Flume快速入门
Flume快速入门
一、简介
高可用、高可靠,分布式的海量日志采集、聚合和传输系统,基于流式架构,灵活简单。
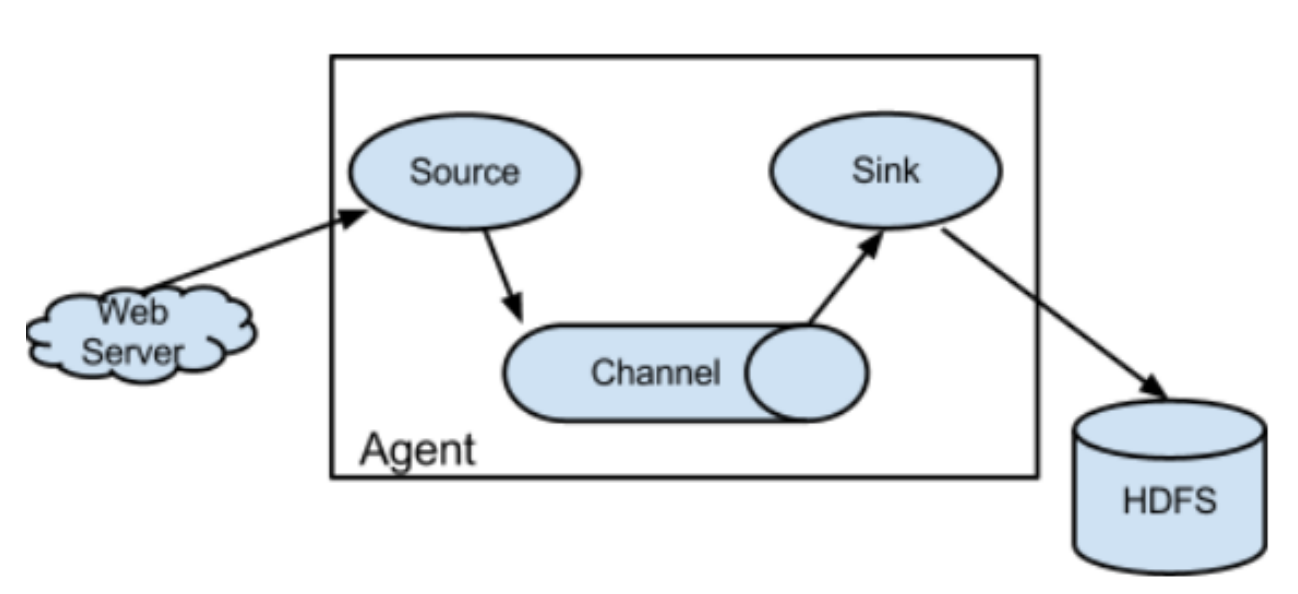
event:事件 source:数据源 sink:目标 channel:数据管道
通过获取数据源转化为事件进入数据管道,在数据管道通过中流向目标对象(HDFS、HBase、MySQL等)进行存储。
优点:可以高速采集数据,采集的数据能够以想要的文件格式压缩方式存储在HDFS上;
事务功能保证数据在采集过程数据不丢失;
部分Source保证了Flume挂了以后依旧能够在上一个采集点采集数据,真正做到数据零丢失。
Event:一个数据单元,由消息头和消息体组成。(Events可以是日志记录,avro对象等。)
Agent:一个独立的Flume进程,包含组件Source、Channel、Sink
Flow:数据从源头到达目的点的迁移的抽象。
二、架构详解
Flume从数据源获取到数据,经过拦截器进行过滤后,以特定的文件格式封装到Event,批量推送到channel中,channel有点像队列,默认设置最大装载100个Event,然后Sink拉取到过滤好的数据,就把channel中的Event删除,最终下沉到目的存储设备(HDFS、HBase、MySQL等)。
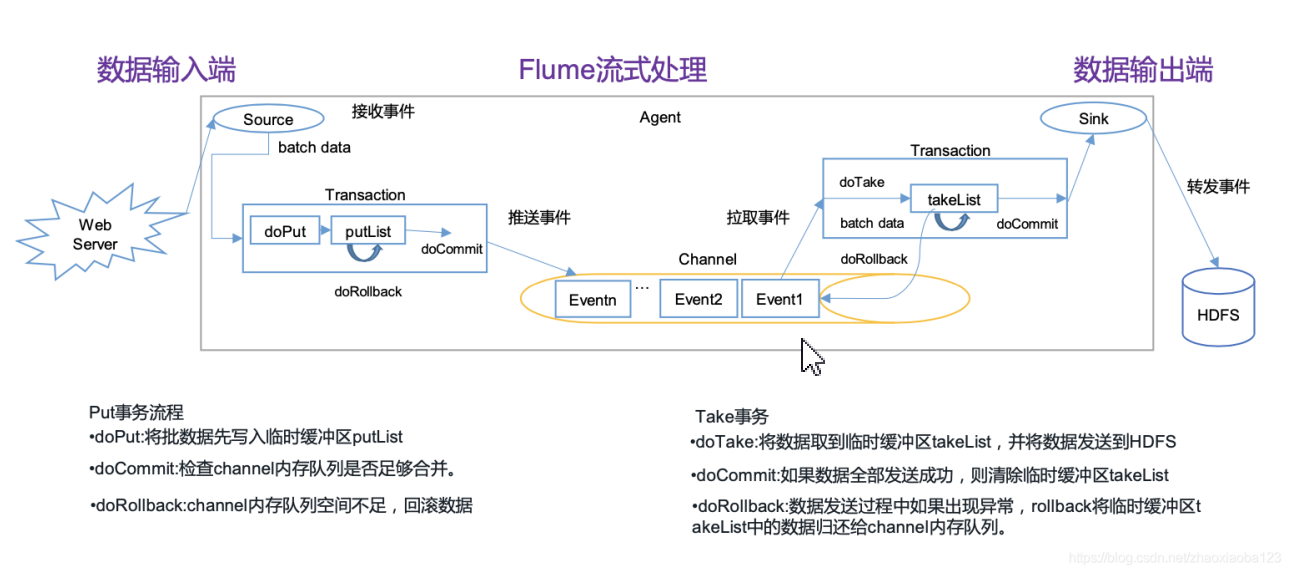
- 事务
Source在推送和Sink拉取时,为了提高系统的容错机制,在推送和拉取过程中设置了事务机制,通过事务机制保证了数据在传输的过程中的安全性。
推送事务流程:doPut: 把批数据写入到临时缓冲区putList;doCommit: 检查Channel容量是否足够,如果容量足够则把putList里的数据发送到Channel;doRollBack:如果Channel容量不够,则把数据回滚到putList。
拉取事务流程:doTake:把数据读取到临时缓冲区takeList;doCommit:检查数据是否发送成功,成功的话,则把event从takeList中移除;doRollBack:如果发送失败,则把takeList的数据回滚数据到Channel。
数据丢失了,只有从存储在磁盘的方式,才能将数据找回,事件在通道中恢复,该通道管理从故障中恢复,flume支持持久的文件通道,该通道由本地文件系统支持。
三、Flume安装
- 安装要求
java运行时环境-java1.8或更高版本。
内存-----足够的内存,用于源,通道或接收器使用的配置
磁盘空间-----足够的磁盘空间用于通道或接收器使用的配置
目录权限-----代理使用的目录的读/写权限
- 上传解压
tar -zxvf apache-flume-1.11.0-bin.tar.gz -C /usr/local/flume/
- 创建存放配置文件的目录(一个配置文件表示一个Agent,存放目录自定义,一般放在以下文件夹中)
mkdir -p /usr/local/flume/apache-flume-1.11.0-bin/options/
- 配置环境变量
cd /usr/local/flume/apache-flume-1.11.0-bin/conf/
cp flume-env.sh.template flume-env.sh
vim flume-env.sh
vim flume-env.sh
# 修改Java_HOME
22 export JAVA_HOME=/usr/local/java/jdk1.8.0_231-amd64
# 设置使用内存大小,只有当channel设置为内存存储的时候才会用到这个
# export JAVA_OPTS="-Xms128m -Xmx1024m -Dcom.sun.management.jmxremote"
- 把配置好的资源分发到其他节点
rsync -av /usr/local/flume/apache-flume-1.11.0-bin root@master:/usr/local/flume/
rsync -av /usr/local/flume/apache-flume-1.11.0-bin root@node2:/usr/local/flume/
- 配置环境变量
vim /etc/profile
export FLUME_HOME=/opt/yjx/apache-flume-1.11.0-bin
export PATH=$FLUME_HOME/bin:$PATH
source /etc/profile #编译配置文件,让配置文件生效
- 测试版本是否生效
flume-ng version
四、Flume使用
案例-简单示范(配置文件以conf结尾)
vim /usr/local/flume/apache-flume-1.11.0-bin/options/netcat2logger.conf
- 配置文件如下:
##定义a1的三个组件的名称
a1.sources = r1
a1.sinks = k1
a1.channels = c1
##定义Source的类型
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
##定义Channel的类型
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
##定义Sink的类型
a1.sinks.k1.type = logger
##组装source channel sink
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
- 启动命令
flume-ng agent -n a1 -c conf -f ${FLUME_HOME}/options/netcat2logger.conf -
Dflume.root.logger=INFO,console
- 安装telnet进行测试
yum install telnet
telnet localhost 44444
读取文件测试
- 编写agent配置文件
vim /usr/local/flume/apache-flume-1.11.0-bin/options/exec2logger.conf
##定义a1的三个组件的名称
a1.sources = r1
a1.sinks = k1
a1.channels = c1
##定义Source的类型
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /root/baidu.log
a1.sources.r1.channels = c1
##定义Channel的类型
a1.channels.c1.type = memory
a1.channels.c1.capacity = 100
a1.channels.c1.transactionCapacity = 100
##定义Sink的类型
a1.sinks.k1.type = logger
##组装source channel sink
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
- 执行日志文件重定向写入
ping www.baidu.com >> /root/baidu.log
- 启动Flume
flume-ng agent -c conf -f $FLUME_HOME/options/exec2logger.conf -Dflume.root.logger=INFO,console
特点:初始化读取文件内容只能从第10行开始读取,断开连接,会丢失数据
Spooling Source读取
- 配置Agent
vim /usr/local/flume/apache-flume-1.11.0-bin/options/spooldir2logger.conf
##定义a1的三个组件的名称
a1.sources = r1
a1.sinks = k1
a1.channels = c1
##定义Source的类型
a1.sources.r1.type = spooldir
#设置读取的文件目录 可以读取目录下的多个文件
a1.sources.r1.spoolDir = /root/logs
##定义Channel的类型
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
##定义Sink的类型
a1.sinks.k1.type = logger
##组装source channel sink
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
- 在/root/logs目录下存放要读取的文件
flume-ng agent -c conf -f $FLUME_HOME/options/spooldir2logger.conf -Dflume.root.logger=INFO,console
特点:经过一次读取,文件格式发生转变,原来文件不能读取了!需要重新建立文件读取。也就是断开连接无法继续读取。
TailDir Source读取
vim /usr/local/flume/apache-flume-1.11.0-bin/options/TailDir2logger.conf
##定义a1的三个组件的名称
a1.sources = r1
a1.sinks = k1
a1.channels = c1
##定义Source的类型
a1.sources.r1.type = TAILDIR
## 配置存放偏移量信息的数文件
a1.sources.r1.positionFile = /var/yjx/flume/taildir2logger_position.json
a1.sources.r1.filegroups = f1 f2
#配置需要的读取的文件
a1.sources.r1.filegroups.f1 = /root/logs/baidu.log
a1.sources.r1.headers.f1.headerKey1 = f1
a1.sources.r1.filegroups.f2 = /root/logs/.*log.*
a1.sources.r1.headers.f2.headerKey1 = f2key1
a1.sources.r1.headers.f2.headerKey2 = f2key2
a1.sources.r1.fileHeader = true
##定义Channel的类型
a1.channels.c1.type = memory
## 信道最大存放1000个Event
a1.channels.c1.capacity = 1000
## 信道单次传输100个Event
a1.channels.c1.transactionCapacity = 100
##定义Sink的类型
a1.sinks.k1.type = logger
##组装source channel sink
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
- 启动Flume
flume-ng agent -c conf -f $FLUME_HOME/options/TailDir2logger.conf -Dflume.root.logger=INFO,console
特点:数据读取完整,数据传输断开,会保留上次的偏移量信息,下次读取直接从偏移量文件存储的位置开始读取信息。
Interceptors拦截器案例
vim /usr/local/flume/apache-flume-1.11.0-bin/options/exec2Interceptor2logger.conf
##定义a1的三个组件的名称
a1.sources = r1
a1.sinks = k1
a1.channels = c1
##定义拦截器拦截source数据源进行过滤
a1.sources.r1.interceptors = ts hn sc ud sr rf
#在头部信息中添加时间戳 {timestamp=1700647174337}
a1.sources.r1.interceptors.ts.type = timestamp
#在头部信息中添加主机Ip{host=192.168.147.120}
a1.sources.r1.interceptors.hn.type = host
# 在Event中头部信息添加 [master:liyi]
a1.sources.r1.interceptors.sc.type = static
a1.sources.r1.interceptors.sc.key = master
a1.sources.r1.interceptors.sc.value = liyi
# 配置UUID生成加入头部信息{uuid=ef730712-1129-46f2-84b2-2b602030306c}
a1.sources.r1.interceptors.ud.type =
org.apache.flume.sink.solr.morphline.UUIDInterceptor$Builder
a1.sources.r1.interceptors.ud.headerName = uuid
#正则表达式匹配替换对应的字符 (替换匹配正则符号的值) 把所有数字替换成***
a1.sources.r1.interceptors.sr.type = search_replace
a1.sources.r1.interceptors.sr.searchPattern = \\d+
a1.sources.r1.interceptors.sr.replaceString = ***
#把包含数字的全部过滤掉 一行单纯数字不显示 一行嵌套数字,数字变....
a1.sources.r1.interceptors.rf.type = regex_filter
a1.sources.r1.interceptors.rf.regex = \\d+
a1.sources.r1.interceptors.rf.excludeEvents = true
##定义Source的类型
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /root/baidu.log
a1.sources.r1.channels = c1
##定义Channel的类型
a1.channels.c1.type = memory
a1.channels.c1.capacity = 100
a1.channels.c1.transactionCapacity = 100
##定义Sink的类型
a1.sinks.k1.type = logger
##组装source channel sink
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
通过设置过滤器,可以过滤出不合规的数据,甚至敏感词!可以在过滤器中实现想要的操作!
HDFS上传案例
- 配置agent
vim /usr/local/flume/apache-flume-1.11.0-bin/options/hdfs-logger.conf
##定义a1的三个组件的名称
a1.sources = r1
a1.sinks = k1
a1.channels = c1
##定义Source的类型
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /root/baidu.log
a1.sources.r1.channels = c1
##定义Sink的类型
a1.sinks.k1.type=hdfs
## 设置文件夹名字 以时间格式设置文件夹名字
a1.sinks.k1.hdfs.path=hdfs://hdfs-zwf/flume/baidu/%Y%m%d/%H%M
##hdfs有多少条消息时新建文件,0不基于消息个数
a1.sinks.k1.hdfs.rollCount=0
##hdfs创建每隔60s时间新建文件,0表示不基于时间
a1.sinks.k1.hdfs.rollInterval=60
##hdfs多大时新建文件,0不基于文件大小 文件大小超过10M的时候产生新文件
a1.sinks.k1.hdfs.rollSize=10240
##当目前被打开的临时文件在该参数指定的时间(秒)内,没有任何数据写入,则将该临时文件关闭并重命名成目标文件
a1.sinks.k1.hdfs.idleTimeout=3
## 不使用压缩 只适用数据流
a1.sinks.k1.hdfs.fileType=DataStream
## 使用本地时间作为创建时间 如果false则是头部信息时间作为创建时间 (分桶) 文件名称是本地时间戳
a1.sinks.k1.hdfs.useLocalTimeStamp=true
##每五分钟生成一个目录:
##是否启用时间上的”舍弃”,这里的”舍弃”,类似于”四舍五入”,后面再介绍。如果启用,则会影响除了%t的其他所有时间表达式
a1.sinks.k1.hdfs.round=true
##时间上进行“舍弃”的值; 5分钟生成一个目录(分区)
a1.sinks.k1.hdfs.roundValue=5
##时间上进行”舍弃”的单位,包含:second,minute,hour
a1.sinks.k1.hdfs.roundUnit=minute
##定义Channel的类型
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
##组装source channel sink
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
连接HDFS导入数据,可以设置分区分桶,设置目录生成间隔时间
Flume连接案例
- 在master节点上
vim /usr/local/flume/apache-flume-1.11.0-bin/options/netcat2avro.conf
##定义a1的三个组件的名称
a1.sources = r1
a1.sinks = k1
a1.channels = c1
##定义Source的类型
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
##定义Channel的类型 基于内存的管道
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
##定义Sink的类型
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = 192.168.147.130
a1.sinks.k1.port = 55555
##组装source channel sink
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
- 在node2节点上
vim /usr/local/flume/apache-flume-1.11.0-bin/options/netcat2avro.conf
##定义a1的三个组件的名称
a1.sources = r1
a1.sinks = k1
a1.channels = c1
##定义Source的类型
a1.sources.r1.type = avro
a1.sources.r1.bind = 192.168.147.130
a1.sources.r1.port = 55555
##定义Channel的类型
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
##定义Sink的类型
a1.sinks.k1.type = logger
##组装source channel sink
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
- 启动master和node2的flume
[root@master ~]# flume-ng agent -n a1 -c conf -f ${FLUME_HOME}/options/netcat2avro.conf -
Dflume.root.logger=INFO,console
[root@node2 ~]# flume-ng agent -n a1 -c conf -f ${FLUME_HOME}/options/netcat2avro.conf -
Dflume.root.logger=INFO,console
- 在master使用telnet测试灌数据
telnet localhost 44444
负载均衡案例(轮询模式 先在资源比较充足的机器跑 跑完以后再在另外机器跑)
- Node1配置Agent
vim /usr/local/flume/apache-flume-1.11.0-bin/options/netcat2load_balance.conf
# 定义a1的三个组件的名称
a1.sources = r1
a1.channels = c1
a1.sinkgroups = g1
a1.sinks = k1 k2
# 定义负载均衡
a1.sinkgroups.g1.processor.type =load_balance
a1.sinkgroups.g1.processor.backoff = true
a1.sinkgroups.g1.processor.selector =round_robin
# 定义Source的类型
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
# 定义Sink的类型
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = 192.168.147.110
a1.sinks.k1.port = 33102
a1.sinks.k2.type = avro
a1.sinks.k2.hostname = 192.168.147.130
a1.sinks.k2.port = 33103
# 定义Channel的类型
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# 组装source channel sink
a1.sources.r1.channels = c1
a1.sinkgroups.g1.sinks = k1 k2
a1.sinks.k1.channel = c1
a1.sinks.k2.channel = c1
node1和node3配置Agent
- node1配置agent
vim /usr/local/flume/apache-flume-1.11.0-bin/options/netcat2load_balance.conf
# 定义a1的三个组件的名称
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# 定义Source的类型
a1.sources.r1.type = avro
a1.sources.r1.bind = 192.168.147.110
a1.sources.r1.port = 33102
# 定义Sink的类型
a1.sinks.k1.type = logger
# 定义Channel的类型
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# 组装source channel sink
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
- node2配置agent
vim /usr/local/flume/apache-flume-1.11.0-bin/options/netcat2load_balance.conf
# 定义a1的三个组件的名称
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# 定义Source的类型
a1.sources.r1.type = avro
a1.sources.r1.bind = 192.168.147.130
a1.sources.r1.port = 33103
# 定义Sink的类型
a1.sinks.k1.type = logger
# 定义Channel的类型
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# 组装source channel sink
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
- 启动flume服务
[root@master ~]# flume-ng agent -n a1 -c conf -f ${FLUME_HOME}/options/netcat2avro.conf -
Dflume.root.logger=INFO,console
[root@node2 ~]# flume-ng agent -n a1 -c conf -f ${FLUME_HOME}/options/netcat2avro.conf -
Dflume.root.logger=INFO,console
- master节点上使用telnet连接master:44444,模拟灌入数据
telnet localhost 44444
案例----故障转移----高可用
- master配置agent文件
vim /usr/local/flume/apache-flume-1.11.0-bin/options/exec2failover.conf
# 定义a1的三个组件的名称
a1.sources = r1
a1.channels = c1
a1.sinkgroups = g1
a1.sinks = k1 k2
# 定义Source的类型
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
# 设置sink组故障转移
a1.sinkgroups.g1.processor.type = failover
# 设置sink组中的sink的优先级,绝对值越大表示优先级越高,较高优先级值的Sink较早被激活。
a1.sinkgroups.g1.processor.priority.k1 = 100
a1.sinkgroups.g1.processor.priority.k2 = 200
# 失败的sink的最大退避时间(以毫秒为单位),默认是30000,也就是30秒
a1.sinkgroups.g1.processor.maxpenalty = 5000
# 定义Sink的类型
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = 192.168.147.110
a1.sinks.k1.port = 44102
a1.sinks.k2.type = avro
a1.sinks.k2.hostname = 192.168.147.130
a1.sinks.k2.port = 44103
# 定义Channel的类型
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# 组装source channel sink
a1.sources.r1.channels = c1
a1.sinkgroups.g1.sinks = k1 k2
a1.sinks.k1.channel = c1
a1.sinks.k2.channel = c1
node1和node2配置agent
- node1配置agent
vim /usr/local/flume/apache-flume-1.11.0-bin/options/exec2failover.conf
# 定义a1的三个组件的名称
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# 定义Source的类型
a1.sources.r1.type = avro
a1.sources.r1.bind = 192.168.147.110
a1.sources.r1.port = 44102
# 定义Sink的类型
a1.sinks.k1.type = logger
# 定义Channel的类型
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# 组装source channel sink
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
- node2配置agent
vim /usr/local/flume/apache-flume-1.11.0-bin/options/exec2failover.conf
# 定义a1的三个组件的名称
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# 定义Source的类型
a1.sources.r1.type = avro
a1.sources.r1.bind = 192.168.147.130
a1.sources.r1.port = 44103
# 定义Sink的类型
a1.sinks.k1.type = logger
# 定义Channel的类型
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# 组装source channel sink
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
- 启动flume
[root@node1 ~]# flume-ng agent -n a1 -c conf -f ${FLUME_HOME}/options/exec2failover.conf -Dflume.root.logger=INFO,console
[root@master ~]# flume-ng agent -n a1 -c conf -f ${FLUME_HOME}/options/exec2failover.conf -Dflume.root.logger=INFO,console
[root@node2 ~]# flume-ng agent -n a1 -c conf -f ${FLUME_HOME}/options/exec2failover.conf -Dflume.root.logger=INFO,console
- master节点上使用telnet连接master:44444,模拟灌入数据
telnet localhost 44444
设置的node2权重较高,先执行node2主机,如果node2宕机,会先报错,然后在node1执行,如果node2恢复了,依然是node2优先执行!
五、自定义拦截器

- 自定义Interceptor配置agent
##定义a1的三个组件的名称
a1.sources = r1
a1.sinks = k1
a1.channels = c1
##定义Source的类型
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
## 定义使用自定义拦截器
a1.sources.r1.interceptors=cs
a1.sources.r1.interceptors.cs.type=com.zwf.flume.HelloInterceptor1$Builder
a1.sources.r1.interceptors.cs.param=parameter
##定义Channel的类型
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
##定义Sink的类型
a1.sinks.k1.type = logger
##组装source channel sink
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
- 配置pom.xml
<dependency>
<groupId>org.apache.flume</groupId>
<artifactId>flume-ng-core</artifactId>
<version>1.11.0</version>
</dependency>
- 编写java
package com.zwf.flume;
import org.apache.flume.Context;
import org.apache.flume.Event;
import org.apache.flume.interceptor.Interceptor;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
/**
* @author MrZeng
* @version 1.0
* @date 2023-11-22 21:53
*/
public class HelloInterceptor1 implements Interceptor {
//过滤后Event集合
private List<Event> eventList=new ArrayList<>();
@Override
public void initialize() {
//初始化
System.out.println("拦截初始化……");
}
/**
* 从source中获取源数据参数
* @param list 源数据转化成List<Event>
* @return
*/
@Override
public List<Event> intercept(List<Event> list) {
eventList.clear();
for (Event event:list){
if(event!=null) {
//调用下面的方法
eventList.add(intercept(event));
}
}
return eventList;
}
/**
* 从source中获取源数据参数
* @param event 处理来自源数据中遍历一个个事件进行自定义处理
* @return
*/
@Override
public Event intercept(Event event) {
//获取请求头
Map<String, String> headers = event.getHeaders();
//获取请求信息
String body = new String(event.getBody());
//请求头加{length=字符串长度}
headers.put("length",String.valueOf(body.length()));
//请求体拼接"zwf-hadoop"字符串,由于字符串是不可变数组 需要把生成的临时变量设置在请求体中
event.setBody((body+"zwf-hadoop").getBytes());
return event;
}
@Override
public void close() {
System.out.println("事件关闭……");
}
public static class Builder implements Interceptor.Builder {
//通过该静态内部类来创建自定义对象供flume使用,实现Interceptor.Builder接口,并实现其抽象方法
@Override
public Interceptor build() {
return new HelloInterceptor1();
}
/**
*
* @param context 通过该对象可以获取flume配置自定义拦截器的参数
*/
@Override
public void configure(Context context) {
context.getParameters().entrySet().stream().forEach(System.out::println);
}
}
}
本文来自博客园,作者:戴莫先生Study平台,转载请注明原文链接:https://www.cnblogs.com/smallzengstudy/p/17856339.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号