学习笔记
1.处理海量数据的核心技术
海量数据存储:分布式
海量数据运算:分布式
2.存储框架
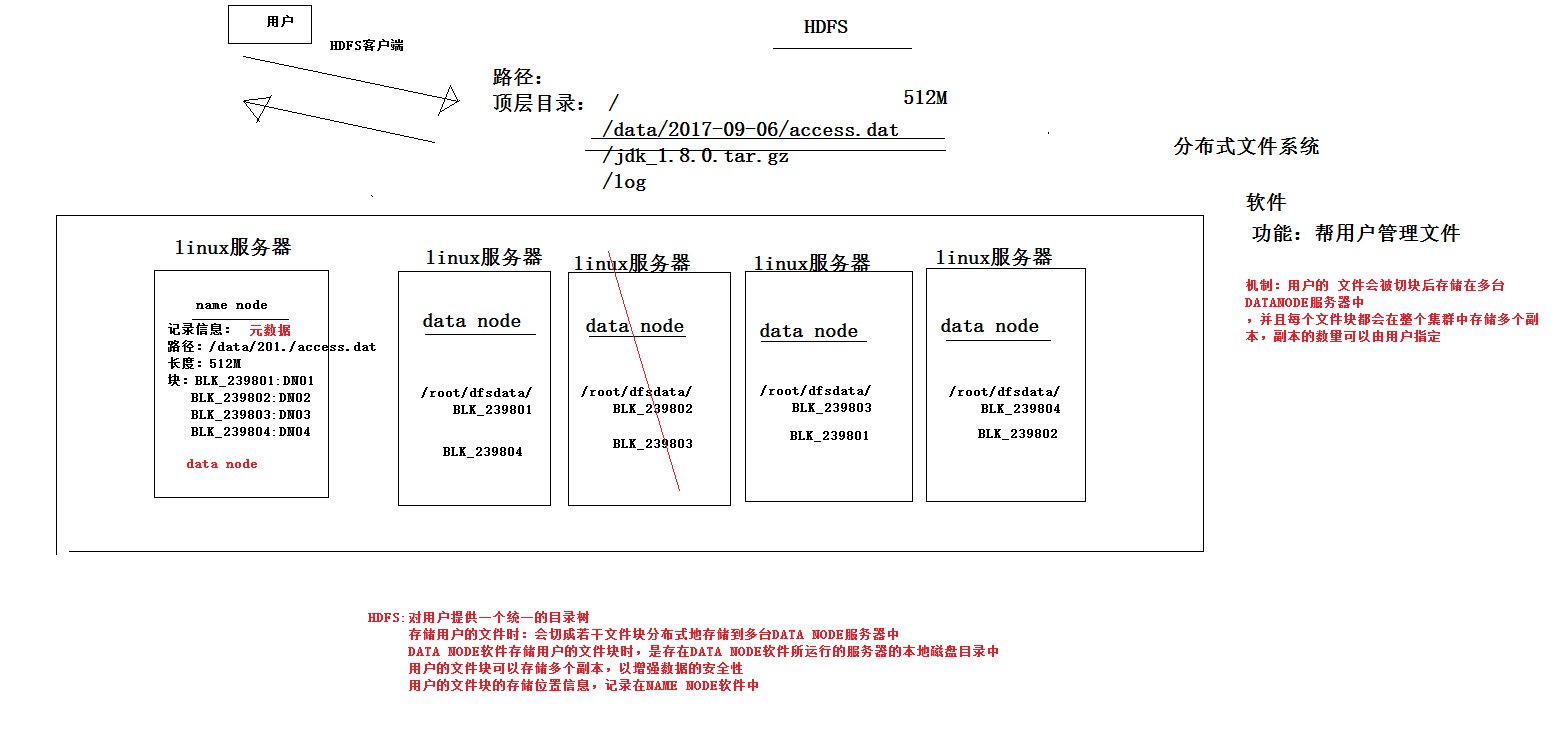
HDFS-----分布式文件存储系统(HADOOP中的存储框架)
HBASE------分布式数据库系统
KAFKA-------分布式消息缓存系统(实时流式数据处理场景中应用广泛)
3.运算框架:(要解决的核心问题就是帮用户将处理逻辑在很多机器上并行)
MAPREDUCE----离线批处理/HADOOP中的运算框架,分布式运算编程框架,实现在很多机器上分布式并行计算
SPARK(本身就是框架)-----离线批处理
STORM------实时流式计算
4.辅助类的工具(解放大数据工程的繁琐工作):
HIVE----数据仓库工具(只是个工具):可以接受SQL,翻译成mapreduce或者spark程序运行
FLUME----数据采集(可以自动采集)
SQOOP----数据迁移
ELASTIC SEARCH---分布式的搜索引擎
5.hadoop中有3个核心组件
分布式文件系统:HDFS----实现将文件分布式存储再很多的服务器上
分布式运算编程框架:MAPREDUCE---实现在很多机器上分布式并行运算
分布式资源调度平台:YARN---帮用户调度大量的mapreduce程序,并合理分配运算资源

 浙公网安备 33010602011771号
浙公网安备 33010602011771号