爬虫2
1.Cookie
-
-
cookie的本质就是一组数据(键值对的形式存在)
-
是由服务器创建,返回给客户端,最终会保存在客户端浏览器中。
-
如果客户端保存了cookie,则下次再次访问该服务器,就会携带cookie进行网络访问。
-
-
-
-
手动处理:将抓包工具中的cookie赋值到headers中即可
-
缺点:
-
编写麻烦
-
cookie通常都会存在有效时长
-
cookie中可能会存在实时变化的局部数据
-
-
-
自动处理
-
基于session对象实现自动处理cookie。
-
1.创建一个空白的session对象。
-
2.需要使用session对象发起请求,请求的目的是为了捕获cookie
-
注意:如果session对象在发请求的过程中,服务器端产生了cookie,则cookie会自动存储在session对象中。
-
-
3.使用携带cookie的session对象,对目的网址发起请求,就可以实现携带cookie的请求发送,从而获取想要的数据。
-
-
注意:session对象至少需要发起两次请求
-
第一次请求的目的是为了捕获存储cookie到session对象
-
后次的请求,就是携带cookie发起的请求了
-
-
import requests #1.创建一个空白的session对象 session = requests.Session() headers = { 'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.80 Safari/537.36', } main_url = 'https://xueqiu.com/' #2.使用session发起的请求,目的是为了捕获到cookie,且将其存储到session对象中 session.get(url=main_url,headers=headers) url = 'https://xueqiu.com/statuses/hot/listV2.json' param = { "since_id": "-1", "max_id": "311519", "size": "15", } #3.就是使用携带了cookie的session对象发起的请求(就是携带者cookie发起的请求) response = session.get(url=url,headers=headers,params=param) data = response.json() print(data)
1.1 timeout 超时
- 在爬虫中,一个请求很久没有结果,就会让整个项目的效率变得非常低,这个时候我们就需要对请求进行强制要求,让他必须在特定的时间内返回结果,否则就报错。
- timeout=3 发送请求后,3秒内没有响应就抛出异常。
import requests url = 'https://twitter.com' response = requests.get(url, timeout=3) # 设置超时时间
- 在使用浏览器上网的时候,有时能够看到下面的提示
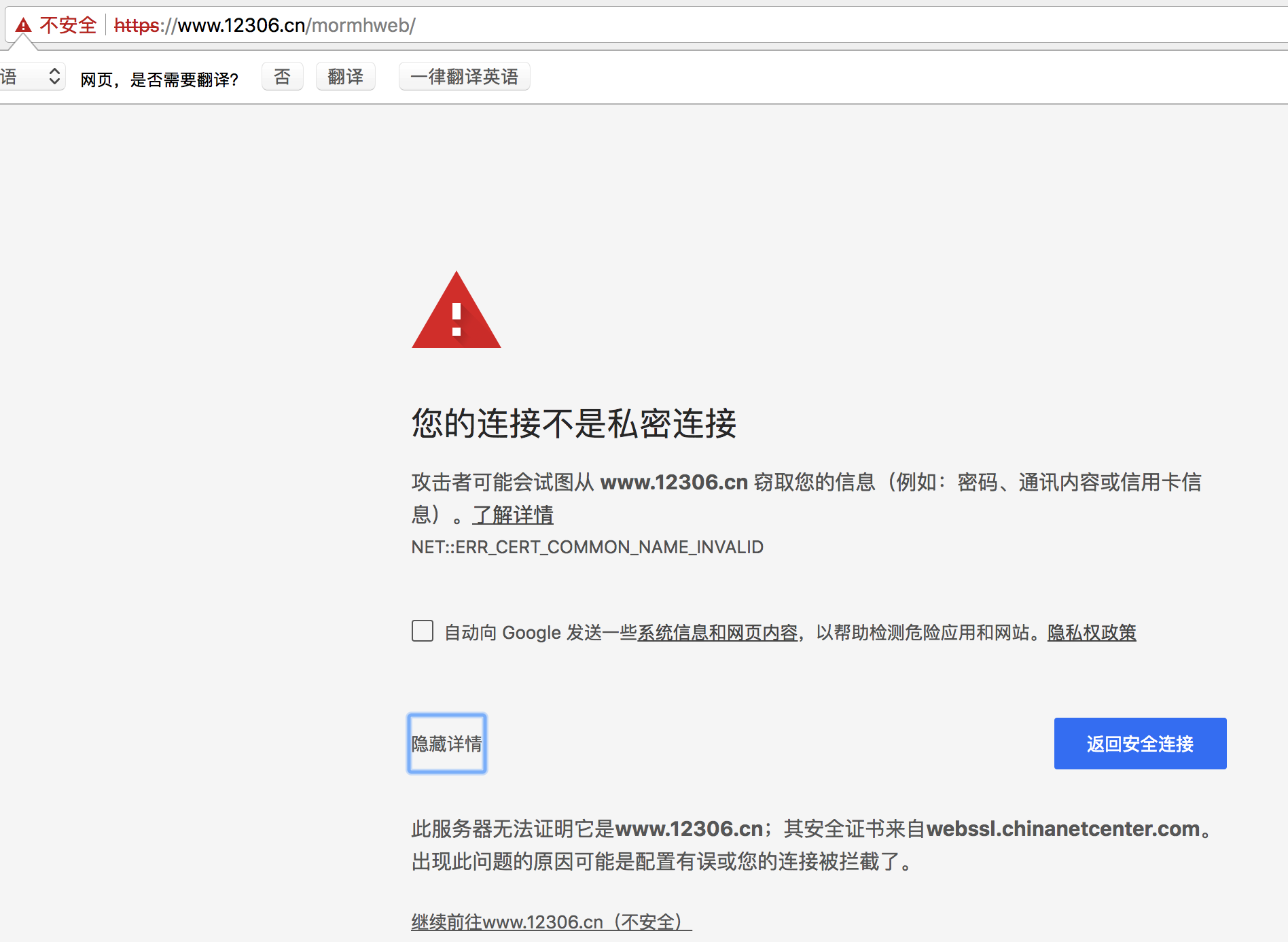
运行下面的代码将会抛出包含ssl.CertificateError ...
import requests url = "https://sam.huat.edu.cn:8443/selfservice/" response = requests.get(url)
解决方案:
import requests url = "https://sam.huat.edu.cn:8443/selfservice/" response = requests.get(url,verify=False)
2. 代理
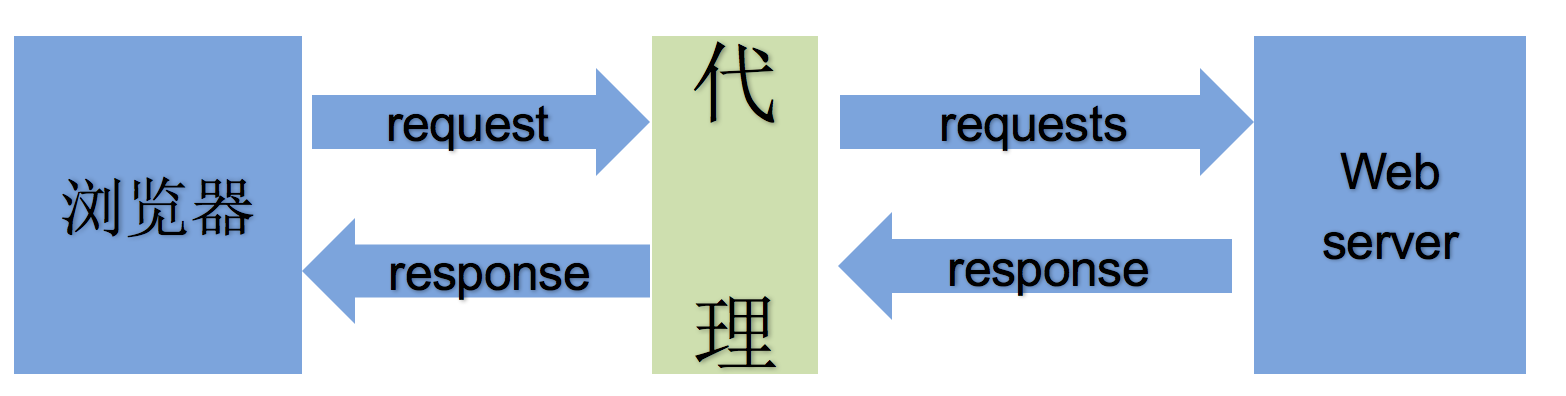
- 为何需要使用代理?
-
REMOTE_ADDR = Proxy IP HTTP_VIA = Proxy IP HTTP_X_FORWARDED_FOR = Your IP
- 匿名代理(Anonymous Proxy):网站服务器知道你使用了代理,但是无法获知你真实的ip。目标服务器接收到的请求头如下:
REMOTE_ADDR = proxy IP HTTP_VIA = proxy IP HTTP_X_FORWARDED_FOR = proxy IP
- 高匿代理(Elite proxy或High Anonymity Proxy):网站服务器不知道你使用了代理,也不知道你的真实ip(推荐)。毫无疑问使用高匿代理效果最好。目标服务器接收到的请求头如下:
REMOTE_ADDR = Proxy IP HTTP_VIA = not determined HTTP_X_FORWARDED_FOR = not determined
根据网站所使用的协议不同,需要使用相应协议的代理服务。从代理服务请求使用的协议可以分为:
-
-
https代理:目标url为https协议
-
socks隧道代理(例如socks5代理)等:
-
socks 代理只是简单地传递数据包,不关心是何种应用协议(FTP、HTTP和HTTPS等)。
-
socks 代理比http、https代理耗时少。
-
-
import requests from lxml import etree headers = { 'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.80 Safari/537.36', } url = 'https://www.sogou.com/web?query=ip' page_text = requests.get(url=url,headers=headers).text tree = etree.HTML(page_text) data = tree.xpath('//*[@id="ipsearchresult"]/strong/text()')[0] print(data)
import requests from lxml import etree headers = { 'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.80 Safari/537.36', } url = 'https://www.sogou.com/web?query=ip' #使用代理服务器发起请求 #proxies={'代理类型':'ip:port'} page_text = requests.get(url=url,headers=headers,proxies={'https':'42.57.150.150:4278'}).text tree = etree.HTML(page_text) data = tree.xpath('//*[@id="ipsearchresult"]/strong/text()')[0] print(data)
3. 验证码
-
-
使用图鉴识别古诗文网登录中的验证码
-
古诗文网:
-
-
-
注册登录图鉴平台
-
登录后,点击开发文档,提取识别的源代码
-
-
import base64 import json import requests # 一、图片文字类型(默认 3 数英混合): # 1 : 纯数字 # 1001:纯数字2 # 2 : 纯英文 # 1002:纯英文2 # 3 : 数英混合 # 1003:数英混合2 # 4 : 闪动GIF # 7 : 无感学习(独家) # 11 : 计算题 # 1005: 快速计算题 # 16 : 汉字 # 32 : 通用文字识别(证件、单据) # 66: 问答题 # 49 :recaptcha图片识别 # 二、图片旋转角度类型: # 29 : 旋转类型 # # 三、图片坐标点选类型: # 19 : 1个坐标 # 20 : 3个坐标 # 21 : 3 ~ 5个坐标 # 22 : 5 ~ 8个坐标 # 27 : 1 ~ 4个坐标 # 48 : 轨迹类型 # # 四、缺口识别 # 18 : 缺口识别(需要2张图 一张目标图一张缺口图) # 33 : 单缺口识别(返回X轴坐标 只需要1张图) # 五、拼图识别 # 53:拼图识别 #函数实现忽略 def base64_api(uname, pwd, img, typeid): with open(img, 'rb') as f: base64_data = base64.b64encode(f.read()) b64 = base64_data.decode() data = {"username": uname, "password": pwd, "typeid": typeid, "image": b64} result = json.loads(requests.post("http://api.ttshitu.com/predict", json=data).text) if result['success']: return result["data"]["result"] else: return result["message"] return "" def getImgCodeText(imgPath,imgType):#直接返回验证码内容 #imgPath:验证码图片地址 #imgType:验证码图片类型 result = base64_api(uname='bb328410948', pwd='bb328410948', img=imgPath, typeid=imgType) return result
-
验证码图片识别操作
from lxml import etree import requests import tujian headers = { 'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36' } #将验证码图片请求后保存到本地 login_url = 'https://so.gushiwen.cn/user/login.aspx?from=http://so.gushiwen.cn/user/collect.aspx' page_text = requests.get(url=login_url,headers=headers).text tree = etree.HTML(page_text) img_src = 'https://so.gushiwen.cn'+tree.xpath('//*[@id="imgCode"]/@src')[0] code_data = requests.get(url=img_src,headers=headers).content with open('./code.jpg','wb') as fp: fp.write(code_data) #识别验证码图片内容 result = tujian.getImgCodeText('./code.jpg',3) print(result)
4. 模拟登录
-
-
在抓包工具里定位点击登录按钮后对应的数据包:
-
只要数据包的请求参数中包含用户名,密码和验证码则该数据包就是我们要定位的
-
-
from lxml import etree import requests import tujian headers = { 'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36' } #将验证码图片请求后保存到本地 login_url = 'https://so.gushiwen.cn/user/login.aspx?from=http://so.gushiwen.cn/user/collect.aspx' page_text = requests.get(url=login_url,headers=headers).text tree = etree.HTML(page_text) img_src = 'https://so.gushiwen.cn'+tree.xpath('//*[@id="imgCode"]/@src')[0] code_data = requests.get(url=img_src,headers=headers).content with open('./code.jpg','wb') as fp: fp.write(code_data) #识别验证码图片内容 result = tujian.getImgCodeText('./code.jpg',3) print(result) #模拟登录 url = 'https://so.gushiwen.cn/user/login.aspx?from=http%3a%2f%2fso.gushiwen.cn%2fuser%2fcollect.aspx' data = { "__VIEWSTATE": "opfVI7oolwkr7MLRVzsNSMASqLRUuO1dg5ZP5EIRa4FyM+mOYKEs6KWEKQKaba2ulLoZQIaLFiKK4mr5K3ci1v8ua28wtcRtabKWjOtJtU/i2etH+zSduegTMcg=", "__VIEWSTATEGENERATOR": "C93BE1AE", "from": "http://so.gushiwen.cn/user/collect.aspx", "email": "15027900535", "pwd": "bobo@15027900535", "code":result , "denglu": "登录" } #获取了登录成功后的页面源码数据 login_page_text = requests.post(url=url,headers=headers,data=data).text with open('wushiwen.html','w') as fp: fp.write(login_page_text)
-
验证码不对(否定)
-
没有携带cookie
-
出现了动态变化的请求参数
-
如何获取动态变化的请求参数
-
-
from lxml import etree import requests import tujian headers = { 'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36' } #创建session对象 session = requests.Session() #将验证码图片请求后保存到本地 login_url = 'https://so.gushiwen.cn/user/login.aspx?from=http://so.gushiwen.cn/user/collect.aspx' page_text = session.get(url=login_url,headers=headers).text tree = etree.HTML(page_text) img_src = 'https://so.gushiwen.cn'+tree.xpath('//*[@id="imgCode"]/@src')[0] code_data = session.get(url=img_src,headers=headers).content with open('./code.jpg','wb') as fp: fp.write(code_data) #解析出动态变化的请求参数 __VIEWSTATE = tree.xpath('//*[@id="__VIEWSTATE"]/@value')[0] #识别验证码图片内容 result = tujian.getImgCodeText('./code.jpg',3) print(result) #模拟登录 url = 'https://so.gushiwen.cn/user/login.aspx?from=http%3a%2f%2fso.gushiwen.cn%2fuser%2fcollect.aspx' data = { "__VIEWSTATE": __VIEWSTATE, "__VIEWSTATEGENERATOR": "C93BE1AE", "from": "http://so.gushiwen.cn/user/collect.aspx", "email": "15027900535", "pwd": "bobo@15027900535", "code":result , "denglu": "登录" } #获取了登录成功后的页面源码数据 login_page_text = session.post(url=url,headers=headers,data=data).text with open('wushiwen.html','w') as fp: fp.write(login_page_text)
-
-
以图片为例,访问图片要从他的网站访问才可以,否则直接访问图片地址得不到图片
-
-
练习:抓取微博图片,url:http://blog.sina.com.cn/lm/pic/,将页面中某一组系列详情页的图片进行抓取保存,比如三里屯时尚女郎:http://blog.sina.com.cn/s/blog_01ebcb8a0102zi2o.html?tj=1
-
注意:
-
1.在解析图片地址的时候,定位src的属性值,返回的内容和开发工具Element中看到的不一样,通过network查看网页源码发现需要解析real_src的值。
-
2.直接请求real_src请求到的图片不显示,加上Refere请求头即可
-
-
-
import requests from lxml import etree headers = { 'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36', "Referer": "http://blog.sina.com.cn/", } url = 'http://blog.sina.com.cn/s/blog_01ebcb8a0102zi2o.html?tj=1' page_text = requests.get(url,headers=headers).text tree = etree.HTML(page_text) img_src = tree.xpath('//*[@id="sina_keyword_ad_area2"]/div/a/img/@real_src') for src in img_src: data = requests.get(src,headers=headers).content with open('./123.jpg','wb') as fp: fp.write(data) # break
6. 懒加载
-
-
爬取上述链接中所有的图片数据
-
图片懒加载:
-
主要是应用在展示图片的网页中的一种技术,该技术是指当网页刷新后,先加载局部的几张图片数据即可,随着用户滑动滚轮,当图片被显示在浏览器的可视化区域范围的话,在动态将其图片请求加载出来即可。(图片数据是动态加载出来)。
-
如何实现图片懒加载/动态加载?
-
使用img标签的伪属性(指的是自定义的一种属性)。在网页中,为了防止图片马上加载出来,则在img标签中可以使用一种伪属性来存储图片的链接,而不是使用真正的src属性值来存储图片链接。(图片链接一旦给了src属性,则图片会被立即加载出来)。只有当图片被滑动到浏览器可视化区域范围的时候,在通过js将img的伪属性修改为真正的src属性,则图片就会被加载出来。
-
-
-
如何爬取图片懒加载的图片数据?
-
import requests import re header = { 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36' } url = "https://sc.chinaz.com/tupian/meinvtupian.html" res = requests.get(url=url,headers=header) res.encoding="utf-8" html_text = res.text ex = re.findall('<div class="item".*?data-original="(.*?)"',html_text,re.S) for i in ex: new_url = "https:"+i aa = requests.get(url=new_url,headers=header) img = aa.content name = i.split('/')[-1] with open(name,'wb') as f: f.write(img) print(name,"下载成功")

