
flink cdc 3.0 "尝鲜"
背景
在大数据实时同步的场景中,一个常见场景是从 mysql OLTP 数据库同步到 doris OLAP 数据库,前者属于业务系统通常情况下使用的数据库,后者提供给业务的同事进行高并发、大批量的数据计算和分析
今年年初时,我们这里的部署方案还是 flink cdc 2.4 + flink sql,任务在 yarn 上运行,架构如下:
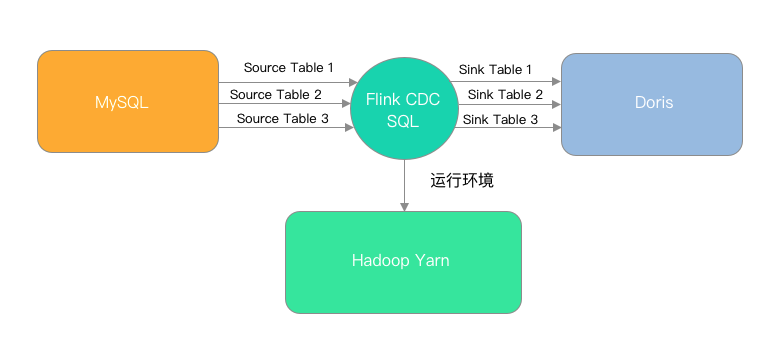
这个架构在需要同步的表不多的情况下,维护起来不算麻烦,不过也有两个实践中很关键的问题: 通过 SQL 提交后每张表都会单独拉取 binlog,造成资源浪费,以及频繁拉取造成 MySQL 压力较大;其次是不支持表结构同步,比如 mysql 新增了字段,虽然不会直接导致同步任务报错(修改字段类型除外),但是一旦业务说需要用到这个字段,那我就需要在 flink sql 中加上这个字段,下游的 doris 手动执行 alter 去添加字段,再把 flink 任务重启,这些操作,比创建一个新的任务还要麻烦
于是在看到 flink 3.0 对 schema evolution 和批量表同步支持之后,我也是第一时间去尝鲜,根据官方文档: Streaming ELT 同步 MySQL 到 Doris,在本地运行了整套 mysql 、 doris 、 flink 以及 flink cdc 任务。本文总结了整套服务部署过程,也提示一些遇到的小坑,希望助大家丝滑体验 flink cdc
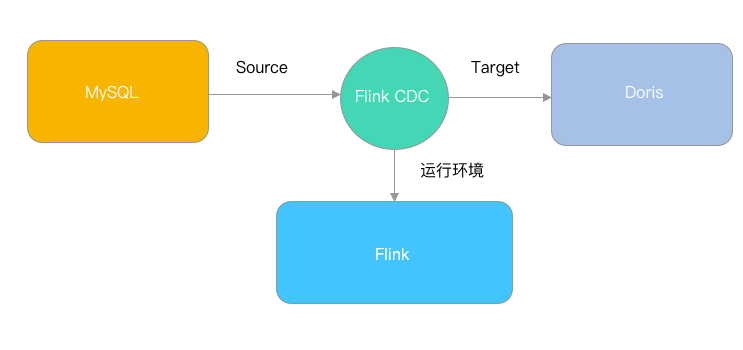
flink cdc 3.0 之后的任务架构如下:
flink cdc 功能速览
flink cdc 是一个支持实时同步的数据流框架,相比其他第三方实现的实时同步框架,如 seatunnel、chunjun 等,它的优势在于 flink 社区原生支持,版本迭代和新功能发布更快,不足点在于缺少任务管理功能,需要自己做好任务监控和自动恢复机制
3.0 架构:
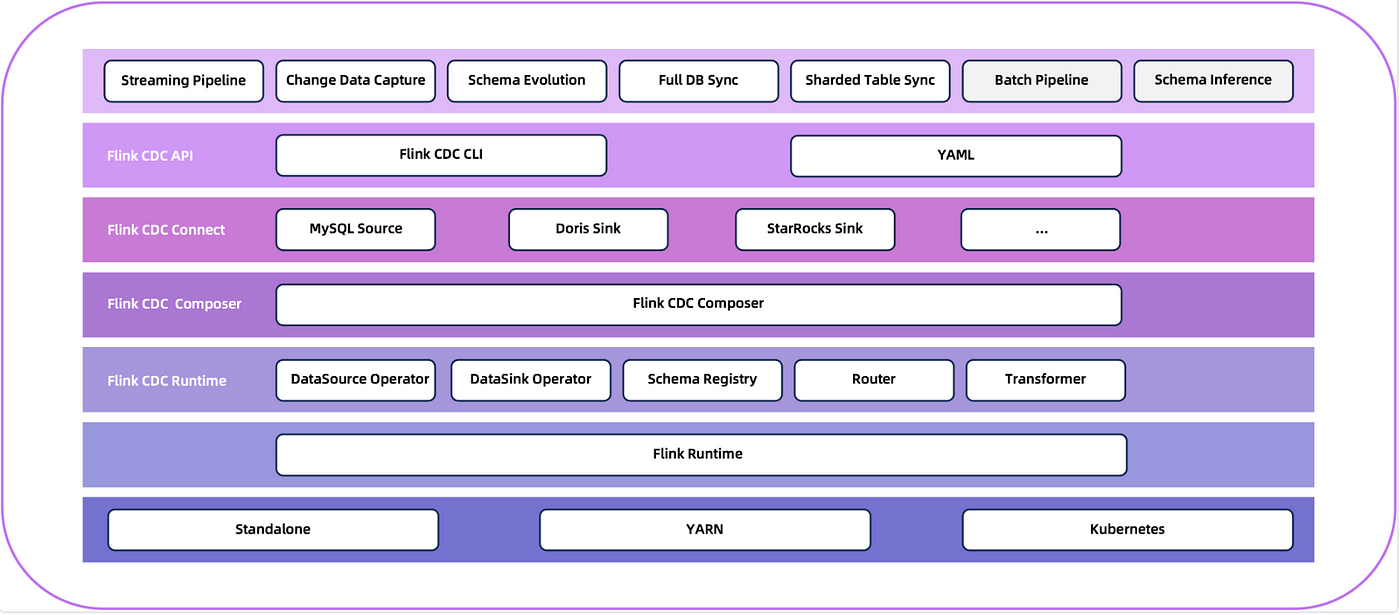
图片来源-A Glimpse into Flink CDC 3.0
3.0 之后 cdc 整体的架构就很清晰了,架构中几个比较重要的概念如下:
CDC Client: 新的用于提交任务的客户端封装
Data Pipeline: 整个 flink cdc 数据流称为 pipeline,内部包括必须配置的 Data Source 和 Data Sink,以及可选的 router
Pipeline Connector: 支持 schema evolution 的数据源,目前有 mysql ( debezium ) 、 paimon ( paimon flink conector ) 、 kafka ( kafka flink connector ) 、doris ( doris flink connector ) 、 starrocks ( starrocks flink connector ) 和 elasticsearch ( elasticsearch flink connector )
Source Connector: 包括 pipeline connector 以及其他暂不支持 pipeline 的其他数据源,如 pgsql (debezium) 和 tidb ( tikv client java ) 等,可直接引用或通过 flink sql 使用
Data Source: 数据读取端封装
Data Sink: 数据写入端封装
Table ID: 标识同步数据源时需要指定的表标识,如 mysql 就是表名,kafka 就是 topic
Transform: 通过 SQL 或者 UDF 注入字段转换的特殊逻辑
Route: 路由,支持设置不同表名映射、多表对单表映射等
环境准备
需要部署的 mysql, doris 和 flink 都可以单点模式运行,因此接下来的所有部署操作都在一个 centos8 容器内执行
# 3306: mysql
# 9030: doris fe
# 8081: flink web
docker run -it -p 3306:3306 -p 9030:9030 -p 8081:8081 -d --name test_flink centos8
flink local singleton
flink 选择 1.18 版本, 本地启动 jobmanager 和 taskmanager
# 下载安装包
wget https://dlcdn.apache.org/flink/flink-1.18.1/flink-1.18.1-bin-scala_2.12.tgz
tar -xvf flink-1.18.1-bin-scala_2.12.tgz
# 设置默认配置
# web ui port
rest.port: 24001
# web ui bind address
rest.bind-address: 0.0.0.0
## 其他和内存相关的配置,在生产环境需要考虑扩容的: taskmanager.memory.process.size、jobmanager.memory.process.size 等
# 启动 jobmanager 和 taskmanager
bash /opt/modules/flink/bin/jobmanager.sh start
bash /opt/modules/flink/bin/taskmanager.sh start
# 运行 wordcount example
/opt/modules/flink/bin/flink run /opt/modules/flink/examples/batch/WordCount.jar
flink cdc 3.0
3.0 之后的 flink cdc 可以直接通过它自己封装的 Client 提交任务了,因此除了和 2.4 同样的要下载数据源对应的 jar 包外,还需用到官方提供的客户端
# 从 release 中下载并安装 flink cdc
wget https://dlcdn.apache.org/flink/flink-cdc-3.1.1/flink-cdc-3.1.1-bin.tar.gz
tar -xzvf flink-cdc-3.1.1-bin.tar.gz
mv flink-cdc-3.1.1 flink-cdc
# 注意: lib 下面只有 cdc 本身的依赖,数据库相关的依赖包需要自行下载
# 运行创建 flink jdbc connector 的任务需要以下依赖
wget https://repo1.maven.org/maven2/mysql/mysql-connector-java/8.0.30/mysql-connector-java-8.0.30.jar -O lib/mysql-connector-java-8.0.30.jar
wget https://repo1.maven.org/maven2/org/apache/flink/flink-connector-jdbc/3.1.2-1.18/flink-connector-jdbc-3.1.2-1.18.jar -O lib/flink-connector-jdbc-3.1.2-1.18.jar
# 运行从 mysql 同步到 doris 的 CDC 任务还需要以下依赖
wget https://repo.maven.apache.org/maven2/org/apache/flink/flink-cdc-pipeline-connector-mysql/3.1.1/flink-cdc-pipeline-connector-mysql-3.1.1.jar -O lib/flink-cdc-pipeline-connector-mysql-3.1.1.jar
wget https://repo.maven.apache.org/maven2/org/apache/flink/flink-cdc-pipeline-connector-doris/3.1.1/flink-cdc-pipeline-connector-doris-3.1.1.jar -O lib/flink-cdc-pipeline-connector-doris-3.1.1.jar
- 注意: flink cdc 的版本要和 connector 的版本对应,否则可能会在提交任务时报 Cannot find factory with identifier "mysql" in the classpath
mysql
这里我们部署 8.0.39 版本,作为数据源
注: 一开始部署 8.4.3 最新版本 mysql ,发现读取 binlog 信息的 SHOW MASTER STATUS 竟然执行不了,替换成了 SHOW BINARY LOG STATUS ,而 flink cdc 还没有做适配,因此只能把 mysql 回退重装了。看来什么都用社区最新版还是有一些踩坑的风险的😂
# 从官网下载安装包,注意下载适配系统架构的版本
# https://dev.mysql.com/downloads/mysql
# 注意: 系统若已有 mariadb 相关的安装包,安装会报冲突,需要先卸载 mariadb 相关包
# 下载 arm 的 mysql 官方安装包
wget https://dev.mysql.com/get/Downloads/MySQL-8.4/mysql-community-common-8.0.39-1.el8.aarch64.rpm
wget https://dev.mysql.com/get/Downloads/MySQL-8.0/mysql-community-client-plugins-8.0.39-1.el8.aarch64.rpm
wget https://dev.mysql.com/get/Downloads/MySQL-8.0/mysql-community-libs-8.0.39-1.el8.aarch64.rpm
wget https://dev.mysql.com/get/Downloads/MySQL-8.0/mysql-community-client-8.0.39-1.el8.aarch64.rpm
wget https://dev.mysql.com/get/Downloads/MySQL-8.0/mysql-community-icu-data-files-8.0.39-1.el8.aarch64.rpm
wget https://dev.mysql.com/get/Downloads/MySQL-8.0/mysql-community-server-8.0.39-1.el8.aarch64.rpm
# x86
wget https://dev.mysql.com/get/Downloads/MySQL-8.4/mysql-community-common-8.0.39-1.el8.x86_64.rpm
wget https://dev.mysql.com/get/Downloads/MySQL-8.4/mysql-community-client-plugins-8.0.39-1.el8.x86_64.rpm
wget https://dev.mysql.com/get/Downloads/MySQL-8.4/mysql-community-libs-8.0.39-1.el8.x86_64.rpm
wget https://dev.mysql.com/get/Downloads/MySQL-8.4/mysql-community-client-8.0.39-1.el8.x86_64.rpm
wget https://dev.mysql.com/get/Downloads/MySQL-8.4/mysql-community-icu-data-files-8.0.39-1.el8.x86_64.rpm
wget https://dev.mysql.com/get/Downloads/MySQL-8.4/mysql-community-server-8.0.39-1.el8.x86_64.rpm
# 安装
rpm -ivh mysql-community-common-8.0.39-1.el8.aarch64.rpm
rpm -ivh mysql-community-client-plugins-8.0.39-1.el8.aarch64.rpm
rpm -ivh mysql-community-libs-8.0.39-1.el8.aarch64.rpm
rpm -ivh mysql-community-client-8.0.39-1.el8.aarch64.rpm
rpm -ivh mysql-community-icu-data-files-8.0.39-1.el8.aarch64.rpm
rpm -ivh mysql-community-server-8.0.39-1.el8.aarch64.rpm
# 初始化、首次启动 mysql
mysqld --initialize
mysqld --user=root
# 从 /var/log/mysqld.log 中获得 mysql 初始密码
cat /var/log/mysqld.log | grep "A temporary password"
# 从另一个窗口登录 mysql
mysql -h127.0.0.1 -P3306 -uroot -p{mysql初始密码}
# 修改 root 密码
SET PASSWORD = '{mysql密码}';
doris
doris 是一个具备高性能实时计算和查询性能的OLAP数据库,经常用于从业务数据库实时同步数据后,进行海量数据分析、高并发即席查询、日志分析、用户画像分析等。在企业内最常用的场景是制作各种业务报表,提供给数据分析师和管理者。相关技术主要有存储模型、物化视图、向量化引擎、CBO优化等
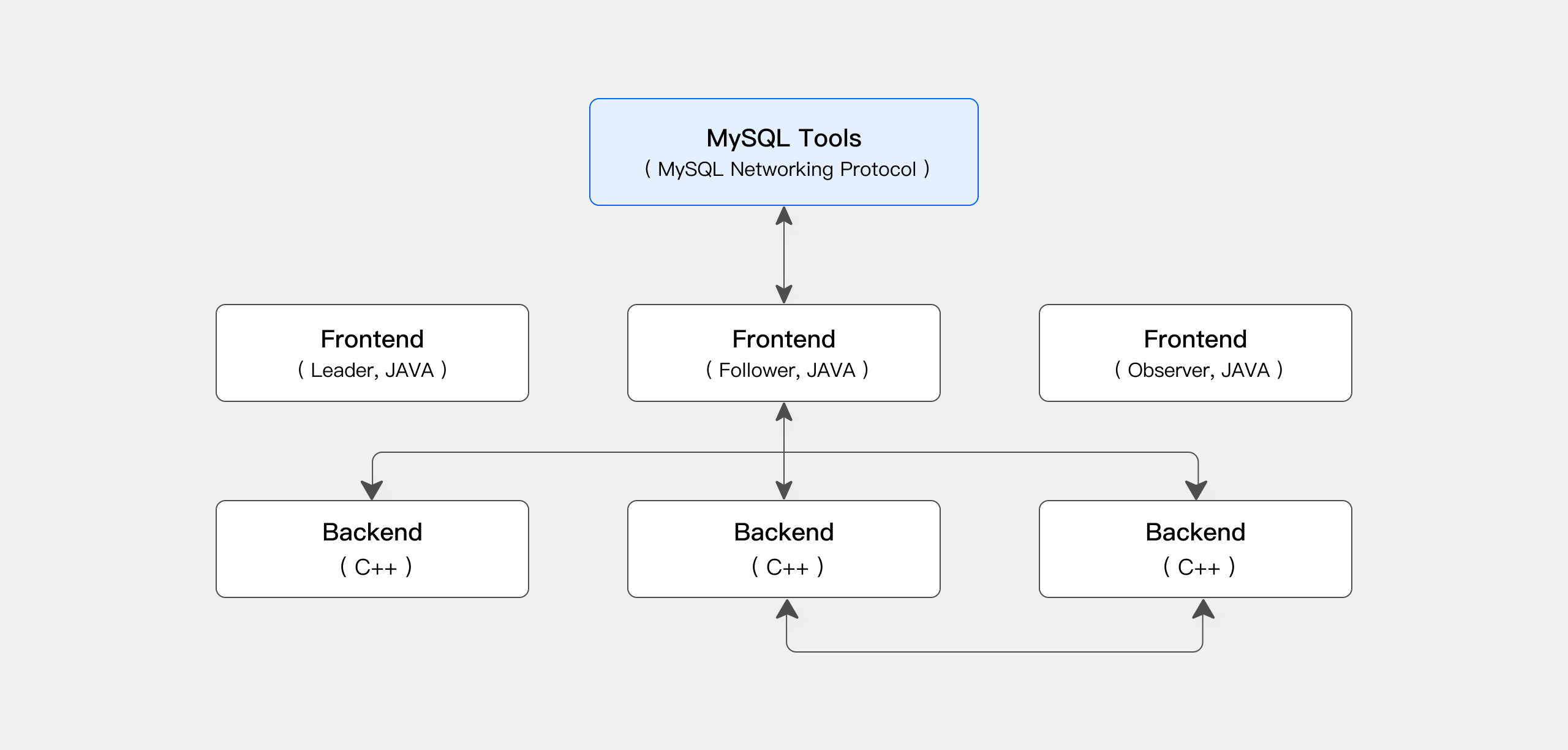
doris 的基本组件为 fe 和 be,fe 负责管理集群,接收和处理用户请求,分析并得到SQL执行计划,be 负责数据存储和SQL的具体计算逻辑执行
# doris 3.0 版本需要用 jdk 17
# adoptium 版本的开源 openjdk 可以从这里下载
# https://github.com/adoptium/temurin17-binaries/releases
wget https://github.com/adoptium/temurin17-binaries/releases/download/jdk-17.0.9%2B9/OpenJDK17U-jdk_aarch64_linux_hotspot_17.0.9_9.tar.gz
# 设置环境变量
export JAVA_HOME=/opt/modules/java/jdk-17.0.9+9
# 下载 doris
wget https://apache-doris-releases.oss-accelerate.aliyuncs.com/apache-doris-3.0.2-bin-arm64.tar.gz
# 修改配置
# fe: http_port: frontend 界面地址,默认 9030
# fe: meta_dir: frontend 元数据存储路径
vim /opt/modules/doris/fe/conf/fe.conf
meta_dir = /opt/modules/doris/fe/meta
# be: storage_root_path: 存储路径
vim /opt/modules/doris/be/conf/be.conf
storage_root_path = /opt/modules/doris/be/data
# 启动 fe
mkdir -p /opt/modules/doris/fe/meta
/opt/modules/doris/fe/bin/start_fe.sh --daemon
# 查看启动日志
tail -f /opt/modules/doris/fe/log/fe.log
# 启动 be
mkdir -p /opt/modules/doris/be/data
/opt/modules/doris/be/bin/start_be.sh --daemon
# 查看启动日志
tail -f /opt/modules/doris/be/log/be.INFO
# 启动后,首次登录 fe 不需要密码,设置 root 密码并添加 be
mysql -h127.0.0.1 -P9030 -uroot
SET PASSWORD FOR 'root' = PASSWORD('{Doris密码}');
ALTER SYSTEM ADD BACKEND "localhost:9050";
注: 容器内启动可能会遇到报错 Please set vm.max_map_count to be 2000000 under root using 'sysctl -w vm.max_map_count=2000000' ,为了测试可以先注释掉这段判断逻辑,在 /opt/modules/doris/be/bin/start_be.sh 中
任务配置与运行
前面的环境安装都是为了这里的任务运行做铺垫
mysql 模拟表
在 mysql 创建一张“业务”表
-- 专辑
CREATE TABLE `d_music`.`album` (
`id` varchar(255) NOT NULL,
`create_time` datetime DEFAULT CURRENT_TIMESTAMP,
`name` varchar(255) NOT NULL DEFAULT '',
`album_artist` varchar(255) NOT NULL DEFAULT '',
`year` int NOT NULL DEFAULT '0',
`song_count` int NOT NULL DEFAULT '0'
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
通过 dagagen 实时向 mysql 写入数据
flink connector 数据源有各种连接器,其中 datagen 是可以随机生成数据的 connector
针对刚才 mysql 创建的测试表,我们创建一个定时写入数据的任务:
-- /opt/modules/flink/album.sql
CREATE TEMPORARY TABLE album_datagen (
id STRING,
name STRING,
album_artist STRING,
`year` INT,
song_count INT
) WITH (
'connector' = 'datagen',
'rows-per-second' = '3'
);
CREATE TABLE album_mysql (
id STRING,
name STRING,
album_artist STRING,
`year` INT,
song_count INT,
PRIMARY KEY (id) NOT ENFORCED
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://localhost:3306/d_music',
'username' = 'root',
'password' = '{mysql密码}',
'table-name' = 'album'
);
insert into `album_mysql` select * from album_datagen;
注: 这里 flink sql 的表没有设置 create_time 字段,为了让其能使用 mysql 表的默认值
注: rows-per-second 配置为datagen每秒产生的数据量,默认为1w
提交 flink sql:
/opt/modules/flink/bin/sql-client.sh -f /opt/modules/flink/album.sql
提交后可以在 flink 界面看到 datagen 任务正常运行,并在 mysql 中查询到每秒写入的随机数据
mysql -hlocalhost -P3306 -uroot -p'{mysql密码}' -e "select * from d_music.artist order by create_time desc limit 10"
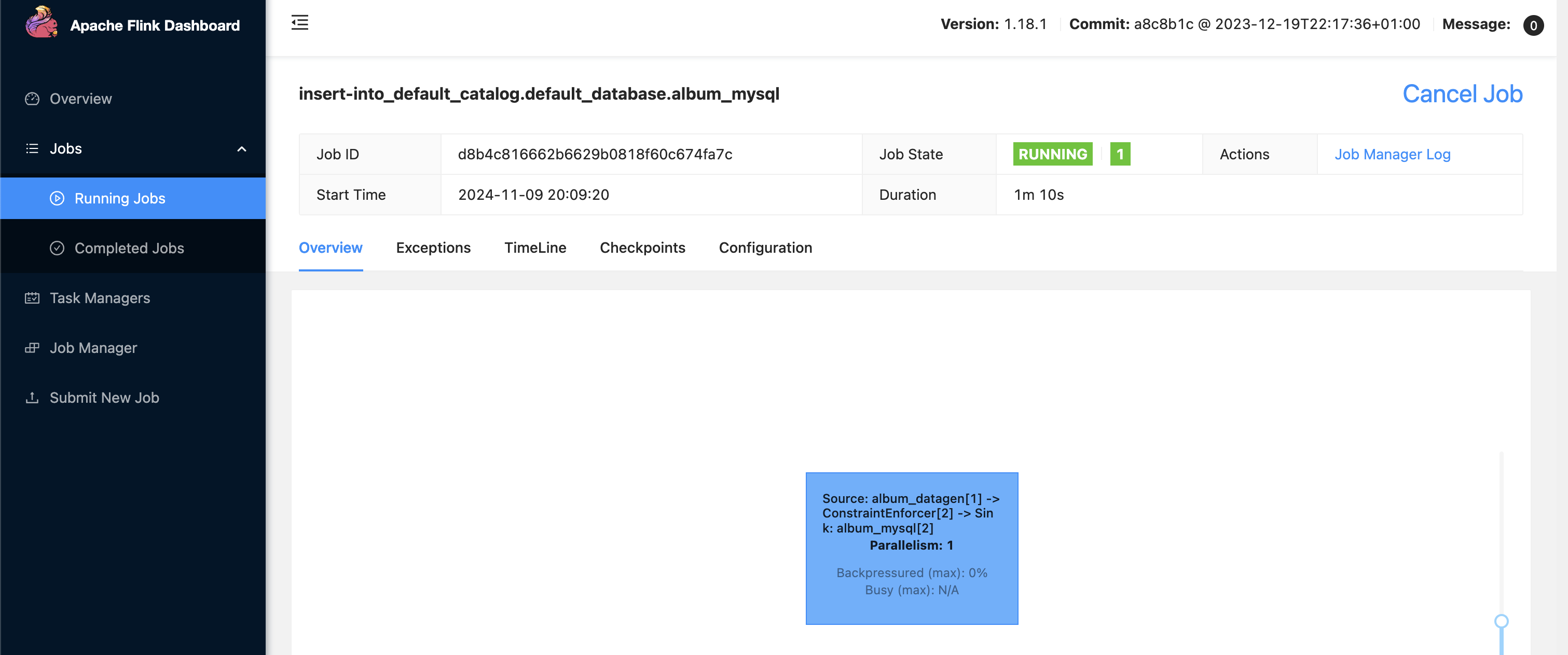
flink cdc 任务配置与提交
按照官方教程,修改 mysql 地址和 doris 地址、需要同步的库表即可
# /opt/modules/flink-cdc/album.yaml
source:
type: mysql
hostname: localhost
port: 3306
username: root
password: {mysql密码}
tables: d_music.album
scan.incremental.snapshot.chunk.size: 1000
scan.snapshot.fetch.size: 1000
scan.startup.mode: initial
server-time-zone: UTC+8
sink:
type: doris
fenodes: localhost:8030
username: root
password: {doris密码}
table.create.properties.light_schema_change: true
table.create.properties.replication_num: 1
pipeline:
name: sr_cdc_sink_doris_example
parallelism: 1
注: 若任务运行的本地时区和 mysql 服务器时区不一致,server-time-zone 需要指定为本地时区
注: fenodes 对应 doris fe 的 http_port
注: scan.startup.mode: 类似 canal 的同步模式配置,initial 表示从头同步所有数据,还支持从指定时间戳同步
然后我们提交这个任务, 正常等待个几秒,在 doris 就能查到从 mysql 同步过来的数据了
# 注意需要显式声明 FLINK_HOME 即 flink 安装路径,在 flink-cdc.sh 脚本中用到
export FLINK_HOME=/opt/modules/flink
/opt/modules/flink-cdc/bin/flink-cdc.sh /opt/modules/flink-cdc/album.yaml
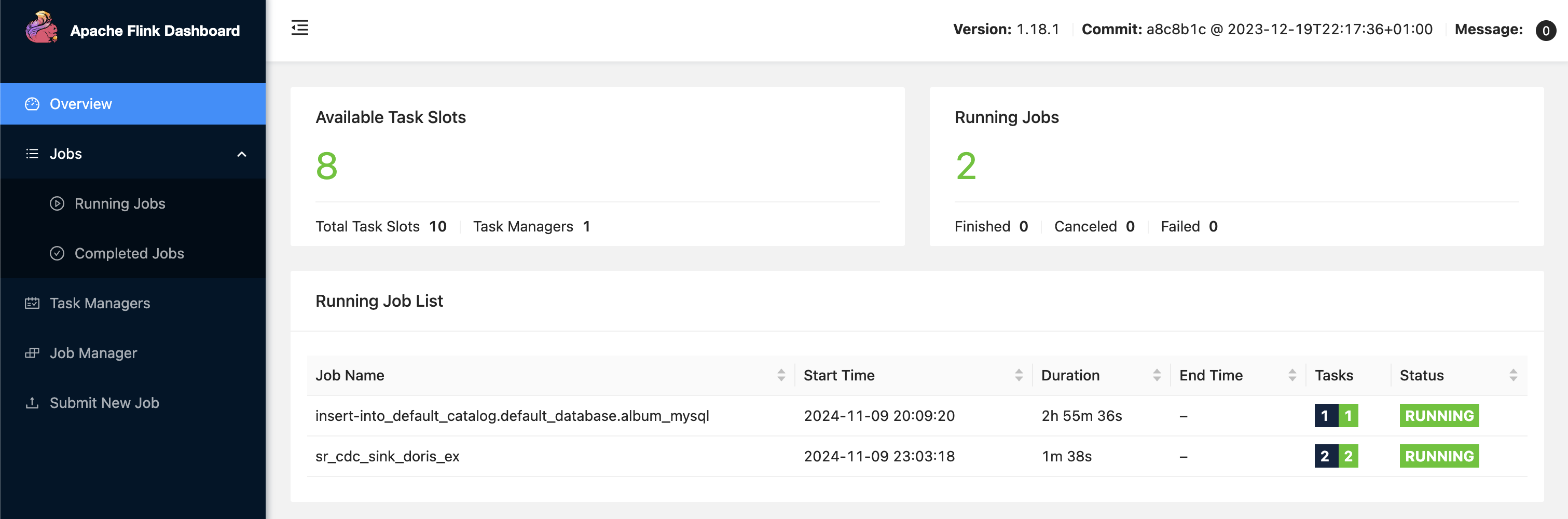
-- 查询 doris 最近写入的数据
mysql -h127.0.0.1 -P9030 -uroot -p{Doris密码} -e "select * from d_music.album order by create_time desc limit 10"
我们还能发现,Doris 这边是不需要提前建表的,flink cdc 已经帮我们建好了一张主键表,其中副本数之类的基本配置根据cdc 任务中的 table.create.properties.replication_num 来设置
show create table d_music.album;
CREATE TABLE `album` (
`id` varchar(765) NULL,
`create_time` datetime NULL,
`name` varchar(765) NULL,
`album_artist` varchar(765) NULL,
`year` int NULL,
`song_count` int NULL
) ENGINE=OLAP
UNIQUE KEY(`id`)
DISTRIBUTED BY HASH(`id`) BUCKETS AUTO
PROPERTIES (
"replication_allocation" = "tag.location.default: 1",
"min_load_replica_num" = "-1",
"is_being_synced" = "false",
"storage_medium" = "hdd",
"storage_format" = "V2",
"inverted_index_storage_format" = "V2",
"enable_unique_key_merge_on_write" = "true",
"light_schema_change" = "true",
"disable_auto_compaction" = "false",
"enable_single_replica_compaction" = "false",
"group_commit_interval_ms" = "10000",
"group_commit_data_bytes" = "134217728",
"enable_mow_light_delete" = "false"
);
当然,除了主键模型,doris 还支持聚合模型(Aggregate)和明细模型(Duplicate)表,参考 data models。但是 flink cdc 对于同步源表中主键的表,会默认创建主键模型表。因此有创建其他模型表的话就需要提前建了
关于 flink cdc 实现提前建表和 schema evolution 的实现可以参考对各个数据源的 MetadataApplier 实现,如 DorisMetadataApplier
schema evolution
铺垫了这么久,终于来到了测试表结构变更同步的环节
# 添加字段
mysql -hlocalhost -P3306 -uroot -p'{mysql密码}' -e "ALTER TABLE d_music.album ADD COLUMN duration DOUBLE AFTER song_count"
# 修改后确认 doris 表结构是否更新
mysql -h127.0.0.1 -P9030 -uroot -p{doris密码} -e "show create table d_music.album"
# 修改 mysql 字段名称
mysql -hlocalhost -P3306 -uroot -p'{mysql密码}' -e "ALTER TABLE d_music.album RENAME COLUMN duration TO duration_total"
# 删除 mysql 字段
mysql -hlocalhost -P3306 -uroot -p'{mysql密码}' -e "ALTER TABLE d_music.album DROP COLUMN duration_total"
从 flink taskmanager 日志中我们可以看到表结构变更时,会触发 SchemaChangeEvent 事件,后续的其他数据写入或变更操作都必须等待当前的 schema change 完成后才会继续进行,以保证数据一致性
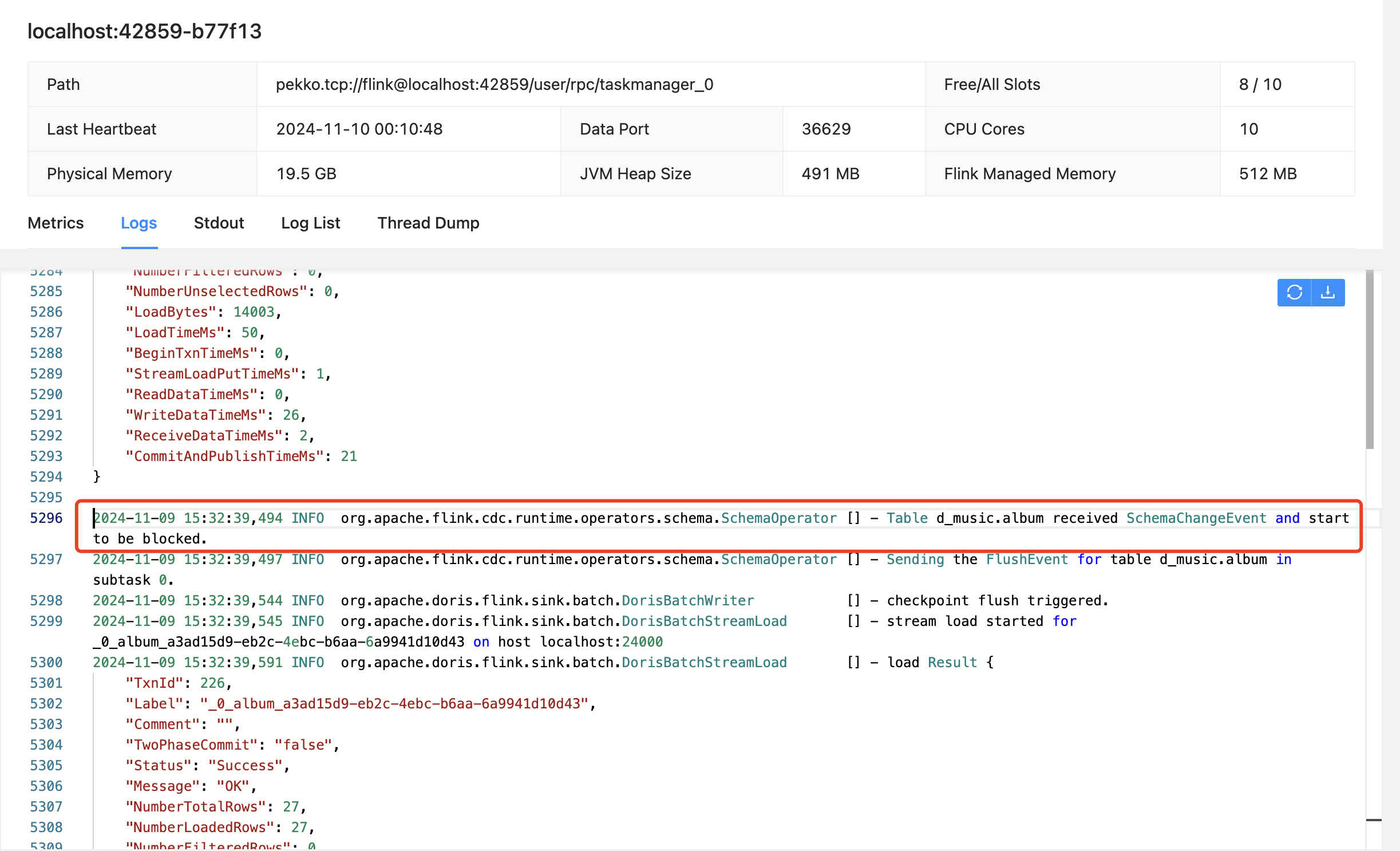
注: 表字段类型变更的同步在 3.2.0 版本之后才支持,本文所用的 3.1 不支持
注: 不同数据源对字段变更的适配完善程度有所不同,如 Doris 在 cdc 最新版支持字段类型变更,但 Starrocks 还不支持
整库同步
我们在 mysql 中再创建两张表
create table if not exists d_music.artist
(
`id` varchar(255) NOT NULL,
`create_time` datetime DEFAULT CURRENT_TIMESTAMP,
`name` varchar(255) NOT NULL DEFAULT '',
`album_count` int NOT NULL DEFAULT '0',
PRIMARY KEY (`id`)
)ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
create table d_music.playlist
(
`id` varchar(255) NOT NULL,
`create_time` datetime DEFAULT CURRENT_TIMESTAMP,
`name` varchar(255) NOT NULL DEFAULT '',
`comment` varchar(255) NOT NULL DEFAULT '',
`song_count` int NOT NULL DEFAULT '0',
PRIMARY KEY (`id`)
)ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
对应的,我们在 flink 也再提交这两张新表的 datagen
CREATE TEMPORARY TABLE artist_datagen (
id STRING,
name STRING,
album_count INT
) WITH (
'connector' = 'datagen',
'rows-per-second' = '3'
);
CREATE TEMPORARY TABLE playlist_datagen (
id STRING,
name STRING,
`comment` STRING,
song_count INT
) WITH (
'connector' = 'datagen',
'rows-per-second' = '3'
);
CREATE TABLE artist_mysql (
id STRING,
name STRING,
album_count INT,
PRIMARY KEY (id) NOT ENFORCED
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://localhost:3306/d_music',
'username' = 'root',
'password' = '{mysql密码}',
'table-name' = 'artist'
);
CREATE TABLE playlist_mysql (
id STRING,
name STRING,
`comment` STRING,
song_count INT,
PRIMARY KEY (id) NOT ENFORCED
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://localhost:3306/d_music',
'username' = 'root',
'password' = '{mysql密码}',
'table-name' = 'playlist'
);
insert into `artist_mysql` select * from artist_datagen;
insert into `playlist_mysql` select * from playlist_datagen;
最后我们再提交同步这三张表 flink cdc ,相比刚才同步一张表的配置只需要修改 tables,按照正则表达式配置即可。从 MySqlDataSourceFactory 可以找到对 tables 配置的解析逻辑
# /opt/modules/flink-cdc/album.yaml
tables: d_music.\.*
提交所有任务后,flink 上将会有四个任务,三个 datagen 对应三张表,而 flink cdc 对应的所有表都在一个任务中同步
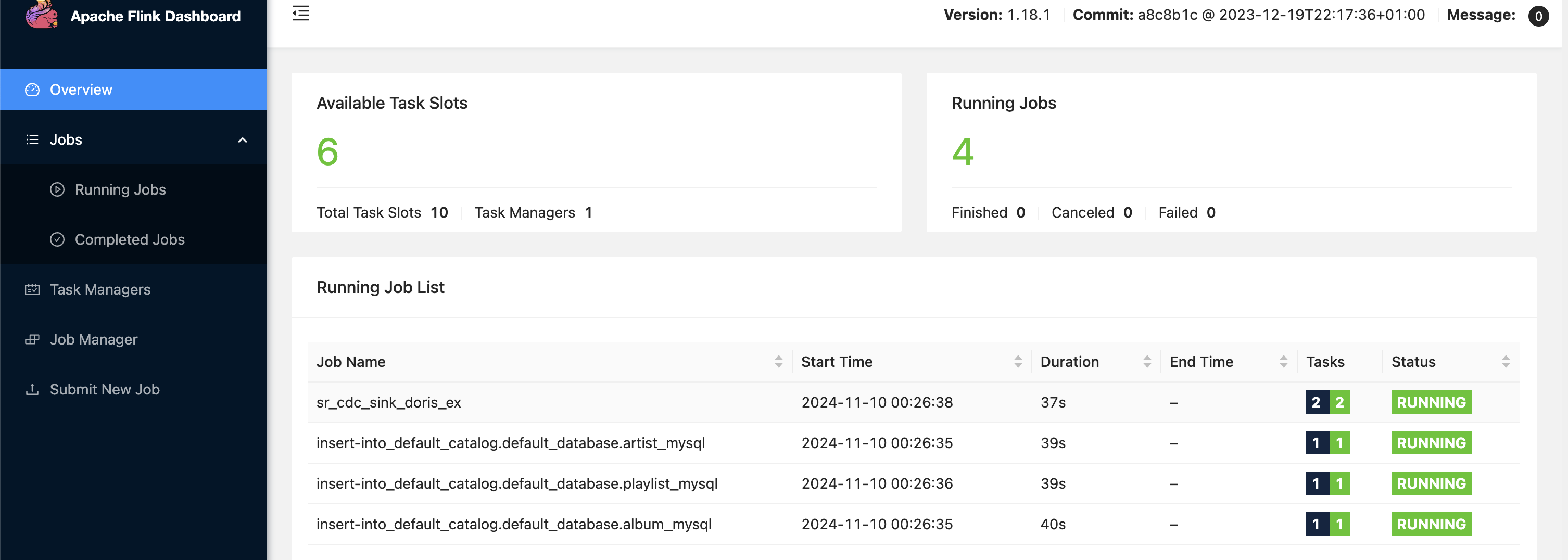
另外,我们还可以注意 mysql 的连接数: 和 2.4 版本对比,这次一整个任务只需要一个连接,其读取 binlog 会自动解析给对应表的同步,而不需要每张表都创建一个连接
-- 查看 mysql 读取 binlog 相关的连接数
mysql -hlocalhost -P3306 -uroot -p'{mysql密码}' -e "show processlist" | grep "Binlog Dump"
但注意: 有哪些表需要同步,是任务在创建的时候就解析的,后续源库再添加表,不会让现有的任务把这个新表也加入同步
总结
3.0 之后的 cdc 在功能上更加成熟,不仅是架构更清楚,通过 yaml 配置 cdc 任务的方式也更简化,和 flink 本身更统一了
不过从整个过程也能看到,在生产环境面对大量业务表需要同步的时候,先不说任务怎么做好监控,本身任务要做到高可用就必须把 checkpoint 打开,另外,不是所有 mysql 的表结构变更都能成功同步到下游,面对无法同步的特殊情况,还需要手动设置指定同步时间点恢复任务,一些繁琐的维护过程还是无法避免
后续有机会再探索一下这些优化的思路吧

 浙公网安备 33010602011771号
浙公网安备 33010602011771号