
Lucene全文检索-从零开始(1)
1.Lucene简介
Lucene是一个开放源代码的全文检索引擎工具包,是一个全文检索引擎的架构,是一款高性能、可扩展的信息检索工具库。
2.全文检索
全文检索是指计算机索引程序通过扫描文章中的每一个词,对每一个词建立一个索引,指明该词在文章中出现的次数和位置,当用户查询时,检索程序就根据事先建立的索引进行查找,并将查找的结果反馈给用户的检索方式。这个过程类似于通过字典中的检索字表查字的过程。
3.为什么要用Lucene
也许有人会说我经常都是用like、Match、contain来做基本查询的。当你只有几百行几千行数据时,查询速度很快,但是如果有几十万几百万条数据呢。下面我们对用like关键字查询和使用Lucene查询的时间进行比较。
3.1 Lucene和like的效率比较
数据表中共有数据146450条。

首先我们用like来查询

接着我们使用Lucene检索
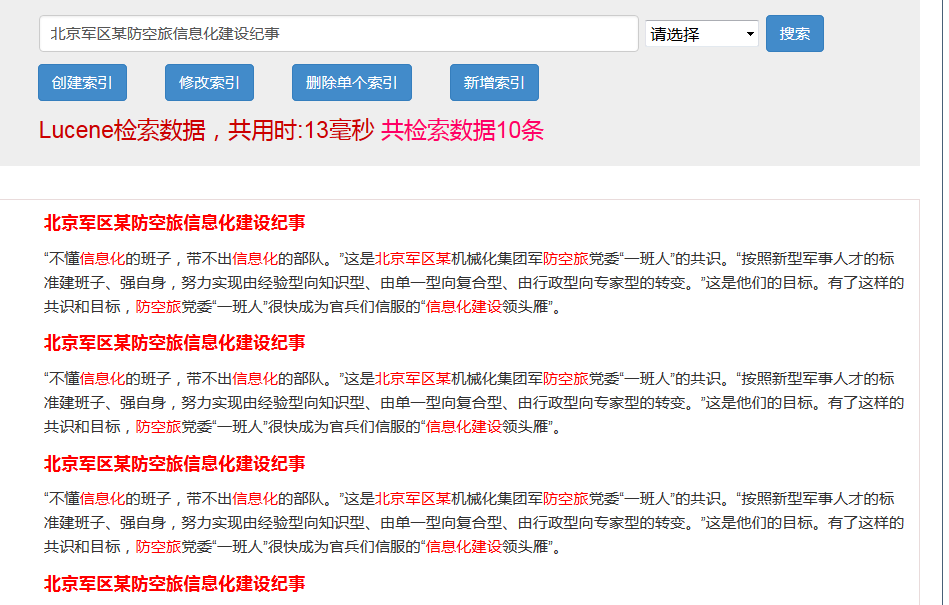
通过比较,两者有着明显的差别,lucene几乎是like的40倍。
4.全文检索中分词器的使用
4.1 盘古分词
1 class Program
2 {
3 /// <summary>
4 /// 盘古分词器
5 /// </summary>
6 public Analyzer panGuAnalyzer
7 {
8 get { return new PanGuAnalyzer(); }
9 }
10
11 static void Main(string[] args)
12 {
13 Analyzer analyzer = new PanGuAnalyzer();
14 TokenStream tokenStream = analyzer.TokenStream("", new StringReader("Hello Lucene.Net,.net全文检索的实现,I love lucene"));
15 Lucene.Net.Analysis.Token token = null;
16 while ((token = tokenStream.Next()) != null)
17 {
18 Console.WriteLine(token.TermText());
19 }
20 Console.ReadKey();
21 }
22
23 }
这个分词效果很棒吧,无论是对中文还是英文。

下一节将会介绍如何创建索引。

