卫生健康委员会新型冠状病毒文本爬取文本分析(含源码)
政府公文有一定的格式,观察一阵不难发现规律,例如:
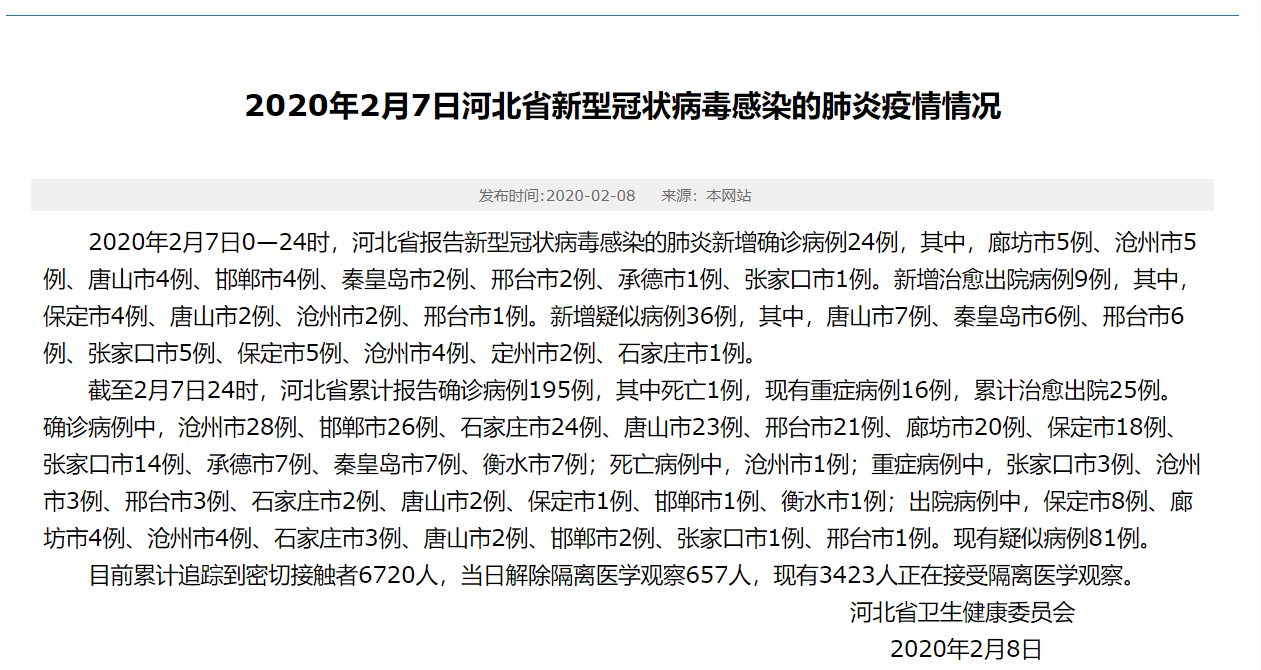
第一段是新增
第二段是确诊
第三段是密切接触者
下面是代码:
1 from lxml import etree 2 import re 3 import requests #导入requests包 4 5 import 肺炎.SQL as SQL 6 #url = 'http://www.hebwst.gov.cn/index.do?id=397505&templet=content&cid=45' 7 #url ='http://www.hebwst.gov.cn/index.do?id=397291&templet=content&cid=45' 8 #url='http://www.hebwst.gov.cn/index.do?id=395538&templet=content&cid=326' 9 10 11 hrefs = [] 12 def ULS(): 13 urls = [] 14 15 for i in range(6): 16 17 url='http://www.hebwst.gov.cn/index.do?templet=search_list&searchType=1&searchText=河北省新型冠状病毒感染的肺炎疫情情况&type=search&cid=0&page='+str(i) 18 print(url) 19 strhtml = requests.get(url) 20 tree = etree.HTML(strhtml.text) 21 urls.append(tree.xpath('//td[@class=\'sy_new_list\']/a//@href')) 22 print(urls) 23 for href1 in urls: 24 for href in href1: 25 print(href) 26 href = 'http://www.hebwst.gov.cn/'+ href 27 a = re.match(r'.*?&cid=45', href) 28 if (a): 29 if (href !='http://www.hebwst.gov.cn/index.do?id=395795&templet=content&cid=45'): 30 hrefs.append(href) 31 print(hrefs) 32 33 34 def info(url): 35 print(url) 36 strhtml = requests.get(url) # Get方式获取网页数据 37 tree = etree.HTML(strhtml.text) 38 text=tree.xpath('//p//text()') 39 text[0]=re.sub(r'\u3000','',text[0]) 40 #print(text) 41 42 #新增 43 date=re.findall(r"(.+?日)", text[0]) 44 print("时间",date) 45 xin_que_num=re.findall(r"新增确诊病例(.+?例)", text[0]) 46 mid = text[0].split("其中", 1)[1] 47 num=len(mid.split("其中", 1)) 48 if num>1: 49 mid=mid.split("其中", 1)[0] 50 51 xin_shi_num=re.findall(r"[,,、](.+?市)(.+?例)", mid) 52 53 xin_chu_num = re.findall(r"新增治愈出院病例(.+?例)", text[0]) 54 xin_yi_num = re.findall(r"新增疑似病例(.+?例)", text[0]) 55 print("新增确诊病例",xin_que_num) 56 print("详细新增确诊病例\n",xin_shi_num) 57 58 print("新增治愈出院病例",xin_chu_num) 59 print("新增疑似病例\n",xin_yi_num) 60 61 62 63 #确诊 64 65 66 67 que_num=re.findall(r"累计报告确诊病例(.+?例)", text[1]) 68 69 si_num=re.findall(r"例,其中死亡(.+?例)", text[1]) 70 71 zhong_num=re.findall(r",现有重症病例(.+?例)", text[1]) 72 73 yu_num=re.findall(r",累计治愈出院(.+?例)", text[1]) 74 75 print("累计确诊病例",que_num) 76 print("死亡病例",si_num) 77 print("重症病例",zhong_num) 78 print("出院病例",yu_num) 79 80 #详细 81 82 que_xi_num=[] 83 si_xi_num=[] 84 zhong_xi_num=[] 85 chu_xi_num=[] 86 87 num=len(text[1].split("确诊病例中",1)) 88 if num>1: 89 mid = text[1].split("确诊病例中", 1)[1] 90 num = len(mid.split("死亡病例中",1)) 91 if num > 1: 92 que=mid.split("死亡病例中",1)[0] 93 94 que_xi_num = re.findall(r"[,、](.+?市)(.+?例)", que) 95 si=mid.split("死亡病例中",1)[1] 96 mid=si 97 num = len(mid.split("重症病例中", 1)) 98 if num > 1: 99 si=mid.split("重症病例中",1)[0] 100 101 si_xi_num = re.findall(r"[,、](.+?市)(.+?例)", si) 102 zhong=mid.split("重症病例中",1)[1] 103 mid=zhong 104 num = len(mid.split("出院病例中", 1)) 105 if num > 1: 106 zhong=mid.split("出院病例中",1)[0] 107 zhong_xi_num = re.findall(r"[,、](.+?市)(.+?例)", zhong) 108 chu=mid.split("出院病例中",1)[1] 109 chu_xi_num = re.findall(r"[,、](.+?市)(.+?例)", chu) 110 else: 111 zhong_xi_num = re.findall(r"[,、](.+?市)(.+?例)", zhong) 112 else: 113 si_xi_num = re.findall(r"[,、](.+?市)(.+?例)", si) 114 115 116 print("详细确诊病例",que_xi_num) 117 print("详细死亡病例",si_xi_num) 118 print("详细重症病例",zhong_xi_num) 119 print("详细出院病例",chu_xi_num) 120 121 #疑似 122 123 yisi_num=re.findall(r"疑似病例(.+?例)", text[1]) 124 print("疑似病例",yisi_num) 125 126 #密切接触者 接触医学观察 正在隔离 127 128 miqie_num=re.findall(r"密切接触者(.+?人)", text[2]) 129 jie_num=re.findall(r"解除隔离医学观察(.+?人)", text[2]) 130 guan_num=re.findall(r"现有(.+?人)", text[2]) 131 132 print("密切接触者",miqie_num) 133 print("接触医学观察",jie_num) 134 print("现有医学观察人数",guan_num) 135 136 137 SQL.insert_province(date[0], "".join(xin_que_num),"".join(xin_chu_num), "".join(xin_yi_num), "".join(que_num), "".join(si_num), "".join(zhong_num), "".join(yu_num),"".join(yisi_num), "".join(miqie_num), "".join(jie_num), "".join(guan_num), url) 138 for mid_value in que_xi_num: 139 City=mid_value[0] 140 Num=mid_value[1] 141 print("CITY:",City) 142 print("num:",Num) 143 SQL.insert_city(date[0],City,Num,url) 144 # ,,,,Ur 145 for mid_value in xin_shi_num: 146 City=mid_value[0] 147 Num=mid_value[1] 148 print("CITY:",City) 149 print("num:",Num) 150 SQL.update_db(City,"New_Confirmed_num",Num) 151 152 153 for mid_value in si_xi_num: 154 City=mid_value[0] 155 Num=mid_value[1] 156 print("CITY:",City) 157 print("num:",Num) 158 SQL.update_db(City,"Dead_num",Num) 159 160 for mid_value in zhong_xi_num: 161 City=mid_value[0] 162 Num=mid_value[1] 163 print("CITY:",City) 164 print("num:",Num) 165 SQL.update_db(City,"Zhong_num",Num) 166 167 for mid_value in chu_xi_num: 168 City=mid_value[0] 169 Num=mid_value[1] 170 print("CITY:",City) 171 print("num:",Num) 172 SQL.update_db(City,"Cured_num",Num) 173 174 175 176 if __name__ =='__main__': 177 #ULS() 178 #SQL.delete_db("hebei_info") 179 #SQL.delete_db("hebei_city_info") 180 #for url in hrefs: 181 #info(url) 182 info('http://wsjkw.hebei.gov.cn/content/content_45/397632.jhtml')

 浙公网安备 33010602011771号
浙公网安备 33010602011771号