分布式事务
1、前言
现在的系统越来越复杂,就算针对小型项目一般也会考虑下扩展性,因此,分表分库还是很有必要的,分完库之后,就涉及到了分布式事务的问题,不管是微服务化还是单服务多数据源都面对该问题,当然在sharding-sphere分表分库框架里面,已经解决了当应用的分布式问题。下面我们来了解下分布式事务。
2、事务
事务这个概念做个开发的,大家都比较熟悉,针对事务有4大特性原子性、一致性、隔离性、持久性。我们要理解分布式事务,不能只简单理解事务的4大特性,还得知道数据大概是怎么实现的,为了方便说明,主要以mysql来说说数据库是怎么实现事务的。
2.1 mysql undo 和redo 针对InnoDB的操作
核心的分析可以参考阿里的文章(http://mysql.taobao.org/monthly/2015/05/01/)(http://www.uml.org.cn/sjjm/201205222.asp)
Undo Log的原理
为了满足事务的原子性,在操作任何数据之前,首先将数据备份到一个地方(这个存储数据备份的地方称为Undo Log)。然后进行数据的修改。如果出现了错误或者用户执行了ROLLBACK语句,系统可以利用Undo Log中的备份将数据恢复到事务开始之前的状态。
用Undo Log实现原子性和持久化的事务的简化过程
假设有A、B两个数据,值分别为1,2。
A.事务开始.
B.记录A=1到undo log.
C.修改A=3.
D.记录B=2到undo log.
E.修改B=4.
F.将undo log写到磁盘。
G.将数据写到磁盘。
H.事务提交
这里有一个隐含的前提条件:‘数据都是先读到内存中,然后修改内存中的数据,最后将数据写回磁盘’。
之所以能同时保证原子性和持久化,是因为以下特点:
A. 更新数据前记录Undo log。
B. 为了保证持久性,必须将数据在事务提交前写到磁盘。只要事务成功提交,数据必然已经持久化。
C. Undo log必须先于数据持久化到磁盘。如果在G,H之间系统崩溃,undo log是完整的,可以用来回滚事务。
D. 如果在A-F之间系统崩溃,因为数据没有持久化到磁盘。所以磁盘上的数据还是保持在事务开始前的状态。
缺陷:每个事务提交前将数据和Undo Log写入磁盘,这样会导致大量的磁盘IO,因此性能很低。(其它分析参考http://www.uml.org.cn/sjjm/201205222.asp)
通过mysql InnoDB 的事务简化流程,我们是清楚的知道,在数据库事务提交任何一个流程失败,事务都可以通过undo log 回滚到事务之前到状态的。
我们再来看看java代码事务代码
private Connection conn = null; private PreparedStatement ps = null; try { conn.setAutoCommit(false); //将自动提交设置为false ps.executeUpdate("修改SQL"); //执行修改操作 ps.executeQuery("查询SQL"); //执行查询操作 conn.commit(); //当两个操作成功后手动提交 } catch (Exception e) { conn.rollback(); //一旦其中一个操作出错都将回滚,使两个操作都不成功 }
一阶段提交(Best Efforts 1PC模式)
根据分析 在事务提交conn.commit() 是事务成功与失败的分界点,因此出现了一阶段提交的方案。
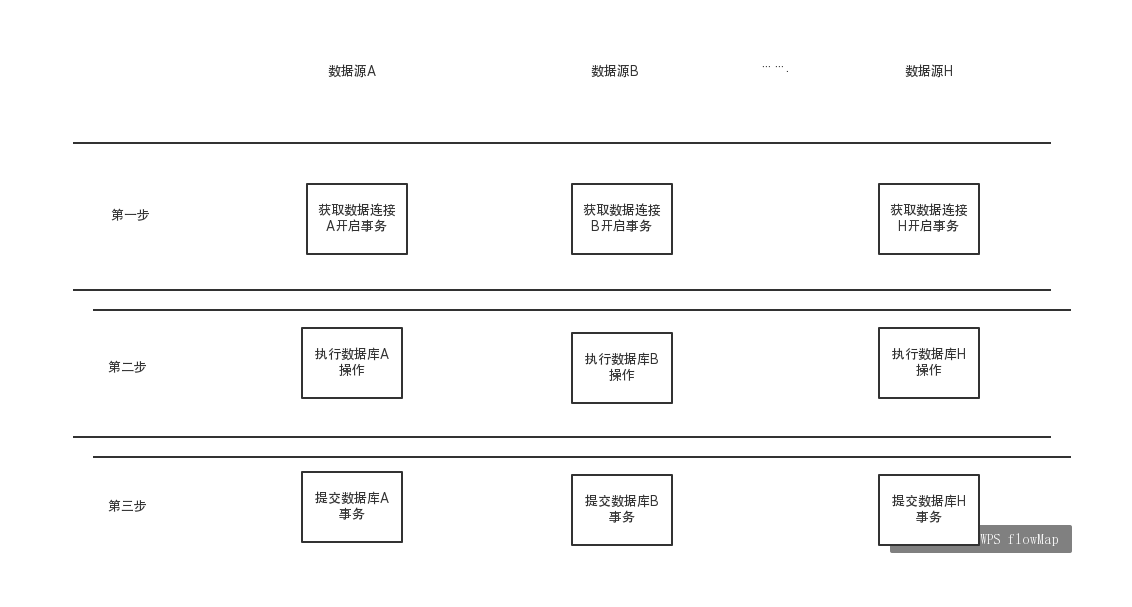
说明:
1、一阶段方案多数据源,同时获取数据库连接,然后同时执行sql,最后同时提交事务;
2、大部分数据库操作失败在第一和第二阶段,在第三阶段失败的情况只有当基础设施出现问题的时候(如网络中断,当机等)。
3、从总的执行时间上看,第一,第二阶段几乎占有整个事务操作时间的99%以上,因此在绝大多数情况下,一阶段事务提交能保证99%以上的事务的准确性。
我们可以在sharding-sphere中看到一阶段提交的代码。
public abstract class AbstractConnectionAdapter extends AbstractUnsupportedOperationConnection { private final Multimap<String, Connection> cachedConnections = LinkedHashMultimap.create(); private boolean autoCommit = true; private boolean readOnly = true; private volatile boolean closed; private int transactionIsolation = TRANSACTION_READ_UNCOMMITTED; private final ForceExecuteTemplate<Connection> forceExecuteTemplate = new ForceExecuteTemplate<>(); private final ForceExecuteTemplate<Entry<String, Connection>> forceExecuteTemplateForClose = new ForceExecuteTemplate<>(); private final RootInvokeHook rootInvokeHook = new SPIRootInvokeHook(); private final TransactionType transactionType; private final ShardingTransactionHandler<ShardingTransactionContext> shardingTransactionHandler; protected AbstractConnectionAdapter(final TransactionType transactionType) { rootInvokeHook.start(); this.transactionType = transactionType; shardingTransactionHandler = ShardingTransactionHandlerRegistry.getInstance().getHandler(transactionType); if (TransactionType.LOCAL != transactionType) { Preconditions.checkNotNull(shardingTransactionHandler, "Cannot find transaction manager of [%s]", transactionType); } } /** * Get database connection. * * @param dataSourceName data source name * @return database connection * @throws SQLException SQL exception */ public final Connection getConnection(final String dataSourceName) throws SQLException { return getConnections(ConnectionMode.MEMORY_STRICTLY, dataSourceName, 1).get(0); } /** * Get database connections. * * @param connectionMode connection mode * @param dataSourceName data source name * @param connectionSize size of connection list to be get * @return database connections * @throws SQLException SQL exception */ public final List<Connection> getConnections(final ConnectionMode connectionMode, final String dataSourceName, final int connectionSize) throws SQLException { DataSource dataSource = getDataSourceMap().get(dataSourceName); Preconditions.checkState(null != dataSource, "Missing the data source name: '%s'", dataSourceName); Collection<Connection> connections; synchronized (cachedConnections) { connections = cachedConnections.get(dataSourceName); } List<Connection> result; if (connections.size() >= connectionSize) { result = new ArrayList<>(connections).subList(0, connectionSize); } else if (!connections.isEmpty()) { result = new ArrayList<>(connectionSize); result.addAll(connections); List<Connection> newConnections = createConnections(connectionMode, dataSource, connectionSize - connections.size()); result.addAll(newConnections); synchronized (cachedConnections) { cachedConnections.putAll(dataSourceName, newConnections); } } else { result = new ArrayList<>(createConnections(connectionMode, dataSource, connectionSize)); synchronized (cachedConnections) { cachedConnections.putAll(dataSourceName, result); } } return result; } @SuppressWarnings("SynchronizationOnLocalVariableOrMethodParameter") private List<Connection> createConnections(final ConnectionMode connectionMode, final DataSource dataSource, final int connectionSize) throws SQLException { if (1 == connectionSize) { return Collections.singletonList(createConnection(dataSource)); } if (ConnectionMode.CONNECTION_STRICTLY == connectionMode) { return createConnections(dataSource, connectionSize); } synchronized (dataSource) { return createConnections(dataSource, connectionSize); } } private List<Connection> createConnections(final DataSource dataSource, final int connectionSize) throws SQLException { List<Connection> result = new ArrayList<>(connectionSize); for (int i = 0; i < connectionSize; i++) { try { result.add(createConnection(dataSource)); } catch (final SQLException ex) { for (Connection each : result) { each.close(); } throw new SQLException(String.format("Could't get %d connections one time, partition succeed connection(%d) have released!", connectionSize, result.size()), ex); } } return result; } private Connection createConnection(final DataSource dataSource) throws SQLException { Connection result = dataSource.getConnection(); replayMethodsInvocation(result); return result; } protected abstract Map<String, DataSource> getDataSourceMap(); @Override public final boolean getAutoCommit() { return autoCommit; } @Override public final void setAutoCommit(final boolean autoCommit) throws SQLException { this.autoCommit = autoCommit; if (TransactionType.LOCAL == transactionType) { recordMethodInvocation(Connection.class, "setAutoCommit", new Class[]{boolean.class}, new Object[]{autoCommit}); forceExecuteTemplate.execute(cachedConnections.values(), new ForceExecuteCallback<Connection>() { @Override public void execute(final Connection connection) throws SQLException { connection.setAutoCommit(autoCommit); } }); } if (autoCommit) { return; } if (TransactionType.XA == transactionType) { shardingTransactionHandler.doInTransaction(new XATransactionContext(TransactionOperationType.BEGIN)); } else if (TransactionType.BASE == transactionType) { shardingTransactionHandler.doInTransaction(new SagaTransactionContext(TransactionOperationType.BEGIN, this)); } } @Override public final void commit() throws SQLException { if (TransactionType.LOCAL == transactionType) { forceExecuteTemplate.execute(cachedConnections.values(), new ForceExecuteCallback<Connection>() { @Override public void execute(final Connection connection) throws SQLException { connection.commit(); } }); } else if (TransactionType.XA == transactionType) { shardingTransactionHandler.doInTransaction(new XATransactionContext(TransactionOperationType.COMMIT)); } else if (TransactionType.BASE == transactionType) { shardingTransactionHandler.doInTransaction(new SagaTransactionContext(TransactionOperationType.COMMIT)); } } @Override public final void rollback() throws SQLException { if (TransactionType.LOCAL == transactionType) { forceExecuteTemplate.execute(cachedConnections.values(), new ForceExecuteCallback<Connection>() { @Override public void execute(final Connection connection) throws SQLException { connection.rollback(); } }); } else if (TransactionType.XA == transactionType) { shardingTransactionHandler.doInTransaction(new XATransactionContext(TransactionOperationType.ROLLBACK)); } else if (TransactionType.BASE == transactionType) { shardingTransactionHandler.doInTransaction(new SagaTransactionContext(TransactionOperationType.ROLLBACK)); } } @Override public final void close() throws SQLException { closed = true; HintManagerHolder.clear(); MasterVisitedManager.clear(); TransactionTypeHolder.clear(); int connectionSize = cachedConnections.size(); try { forceExecuteTemplateForClose.execute(cachedConnections.entries(), new ForceExecuteCallback<Map.Entry<String, Connection>>() { @Override public void execute(final Entry<String, Connection> cachedConnections) throws SQLException { cachedConnections.getValue().close(); } }); } finally { cachedConnections.clear(); rootInvokeHook.finish(connectionSize); } } @Override public final boolean isClosed() { return closed; } @Override public final boolean isReadOnly() { return readOnly; } @Override public final void setReadOnly(final boolean readOnly) throws SQLException { this.readOnly = readOnly; recordMethodInvocation(Connection.class, "setReadOnly", new Class[]{boolean.class}, new Object[]{readOnly}); forceExecuteTemplate.execute(cachedConnections.values(), new ForceExecuteCallback<Connection>() { @Override public void execute(final Connection connection) throws SQLException { connection.setReadOnly(readOnly); } }); } @Override public final int getTransactionIsolation() throws SQLException { if (cachedConnections.values().isEmpty()) { return transactionIsolation; } return cachedConnections.values().iterator().next().getTransactionIsolation(); } @Override public final void setTransactionIsolation(final int level) throws SQLException { transactionIsolation = level; recordMethodInvocation(Connection.class, "setTransactionIsolation", new Class[]{int.class}, new Object[]{level}); forceExecuteTemplate.execute(cachedConnections.values(), new ForceExecuteCallback<Connection>() { @Override public void execute(final Connection connection) throws SQLException { connection.setTransactionIsolation(level); } }); } // ------- Consist with MySQL driver implementation ------- @Override public final SQLWarning getWarnings() { return null; } @Override public void clearWarnings() { } @Override public final int getHoldability() { return ResultSet.CLOSE_CURSORS_AT_COMMIT; } @Override public final void setHoldability(final int holdability) { } }
当transactionType= TransactionType.LOCAL时,所有的事务模式就是一阶段事务提交。
但是一阶段提交在基础设施出现问题的时候还是可以出现事务不一致,那针对银行一类对数据一致性要求非常高的业务,该怎么办。下面来说说两阶段事务
二阶段事务(2PC事务)
大家可以参考(https://sq.163yun.com/blog/article/165554812476866560)

网上大部分的两阶段提交分为准备阶段和提交阶段,图中1,2为准备阶段,3,4为提交阶段。
两阶段又可以分为下面两个分支流程。
1、回滚流程

大概流程:
0、协调者准备
开启事务,写入开启事务的TS log(记录分布式事务的开启),生成全局分支xid(分布式事务的唯一标识),写入参与者信息(记录参与者,方便和参与者通信)。
1、通知参与者开始准备事务
1.1 参与者1收到事务准备通知,发现不能提交进行提交,发送abort 消息给协调者;
1.2 参与者2收到事务准备通知,开始写入redo log(持久化),undo log(原子性),锁定当前记录资源(防止资源被修改),发送commit消息给协调者;
2、协调者收到一个abort 消息和commit消息,判断当前分布式事务需要abort 消息;
3、协调者写入rollback log;
4、协调者发送rollback 指令给参与者;
5、参与者收到rollback指令,
参与者1:什么都不做,发送确认消息给协调者;
参与者2:通过undo log rollback,释放资源,发送确认消息给协调者;
6、协调者收到确认消息,写入事务完成日志。
问题说明:
1、在上面流程中我们可以看见有资源的锁定和释放过程,这个过程降低了系统的性能,如果参与者2在锁定资源之后,系统宕机或者其它情况,这样会存在资源一直占用的问题,因此,整体流程中还得添加资源的,超时释放资源和回滚策略;
2、在协调者和参与者网络和机器都正常的情况下,两阶段提交事务,回滚流程是没有任何问题的,但是在出现网络问题或者宕机情况下,是怎么保证事务的。
协调者宕机情况:
情况1:在第一步之前,协调者宕机,什么都不用处理,
情况2:在收到回滚或者提交消息前,协调者宕机,协调者重启之后(事务是否完成?通过判断是否写入end TS log ),发送abort 消息给所有的参与者(可能有一部分参与者完成了prepare),
情况3:协调者写入rollback log之后任何适合宕机,协调者重启之后(事务是否完成?通过判断是否写入end TS log),发送abort 消息给所有的参与者;
参与者宕机情况
协调者定期给参与者发送指令;
情况1: 阶段一,某个参与者宕机(未完成prepare)
参与者重启后,需要进行回滚(分布式事务的状态是abort)
情况2: 阶段二,某个参与者宕机(已完成prepare)
参与者重启后,参与者如果没有询问其他参与者或协调者事务是否提交的能力,恢复后事务处于悬挂状态,等待协调者指令(分布式事务的决策可能是提交,可能是回滚)
2、提交流程

大概流程:
0、协调者准备
开启事务,写入开启事务的TS log(记录分布式事务的开启),生成全局分支xid(分布式事务的唯一标识),写入参与者信息(记录参与者,方便和参与者通信)。
1、通知参与者开始准备事务
参与者收到事务准备通知,开始写入redo log(持久化),undo log(原子性),锁定当前记录资源(防止资源被修改),发送commit消息给协调者;
2、协调者收到commit消息,判断当前分布式事务需要abort 消息;
3、协调者写入commit log;
4、协调者发送commit 指令给参与者;
5、参与者收到commit指令,参与者 通过redo log commit,释放资源,发送确认消息给协调者;
6、协调者收到确认消息,写入事务完成日志。
问题说明:
1、在上面流程中我们可以看见有资源的锁定和释放过程,这个过程降低了系统的性能,如果参与者2在锁定资源之后,系统宕机或者其它情况,这样会存在资源一直占用的问题,因此,整体流程中还得添加资源的,超时释放资源和回滚策略;
2、在协调者和参与者网络和机器都正常的情况下,两阶段提交事务,回滚流程是没有任何问题的,但是在出现网络问题或者宕机情况下,是怎么保证事务的。
协调者宕机情况:
情况1:在第一步之前,协调者宕机,什么都不用处理,
情况2:在收到回滚或者提交消息前,协调者宕机,协调者重启之后(事务是否完成?通过判断是否写入end TS log ),发送commit 消息给所有的参与者(可能有一部分参与者完成了prepare),
情况3:协调者写入commit log之后任何适合宕机,协调者重启之后(事务是否完成?通过判断是否写入end TS log),发送commit 消息给所有的参与者;
参与者宕机情况
协调者定期给参与者发送指令;
情况1: 阶段一,某个参与者宕机(未完成prepare)
参与者重启后,需要进行回滚(分布式事务的状态是abort)
情况2: 阶段二,某个参与者宕机(已完成prepare)
参与者重启后,参与者如果没有询问其他参与者或协调者事务是否提交的能力,恢复后事务处于悬挂状态,等待协调者指令(分布式事务的决策可能是提交,可能是回滚)
二阶段提交的缺点
-
同步阻塞
事务执行过程中,所有参与节点都是事务阻塞的。当参与者占有资源时,其他访问相关资源的进程也将处于阻塞状态。 参与者对锁资源的释放必须等到事务结束,所以与一阶段提交相比,执行同样的事务,二阶段会耗费更多时间。 事务执行时间的延长意味着锁资源发生冲突的概率增加,当事务并发量达到一定数量时,会出现大量事务积压甚至出现死锁,系统性能会严重下滑。 -
单点故障
一旦协调者发生故障,参与者会一直阻塞。参与者完成准备阶段后,协调者发生故障,所有的参与者都将处于锁定事务资源的状态中(事务悬挂状态),无法继续完成事务操作。 - 数据不一致
在提交阶段中,当协调者向参与者发送commit消息后,发生了局部网络异常或者在发送commit消息过程中协调者发生了故障, 这会导致只有一部分参与者接受到了commit消息。而这些参与者收到commit消息后就会执行commit操作。 但是其他未收到commit消息的参与者无法执行commit。于是整个分布式系统出现了数据不一致性。
3、TCC 分布式事务
4、消息事务

 浙公网安备 33010602011771号
浙公网安备 33010602011771号