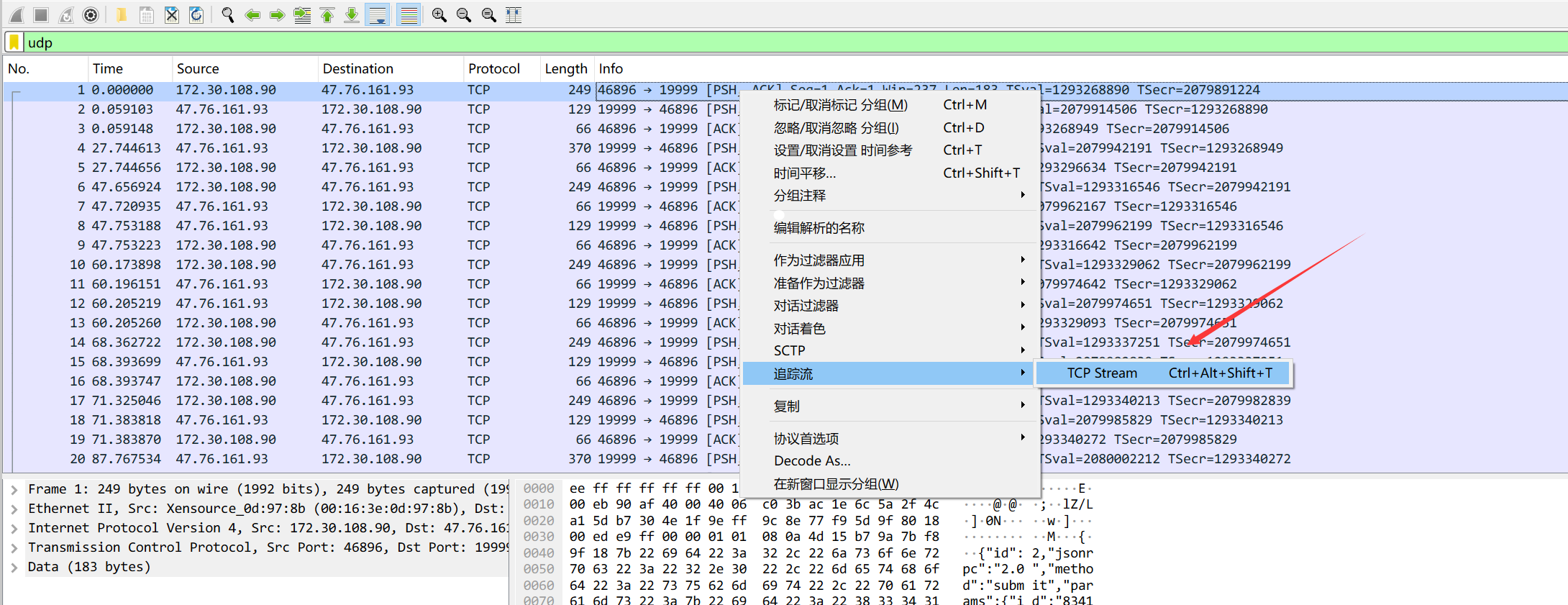
红色为客户端矿机的数据包,蓝色为服务端矿池数据包。
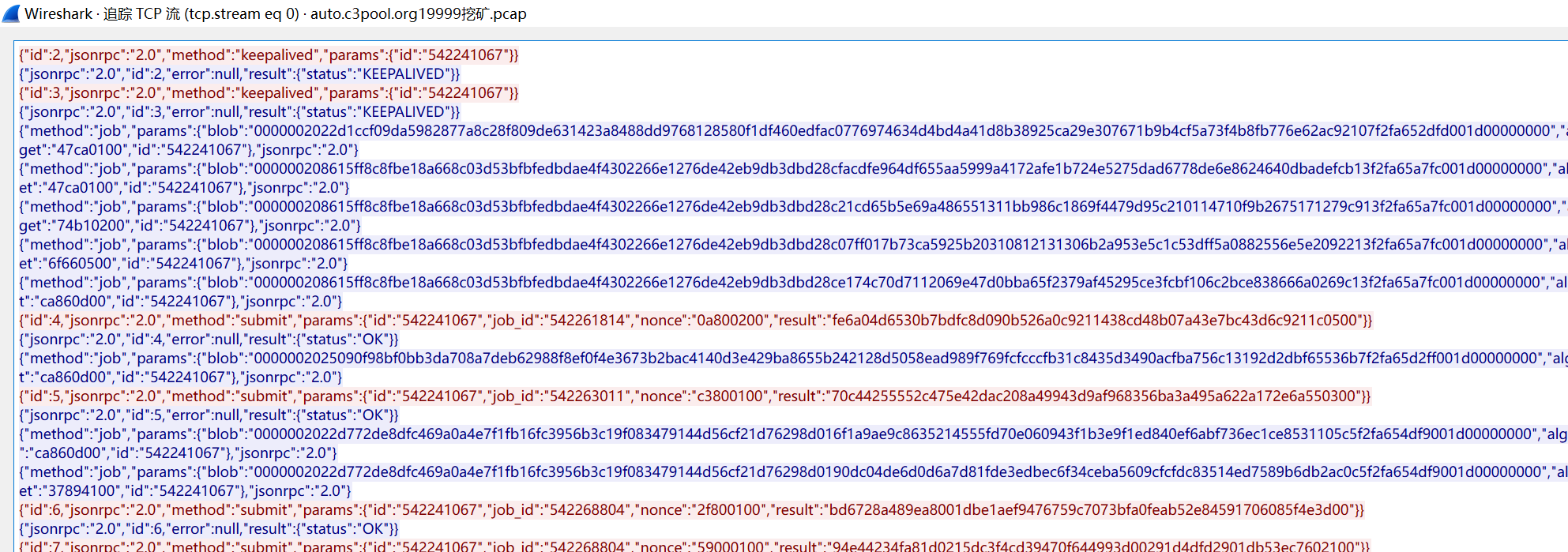
XMR采用Cryptonight算法作为其工作量证明的哈希函数。当使用XMRig进行挖矿时,他所采用的CryptoNight算法可能会产生较多的网络流量,因为它需要频繁地与矿池通信以获取新的挖矿任务。各种挖矿程序在使用Stratum协议的数据格式都会稍有不同,包括XMRig。但是它们都遵循 JSON-RPC 2.0 的规范。
上面所提到登录认证通过mining.authorize方法,而XMRig则是通过jsonrpc方式登录:
{"id":,"jsonrpc":"2.0","method":"login","params":{"login":"","pass":"","agent":"","algo":["","",""]}}
接下来下面来分析在挖矿过程出现最为频繁的两种数据包流量,其一是XMRig挖矿客户端向矿池服务器提交挖矿工作的Request:
{"id":,"jsonrpc":"2.0","method":"submit","params":{"id":"","job_id":"","nonce":"","result":""}}
比如抓到包中的这条id为4的请求数据:
{
"id": 4,
"jsonrpc": "2.0",
"method": "submit",
"params": {
"id": "542241067",
"job_id": "542261814",
"nonce": "0a800200",
"result": "fe6a04d6530b7bdfc8d090b526a0c9211438cd48b07a43e7bc43d6c9211c0500"
}
}
按顺序各个字段:
-
id:这是请求的标识符,用于匹配请求和响应
-
jsonrpc:这指定了JSON-RPC协议的版本,这里是2.0版
-
method:这里的"submit"方法用于提交挖矿工作结果
-
params:这是一个参数对象,包含了提交挖矿结果所需的数据
-
id:是挖矿任务的唯一标识符,用于矿池追踪和管理挖矿任务
-
job_id:这是挖矿任务的ID,矿工使用这个ID来标识他们正在解决的具体工作
-
nonce:Nonce是一个随机数,矿工用它来改变挖矿算法的输入,直到找到一个低于当前网络难度目标的哈希值
-
result:这是挖矿工作的结果,即矿工找到的符合工作量证明条件的哈希值
当矿池服务器接收到这个JSON请求时,它会验证提交的哈希值是否有效,即是否满足当前网络的挖矿难度目标。
其二是矿池服务器向XMRig挖矿客户下发挖矿任务的Response:
{"params":{"blob":"","target":"","job_id":""},"method":""}
接下来分析id为4的响应数据:
在正式的响应数据之前有这样一条json数据:
{
"jsonrpc": "2.0",
"id": 4,
"error": null,
"result": {
"status": "OK"
}
}
这是一个通用的成功响应,再机矿成功提交挖矿工作后由矿池返回。
-
jsonrpc:这里JSON-RPC协议的版本是2.0版
-
id:这是请求的唯一标识符,与之前提到的请求ID相匹配,用于确保响应对应于正确的请求
-
error:表示请求成功,没有发生错误
-
result:包含了请求的结果对象
-
status:表明操作成功完成
返回的第二条数据,是矿池给挖矿客户端发送新的挖矿任务:
{
"method": "job",
"params": {
"blob": "0000002025090f98bf0bb3da708a7deb62988f8ef0f4e3673b2bac4140d3e429ba8655b242128d5058ead989f769fcfcccfb31c8435d3490acfba756c13192d2dbf65536b7f2fa65d2ff001d00000000",
"algo": "ghostrider",
"height": 788962,
"job_id": "542263011",
"target": "ca860d00",
"id": "542241067"
},
"jsonrpc": "2.0"
}
-
method:job 这表明消息是一个挖矿任务的方法调用
-
params:包含了挖矿任务的具体参数
-
blob:挖矿任务的数据,矿工需要对其进行哈希运算直到找到一个低于目标哈希值的解
-
algo:指定了挖矿使用的算法是GhostRider
-
height:表示区块的高度,是区块链中区块的序号
-
job_id:挖矿任务的唯一标识符
-
target:挖矿的目标哈希值,矿工必须找到低于这个值的哈希才算成功
-
id:可能是挖矿客户端的ID或者挖矿任务的某个特定标识符
-
jsonrpc:同样表明消息遵循JSON-RPC 2.0规范
这条响应是矿池向挖矿客户端提供的一个新的挖矿任务。挖矿客户端需要使用提供的 blob 数据和 algo 算法来开始挖矿工作,并尝试找到一个符合 target 要求的哈希值。
总结
对上面的json流量特征分析可以发现,主要特征字段有id,jsonrpc,method,params,job_id,nonce,result等,通过对具体通信数据包进行相应特征字符串的检测,以此来发现挖矿行为的存在。
通过以上的方式,基本能够发现大多数的挖矿行为,但有些情况还是检测不到的。比如使用ssl对Stratum的数据进行加密,那么基于特征字符串的 DPI 技术就无能为力了。
参考文章:
https://en.bitcoin.it/wiki/Stratum_mining_protocol#Protocol
https://github.com/pangsitao/slush_stratum_protocol_zhCN/blob/master/main.md#Stratum协议
https://docs.google.com/document/d/17zHy1SUlhgtCMbypO8cHgpWH73V5iUQKk_0rWvMqSNs/edit?hl=en_US
https://zhuanlan.zhihu.com/p/571589377
https://www.freebuf.com/articles/network/195171.html
https://www.yuameshi.top/2021/05/termux-xmrig/
若有错误,欢迎指正!o( ̄▽ ̄)ブ

 浙公网安备 33010602011771号
浙公网安备 33010602011771号