python 模块
1.定义:
- 模块:用来从逻辑上组织python代码(变量,函数,逻辑:实现一个功能),本质就是.py结尾的python文件(文件名:test.py。)
- 包(文件夹):用来从逻辑上组织模块的,本质就是一个目录,(必须带有一个__init__.py文件)
2.包的导入方法
import 和 from区别:假如有个a.py文件。
- import a:把模块解释了一遍或运行一遍。把a文件中所有代码赋值给了 a变量。
- 使用:变量名.方法 或者 变量名.变量名
- form a import *:把 a文件中所有代码放到当前文件下,执行了一遍。
- 使用:方法名 或 变量名
语法:
import 模块名 # 导入1个模块 import 模块名1,模块名2,...... # 导入多个模块 import 模块名 as 别名 # 给模块起别名 from 模块名 import * # 导入模块下的所有代码,不建议使用 from 模块名 import 方法 # 导入模块下的方法 from 模块名 import 方法 as 别名 # 给模块的方法起别名
2.1 同级目录下导包和模块
- 导入模块的本质就是把python文件解释一遍
- 导入包的本质就是执行该包下的__init__.py文件
文件结构:
- modult_test 包下有三个文件,一个是 a包,一个b包,一个d模块
- a包下有三个文件,一个__init__文件,一个a模块,一个b模块
- b包下有一个c模块。
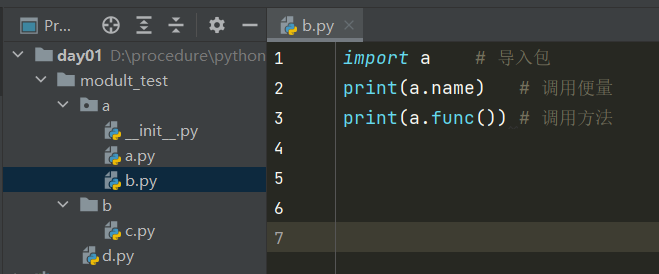
a模块中代码:
name = "Tom"
def func():
print("A.....")
import导入模块示例:b模块执行a模块中代码
import a # 导入包 print(a.name) # 调用便量 print(a.func()) # 调用方法im
import导入包示例:d文件和a包同级
# a包下,__inint__文件中的代码
print("a包下的init文件")
# d模块代码
import a
# 运行d模块 结果:print("a包下的init文件")
from示例:b模块执行a模块中代码
from a import name # 导入a模块中的name变量 from a import func # 导入a模块中的func方法 print(name) # 打变量 func() # 打印方法
2.2 不同级目录下导模块
import示例:
# c模块导入a模块并运行 # 需要先导入modult_test包,再导入a包最后再导入a模块 import modult_test.a.a as aModult print(aModult.name) aModult.func() # d模块导入a模块并运行 import a.a print(a.a.name) a.a.func()
from示例:
# c模块导入a模块中的方法和变量 # 需要先导入d模块的上一级modult_test包,再依次导入模块。 from modult_test.a.a import name from modult_test.a.a import func print(name) func() # d模块导入a模块中的方法和变量 # 需要先导入d模块的上一级modult_test包,再依次导入模块。 from modult_test.a.a import name from modult_test.a.a import func print(name) func()
2.3 添加环境变量
import sys,os path = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))#搜索路径 sys.path.insert(0,path)#添加环境变量
为什么添加环境变量?
- 导入模块时,因为要导入的包没在环境变量里,所以需要层级导入。
- 如果想直接导入,就需要把包上一层的路径添加到环境变量。
示例:
# import添加环境变量导入 import sys,os path = os.path.dirname(os.path.dirname(os.path.abspath(__file__))) # 搜索路径 sys.path.insert(0,path) # 添加环境变量 import d # 导入d模块 print(d.name) d.run() # import:层级导入 import modult_test.d as dModult # 导入d模块 print(dModult.name) dModult.run() # from 导入 from modult_test.d import name from modult_test.d import run print(name) run()



b.py文件 import os print(os.getcwd()) from aa import cc print(cc.a.name) __init__.py 文件 from aa.cc import a a.py文件 name="123"
- 相对路径:可以随意移动包 只要能找到包的位置,就可以使用包里的模块
- 包里的模块如果想使用其它模块的内容只能使用相对路径,使用了相对路径就不能在包内直接执行了

b.py文件 import os print(os.getcwd()) from aa import cc print(cc.a.name) __init__.py 文件 from . import a a.py 文件 from . import a
例子:

a.py文件 import os,sys # 把untitled的绝对路径添加环境变了 sys.path.insert(0,os.path.dirname(os.getcwd())) # 基于 untitled 下的文件夹倒入模块,比如bb文件夹 from bb import b from bb.cc import dd # 绝对路径 if __name__ == '__main__': b.main() print(b.name) print(dd.name_d) dd.py文件 from .. import b # 相对路径 name_d="我是dd文件" print("这是dd文件:",b.name) b.py文件 def main(): print("main") name="jack"
2.4 动态导入模块
创建两个文件,文件a.py 和 lib文件夹同级,文件aa.py 在lib文件夹里。
aa.py文件
class A(object):
def __init__(self):
self.name = "Tom"
a.py文件
lib = __import__('lib.aa') # 这是解释器自己内部用的,导入的是 lib
obj = lib.aa.A()
print(obj.name)
import importlib #官方建议用这个
lib = importlib.import_module("lib.aa") # 导入的是 aa
print(lib)
obj = lib.A()
print(obj.name)
3.time模块和datetime模块
1 import time 2 time.time() #时间戳从1970年期到现在的时间,以秒计算 3 time.daylight #0代表没有使用夏令时 4 time.sleep(2) #睡几秒 5 6 7 时间戳转换成格式化的元组 8 time.gmtime() #标准时间UTC #时间戳转换成元组 9 time.gmtime(123123123) #可以传入参数,单位是秒 10 time.localtime() #本地时间 UTC+8 #时间戳转换成元组 11 x=time.localtiome(123123123) 12 print(x.tm_year) #输出123123123是哪一年 13 元组转换成时间戳 14 time.mktime(x) 15 元组转换成格式化的字符串 16 time.strftime("%Y-%m-%d %H:%M:%S",x) 17 格式化的字符串转换成元组 18 time.strptime("2016-8-21 14:38:50","%Y-%m-%d %H:%M:%S" 19 20 time.asctime() #默认就是当前时间 #元组装换成字符串 21 time.ctime() #默认就是当前时间 #时间戳转换成字符串 22 23 元组 24 time.localtime()
表示时间的三种方式:时间戳、元组(struct_time)、格式化的时间字符串:
1. 时间戳(timestamp) :通常来说,时间戳表示的是从1970年1月1日00:00:00开始按秒计算的偏移量。我们运行“type(time.time())”,返回的是float类型。
#时间戳 >>>time.time() 1500875844.800804
2. 格式化的时间字符串(Format String): '1999-12-06'
%y 两位数的年份表示(00-99) %Y 四位数的年份表示(000-9999) %m 月份(01-12) %d 月内中的一天(0-31) %H 24小时制小时数(0-23) %I 12小时制小时数(01-12) %M 分钟数(00=59) %S 秒(00-59) %a 本地简化星期名称 %A 本地完整星期名称 %b 本地简化的月份名称 %B 本地完整的月份名称 %c 本地相应的日期表示和时间表示 %j 年内的一天(001-366) %p 本地A.M.或P.M.的等价符 %U 一年中的星期数(00-53)星期天为星期的开始 %w 星期(0-6),星期天为星期的开始 %W 一年中的星期数(00-53)星期一为星期的开始 %x 本地相应的日期表示 %X 本地相应的时间表示 %Z 当前时区的名称 %% %号本身
#时间字符串 >>>time.strftime("%Y-%m-%d %X") '2017-07-24 13:54:37' >>>time.strftime("%Y-%m-%d %H-%M-%S") '2017-07-24 13-55-04'
3. 元组(struct_time) :struct_time元组共有9个元素共九个元素:(年,月,日,时,分,秒,一年中第几周,一年中第几天等)
| 索引(Index) | 属性(Attribute) | 值(Values) |
|---|---|---|
| 0 | tm_year(年) | 比如2011 |
| 1 | tm_mon(月) | 1 - 12 |
| 2 | tm_mday(日) | 1 - 31 |
| 3 | tm_hour(时) | 0 - 23 |
| 4 | tm_min(分) | 0 - 59 |
| 5 | tm_sec(秒) | 0 - 60 |
| 6 | tm_wday(weekday) | 0 - 6(0表示周一) |
| 7 | tm_yday(一年中的第几天) | 1 - 366 |
| 8 | tm_isdst(是否是夏令时) | 默认为0 |
#时间元组:localtime将一个时间戳转换为当前时区的struct_time time.localtime() time.struct_time(tm_year=2017, tm_mon=7, tm_mday=24, tm_hour=13, tm_min=59, tm_sec=37, tm_wday=0, tm_yday=205, tm_isdst=0)
几种格式之间的转换

#时间戳-->结构化时间 #time.gmtime(时间戳) #UTC时间,与英国伦敦当地时间一致 #time.localtime(时间戳) #当地时间。与UTC时间相差8小时,UTC时间+8小时 = 当地时间 >>>time.gmtime(1500000000) time.struct_time(tm_year=2017, tm_mon=7, tm_mday=14, tm_hour=2, tm_min=40, tm_sec=0, tm_wday=4, tm_yday=195, tm_isdst=0) >>>time.localtime(1500000000) time.struct_time(tm_year=2017, tm_mon=7, tm_mday=14, tm_hour=10, tm_min=40, tm_sec=0, tm_wday=4, tm_yday=195, tm_isdst=0) #结构化时间-->时间戳 #time.mktime(结构化时间) >>>time_tuple = time.localtime(1500000000) >>>time.mktime(time_tuple) 1500000000.0
#结构化时间-->字符串时间 #time.strftime("格式定义","结构化时间") 结构化时间参数若不传,则显示当前时间 >>>time.strftime("%Y-%m-%d %X") '2017-07-24 14:55:36' >>>time.strftime("%Y-%m-%d",time.localtime(1500000000)) '2017-07-14' #字符串时间-->结构化时间 #time.strptime(时间字符串,字符串对应格式) >>>time.strptime("2017-03-16","%Y-%m-%d") time.struct_time(tm_year=2017, tm_mon=3, tm_mday=16, tm_hour=0, tm_min=0, tm_sec=0, tm_wday=3, tm_yday=75, tm_isdst=-1) >>>time.strptime("07/24/2017","%m/%d/%Y") time.struct_time(tm_year=2017, tm_mon=7, tm_mday=24, tm_hour=0, tm_min=0, tm_sec=0, tm_wday=0, tm_yday=205, tm_isdst=-1)

#结构化时间 --> %a %b %d %H:%M:%S %Y串 #time.asctime(结构化时间) 如果不传参数,直接返回当前时间的格式化串 >>>time.asctime(time.localtime(1500000000)) 'Fri Jul 14 10:40:00 2017' >>>time.asctime() 'Mon Jul 24 15:18:33 2017' #时间戳 --> %a %b %d %H:%M:%S %Y串 #time.ctime(时间戳) 如果不传参数,直接返回当前时间的格式化串 >>>time.ctime() 'Mon Jul 24 15:19:07 2017' >>>time.ctime(1500000000) 'Fri Jul 14 10:40:00 2017'
datetime模块
1.datetime.now() # 获取当前datetime
datetime.utcnow() # 获取当前格林威治时间
from datetime import datetime #获取当前本地时间 a=datetime.now() print('当前日期:',a) #获取当前世界时间 b=datetime.utcnow() print('世界时间:',b)
2.datetime(2017, 5, 23, 12, 20) # 用指定日期时间创建datetime
from datetime import datetime #用指定日期创建 c=datetime(2017, 5, 23, 12, 20) print('指定日期:',c)
3.将以下字符串转换成datetime类型:
'2017/9/30'
'2017年9月30日星期六'
'2017年9月30日星期六8时42分24秒'
'9/30/2017'
'9/30/2017 8:42:50 '
from datetime import datetime d=datetime.strptime('2017/9/30','%Y/%m/%d') print(d) e=datetime.strptime('2017年9月30日星期六','%Y年%m月%d日星期六') print(e) f=datetime.strptime('2017年9月30日星期六8时42分24秒','%Y年%m月%d日星期六%H时%M分%S秒') print(f) g=datetime.strptime('9/30/2017','%m/%d/%Y') print(g) h=datetime.strptime('9/30/2017 8:42:50 ','%m/%d/%Y %H:%M:%S ') print(h)
4.将以下datetime类型转换成字符串:
2017年9月28日星期4,10时3分43秒
Saturday, September 30, 2017
9/30/2017 9:22:17 AM
September 30, 2017
from datetime import datetime i=datetime(2017,9,28,10,3,43) print(i.strftime('%Y年%m月%d日%A,%H时%M分%S秒')) j=datetime(2017,9,30,10,3,43) print(j.strftime('%A,%B %d,%Y')) k=datetime(2017,9,30,9,22,17) print(k.strftime('%m/%d/%Y %I:%M:%S%p')) l=datetime(2017,9,30) print(l.strftime('%B %d,%Y'))
5.用系统时间输出以下字符串:
今天是2017年9月30日
今天是这周的第?天
今天是今年的第?天
今周是今年的第?周
今天是当月的第?天
from datetime import datetime #获取当前系统时间 m=datetime.now() print(m.strftime('今天是%Y年%m月%d日')) print(m.strftime('今天是这周的第%w天')) print(m.strftime('今天是今年的第%j天')) print(m.strftime('今周是今年的第%W周')) print(m.strftime('今天是当月的第%d天'))
4.random模块
1 random.random() #随机0-1之间的浮点数 2 random.randint(1,3) #随机1-3之间的整数 3 random.randrange(1,3) #随机1,2不包括3 4 random.choice("hello") #随机序列,字符串,列表 5 random.sample("hello",2)#随机循环两位 6 random.uniform(1,3) #随机循环1-3的浮点数
1 import random 2 checkcode="" 3 for i in range(4): 4 current=random.randrange(0,4) 5 if current == i: 6 tmp = chr(random.randint(65,90)) 7 else: 8 tmp = random.randint(0,9) 9 checkcode+=str(tmp) 10 print(checkcode)
5.os模块
os模块是与操作系统交互
os模块是与操作系统交互 os.listdir #列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印 os.makedirs(r"E:\a\b\c")#递归创建目录 os.removedirs(r"E:\a\b\c")#递归删除空目录 os.mkdir #创建目录 os.rmdir #删除空目录 os.remove() #删除一个文件 os.rename("old","new") #重命名文件/目录 os.stat(r"hehe") #查看文件/目录信息 os.system("bash command") #运行shell命令,直接显示 os.popen("bash command).read() #运行shell命令,获取执行结果 os.getcwd() #获取当前python脚本的目录路径 os.chdir("E:\\a") #改变当前脚本工作目录 os.chdir(r"E:\a") os.curdir #当前目录( . ) os.pardir #上一级目录( .. ) os.sep #输出操作系统特定的路径分隔符,win下为"\\",Linux下为"/" os.linesep #输出当前平台使用的行终止符,win下为"\t\n",Linux下为"\n" os.pathsep #输出用于分割文件路径的字符串 os.name #输出字符串指示当前使用平台。win->'nt'; Linux->'posix' os.environ #获取系统环境变量 os.path.abspath(path) #返回path规范化的绝对路径 os.path.split(path) #将path分割成目录和文件名二元组返回 os.path.dirname(path) #返回path的目录。其实就是os.path.split(path)的第一个元素 os.path.basename(path) #返回path最后的文件名。如何path以/或\结尾,那么就会返回空值。即os.path.split(path)的第二个元素 os.path.exists(path) #如果path存在,返回True;如果path不存在,返回False os.path.isabs(path) #如果path是绝对路径,返回True os.path.isfile(path) #如果path是一个存在的文件,返回True。否则返回False os.path.isdir(path) #如果path是一个存在的目录,则返回True。否则返回False os.path.join(path1[, path2[, ...]]) #将多个路径组合后返回,第一个绝对路径之前的参数将被忽略 os.path.getsize(path) #返回path的大小 , 文件夹的大小不准确,需要循环获取文件大小 os.path.getatime(path) #返回path所指向的文件或者目录的最后存取时间 os.path.getmtime(path) #返回path所指向的文件或者目录的最后修改时间
注意:os.stat('path/filename') 获取文件/目录信息的结构说明
stat 结构: st_mode: inode 保护模式 st_ino: inode 节点号。 st_dev: inode 驻留的设备。 st_nlink: inode 的链接数。 st_uid: 所有者的用户ID。 st_gid: 所有者的组ID。 st_size: 普通文件以字节为单位的大小;包含等待某些特殊文件的数据。 st_atime: 上次访问的时间。 st_mtime: 最后一次修改的时间。 st_ctime: 由操作系统报告的"ctime"。在某些系统上(如Unix)是最新的元数据更改的时间,在其它系统上(如Windows)是创建时间(详细信息参见平台的文档)。
os.walk是一个简单易用的文件、目录遍历器,可以帮助我们高效的处理文件、目录方面的事情。 os.walk的语法: os.walk(top, topdown=True, οnerrοr=None, followlinks=False) 参数: top 是你所要遍历的目录的地址, 返回的是一个三元组(root,dirs,files) root 所指的是当前正在遍历的这个文件夹的本身的地址 dirs 是一个 list ,内容是该文件夹中所有的目录的名字(不包括子目录) files 同样是 list , 内容是该文件夹中所有的文件(不包括子目录) topdown --为 True,则优先遍历 top 目录,否则优先遍历 top 的子目录(默认为开启)。如果 topdown 参数为 True,walk 会遍历top文件夹,与top 文件夹中每一个子目录。 onerror -- 需要一个 callable 对象,当 walk 需要异常时,会调用。 followlinks -- 如果为 True,则会遍历目录下的快捷方式(linux 下是软连接 symbolic link )实际所指的目录(默认关闭),如果为 False,则优先遍历 top 的子目录。 示例: import os for root,dirs,files in os.walk("文件夹"): print("root-----",root) print("dirs-----",dirs) print("files-----",files) os.walk
6.sys模块
sys.argv # 命令行参数List,第一个元素是程序本身路径 sys.modules # 查看所有自己倒入进来的模块 sys.exit(n) # 退出程序,正常退出时exit(0) sys.version # 获取Python解释程序的版本信息 sys.maxint # 最大的Int值 sys.path # 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值 sys.platform # 返回操作系统平台名称 sys.stdout.write('please:') val = sys.stdin.readline()[:-1]
7.shutil模块
1 shutil.copyfile("本节笔记","本节笔记3") #复制文件 2 shutil.copystat("本节笔记","笔记4") #复制权限 3 shutil.copytree("test4","new_test4")#递归复制目录 4 shutil.rmtree("new_test4") #递归删除目录 5 打包压缩 6 shutil.make_archive("shutil_archive_test","zip","E:\a")
1 import zipfile 2 z = zipfile.ZipFile("day5.zip","w") #默认是读 3 z.write("p_test.py") 4 print("-----") 5 z.write("笔记2") 6 z.close()
1 z = zipfile.ZipFile("day5.zip",'r') 2 z.extractall() 3 z.close()
8.hashlib模块
用于加密相关的操作,3.x里代替了md5模块和sha模块,主要提供 SHA1, SHA224, SHA256, SHA384, SHA512 ,MD5 算法
1 import hashlib 2 3 m = hashlib.md5() 4 m.update(b"Hello") 5 m.update(b"It's me") 6 print(m.digest()) 7 m.update(b"It's been a long time since last time we ...") 8 9 print(m.digest()) #2进制格式hash 10 print(len(m.hexdigest())) #16进制格式hash
1 import hmac 2 h = hmac.new(b"abcde","天王盖地虎".encode(encoding="utf-8")) 3 print(h.digest()) #十进制 4 print(h.hexdigest()) #十六进制
9.Json&pickle数据序列化
用于序列化的两个模块
- json,用于字符串 和 python数据类型间进行转换
-
json能处理简单的数据类型,字典,列表,字符串。
-
json是所有语言通用的,json的作用是不同语言之间进行数据交互。
- pickle,用于python特有的类型 和 python的数据类型间进行转换
Json模块提供了四个功能:dumps、dump、loads、load
pickle模块提供了四个功能:dumps、dump、loads、load
import json dic = {'k1':'v1','k2':'v2','k3':'v3'} str_dic = json.dumps(dic) print(str_dic) dic2 = json.loads(str_dic) print(dic2) list_dic = [1,['a','b','c'],3,{'k1':'v1','k2':'v2'}] str_dic = json.dumps(list_dic) print(str_dic) list_dic2 = json.loads(str_dic) print(list_dic2)
import json f = open('json_file','w') dic = {'k1':'v1','k2':'v2','k3':'v3'} json.dump(dic,f) #dump方法接收一个文件句柄,直接将字典转换成json字符串写入文件 f.close() f = open('json_file') dic2 = json.load(f) #load方法接收一个文件句柄,直接将文件中的json字符串转换成数据结构返回 f.close() print(dic2)
pickle序列化 import pickle def sayhi(name): print("hello,",name) info = { "name":"alex", "age":22, "func":sayhi } f = open("test.txt","wb") f.write(pickle.dumps(info)) f.close() pickle反序列化 import pickle def sayhi(name): print("hello,",name) f = open("test.txt","rb") data = pickle.loads(f.read()) print(data['func']("Alex"))
10.re模块
语法:
re.match(pattern, string, flags=0)
pattern 正则表达式
string 要匹配的字符串
flags 修饰符
常用正则表达式符号:
# 匹配单个字符
'.' 默认匹配除\n之外的任意一个字符,若指定flag DOTALL,则匹配任意字符,包括换行
'[]' 匹配[]中列举的字符
'\d' 匹配数字0-9
'\D' 匹配非数字
'\w' 匹配包括下划线在内任何字母数字字符,相当于[A-Za-z0-9]
'\W' 匹配非任何字母数字字符包括下划线在内,相当于[A-Za-z0-9]
'\s' 匹配空白字符、\t、\n、\r , re.search("\s+","ab\tc1\n3").group() 结果 '\t'
'\S' \S匹配任何非空白字符,它相当于类[^\t\n\r\f\v]
# 转义字符串
'\' 转义字符,把特殊字符串变成普通字符串。
# 匹配多个字符
'*' 匹配*号前的字符0次或多次,re.findall("ab*","cabb3abcbbac") 结果为['abb', 'ab', 'a']
'+' 匹配前一个字符1次或多次,re.findall("ab+","ab+cd+abb+bba") 结果['ab', 'abb']
'?' 匹配前一个字符1次或0次
'{m}' 匹配前一个字符m次
'{n,m}' 匹配前一个字符n到m次,re.findall("ab{1,3}","abb abc abbcbbb") 结果'abb', 'ab', 'abb']
'[^字符串]' 除了[^]里面的字符串都匹配。re.match("[^abcd].*","etc")
# 匹配开头和结尾
'^' 匹配字符开头,若指定flags MULTILINE,这种也可以匹配上(r"^a","\nabc\neee",flags=re.MULTILINE)
'$' 匹配字符结尾,或e.search("foo$","bfoo\nsdfsf",flags=re.MULTILINE).group()也可以
'\A' 只从字符开头匹配,同^。re.search("\Aabc","alexabc") 是匹配不到的
'\Z' 匹配字符结尾,同$
# 匹配分组
'|' 匹配左或右任意一个表达式,re.search("abc|ABC","ABCBabcCD").group() 结果'ABC'
'(...)' 分组匹配,re.search("(abc){2}a(123|456)c", "abcabca456c").group() 结果 abcabca456c
'\num' 引用分组num匹配到的字符串
# \1 是特殊字符需要转移, \\1
'(?P=name)' 分组起别名,引用别名为name分组匹配到的字符串
'(?P<name>...)' 引用别名为name的分组
分组匹配 re.search("(?P<province>[0-9]{4})(?P<city>[0-9]{2})(?P<birthday>[0-9]{4})","371481199306143242").groupdict("city") 结果{'province': '3714', 'city': '81', 'birthday': '1993'}
# 匹配单个字符 # . 匹配除了\n的任意字符数字 res = re.match("...","匹配.").group() print(res) # [] 匹配[]中的数字 res = re.match("..中的字符[0-9]","[]中的字符1").group() print(res) # \d 相当于[0123456789]的数字 res = re.match("..中的字符[\d]","[]中的字符2").group() print(res) # \D 匹配非数字 res = re.match("匹配非数字\D","匹配非数字。").group() print(res) # \w 匹配包括下划线在内任何字母数字字符,相当于[A-Za-z0-9] res = re.match("\w","a").group() print(res) # \W 匹配非任何字母数字字符包括下划线在内,相当于[A-Za-z0-9] res = re.match("\W","!").group() print(res) # \s 匹配空白字符、\t、\n、\r , re.search("\s+","ab\tc1\n3").group() 结果 '\t' res = re.match("哎\s呀","哎 呀").group() print(res) # \S \S匹配任何非空白字符,它相当于类[^\t\n\r\f\v] res = re.match("1\S1","1+1").group() print(res)
# 匹配多个字符 # '*' 匹配*号前的字符0次或多次,re.findall("ab*","cabb3abcbbac") 结果为['abb', 'ab', 'a'] res = re.match("138*","13888888888").group() print(res) # '+' 匹配前一个字符1次或多次,re.findall("ab+","ab+cd+abb+bba") 结果['ab', 'abb'] res = re.match("138.+","13815348").group() print(res) # '?' 匹配前一个字符1次或0次 res = re.match("138?","138").group() print(res) # '{m}' 匹配前一个字符m次 res = re.match("138{2}","1388888").group() print(res) # '{n,m}' 匹配前一个字符n到m次 res = re.findall("ab{1,3}","abb abc abbcbbb") print(res) # [^abcd] 不匹配abcd res = re.match("[^abcd].*","fgj") print(res)
# 匹配开头和结尾 # '^' 匹配字符开头,若指定flags MULTILINE,这种也可以匹配上(r"^a","\nabc\neee",flags=re.MULTILINE) res = re.match("^\d.*","1a").group() print(res) # '$' 匹配字符结尾,或e.search("foo$","bfoo\nsdfsf",flags=re.MULTILINE).group()也可以 res = re.match(".*$","aaa3").group() print(res) # '\A' 只从字符开头匹配,同^。re.search("\Aabc","alexabc") 是匹配不到的 res = re.match("\A\d.*","1a").group() print(res) # '\Z' 匹配字符结尾,同$ res = re.match(".*\Z","bbb3").group() print(res)
# 匹配分组 # '|' 匹配左或右任意一个表达式 fruit = 'apple banana orage pear peach' res = re.search('banana|pear',fruit).group() print(res) # '(...)' 分组匹配,163,126,qq邮箱 res = re.match('[A-Za-z0-9]{4,20}@(163|126|qq)\.com','abcd123@qq.com') print(res.group(1)) # 获取分组的结果,在第一个分组获取 print(res.group()) # '\num' 引用分组num匹配到的字符串,(abc)(123) ,引用第一个分组:\\1 ,引用第二个:\2 # \1 是特殊字符需要转移, \\1 res = re.match('<([A-Za-z0-9]*).*</\\1>','<html>hello</html>').group() print(res) # '(?P=name)' 引用别名为name分组匹配到的字符串 # '(?P<name>...)' 分组匹配 res = re.match('<(?P<name>[A-Za-z0-9]*).*</(?P=name)>','<html>hello</html>').group() print(res)
最常用的匹配语法 :
re.match(pattern, string, flags=0) # 从头开始匹配
re.search(pattern, string, flags=0) # 查找全部字符串,匹配第一符合规则的字符串。
re.findall(pattern, string, flags=0) # 把所有匹配到的字符放到以列表中的元素返回
re.split(pattern, string, maxsplit=0, flags=0) # 以匹配到的字符当做列表分隔符
# maxsplit:指定分割个数
re.sub(pattern, repl, string, count=0, flags=0) # 匹配字符并替换
# repl : 要替换的字符串
# count : 指定匹配个数
re.match().group()
group() # 获取匹配到的所有结果,不管有没有分组将匹配到的全部拿出来,有参取匹配到的第几个如2
groups() # 获取模型中匹配到的分组结果,只拿出匹配到的字符串中分组部分的结果
groupdict() # 获取模型中匹配到的分组结果,只拿出匹配到的字符串中分组部分定义了key的组结果
修饰符:
| 修饰符 | 描述 |
|---|---|
| re.I | 使匹配对大小写不敏感 |
| re.L | 做本地化识别(locale-aware)匹配 |
| re.M | 多行匹配,影响 ^ 和 $ |
| re.S | 使 . 匹配包括换行在内的所有字符 |
| re.U | 根据Unicode字符集解析字符。这个标志影响 \w, \W, \b, \B. |
| re.X | 该标志通过给予你更灵活的格式以便你将正则表达式写得更易于理解。 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号