

Scrapy框架爬取豆瓣
Scrapy框架爬取豆瓣
下载Scrapy
- 下载命令
conda install scrapy(使用这个命令必须安装Anaconda) - 验证是否安装成功
在cmd窗口输入【scrapy】,回车,出现使用方法表示安装成功
使用Scrapy框架爬取豆瓣
-
新建项目
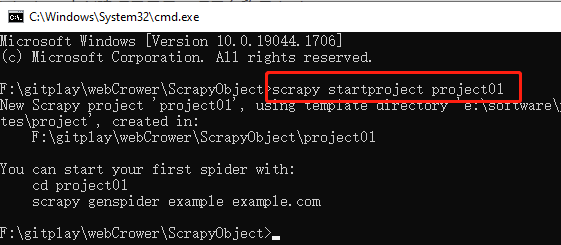
在预备创建项目的路径下打开cmd窗口,输入命令scrapy startproject project01,创建一个名为project01的项目,项目的目录结构如下。
-
编辑爬虫
-
在spider下新建一个top250.py文件
top250.py
import scrapy import bs4 from ..items import Project01Item class DoubanSpider(scrapy.Spider): # 定义一个爬虫类DoubanSpider name = 'book_douban' # name是定义爬虫的名字,这个名字是爬虫的唯一标识。 # name = 'book_douban'意思是定义爬虫的名字为book_douban。 # 等会我们启动爬虫的时候,要用到这个名字。 allowed_domains = ['book.douban.com'] # allowed_domains是定义允许爬虫爬取的网址域名(不需要加https://)。 # 如果网址的域名不在这个列表里,就会被过滤掉。 start_urls = ['https://book.douban.com/top250?start=0'] # start_urls是定义起始网址,就是爬虫从哪个网址开始抓取。 # 并且allowed_domains的设定对start_urls里的网址不会有影响。 # for x in range(3): # url = f'https://book.douban.com/top250?start={x * 25}' # start_urls.append(url) def parse(self, response): # parse是默认处理response的方法 bs = bs4.BeautifulSoup(response.text, 'html.parser') # 用BeautifulSoup解析response datas = bs.find_all('tr', class_="item") # 用find_all提取<tr class="item">元素,这个元素里含有书籍信息 for data in datas: # 遍历data item = Project01Item() # 实例化DoubanItem这个类 item['title'] = data.find_all('a')[1]['title'] # 提取出书名,并把这个数据放回DoubanItem类的title属性里 item['publish'] = data.find('p', class_='pl').text # 提取出出版信息,并把这个数据放回DoubanItem类的publish里 item['score'] = data.find('span', class_='rating_nums').text # 提取出评分,并把这个数据放回DoubanItem类的score属性里。 print(item['title']) # 打印书名 yield item # yield item是把获得的item传递给引擎 -
编辑item.py文件
item.py
import scrapy class Project01Item(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() # 定义书名的数据属性 title = scrapy.Field() # 定义出版信息的数据属性 publish = scrapy.Field() # 定义评分的数据属性 score = scrapy.Field() pass -
更新部分setting.py设置
setting.py
# Crawl responsibly by identifying yourself (and your website) on the user-agent USER_AGENT = 'project01 (+http://www.yourdomain.com)' # Obey robots.txt rules ROBOTSTXT_OBEY = True # 遵循robots协议 LOG_LEVEL = 'WARNING' # 设置log打印等级,筛选打印信息
-
-
运行爬虫
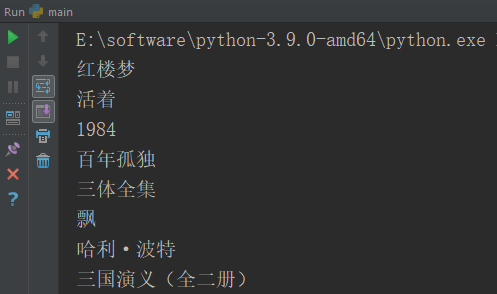
根目录下新建一个main.py运行程式即可输出打印信息main.py
from scrapy import cmdline #导入cmdline模块,可以实现控制终端命令行 cmdline.execute(['scrapy','crawl','book_douban']) #用execute()方法,输入运行scrapy的命令
Scrapy调用分析
参考链接:https://blog.csdn.net/qq_38486203/article/details/80349491
-
Scrapy流程图
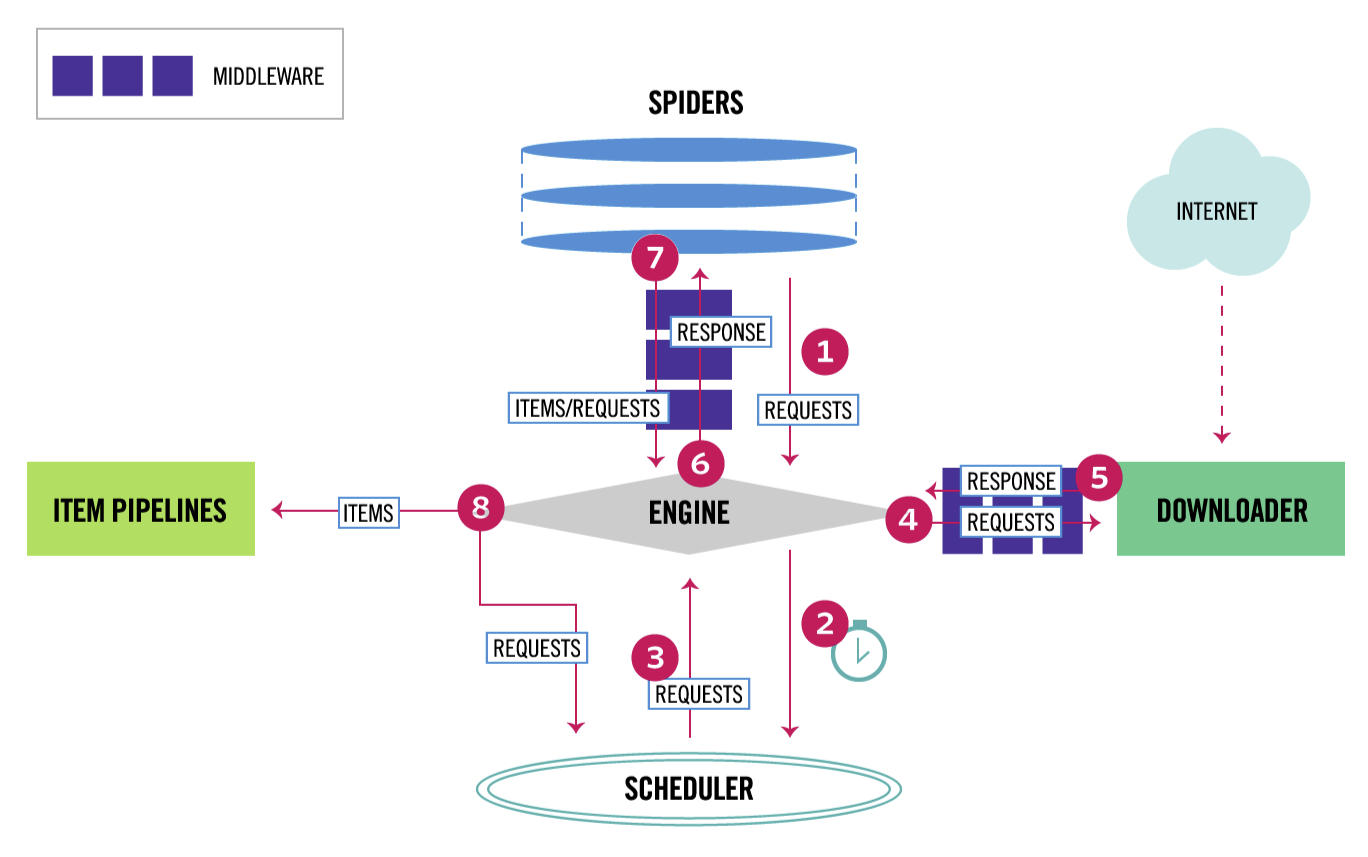
-
执行步骤
先明确对应关系
SPIDERS -- spiders\top250.py
ITEM PIPLINES -- item.py & piplines.py
MIDDLEWARE -- middlewares.py
- spiders向爬虫引擎发出初始请求'''https://book.douban.com/top250?start=0'''
- 爬虫引擎将请求'''https://book.douban.com/top250?start=0'''放入调度器队列
- 调度器返回请求URL'''https://book.douban.com/top250?start=0'''给爬虫引擎
- 爬虫引擎请求下载'''https://book.douban.com/top250?start=0'''
- 下载器将从INTERNET中下载的数据(此处为HTML)返回给爬虫引擎
- 爬虫引擎将下载的数据通过中间件交给spiders处理(通过bs4获取item的属性title,publish, score)
- 爬虫通过中间件返回处理后的items,以及新的请求给引擎。
- items的值就存放在ITEM PIPLINES中,可以在piplines.py中print(items)得到相应结果。出现打印信息的前提是在setting.py中打开item_piplines。'''ITEM_PIPELINES = {'project01.pipelines.Project01Pipeline': 300,}''',新的请求则放入调度器的队列中。




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 【杭电多校比赛记录】2025“钉耙编程”中国大学生算法设计春季联赛(1)
2020-05-26 百度云文字识别使用
2020-05-26 第八篇 -- 修改新浪微博绑定手机号
2020-05-26 XPath语法
2020-05-26 爬取千千小说 -- xpath