python解析.xml文件-- xmltodict模块(第三方)
第一part:XML文件介绍
1.XML的定义: 指可扩展标记语言(EXtensible Markup Language)。
2.XML的特点:
| 1)XML 是一种很像HTML的标记语言; 2)XML 的设计宗旨是传输数据,而不是显示数据; 3)XML 标签没有被预定义,需要自行定义标签; 4)XML 被设计为具有自我描述性; 5)XML 是 W3C 的推荐标准。 |
3.XML的用途:
| 1)XML把数据从HTML分离; 2)XML简化数据共享; 3)XML简化数据传输; 4)XML简化平台变更; 5)XML使您的数据更有用; 6)XML用于创建新的互联网语言。 |
4.XML的文件内容结构:
元素:指从开始标签到结束标签的部分(均包括开始和结束),一个元素可以包括:子元素,属性和文本。
| 子元素 <people> <name></name> </people> 属性 <sex=’男’></sex> 文本 <age>12</age> |
5.XML语法规则:
| 1)所有的元素都必须有开始标签和结束标签,省略结束标签是非法的; 2)大小写敏感,(比如:<people></people>和<People></People>是两个不同的标签; 3)xml文档必须有根元素; 4)XML必须正确嵌套,父元素必须完全包住子元素; 5)XML属性值必须加引号,元素的属性值都是一个键值对形式。 |
第二part:Python对XML的解析的方法
常见的XML编程接口有DOM和SAX,这两种接口处理XML文件的方式不同, 使用场合也不同。
python有三种方法解析XML:SAX,DOM和ElementTree
|
1)DOM(Document Object Model):
3)ElementTree(元素树) |
xml.dom解析XML详解介绍:
1)先定义一个data4.xml文件,如下: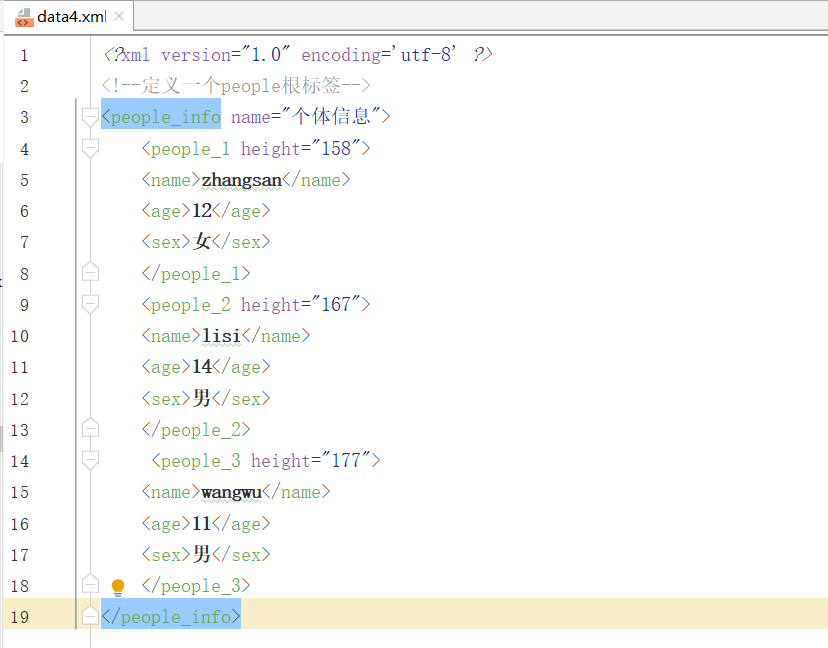
2)安装xmltodict第三方模块:安装的方式有两种,一种是通过命令行 pip install xmltodict;第二种是通过pycharm的settings中搜索安装该模块
3)解析代码:
#导包
import xmltodict
import json
with open("data4.xml",encoding="utf-8") as fp:
# 参数可以是字符串也可以是文件流对象
get_xml=xmltodict.parse(fp.read())
print(get_xml)
print("根标签的属性:",get_xml["people_info"]['@name'])
print("根标签下people_1子标签hegiht属性值:",get_xml["people_info"]["people_1"]["@height"])
fp.seek(0)
#可以直接将结果转换成json格式
print(json.dumps(xmltodict.parse(fp.read()),ensure_ascii=False))
执行结果如下:

4)需求:需要对data4.xml文件中的所有根标签下的以people开头的子标签文本内容全部以字典的形式定义成一组数据,最后全部写入到一个列表中;代码如下:
#导包
import xmltodict
import json
def get_xml_data(input):
'''
:param input: 传入键的开头值
:return:
'''
list1=[]
with open("data4.xml",encoding="utf-8") as fp:
#解析xml得到字典格式;存在根标签
get_result=json.loads(json.dumps(xmltodict.parse(fp.read()),ensure_ascii=False))
#取到根标签的值然后进行遍历键和值,然后再根据键以people开头的标签取出对应的值
for key,value in list(get_result.values())[0].items():
dict1={}
if str(key).startswith(input):
#子标签可能存在属性,属性一般通过xmltodict转换后得到的通常都是以@开头的
for get_key,get_value in value.items():
if not str(get_key).startswith("@"):
dict1[get_key]=get_value
list1.append(dict1)
return list1
#调用测试代码
print(get_xml_data("people"))
执行结果,如下:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号