improve deep learning network 课程笔记
公开课笔记
Bias & variance

bias: 1. more epoch 2. deeper network 3.hyperparameters
variance : larger dataset 2. regularization
regularization
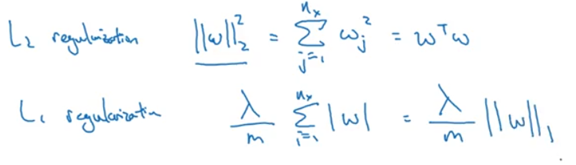
L2 norm: weight decay

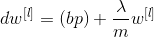
dropout regularization
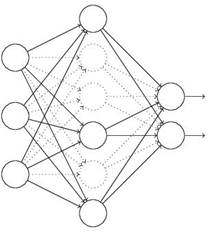
dropout:在反向传播误差更新权值时候,随机删除一部分hidden units,以防止过拟合。
other methods for variance:
data augmentation:图像有 翻转、裁剪、扭曲、旋转等操作
early stopping:
在validation error开始上升时,停止训练

当神经网络还未运行太多迭代过程的时候,w参数接近于0。开始迭代过程,w的值会变得越来越大。early stopping要做的就是在中间点停止迭代过程。这样我们将会得到一个中等大小的w参数,这个结果与得到与L2正则化的结果相似,最终得到w参数较小的神经网络。
梯度消失和梯度爆炸vanishing & exploding
神经网络过深时易产生的现象.
解决方法:1.高斯分布权重初始化 2. relu 3.clip gradient(解决梯度爆炸)

4. shortcut

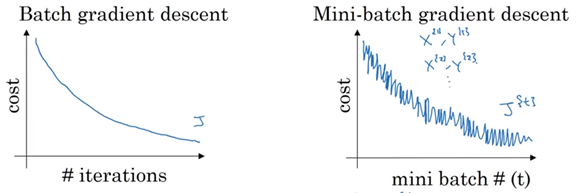
Mini batches
Exponentially weighted average


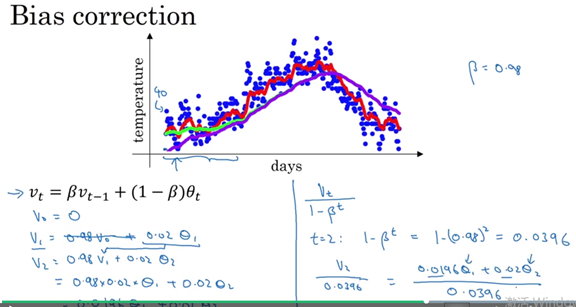
Bias correction
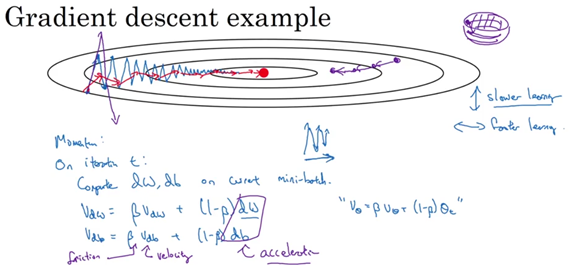
Monumentum


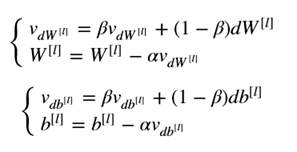
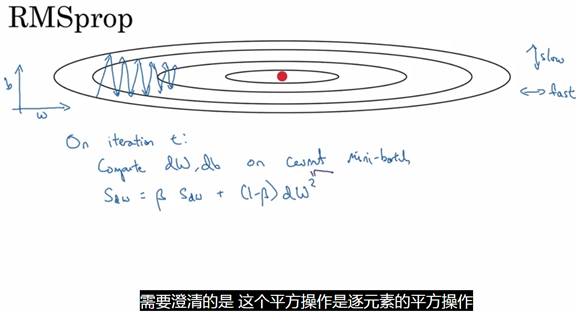
RMSprop

Adam OPTIMIZER
Momentum + RMSprop


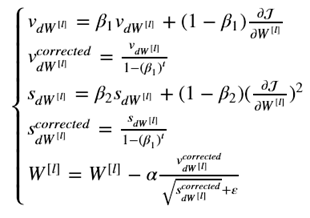
Learning rate decay


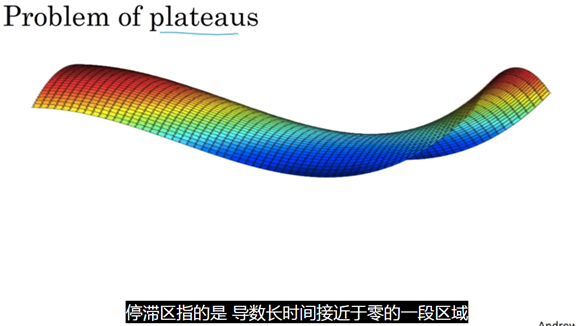
解决方法:Adam optimizer等
Batch normalize

关于batch normalization 论文解读:https://www.cnblogs.com/guoyaohua/p/8724433.html
IID独立同分布假设,就是假设训练数据和测试数据是满足相同分布的,这是通过训练数据获得的模型能够在测试集获得好的效果的一个基本保障。那BatchNorm的作用是什么呢?BatchNorm就是在深度神经网络训练过程中使得每一层神经网络的输入保持相同分布的。
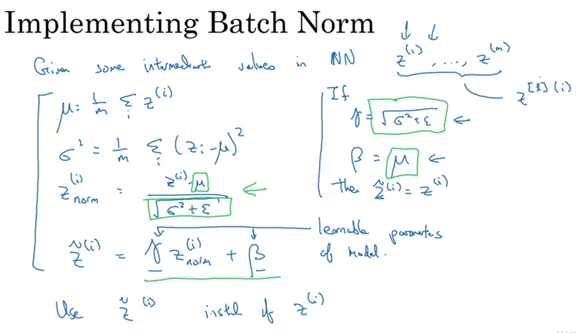

Scale and shift:
经过变换后网络表达能力下降,为了防止这一点,每个神经元增加两个调节参数(scale和shift),这两个参数通过训练来学习,用于对变换后的激活反变换,使得网络表达能力增强。
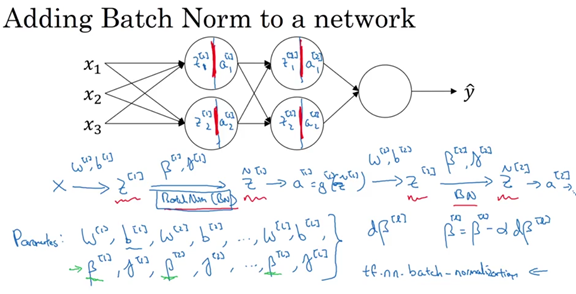

在我们训练的过程中,对于训练集的Mini-batch,使用指数加权平均,当训练结束的时候,得到指数加权平均后的均值和方差,而这些值直接用于Batch Norm公式的计算,用以对测试样本进行预测。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号