深入学习go语言(零):前置知识-编译过程
编译原理-从源码到机器码
任何一门高级语言,要想最终能够在机器上执行那么就一定要从源码生成机器码,因为对于机器来说,它只认同由0和1组成的二进制程序。
从人类可读的源码到机器可识别的机器码的过程就是使用编译器完成的,而编译器就与我们的编译原理息息相关。
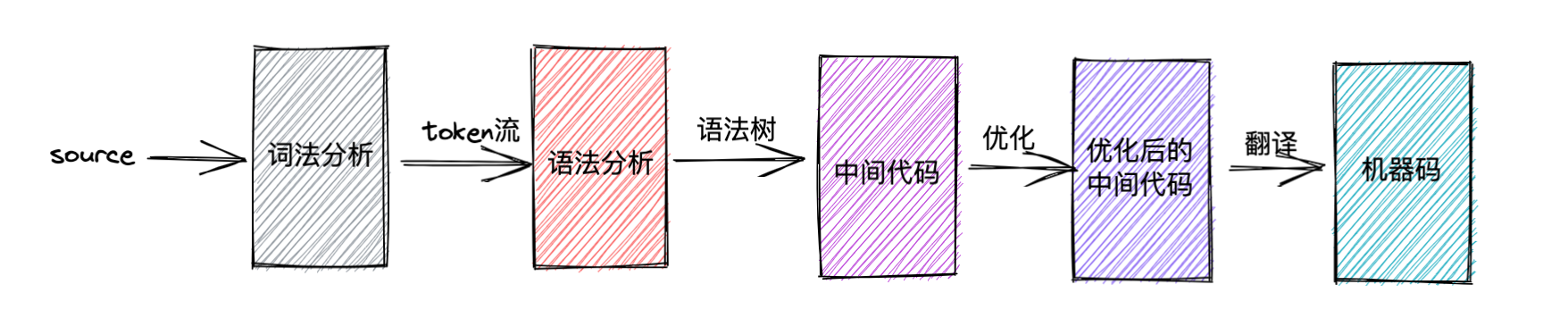
编译器将源码变为机器码的过程主要分为以下的步骤:
- 词法分析。输入源码,输出Token流。
- 语法分析。输入Token流,输出语法树。
- 中间代码生成。输入语法树,输出中间代码。
- 中间代码优化。对中间代码进行性能优化。
- 目标代码生成。也就是能够在目标机器上运行的二进制代码。
编译原理是一门范围广、知识深的课程,这里本人没有能力来深入介绍编译原理的知识。我们的目标是为了能够阅读Go语言的源码,因此我们只关注Go语言的编译过程即可。
词法分析
编译原理就其本质而言就是模拟人类理解源码的过程。
为了理解一句代码,首先就是要得到组成句子的有意义的词元,即Token。例如
make(chan int)
我们一眼就可以识别出make,chan ,int这些单词,因为这里单词都是有含义的,我们学过的知识以及直觉告诉我们要这样分解。
但是机器是没有任何知识和直觉的,它只会按我们预设的执行工作。所以我们需要告诉它哪些是有意义的词,让它能够正确的将代码分解为Token流,这个过程就是词法分析的过程,负责完成这个工作的就是词法分析器。
词法分析器是按照给定的规则识别出词元的过程,所以其实有了规则就能够知道词法分析器该如何工作了,于是就又了根据规则生成词法分析器的工具,感兴趣的话可以了解一下lex,这里就不进行扩展,耗费精力了。
go语言是一门实现了自举的语言,就是说用来go语言的编译器自身就是使用go语言编写的。负责词法分析的是src/cmd/compile/internal/syntax/scanner.go中的scanner结构体,这个结构体持有当前扫描的源文件,扫描的模式,以及表示当前扫描的token和表示扫描状态的标志位。
type scanner struct {
source
mode uint
nlsemi bool // if set '\n' and EOF translate to ';'
// current token, valid after calling next()
line, col uint
blank bool // line is blank up to col
tok token
lit string // valid if tok is _Name, _Literal, or _Semi ("semicolon", "newline", or "EOF"); may be malformed if bad is true
bad bool // valid if tok is _Literal, true if a syntax error occurred, lit may be malformed
kind LitKind // valid if tok is _Literal
op Operator // valid if tok is _Operator, _AssignOp, or _IncOp
prec int // valid if tok is _Operator, _AssignOp, or _IncOp
}
会不断从source中读取内容,解析出当前的token,并根据当前的解析结果设置对应的状态。在src/cmd/compile/internal/syntax/tokens.go文件中定义了token的类型。
const (
_ token = iota
_EOF // EOF
// names and literals
_Name // name
_Literal // literal
// operators and operations
// delimiters
// keywords
)
可以看到,分为终止符、变量名、字面量、运算符、分隔符、关键字等类型。对于字面量又进一步划分了整形、浮点型、字符串型等等类型,运算符同样如此,并且还定义了运算符的优先级。
词法解析过程由scanner实现的next方法进行驱动,每一次调用就往后读取一个token。这个函数代码近300行,但是逻辑很简单
func (s *scanner) next() {
...
redo:
//跳过空白符
s.stop()
startLine, startCol := s.pos()
for s.ch == ' ' || s.ch == '\t' || s.ch == '\n' && !nlsemi || s.ch == '\r' {
s.nextch()
}
// token start
s.line, s.col = s.pos()
s.blank = s.line > startLine || startCol == colbase
s.start()
if isLetter(s.ch) || s.ch >= utf8.RuneSelf && s.atIdentChar(true) {
s.nextch()
s.ident()
return
}
switch s.ch {
case -1:
if nlsemi {
s.lit = "EOF"
s.tok = _Semi
break
}
s.tok = _EOF
case '\n':
s.nextch()
s.lit = "newline"
s.tok = _Semi
case '0', '1', '2', '3', '4', '5', '6', '7', '8', '9':
s.number(false)
case '"':
s.stdString()
case '`':
s.rawString()
...
}
}
整个流程就是以非空白字符开始,通过大量的switch-case分支来匹配符合类型的token。具体的类型是如何解析出来的,可以查看对应的分支。
上层解析器就可以调用scanner.next()方法来获取token。
语法分析
语法分析是按照指定的文法,对词法解析器输出的token序列进行分析并确定其语法结构。每个源文件都会被解析为一个独立的抽象语法树,这个过程是由src/cmd/compile/internal/syntax/parser.go完成的。在对应类型的解析函数的注释当中就可以看到对应的文法规则,例如SourceFile
// SourceFile = PackageClause ";" { ImportDecl ";" } { TopLevelDecl ";" } .
也许你会奇怪go语言中明明没有分号,为什么文法当中会有。其实go语言是会自动为我们加上分号的,回顾上面词法分析中的scanner结构体,是否有一个nlsemi字段,它就是用来在语句的末尾加上分号的。
这里我们就可以看出来,一个go源文件是由包声明部分,导入的包声明,还有一些顶层声明组成的。SourceFile对应的是src/cmd/compile/internal/syntax/nodes.go下的File结构体,两者之间的对应关系还是很容易看出来的
// package PkgName; DeclList[0], DeclList[1], ...
type File struct {
Pragma Pragma
PkgName *Name
DeclList []Decl
EOF Pos
node
}
顶层声明有五大类型,分别是常量、类型、变量、函数和方法。我们可以从src/cmd/compile/internal/syntax/parser.go文件的注释中查看它们的文法,在src/cmd/compile/internal/syntax/nodes.go中查看对应的结构体。
对此感兴趣的可以自行了解,后续的文章我们也会不断来到这里进行查看的。
go编译器的入口函数为src/cmd/compile/internal/gc.Main,其中调用了src/cmd/compile/internal/noder/noder.go中的LoadPackage函数,在这个函数中启动了多个goroutine并调用src/cmd/compile/internal/syntax/syntax.go中的Parse函数来解析源文件,
func LoadPackage(filenames []string) {
for i, filename := range filenames {
p := noder{
err: make(chan syntax.Error),
trackScopes: base.Flag.Dwarf,
}
noders[i] = &p
filename := filename
go func() {
sem <- struct{}{}
defer func() { <-sem }()
defer close(p.err)
fbase := syntax.NewFileBase(filename)
f, err := os.Open(filename)
if err != nil {
p.error(syntax.Error{Msg: err.Error()})
return
}
defer f.Close()
p.file, _ = syntax.Parse(fbase, f, p.error, p.pragma, mode) // errors are tracked via p.error
}()
}
}
而syntx.Parse函数则是创建了一个parser对象并调用parser.fileOrNil来启动源文件的解析,最终的结果就是我们上面介绍的File结构体。
func Parse(base *PosBase, src io.Reader, errh ErrorHandler, pragh PragmaHandler, mode Mode) (_ *File, first error) {
defer func() {
if p := recover(); p != nil {
if err, ok := p.(Error); ok {
first = err
return
}
panic(p)
}
}()
var p parser
p.init(base, src, errh, pragh, mode)
p.next()
return p.fileOrNil(), p.first
}
更多的内容这里就不继续讲述了,主要了解了整个流程,以及如何找到对应的源码即可,方便我们后续的学习。
类型检查
Go语言是一门强类型语言,并不会进行隐式类型转换,成功地经过前面的词法分析和语法分析得到抽象语法树后,也并不意味着语句的正确性,例如
a := 1.0
b := 1
c := a + b
虽然从语法上看是正确的,但是go并不允许浮点数和整数直接进行算术运行,而类型检查就是负责检测出这种类型的错误的。
类型检查的代码在src/cmd/compile/internal/typecheck/typecheck.go下,同样是在src/cmd/compile/internal/noder/noder.go中的LoadPackage函数。
类型检查分为一下步骤:
- 检查常量、类型、函数声明
- 变量赋值语句的类型,依赖于步骤1
- 检查函数体
- 检查外部声明
- 检查哈希键
调用了一下的函数用于检查
typecheck.Stmt
typecheck.FuncBody
typecheck.Expr
这些检查最终都是调用的src/cmd/compile/internal/typecheck/typecheck.go的typecheck函数,其中调用的typecheck1函数是重点。在其中有大量的switch-case分支用来检查不同类型的节点
func typecheck1(n ir.Node, top int) ir.Node {
if n, ok := n.(*ir.Name); ok {
typecheckdef(n)
}
switch n.Op() {
default:
ir.Dump("typecheck", n)
base.Fatalf("typecheck %v", n.Op())
panic("unreachable")
case ir.OTSLICE:
n := n.(*ir.SliceType)
return tcSliceType(n)
case ir.OTARRAY:
n := n.(*ir.ArrayType)
return tcArrayType(n)
case ir.OTMAP:
n := n.(*ir.MapType)
return tcMapType(n)
case ir.OTCHAN:
n := n.(*ir.ChanType)
return tcChanType(n)
与前面一样,我们只需要知道了解整个流程并且知道如何找到对应的类型检查代码即可。
中间代码生成
同样在编译器的Main函数中找到中间代码生成的相关代码。
func Main(archInit func(*ssagen.ArchInfo)) {
...
ssagen.InitConfig()
...
// Compile top level functions.
base.Timer.Start("be", "compilefuncs")
fcount := int64(0)
for i := 0; i < len(typecheck.Target.Decls); i++ {
if fn, ok := typecheck.Target.Decls[i].(*ir.Func); ok {
// Don't try compiling dead hidden closure.
if fn.IsDeadcodeClosure() {
continue
}
enqueueFunc(fn)
fcount++
}
}
base.Timer.AddEvent(fcount, "funcs")
compileFunctions()
...
}
首先是初始化配置,为生成中间代码做准备。cmd/compile/internal/ssagen/ssa.go的InitConfig中准备了中间代码生成过程中会使用的类型指针以及会使用到的中间函数。例如处理defer的deferfunc中间函数。以及根据cpu的架构设置用于生成中间代码和机器码的函数
func InitConfig() {
types_ := ssa.NewTypes()
if Arch.SoftFloat {
softfloatInit()
}
// Generate a few pointer types that are uncommon in the frontend but common in the backend.
// Caching is disabled in the backend, so generating these here avoids allocations.
_ = types.NewPtr(types.Types[types.TINTER]) // *interface{}
_ = types.NewPtr(types.NewPtr(types.Types[types.TSTRING])) // **string
_ = types.NewPtr(types.NewSlice(types.Types[types.TINTER])) // *[]interface{}
_ = types.NewPtr(types.NewPtr(types.ByteType)) // **byte
_ = types.NewPtr(types.NewSlice(types.ByteType)) // *[]byte
_ = types.NewPtr(types.NewSlice(types.Types[types.TSTRING])) // *[]string
_ = types.NewPtr(types.NewPtr(types.NewPtr(types.Types[types.TUINT8]))) // ***uint8
_ = types.NewPtr(types.Types[types.TINT16]) // *int16
_ = types.NewPtr(types.Types[types.TINT64]) // *int64
_ = types.NewPtr(types.ErrorType)
...
ir.Syms.Deferproc = typecheck.LookupRuntimeFunc("deferproc")
...
}
然后在中间代码生成之前,需要对抽象语法树的节点进行替换。用于替换的函数在cmd/compile/internal/walk包下。用于将关键字和内联函数转换为真正的运行时函数,例如将 panic、recover 两个内建函数转换成 runtime.gopanic 和 runtime.gorecover 两个真正运行时函数。
这一部分比较重要,在后面一些数据结构的学习过程中,我们需要了解它们中间代码生成前的这个替换结果,才能更加深入了解其原理。
后续的中间代码的生成以及机器码的内容就不在介绍了,目前的内容足够我们后续的源码的学习了,如有不足再继续补充。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号