(It all comes down to respecting levels of abstraction)遵守(代码)抽象层级,是写好(C++)代码的不二法宝
As software developers, we get to learn many good practices and strive to apply them in our code.
作为软件开发者,我们渴望学习到一些优秀的实践方法并努力将它们运用到编码中。
For instance we learn the importance of good naming of variables and functions, encapsulation, class cohesion, the usage of polymorphism, conciseness, readability, code clarity and expressiveness, and many others.
例如:我们了解了好的变量和函数命名方式的重要性,了解了封装,类聚合,多态性使用的重要性,了解了简洁,阅读性,代码清晰且有表现力的重要性,以及了解了一些其他方面的重要性。
What if there was only one principle to know instead of plenty of best practices ?
那么,是否存在一个准则,只要我们了解了它就能代替大量的最佳实践?
I believe this principle exists: it consists of Respecting levels of abstraction.
我相信这个准则是存在的:它由遵守(代码)抽象层级组成。
This is the one principle to rule them all, because applying it automatically applies all the above best practices, and even more of them. When you follow it, your code writes itself out well naturally.
因为自动地将它运用到上面介绍的所有最佳实践上去,甚至更多,所以这是一个规范它们的准则。当你遵守该准则,你的代码自然会写的很好。
It’s based on simple notions, but it took me years of practice and study to formalize it. Anyway, enough talk, let’s dive right into it.
它基于简单概念,但是耗费了我多年的实践和学习去把它程序化。反正,说了这么多,让我们开始深入了解它。
The What and the How
是什么和怎么做
What are levels of abstraction in the first place ? This notion is easy to grasp when you look at a call stack. Let’s take the example of a software dealing with financial products, where the user has a portfolio of assets that he wants to evaluate:
首先,抽象层级是什么?当你看到如下这幅调用堆栈图的时候,再去把握这个概念就容易多了。让我们举一个处理金融产品软件的例子,用户想使用该产品评估它的资产组合:
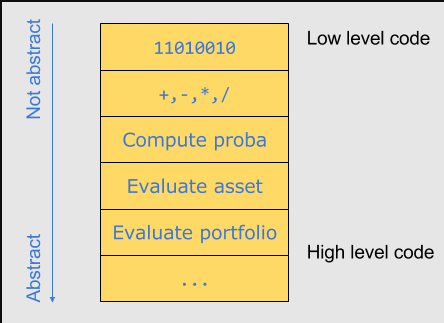
This call stack can be read from the bottom up the following way:
可以通过下面的方式自下而上的读取此调用堆栈:
- To evaluate a portfolio, every asset has to be evaluated.
- 到评估组合,每笔资产必须被评估。
- To evaluate a particular asset, say that some type of probability has to be computed.
- 到取评估某笔资产,即某种类型的概率必须被计算。
- To compute this probability there is a model that does mathematical operations like +, -, etc.
- 到取计算概率,比如像做+,-等算数操作的模型。
- And these elementary mathematical operations are ultimately binary operations sent to the CPU’s arithmetic and logic unit.
- 这些初级算数操作最终会以二进制操作发生到CPU的算术和逻辑单元。
It is quite natural to conceive that the code at the top of this stack is low-level code, and the code towards the bottom of the stack is rather high-level code. But level of what ? They are levels of abstraction.
很自然地会想到栈顶部的代码是底层代码,朝向栈底部的代码是高层代码。但是什么是层呢?他们是抽象层级。
Respecting levels of abstraction means that all the code in a given piece of code (a given function, an interface, an object, an implementation) must be at the same abstraction level. Said differently, at a given abstraction level there mustn’t be any code coming from another level of abstraction.
遵守(代码)抽象层级意味着:所有指定的代码段(函数,接口,对象,实现)必须处于同一抽象层级。换句话说,在指定的抽象层级内一定不能有任何来自于其他抽象层级的代码。
A given level of abstraction is characterized by what is done in it. For example at the bottom level of the stack, what is done is evaluating a portfolio. Then one level above in the stack, what is done is evaluating an asset. And so on.
给定的抽象层级的特征在于它做的内容,即它是什么。例如在上述栈的底层,内容是评估组合。然后在上一层,内容是评估资产。等等。
And to go from a given level of abstraction to the next lower one, the less abstract one is how the more abstract one is implemented. In our example, how to evaluate an asset is by computing a probability. How to compute a probability is with elementary mathematical operations, and so on.
并且从给定抽象层级到下一更低层级,抽象程度低的层级是抽象程度高的层级的实现方式,即怎么做。在我们的例子中,如何计算资产层级是通过计算概率层级实现的。如何计算概率层级使用了基本熟悉运算,等等。
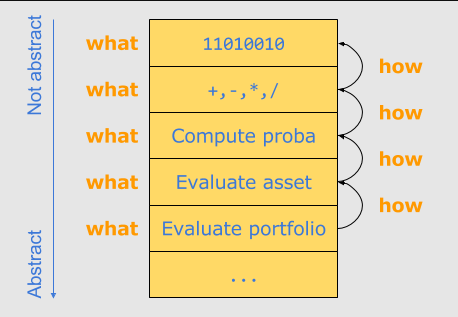
So the crucial question to constantly ask yourself when you design or write code is: “In terms of what am I coding here ?”, to determine which level of abstraction you are coding at, and to make sure you write all surrounding code with a consistent level of abstraction.
所以,当你在设计或编码时要不断问自己至关重要的问题是:“我这里编写的究竟是什么?”,来决定你编写的抽象层级,并确保你以一致的抽象层级编写你周围的代码。
One principle to rule them all
一个准则来规范他们
I deem the Respect of levels of abstraction to be the most important principle in programming, because it automatically implies many other best practices. Let’s see how several well-known best practices are just various forms of respecting levels of abstractions.
我认为在编程中遵守抽象层级是最重要的准则,因为它自动暗含了许多其他最佳实践。接下来让我们看看几个众所周知的最佳实践是如何体现遵守抽象层级形式的。
Polymorphism
多态性
Maybe the first thing you thought of when reading about abstraction is polymorphism.
或许读到抽象你想到的第一件事就是多态性。
Polymorphism consists of segregating levels of abstraction.
多态性由分离的抽象层级组成。
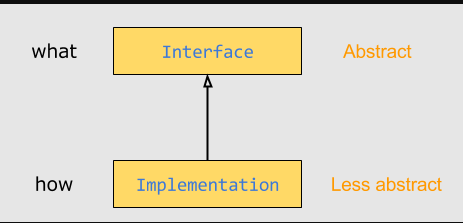
Indeed, for a given interface (or abstract class) and a concrete implementation, the base class is abstract, while the derived implementation is less abstract.
的确,对于给定的接口(或抽象类)和具体的实现,基类是抽象的,但是派生类的实现抽象程度低更低。
Note that the derived class is still somewhat abstract though, since it is not expressed in terms of 0s and 1s, but it is at an inferior level of abstraction than the base class. The base class represents what the interface offers, and the derived class represents how it is implemented:
注意派生类仍然有些抽象,因为它不是用0和1表示的,但是它的抽象层级低于基类。基类表示接口提供的内容,即是什么,且派生类表示该接口是如何实现的:
Good naming
好的命名
Let’s take the example of a class in charge of maintaining a caching of values. This class lets its clients add or retrieve values of type V, with keys of type K.
让我们举个负责维护缓存值的类的例子。该类让其客户端添加或者获取类型为V的值,其键值类型为K。
It can be implemented with a map<K,V>:
它可以使用map<K, V>实现:
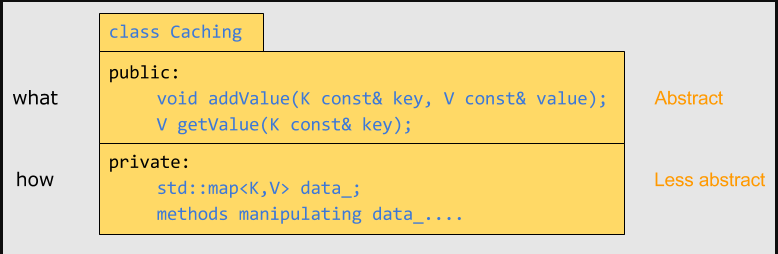
Imagine now that we want the interface to be able to provide the whole set of results for all stored keys at once. Then we add a method to the interface. How should we name this method ? A first try may be “getMap”.
想象下,现在我们想让接口立刻能够为所有存储的键值提供完整的结果集。然后我们添加一个方法给到接口。我们应该如何给这个方法命名呢?第一次尝试的名称可能是"getMap"。
1 .... 2 const std::map<K,V>& getMap() const { return data_; } 3 ....
But as you might feel, “getMap” is not a good name. And the reason why it isn’t is because at the abstraction level of the caching interface, “Map” is a term of how (observe that it appears in the bottom part of the diagram), and not of what, so not at the same abstraction level. Calling it “getMap” would mix several abstraction levels together.
但是你可能感觉"getMap"不是个好名字。感觉不好的原因是:缓存接口的抽象层级,"Map"是如何的术语(观察发现它出现在图表的下部分),而不是什么的术语,所以不在同一抽象层级。一起和它调用"getMap"可能会将几个抽象层级混淆在一起。
A simple fix would be to call it “getAllValues” for instance. “Values” is a consistent term with the level of abstraction of the caching interface, and is therefore a name that is more adapted than “Map”.
一个简单修复办法是实例调用"getAllValues"。"Values"是缓存接口抽象层级的一致术语,因此它的名字比"Map"更容易被采纳。
Good naming is in fact giving names that are consistent with the abtraction level they are used in. This works for variable names too. And because naming defines levels of abstraction and is therefore such an important topic, we will have a dedicated post about it. You can follow me on Twitter (or subscribe to the Rss feed) at the bottom of this post if you want to be notified when this comes out.
好的命名事实上给定的名字与它们在使用中的抽象层级具有一致性。这也同样适用于变量名称。因为命名定义了抽象层级,并且因为它是一个很重要的话题,我们将在后续的博客中涉及它。如果你想收到此类通知,可以关注我此篇文章下边的Twitter(或者订阅Rss)。
Encapsulation
封装
But isn’t it a violation of encapsulation to provide the map of results to the outside of the class in the first place? Actually the answer depends on whether the concept of a results container is logically part of the abstraction of the class interface.
但是一开始把结果map提供给类的外部,这是不是违反了封装?实际上答案取决于结果容器的概念是否是类接口抽象的逻辑部分。
So breaking encapsulation is providing information that go beyond the abstraction level of the interface.
所以打破封装是提供超出接口抽象层级的信息。
Cohesion
内聚
Now imagine that we added a new method in the caching class to do some formatting on values:
现在想象下我们在缓存类中添加一个新的方法来格式化值:
1 .... 2 static void formatValue(V&); 3 ....
This is obviously a bad idea because this class is about caching values, not about formatting them. Doing this would break the cohesion of the class. In terms of abstraction, even though caching and formatting don’t have a what-how relationship, they are two different abstractions because they are in terms of different things.
这显然是个糟糕的想法,因为这个类是关于缓存值,而不是格式化它们。这么做将会打破类的内聚。就抽象而言,即使缓存和格式化没有what-how的关系,但是它们有两种不同的抽象,因为它们是不同的事物。
So cohesion consists of having only one abstraction at a given place.
所以内聚由一个给定的地方只有一个抽象组成。
Conciseness, readability
简明,可读性
Let’s go down to the function (or method) level.
让我们深入到函数(或方法)层级。
To continue on the financial example, let’s consider financial indices such as the Dow Jones or the S&P, that contain a collection of equities like Apple, Boeing or Caterpillar.
继续金融的例子,让我们思考下金融指数,例如:道琼斯或标普指数,其包含一些列的股票像苹果,波音或卡特彼勒。
Say that we want to write a function that triggers the save of an index in database after having done some checks on it. Specifically, we want to save an index only if it is valid, which means say, having an ID, being quoted on a market and being liquid.
比如说我们要编写一个函数,在对其进行一系列检测后触发将索引保存到数据库中。具体来说,我们只想保存一个有效的索引,也就是说,有一个ID,在市场上被引用并且具有流动性。
A first try for the function implementation could be the following:
第一次尝试的函数实现可能如下:
1 void saveIndex(Index const& index) 2 { 3 if (index.hasID() && index.isQuoted() && index.isLiquid()) 4 { 5 ...
We could object to this implementation that it has a relatively complex boolean condition. A natural fix for this would be to group it and take it out of the function, for code conciseness and readability:
我们可能会反对这种实现,它有一个相对复杂的布尔条件。自然而然的修复方式是去组合它并且放到函数外面,因为代码简明和具有可读性:
1 void saveIndex(const Index& index) 2 { 3 if (isValid(index)) 4 { 5 ...
When we think about this fix, it consists in fact pushing out the implementation of how an index is considered valid (having an ID, quoted, liquid) and replacing it with what the save depends on (being valid), which is more consistent with the level of abstraction of the save function.
当我们思考这个修改方式时,它实际上包含推出如何将索引视为有效的实现(具有ID,引用,流动性)并将它替换为保存所依赖的内容,即是什么(有效),其更加符合保存功能的抽象层级。
An interesting thing to note at this point is that respecting levels of abstraction goes beyond the simple conciseness of code. Indeed, we would still have done this fix even if being valid only meant having an ID. This wouldn’t have reduced the number of characters typed in the code (it would even have slighlty increased it), but this would have improved code clarity by respecting levels of abstraction。
在这一点上要注意的一件有趣的事情是遵守抽象层级超出了代码的简洁性。确实,即使有效仅意味着有ID,但是我们仍然会这么修改。这不会降低在代码中键入的字符数量(它可能会稍稍有所增加),但是这可以通过 遵守抽象层级来提高代码的清晰度。
Expressiveness
表达性
Last but not least, expressiveness, which is the focus of Fluent C++.
最后但并非不重要,表达性是Fluent C++的关注点。
Say that we want to remove some components from the index if they are not themselves valid.
比如说我们想从索引中移除一些本身无效的组件。
The best solution here is to use the remove_if algorithm of the STL. STL algorithms say what they do, as opposed to hand-made for loops that just show how they are implemented. By doing this, STL algorithms are a way to rise the level of abstraction of the code, to match the one of your calling site.
这里最好的解决方案是使用STL中的算法 remove_if。STL算法说的是他们做了什么,相反,通过手动循环显示的是它们如何实现的。通过这么处理,STL算法是提升代码抽象层级的方法,以匹配你的调用栈点。
We’ll explore the STL in depth in future posts (again – follow me to stay updated) because they are such a great tool to improve code expressiveness.
在将来的博客中我们将深入探索STL,因为它们是改善代码表达性的非常棒的工具。
Conclusion
结论
Following the principle of Respecting levels of abstraction helps make choices when designing code, on many aspects. If you think about this principle when designing your code, if you constantly ask yourself the question “In terms of what am I coding here ?”, your code will write itself well, naturally.
在许多方面,当设计代码的时候,遵循遵守抽象层帮助做出选择。当设计你的代码时,如果你思考这个准则,就要不断地问自己问题:“我这里写的代码究竟是什么?”,你的代码将自然会写的非常好。
Many guidelines can be derived from this principle. I intend to write several posts exploiting it to improve code in various ways. If you want to be notified so you don’t miss out on this, you can just follow with one of the buttons below :).
许多指导方针可以从这个准则中派生。我打算写几篇博客利用它的各种方式改进代码。如果你想在这方面不错过通知,你只要按以下按钮之一即可:)。
参考:
https://www.fluentcpp.com
声明:以上翻译博主结合自身的理解,难免有不恰当或错误的地方,所以附带英文原文,以做参考。后续结合实际情况,继续翻译该网站下有意义博客内容,一方面提高英文阅读水平,另一方面总结编程相关的经验。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号