
爬取千千小说 -- xpath
今天以其中一本小说为例,讲一下下载小说的主体部分,了解正常的爬取步骤,用到的是request和xpath。
爬取数据三步走:访问url --》爬取数据 --》保存数据
一、访问千千小说网址: https://www.qqxsnew.com/
二、随便选一部小说,打开章节目录界面(比方说魔道祖师):https://www.qqxsnew.com/18/18991/
三、开始编写代码。
a. 利用request访问网页,是get请求还是post请求要看网页上面写的是啥
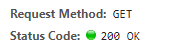 右击检查,选择network,随便找个页面,看下request Method方法是什么。
右击检查,选择network,随便找个页面,看下request Method方法是什么。
url = "https://www.qqxsnew.com/18/18991/" html = requests.get(url, headers=headers).text
b. 得到网页的html页面(html页面 == 在网页鼠标右击“查看网页源代码”),获取章节名字和章节链接。
章节名字和章节链接获取需要用到XPath --》在网页鼠标右击检查 --》定位到任意章节(如第一章)--》copy --》copy XPath --》 //*[@id="list"]/dl/dd[13]/a

如果安装过XPath插件的话,可以将上面复制的XPath在插件里面查询,可以看到只查询到了一个

我们的目的是获取到所有章节的名字和链接,分析上面XPath的字串,发现dd[13]这个地方是定位,每个dd都是一个章节,所以我们模糊定位看看

咦,可以看出来dd里面的内容都出来了,但是前面12章的内容不是我们需要的,我们要的是从第一章开始,所以需要把它们过滤掉,position是一个定位的函数,大于12是说从第13位开始,也就是第一章

这数据正好是我们想要提取的文字,所以我们已经得到了文字提取的XPath字串://*[@id="list"]/dl/dd[position()>12]/a
文字和链接都在a标签里面,链接在href属性里面,所以链接的XPath字串://*[@id="list"]/dl/dd[position()>12]/a/@href

好了,前面是在分析XPath字串是怎么得到的,如果自己对XPath语法熟的话,也可以自己写提取字串,然后用插件去验证,或者直接用代码验证都是可以的。现在我们把它放到代码中去
# 获取a标签对象 chapter_titles_obj = datas.xpath('//*[@id="list"]/dl/dd[position()>12]/a') for chapter_title_obj in chapter_titles_obj: # 获取a标签文本 chapter_title_text = chapter_title_obj.xpath('./text()')[0] # 获取a标签的链接 chapter_url = chapter_title_obj.xpath('./@href')[0]
打印出来看看结果
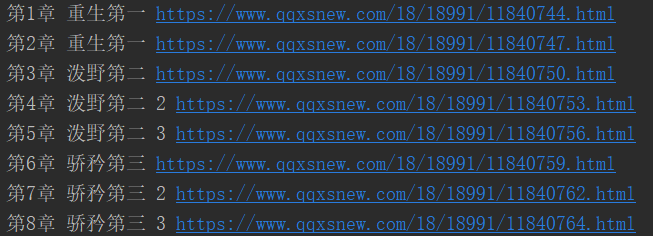
c. 每个章节的链接都拿到了,接下来就是请求了,这个不多说,和上面请求的方法一样,XPath获取方法也相同。

d. 存储获取到的数据
for content_chapter_text in content_chapter: print(content_chapter_text) with open("魔道祖师/" + chapter_title_text + ".txt", 'a', encoding='utf-8') as f: f.write(content_chapter_text)
这样,一篇小说从访问到下载的过程就结束了。
完整代码


#!/usr/bin/env python # _*_ coding: UTF-8 _*_ """================================================= @Project -> File : six-dialog_design -> qianqian.py @IDE : PyCharm @Author : zihan @Date : 2020/5/25 14:50 @Desc : =================================================""" import requests from lxml import etree headers = { 'User-Agent': "" } def main(): url = "https://www.qqxsnew.com/18/18991/" html = requests.get(url, headers=headers).text datas = etree.HTML(html) chapter_titles_obj = datas.xpath('//*[@id="list"]/dl/dd[position()>12]/a') for chapter_title_obj in chapter_titles_obj: chapter_title_text = chapter_title_obj.xpath('./text()')[0] chapter_url = chapter_title_obj.xpath('./@href')[0] chapter_url = "https://www.qqxsnew.com" + chapter_url # 对每一章的链接发送请求 html_chapter = requests.get(chapter_url, headers=headers).text datas_chapter = etree.HTML(html_chapter) content_chapter = datas_chapter.xpath('//*[@id="content"]/text()') print(chapter_title_text, "开始下载") for content_chapter_text in content_chapter: print(content_chapter_text) with open("魔道祖师/" + chapter_title_text + ".txt", 'a', encoding='utf-8') as f: f.write(content_chapter_text) if __name__ == '__main__': main()
OK。如果想要批量下载,或者选择下载等,只是改变url而已,了解主体方法后,这些都不难。
