百度百科简介爬取(含源代码、信息领域词频数据csv格式)
百度百科特征:
https://baike.baidu.com/item/+“信息”
切记不要在要查找的字后面加‘/’
简介代码XPATH:
1 String htmls=page.getHtml().xpath("//div[@class='lemma-summary']/html()").get();
下面是所有的代码:
很简单,可有很快应用到系统中:


1 package Pa; 2 import java.util.ArrayList; 3 import java.util.Date; 4 import java.util.List; 5 6 import org.jsoup.Jsoup; 7 import org.jsoup.nodes.Document; 8 9 import us.codecraft.webmagic.Page; 10 import us.codecraft.webmagic.Site; 11 import us.codecraft.webmagic.Spider; 12 import us.codecraft.webmagic.processor.PageProcessor; 13 14 15 public class 百度百科 implements PageProcessor{ 16 17 public static List<String> titles; 18 19 public static int i=0; 20 public static List<String> words=new ArrayList<String>(); 21 @Override 22 public Site getSite() { 23 return Site.me().setSleepTime(1000).setRetryTimes(10); 24 } 25 26 //jsoup根据html字符串和语法来获取内容 27 private static String selectDocumentText(String htmlText) { 28 Document doc=Jsoup.parse(htmlText); 29 String select=doc.text(); 30 System.out.println(select); 31 return select; 32 } 33 34 35 @Override 36 public void process(Page page) { 37 //定义如何抽取页面信息 38 /*List<String> htmls=page.getHtml().xpath("//div[@class='lemma-summary']/html()").all(); 39 for(String html:htmls) { 40 String mean=selectDocumentText(html); 41 String word=words.get(i); 42 System.out.println(word+":"+mean); 43 } 44 */ 45 46 String htmls=page.getHtml().xpath("//div[@class='lemma-summary']/html()").get(); 47 48 String mean=selectDocumentText(htmls); 49 50 System.out.println(mean); 51 52 53 54 i=i+1; 55 56 } 57 public static void main(String[] args) { 58 long startTime,endTime; 59 startTime=new Date().getTime(); 60 Spider create=Spider.create(new 百度百科()); 61 words.add("信息"); 62 String strr="https://baike.baidu.com/item/技术"; 63 create.addUrl(strr).thread(5).run(); 64 endTime=new Date().getTime(); 65 System.out.println("用时为:"+(endTime-startTime)/1000+"s"); 66 67 } 68 }
数据下载:
样例:
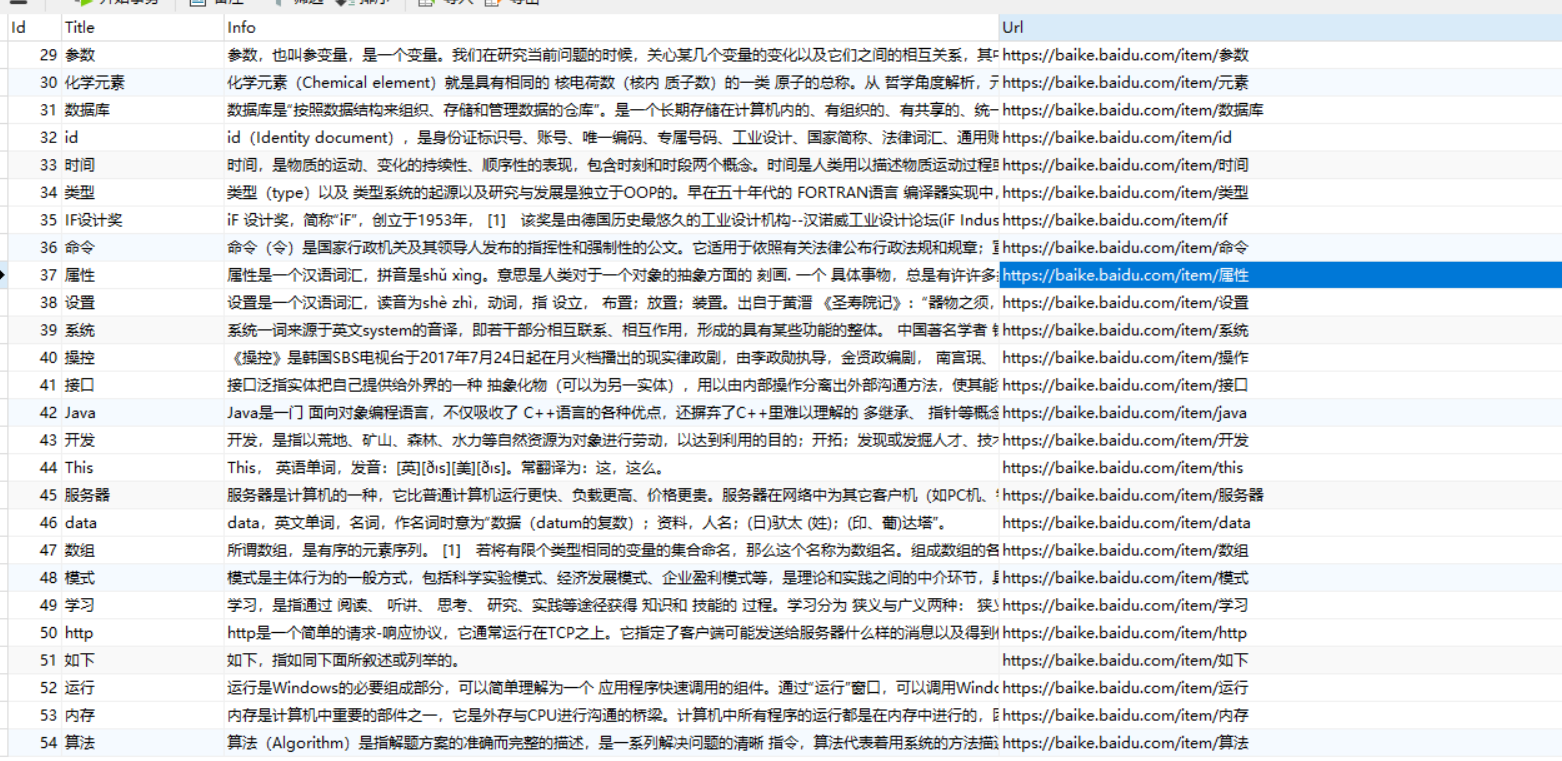
下载地址:
链接:https://pan.baidu.com/s/1K5vR8_wNBmAYNvhMCwoAqg
提取码:yse9
复制这段内容后打开百度网盘手机App,操作更方便哦

 浙公网安备 33010602011771号
浙公网安备 33010602011771号