

有效提高命中率的缓存设计
最近在做网站应用的优化那自然就涉及到缓存方面的处理,实际应用中不可能针对所有数据进行缓存,所以那些数据要优先缓存则变得非常重要.在.net提供一些缓存功能如缓存多长时间或依赖性缓存,但这种缓存方式都很有局限制,并不能达到缓存高命中率的数据.为了实现这点在开始设计缓存的时候采用了LRU算法.
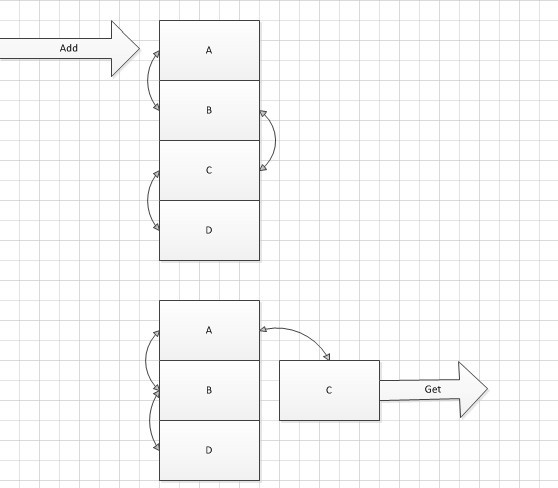
这种算法的主要作用是保存最近使用的数据,可以简单地使用一个双向链接结合哈希表来实现.当添加缓存或使用时候把对应的项移至链表头,通过一个计时器对链表尾进行扫描,把最后活动的数据进行清除.
但这种设计似乎并不理想也很难达到缓存高命中率的数据,拿用户登陆为例实际上最后登陆的用户不一定就是非常活跃的用户,如小张是网站的活跃用户有可能他这几天没有访问网站,那通过以上算法就可能一些不活跃把他挤到后面导致从缓存中排除;这样的结果其实并不是我们想要的,所以紧紧靠简单LRU算实现很达到以上的需求.
经过一段时间的思考在LRU算法的基础加上是L1,L2,L3的Cache似乎可以很好地解决以上问题.
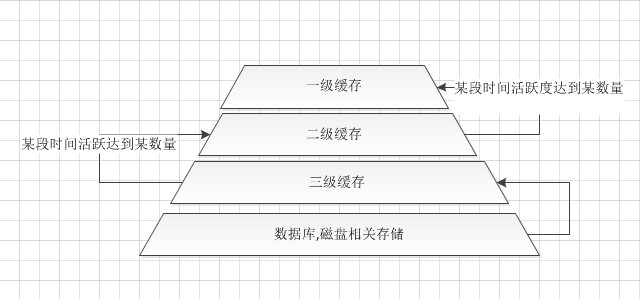
在原有的基础划分了多层Cache,每层缓存活跃度不同的数据中,每层都有各自的LRU算法来排除超出容易的缓存数据.第一级的缓存活跃度最高,第三级的缓存活跃度最低.以登陆为例:一般一个用户登陆后都会在三级缓存区,那是怎样可以冲到一级去呢,唯一的办法就是用户在某层缓存活跃度达到一个数量的同时又没有被本层LRU算法排除的就会切换到上一层缓存区去.由于每一层都有对应的LRU算法,缓存空间不足的情况会自动清除当前最不活跃的,如二级缓存用户升级上去时当一级缓空间不足的情况就把最久没活动的挤出去.
以上设计已经满足当前需求的需要,具体应用效果还有待完成和最终的使用成效.
访问Beetlex的Github
