
Spark Core快速入门
Spark-core快速入门
一、简介
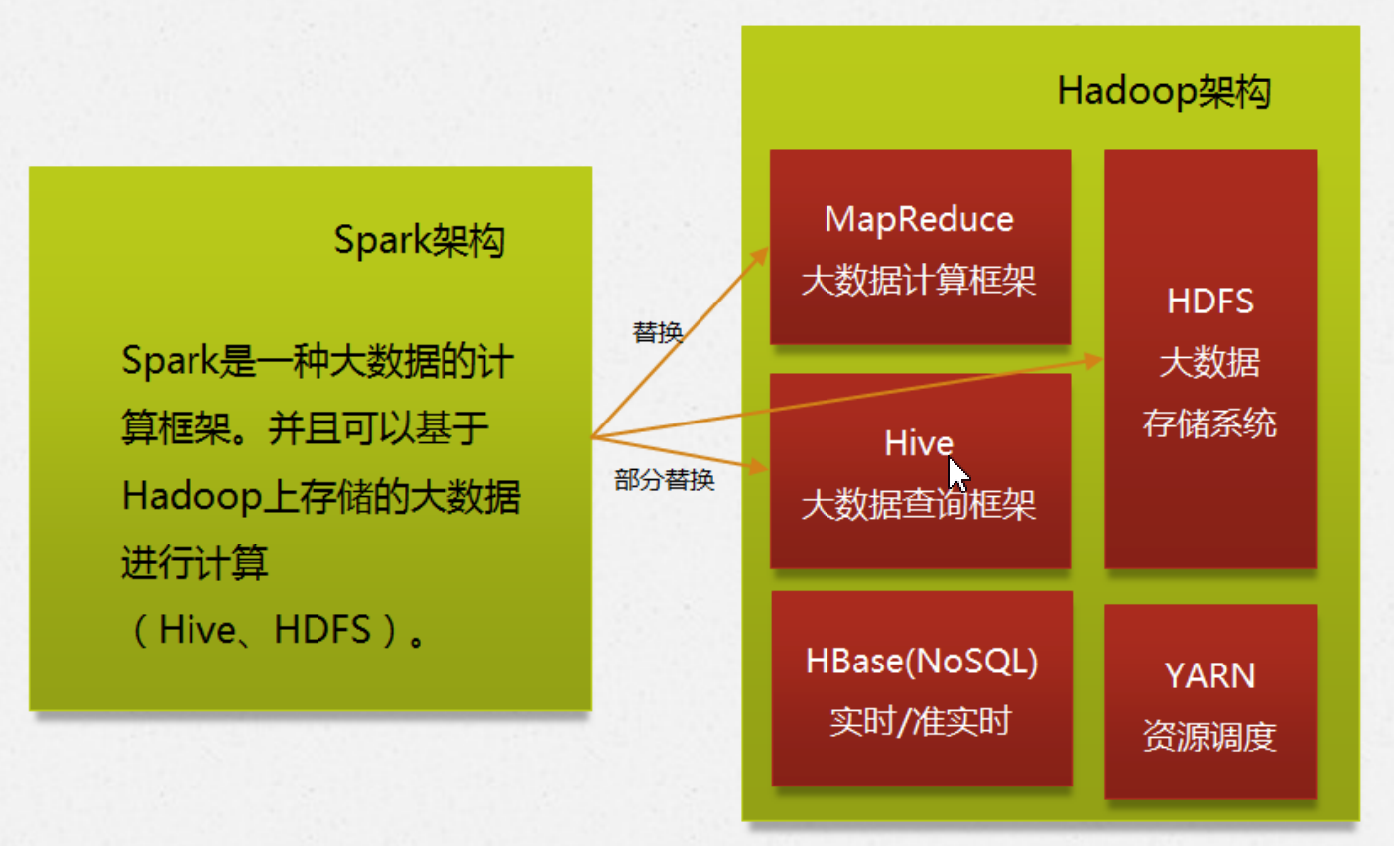
Apache spark是专门为大规模数据处理而设计的快速通用的计算模型,是一种类似于Mapreduce通用并行计算框架,与mapreduce不同的是,spark中间输出数据可以缓存在内存中,不需要读取HDFS,减少磁盘数据交互,spark也被称为基于内存的分布式计算框架。
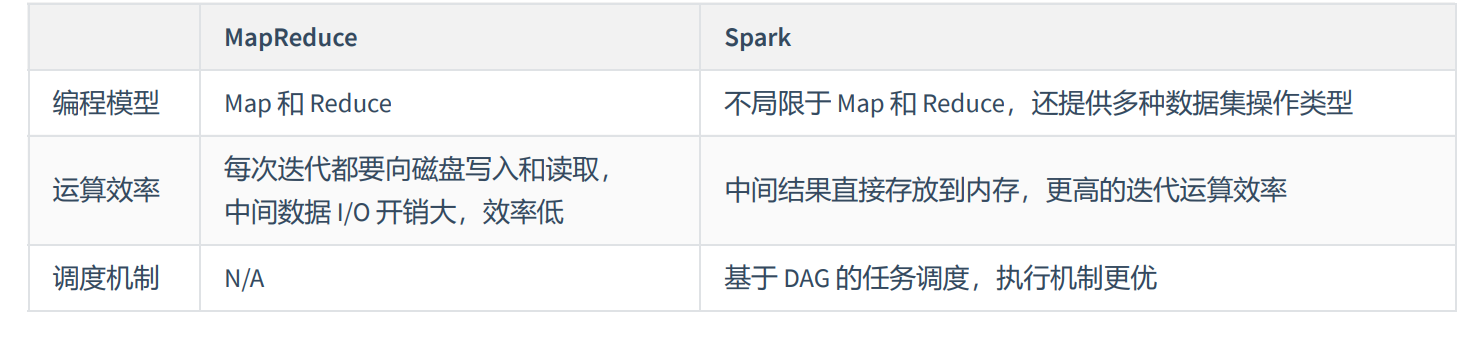
MapReduce只能做离线计算,如果复杂的计算逻辑,一个MR搞不定,需要把上一个MR的数据读取再重复做MR处理,这样就频繁读取HDFS,网络IO和磁盘IO就会成为性能瓶颈导致效率低下,因此spark和hadoop的根本差异是多个作业之间数据通信问题,spark多个作业数据通信是基于内存(spark中除了基于内存计算一个计算快的原因,还有DAG有向无环图来切分任务的执行先后顺序),而MR是基于磁盘。
spark不能完全取代MR,因为spark是基于内存操作的,可能因为内存不足造成OOM,导致任务失败,因此MapReduce是一个很好的选择。
特点:
快:spark是基于内存运算的,比MR快100倍,基于硬盘的运算也要快10倍。
易用:Spark支持scala、java、python、R和SQL多种语言,支持超过80种算子。
通用:spark提供了统一的解决方案。spark可以用于批处理、交互式查询、实时流计算、机器学习、图形计算。
Spark Core :核心组件。最基础与最核心的功能。用于离线数据处理,批量计算。
Spark SQL :交互式查询。用于操作结构化数据,通过 SQL 或者 Hive 的 HQL 来查询数据。
Spark Streaming :准实时流式计算。
Spark MLlib :机器学习。
Spark GraphX :图计算。
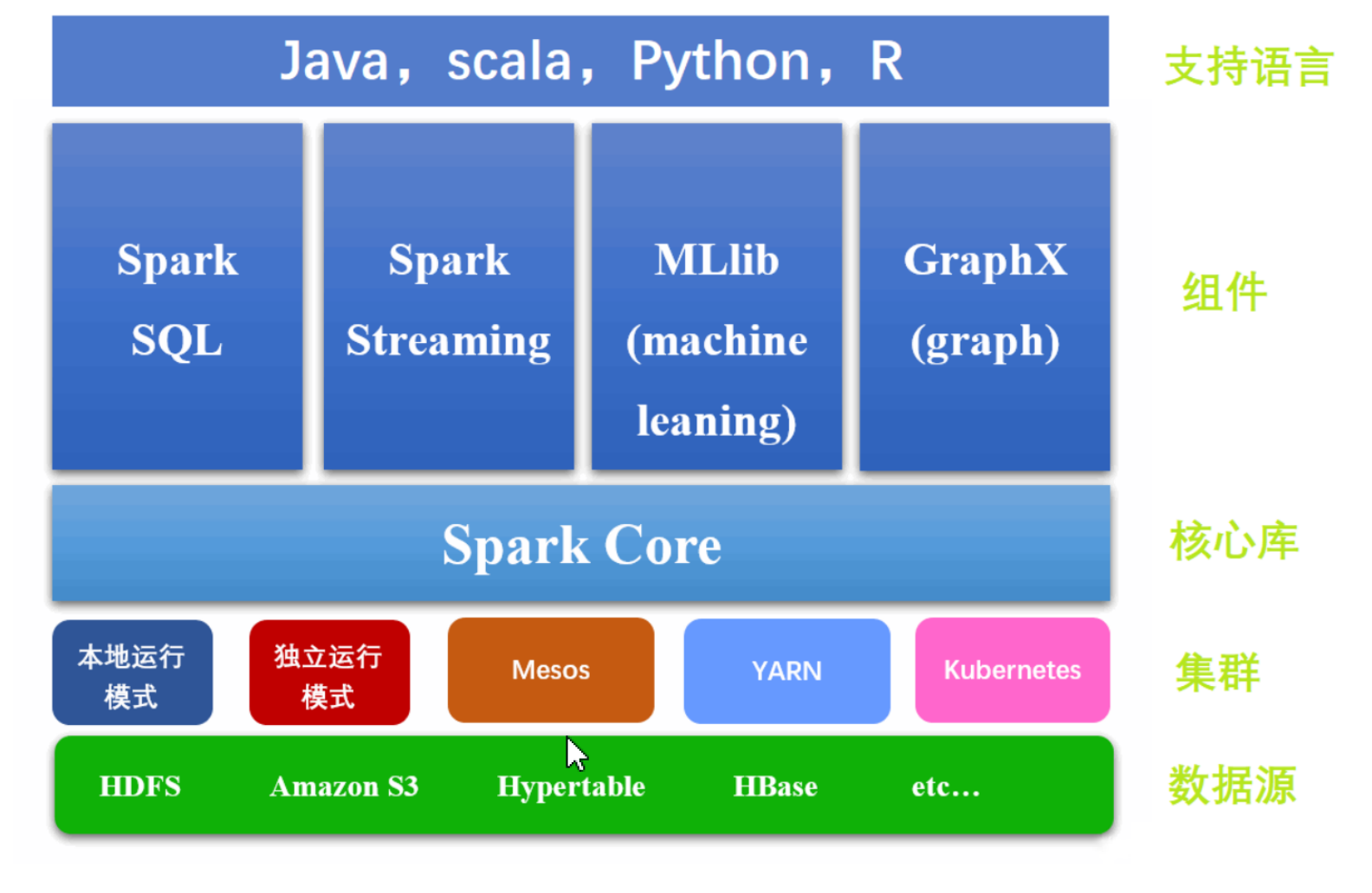
Mesos:Mesos 是一个集群管理器,与 YARN 功能类似,提供跨分布式应用或框架的资源隔离与共享,上面运行 Hadoop(一种 类似 Spark 的分布式系统基础架构)
YARN:最初是为 Hadoop 生态设计的资源管理器,能在上面运行 Hadoop、Hive、 Pig(Pig 是一种基于 Hadoop 平台的高级过程语言)、Spark 等应用框架。
Kubernetes:Kubernetes,简称 K8s,是用 8 代替了单词中间的 8 个字符“ubernete”而成的缩写。
- 运行模式
local:本地模式,就是不需要其他任何节点资源就可以在本地执行spark代码的环境,一般用于教学,调试,演示等。本地模式就是一个独立的进程,通过内部多个线程来模仿整个spark运行时环境。
standalone:独立模式。standalone是spark自带的一个资源调度框架,支持单节点和集群两种模式。
yarn:Hadoop的资源调度框架,spark也可以基于YARN来计算(将Spark中的各个角色以独立进程的形式存在)
mesos:类似YARN的一种资源管理框架,国内比较少使用。
kubernetes:K8s容器。spark中的各个角色运行在kubernetes的容器内部,并组成spark集群环境。
二、快速入门
- pom.xml文件
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>3.3.2</version>
</dependency>
- 准备数据
在项目根路径下创建 data 目录, data 目录下再创建 wordcount 目录, wordcount 目录下创建以下两文件。
wd1.txt
Hello Hadoop
Hello ZooKeeper
Hello Hadoop Hive
wd2.txt
Hello Hadoop HBase
Hive Scala Spark
- WordCount案例
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author MrZeng
* @date 2023-11-11 11:38
* @version 1.0
*/
object WordCountDemo {
//wordcount案例
def main(args: Array[String]): Unit = {
//初始化函数
val conf = new SparkConf()
//设置运行本地模式
conf.setMaster("local").setAppName("WordCount")
//根据配置对象初始化上下文对象
val sc = new SparkContext(conf)
//读取文件,按行读取
val v1: RDD[String] = sc.textFile("./data/wordcount")
//将空格拆分每一行数据 拆分一个个的单词
val v2: RDD[String] = v1.flatMap(w => w.split("\\s+"))
//将单词进行分组 Array[key->()]
val v3: RDD[(String, Iterable[String])] = v2.groupBy(v => v)
val v4: RDD[(String, Int)] = v3.map(kv => (kv._1, kv._2.size))
val array: Array[(String, Int)] = v4.take(10)
array.foreach(println)
//关闭连接 如果SC未停止 就停止SparkContext()
if(!sc.isStopped){
sc.stop()
}
}
}
- Log4J日志配置
Spark默认集成了Log4j作为日志架构,我们只需要在项目的resource文件夹下编写log4j.properties文件即可。
- log4j.properties模板详解
################################################################################
#rootLogger是新的使用名称,对应Logger类;rootCategory是旧的使用名称,对应原来的Category类。Logger类是
Category类的子类。
#①配置根Logger,其语法为:
#
#log4j.rootLogger = [level],appenderName,appenderName2,...
#level是日志记录的优先级,分为OFF,TRACE,DEBUG,INFO,WARN,ERROR,FATAL,ALL
##Log4j建议只使用四个级别,优先级从低到高分别是DEBUG,INFO,WARN,ERROR
#通过在这里定义的级别,您可以控制到应用程序中相应级别的日志信息的开关
#比如在这里定义了INFO级别,则应用程序中所有DEBUG级别的日志信息将不被打印出来
#appenderName就是指定日志信息输出到哪个地方。可同时指定多个输出目的
################################################################################
################################################################################
#②配置日志信息输出目的地Appender,其语法为:
#
#log4j.appender.appenderName = fully.qualified.name.of.appender.class
#log4j.appender.appenderName.optionN = valueN
#
#Log4j提供的appender有以下几种:
#1)org.apache.log4j.ConsoleAppender(输出到控制台)
#2)org.apache.log4j.FileAppender(输出到文件)
#3)org.apache.log4j.DailyRollingFileAppender(每天产生一个日志文件)
#4)org.apache.log4j.RollingFileAppender(文件大小到达指定尺寸的时候产生一个新的文件)
#5)org.apache.log4j.WriterAppender(将日志信息以流格式发送到任意指定的地方)
#
#1)ConsoleAppender选项属性
# -Threshold = DEBUG:指定日志消息的输出最低层次
# -ImmediateFlush = TRUE:默认值是true,所有的消息都会被立即输出
# -Target = System.err:默认值System.out,输出到控制台(err为红色,out为黑色)
#2)FileAppender选项属性
# -Threshold = INFO:指定日志消息的输出最低层次
# -ImmediateFlush = TRUE:默认值是true,所有的消息都会被立即输出
# -File = C:log4j.log:指定消息输出到C:log4j.log文件
# -Append = FALSE:默认值true,将消息追加到指定文件中,false指将消息覆盖指定的文件内容
# -Encoding = UTF-8:可以指定文件编码格式
#
#3)DailyRollingFileAppender选项属性
# -Threshold = WARN:指定日志消息的输出最低层次
# -ImmediateFlush = TRUE:默认值是true,所有的消息都会被立即输出
# -File = C:log4j.log:指定消息输出到C:log4j.log文件
# -Append = FALSE:默认值true,将消息追加到指定文件中,false指将消息覆盖指定的文件内容
# -DatePattern='.'yyyy-ww:每周滚动一次文件,即每周产生一个新的文件。还可以按用以下参数:
# '.'yyyy-MM:每月
# '.'yyyy-ww:每周
# '.'yyyy-MM-dd:每天
# '.'yyyy-MM-dd-a:每天两次
# '.'yyyy-MM-dd-HH:每小时
# '.'yyyy-MM-dd-HH-mm:每分钟
# -Encoding = UTF-8:可以指定文件编码格式
#
#4)RollingFileAppender选项属性
# -Threshold = ERROR:指定日志消息的输出最低层次
# -ImmediateFlush = TRUE:默认值是true,所有的消息都会被立即输出
# -File = C:/log4j.log:指定消息输出到C:/log4j.log文件
# -Append = FALSE:默认值true,将消息追加到指定文件中,false指将消息覆盖指定的文件内容
# -MaxFileSize = 100KB:后缀可以是KB,MB,GB.在日志文件到达该大小时,将会自动滚动.如:log4j.log.1
# -MaxBackupIndex = 2:指定可以产生的滚动文件的最大数
# -Encoding = UTF-8:可以指定文件编码格式
################################################################################
################################################################################
#③配置日志信息的格式(布局),其语法为:
#
#log4j.appender.appenderName.layout = fully.qualified.name.of.layout.class
#log4j.appender.appenderName.layout.optionN = valueN
#
#Log4j提供的layout有以下几种:
#5)org.apache.log4j.HTMLLayout(以HTML表格形式布局)
#6)org.apache.log4j.PatternLayout(可以灵活地指定布局模式)
#7)org.apache.log4j.SimpleLayout(包含日志信息的级别和信息字符串)
#8)org.apache.log4j.TTCCLayout(包含日志产生的时间、线程、类别等等信息)
#9)org.apache.log4j.xml.XMLLayout(以XML形式布局)
#
#5)HTMLLayout选项属性
# -LocationInfo = TRUE:默认值false,输出java文件名称和行号
# -Title=Struts Log Message:默认值 Log4J Log Messages
#
#6)PatternLayout选项属性
# -ConversionPattern = %m%n:格式化指定的消息(参数意思下面有)
#
#9)XMLLayout选项属性
# -LocationInfo = TRUE:默认值false,输出java文件名称和行号
#
#Log4J采用类似C语言中的printf函数的打印格式格式化日志信息,打印参数如下:
# %m 输出代码中指定的消息
# %p 输出优先级,即DEBUG,INFO,WARN,ERROR,FATAL
# %r 输出自应用启动到输出该log信息耗费的毫秒数
# %c 输出所属的类目,通常就是所在类的全名
# %t 输出产生该日志事件的线程名
# %n 输出一个回车换行符
# %d 输出日志时间点的日期或时间,默认格式为ISO8601,也可以在其后指定格式
# 如:%d{yyyy年MM月dd日 HH:mm:ss,SSS},输出类似:2012年01月05日 22:10:28,921
# %l 输出日志事件的发生位置,包括类目名、发生的线程,以及在代码中的行数
# 如:Testlog.main(TestLog.java:10)
# %F 输出日志消息产生时所在的文件名称
# %L 输出代码中的行号
# %x 输出和当前线程相关联的NDC(嵌套诊断环境),像java servlets多客户多线程的应用中
# %% 输出一个"%"字符
#
# 可以在%与模式字符之间加上修饰符来控制其最小宽度、最大宽度、和文本的对齐方式。如:
# %5c: 输出category名称,最小宽度是5,category<5,默认的情况下右对齐
# %-5c:输出category名称,最小宽度是5,category<5,"-"号指定左对齐,会有空格
# %.5c:输出category名称,最大宽度是5,category>5,就会将左边多出的字符截掉,<5不会有空格
# %20.30c:category名称<20补空格,并且右对齐,>30字符,就从左边交远销出的字符截掉
################################################################################
################################################################################
#④指定特定包的输出特定的级别
#log4j.logger.org.springframework=DEBUG
################################################################################
#OFF,systemOut,logFile,logDailyFile,logRollingFile,logMail,logDB,ALL
log4j.rootLogger =ALL,systemOut,logFile,logDailyFile,logRollingFile,logMail,logDB
#输出到控制台
log4j.appender.systemOut = org.apache.log4j.ConsoleAppender
log4j.appender.systemOut.layout = org.apache.log4j.PatternLayout
log4j.appender.systemOut.layout.ConversionPattern = [%-5p][%-22d{yyyy/MM/dd HH:mm:ssS}][%l]%n%m%n
log4j.appender.systemOut.Threshold = DEBUG
log4j.appender.systemOut.ImmediateFlush = TRUE
log4j.appender.systemOut.Target = System.out
#输出到文件
log4j.appender.logFile = org.apache.log4j.FileAppender
log4j.appender.logFile.layout = org.apache.log4j.PatternLayout
log4j.appender.logFile.layout.ConversionPattern = [%-5p][%-22d{yyyy/MM/dd HH:mm:ssS}][%l]%n%m%n
log4j.appender.logFile.Threshold = DEBUG
log4j.appender.logFile.ImmediateFlush = TRUE
log4j.appender.logFile.Append = TRUE
log4j.appender.logFile.File = ../log4j_spark.log
log4j.appender.logFile.Encoding = UTF-8
#按DatePattern输出到文件
log4j.appender.logDailyFile = org.apache.log4j.DailyRollingFileAppender
log4j.appender.logDailyFile.layout = org.apache.log4j.PatternLayout
log4j.appender.logDailyFile.layout.ConversionPattern = [%-5p][%-22d{yyyy/MM/dd HH:mm:ssS}][%l]%n%m%n
log4j.appender.logDailyFile.Threshold = DEBUG
log4j.appender.logDailyFile.ImmediateFlush = TRUE
log4j.appender.logDailyFile.Append = TRUE
log4j.appender.logDailyFile.File = ../log4j_spark
log4j.appender.logDailyFile.DatePattern = '.'yyyy-MM-dd-HH-mm'.log'
log4j.appender.logDailyFile.Encoding = UTF-8
#设定文件大小输出到文件
log4j.appender.logRollingFile = org.apache.log4j.RollingFileAppender
log4j.appender.logRollingFile.layout = org.apache.log4j.PatternLayout
log4j.appender.logRollingFile.layout.ConversionPattern = [%-5p][%-22d{yyyy/MM/dd HH:mm:ssS}][%l]%n%m%n
log4j.appender.logRollingFile.Threshold = DEBUG
log4j.appender.logRollingFile.ImmediateFlush = TRUE
log4j.appender.logRollingFile.Append = TRUE
log4j.appender.logRollingFile.File = ../Struts2/WebRoot/log/RollingFile/log4j_Struts.log
log4j.appender.logRollingFile.MaxFileSize = 1MB
log4j.appender.logRollingFile.MaxBackupIndex = 10
log4j.appender.logRollingFile.Encoding = UTF-8
#用Email发送日志
log4j.appender.logMail = org.apache.log4j.net.SMTPAppender
log4j.appender.logMail.layout = org.apache.log4j.HTMLLayout
log4j.appender.logMail.layout.LocationInfo = TRUE
log4j.appender.logMail.layout.Title = Struts2 Mail LogFile
log4j.appender.logMail.Threshold = DEBUG
log4j.appender.logMail.SMTPDebug = FALSE
log4j.appender.logMail.SMTPHost = SMTP.163.com
log4j.appender.logMail.From = admin@163.com
log4j.appender.logMail.To = admin@gmail.com
#log4j.appender.logMail.Cc = admin@gmail.com
#log4j.appender.logMail.Bcc = admin@gmail.com
log4j.appender.logMail.SMTPUsername = admin
log4j.appender.logMail.SMTPPassword = 123456
log4j.appender.logMail.Subject = Log4j Log Messages
#log4j.appender.logMail.BufferSize = 1024
#log4j.appender.logMail.SMTPAuth = TRUE
#将日志写入到MySQL数据库
log4j.appender.logDB = org.apache.log4j.jdbc.JDBCAppender
log4j.appender.logDB.layout = org.apache.log4j.PatternLayout
log4j.appender.logDB.Driver = com.mysql.jdbc.Driver
log4j.appender.logDB.URL = jdbc:mysql://127.0.0.1:3306/log
log4j.appender.logDB.User = root
log4j.appender.logDB.Password = 123456
log4j.appender.logDB.Sql = INSERT
INTOT_log4j(project_name,create_date,level,category,file_name,thread_name,line,all_category,message)va
lues('Struts2','%d{yyyy-MM-ddHH:mm:ss}','%p','%c','%F','%t','%L','%l','%m')
也可以通过代码
sparkContext.setLogLevel("WARN")直接进行设置。
val sc = new SparkContext("local", "WordCount")
sc.setLogLevel("WARN")
三、运行架构
spark有多种运行模式,可以运行在一台机器上,称为本地模式,也可以使用spark自带的资源调度系统,称为Spark Standalone模式,还可以以Yarn和Mesos作为底层资源调度系统以分布式的方式在集群中运行。
spark是一个计算引擎,整体来说,它采用了标准的Master-Slave结构。Driver表示master,负责整个集群中的作业任务调度,图中的Executor表示slave,负责具体执行任务。无论什么运行模式都会存在这些角色,只是在不同的运行环境下,这些角色的分布会有所不同。

而集群模式又根据 Driver 运行在哪被划分为 Client 模式和 Cluster 模式:
--master :决定了 Spark 任务提交给哪种模式处理,默认为 local。
--deploy-mode :决定了 Driver 的运行方式(运行在哪里),可选值为 client 或 cluster,默认为 client。

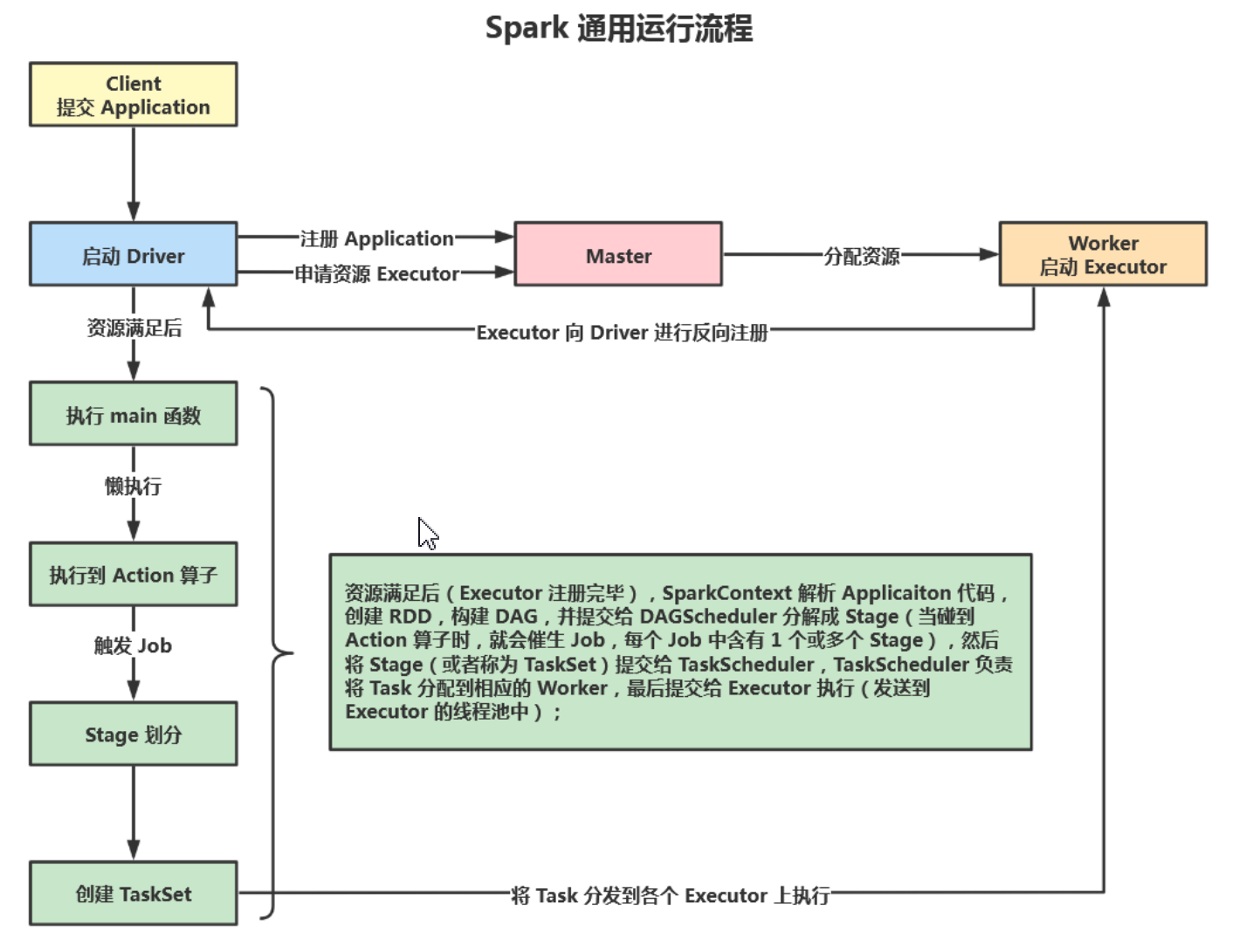
- Spark通用执行流程
client提交application,根据不同的运行模式在不同的位置创建Driver进程,sparkContext连接到Master,向Master注册应用并申请资源(Executor的CPU core和Memory),Master根据SparkContext的资源申请并根据Worker心跳周期内报告的信息决定在哪个Worker上分配资源,也就是Executor,worer节点创建Executor进程,Executor进行反向注册。executor注册完毕后,sparkContext解析Application代码,创建RDD,构建DAG,并提交给DAGSchedule分解程stage,当碰到行动算子时,就会催生Job,每个job含有一个或多个stage,然后将stage提交给TaskScheduler,TaskScheduler负责将Task分配给相应的Worker,最后提交给Executor执行。Executor启动多线程执行来对RDD进行并行计算,并向SparkContext报告,直到Task完成。所有Task完成后,SparkContext向Master注销,释放资源。
- 粗粒度资源申请
Spark 会在 Application 执行之前,将所有的资源申请完毕,当资源申请成功后,才会进行任务的调度,当所有的 Task 执行完成后,才会释放这部分资源。
- 细粒度资源申请
MapReduce 在 Application 执行之前不需要去提前申请资源,而是直接执行,让 Job 中的每一个 Task 在执行前 自己去申请资源, Task 执行完成就立刻释放资源。
- 本地模式
所谓的Local模式,就是不需要其他任何节点资源就可以在本地执行spark代码的环境,一般用于教学,调试,演示。
Local模式在运行时,又分为Local和Local culster
Local:最简单的本地模式
Local-cluster:本地伪分布式模式

四、Yarn模式
Yarn是hadoop的资源调度框架,spark也可以基于Yarn来计算(将spark应用提交到Yarn上运行)。spark端直接连接Yarn,不需要额外构建Spark集群,国内使用比较多。spark中的各个角色运行在Yarn的容器内部,并组成Spark集群环境。
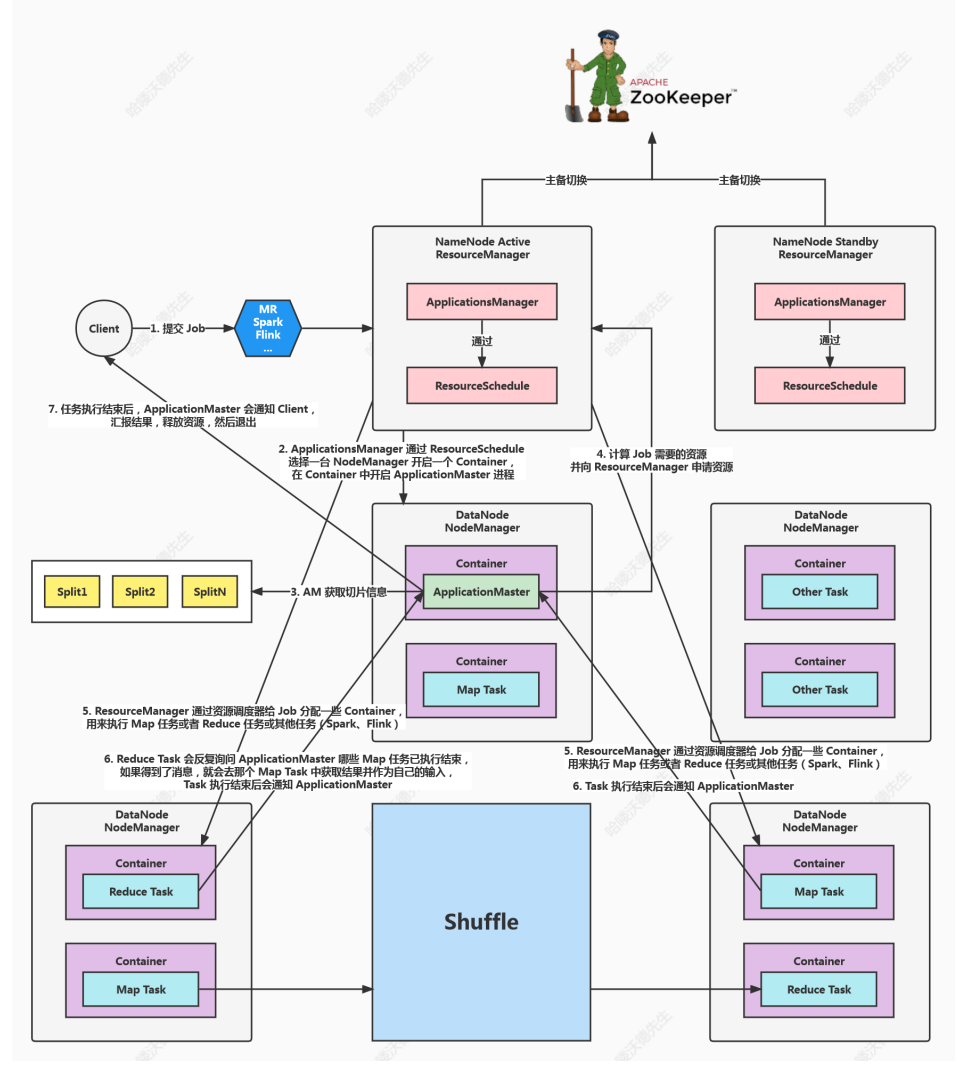
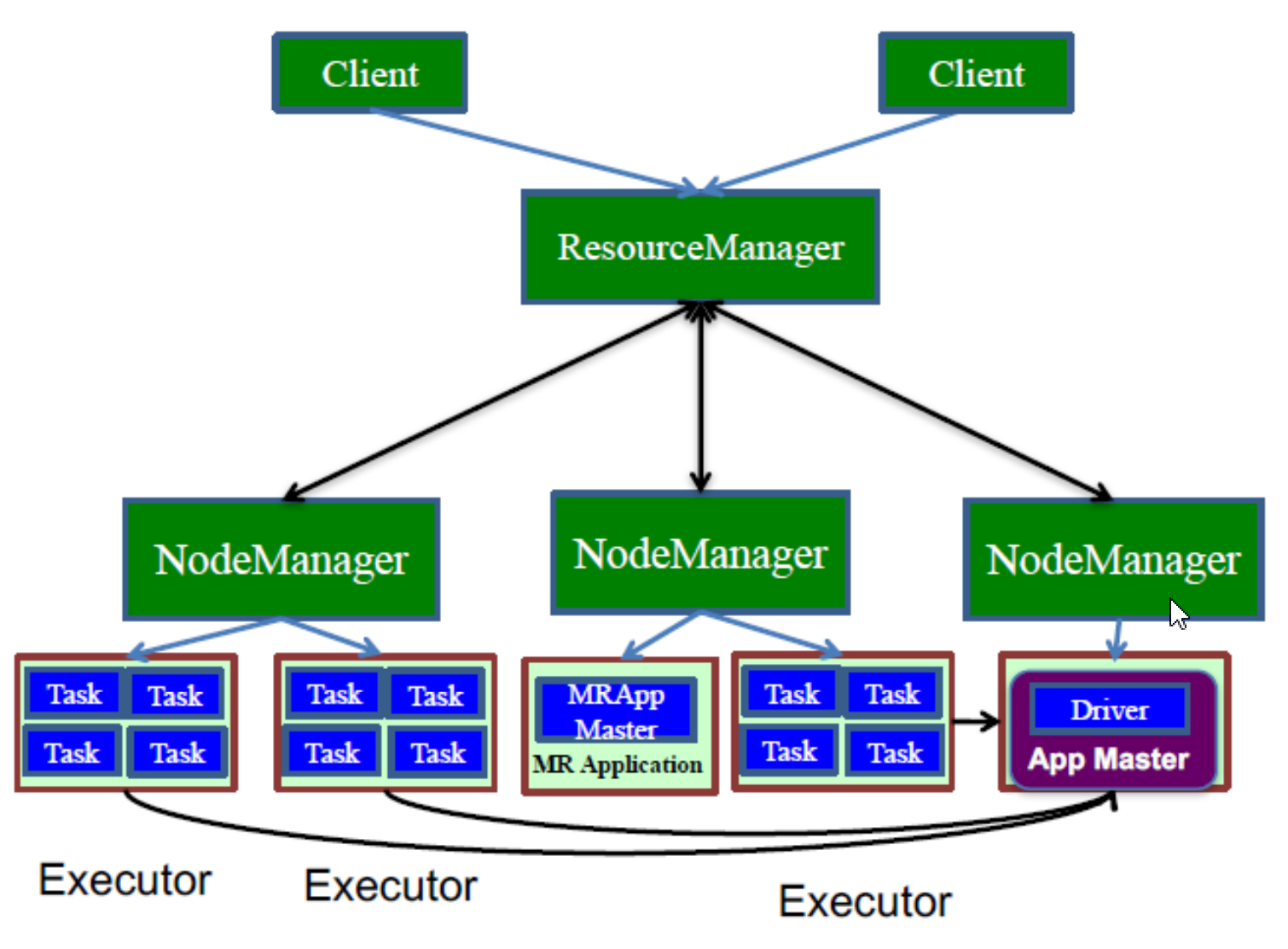
1、Spark-Yarn cluster
第一阶段:Spark的Driver作为一个ApplicationMaster在Yarn集群中先启动。
第二阶段:ApplicationMaster向ResourceManager申请资源,启动Executor运行Task,同时监控它的整个过程
ResourceManager收到请求后为ApplicationMaster申请一个container启动,applicationMaster同时启动Sparkcontext,applicationMaster向ResourceManager注册,采用轮询的方式为各个任务申请资源(分发任务)通,并监控它们的运行状态,Applicationmaster获取资源后与NodeManager信,要求NodeManger接收到Task后立即执行,并向AplicationMaster反馈运行状态和进度(反向注册),开始执行任务,执行完成后Applicationmaster向ResourceManager申请关闭自己。
分发任务时:driver把一个个job分成多个stage,并把stage中的多个Task封装成TaskSet并通过TaskSchedule
分发任务到不同的Executor中。
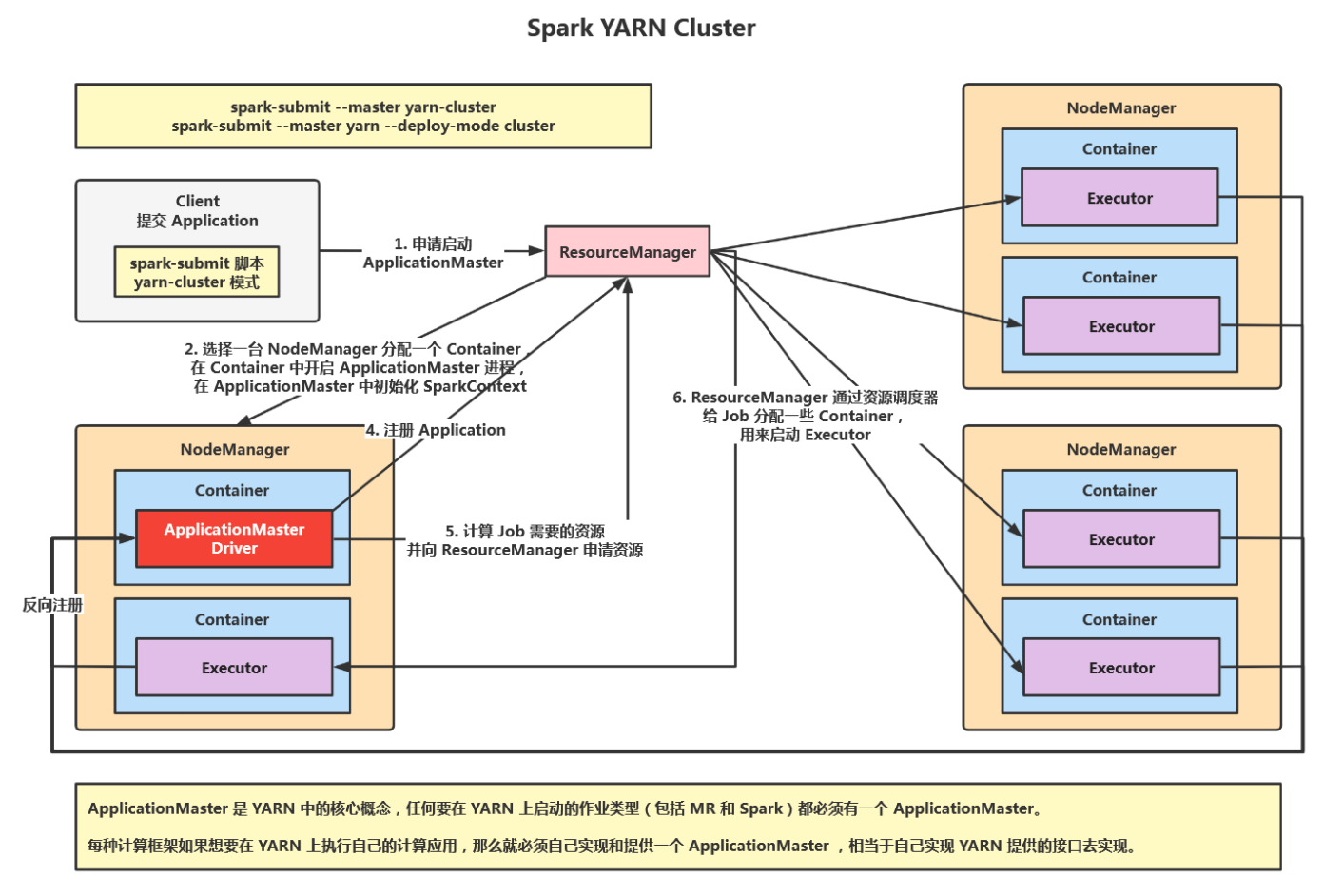
2、Spark-Yarn client
在Yarn client模式下,Driver在应用提交的本地机器运行,Driver启动后会和ResourceManager通讯申请启动Applicationmaster,ResourceManager收到请求后,通过ResourceSchedule选择一台NodeManager分配一个Container,在Container中打开ApplicationMaster进程,Driver中Sparkcontext初始化完毕后,与ApplicationMaster建立通讯,向ResourceManager注册应用,然后ApplicationMaster计算Job所需的资源向ResourceManager申请资源,ResourceManager通过资源调度器给Job分配Container,ApplicationMaster申请到资源后,便与对应的NodeManager通信,启动后Executor向Driver中SparkContext反向注册并申请Task,并执行Task任务,同时向Driver汇报运行状态和进度,方便Driver随时掌握各个任务的运行状态,应用程序运行完后,Driver的SparkContext向ResourceManager申请注销并关闭自己。
注意: ApplicationMaster 在 YARN Client 模式下没有作业调度的功能。因为该模式下,Application 的注册与 Job 和 Stoge 的划分以及 Task 的创建、分配和调度都是 Driver 负责的,而ApplicationMaster(ExecutorLauncher ) 只负责了 Executor 资源的申请。原因就是因为在 YARN Client 模式下,Driver 在应用提交的本地机器上运行。
五、Spark-Yarn集群环境搭建
1、检查环境
搭建之前先确定Java(8)和scala(2.12.X)环境。三台服务器都要安装scala和java8,java8安装见Linux文档。
rpm -ivh scala-2.12.17.rpm
通过whereis scala命令查询scala的安装目录。
[root@node01 ~]# whereis scala
scala: /usr/bin/scala /usr/share/scala /usr/share/man/man1/scala.1.gz
三个节点修改环境变量
vim /etc/profile,在文末结尾添加以下内容:
export SCALA_HOME=/usr/share/scala
export PATH=$SCALA_HOME/bin:$PATH
修改完成后
source /etc/profile重新加载环境变量。
配置完成后检查环境
java -version
scala -version
2、local本地模式
所谓的local模式,就是不需要其他任何节点资源就可以在本地执行Spark代码的环境,一般用于教学,调试,演示等。本地模式就是一个独立的进程,通过其内部多个线程来模拟整个Spark运行时环境,每个线程代表一个Worker。
- 上传解压
将Spark安装包上传至服务器,解压后重命名为Spark-local
mkdir -p /usr/local/spark-local
tar -zxvf spark-XXX-bin-hadoop3.tagz -C /usr/local/spark-local/
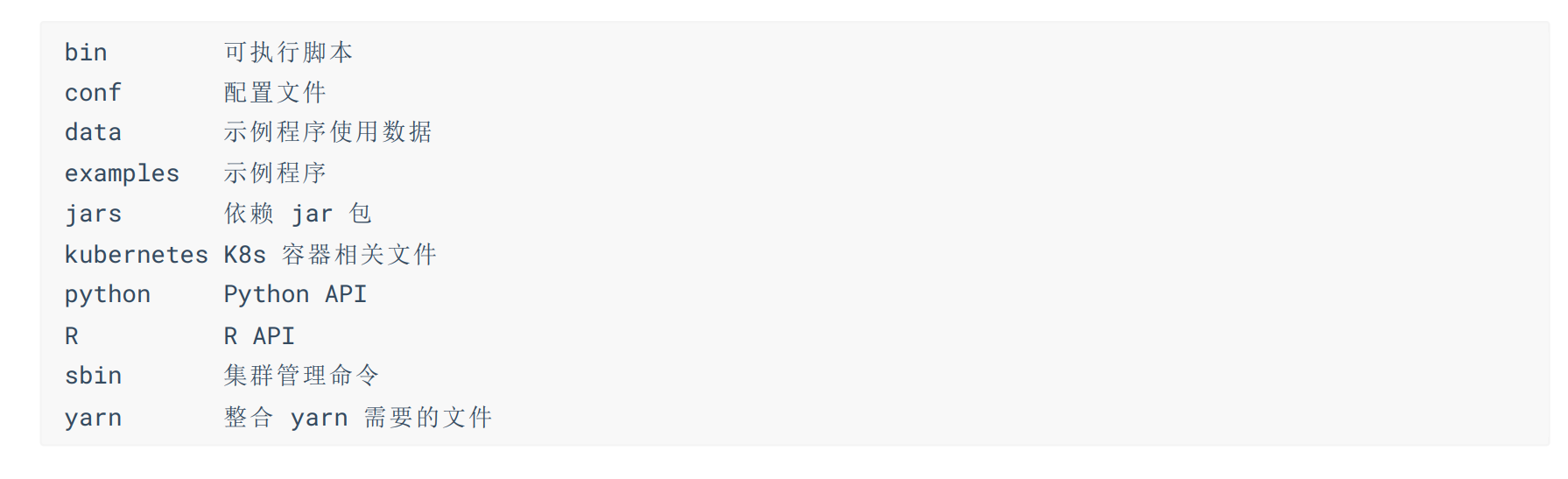
各个解压目录说明:
如果想要在本地模式上,把文件上传到HDFS上,还需要配置以下信息(可选)
cd /usr/local/spark-local/spark-XXX-bin-hadoop3/conf/
cp spark-env.sh.template spark-env.sh
vim spark-env.sh
在脚本文末加上以下
export JAVA_HOME=/usr/local/java/jdk1.8
export HADOOP_HOME=/usr/local/hadoop/hadoop-3.3.4
HADOOP_CONF_DIR=/usr/local/hadoop/hadoop-3.3.4/etc/hadoop
SPARK_DIST_CLASSPATH=$(/opt/yjx/hadoop-3.3.4/bin/hadoop classpath)
在linux找个目录,存放本地数据文件
- 启动本地模式服务
cd /usr/local/spark-local/spark-XXX/bin #切换到命令目录
./spark-shell #启动spark-shell控制台,登录本地模式
- 测试WordCount程序
sc.textFile("file:///opt/yjx/spark-local/data/wordcount").flatMap(_.split("\\s+")).map(_ ->1).reduceByKey(_ + _).take(10)
-
注意:加载 HDFS 文件和本地文件都是使用 textFile,区别是通过前缀( hdfs:// 和 file:// )进行标识。
-
访问:http://node2:4040/ 历史服务器结果如下。
- 退出控制台
:quit
Spark还支持直接打成jar包提交应用,通过spark-submit来实现(spark根目录下)
bin/spark-submit \
--master local[*] \
--executor-memory 1G \
--class org.apache.spark.examples.SparkPi \
./examples/jars/spark-examples_2.12-3.3.2.jar \
10
bin/spark-submit \
--master local-cluster[2,1,1024] \
--executor-memory 1G \
--class org.apache.spark.examples.SparkPi \
./examples/jars/spark-examples_2.12-3.3.2.jar \
10
- 各个参数的解释文档

如果想要自定义程序,打成jar包运行,参考以下例子:
- 导入依赖
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>3.3.2</version>
</dependency>
- 编码
package com.zwf.word
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author MrZeng
* @date 2023-11-11 11:38
* @version 1.0
*/
object WordCountDemo {
//wordcount案例
def main(args: Array[String]): Unit = {
//初始化函数
val conf = new SparkConf()
//设置运行本地模式
conf.setMaster("local").setAppName("WordCount")
//根据配置对象初始化上下文对象
val sc = new SparkContext(conf)
//读取文件,按行读取
val v1: RDD[String] = sc.textFile("./data/wordcount")
//将空格拆分每一行数据 拆分一个个的单词
val v2: RDD[String] = v1.flatMap(w => w.split("\\s+"))
//将单词进行分组 Array[key->()]
val v3: RDD[(String, Iterable[String])] = v2.groupBy(v => v)
val v4: RDD[(String, Int)] = v3.map(kv => (kv._1, kv._2.size))
val array: Array[(String, Int)] = v4.take(10)
array.foreach(println)
//关闭连接 如果SC未停止 就停止SparkContext()
if(!sc.isStopped){
sc.stop()
}
}
}
打包上传到服务器/root目录下,并执行以下命令
bin/spark-submit \
--master local[*] \
--executor-memory 1G \
--class com.zwf.word.WordCountDemo \
/root/WordCountDemo-1.0-SNAPSHOT.jar
读取HDFS文件
当 Spark 配置了 Hadoop 环境以后,在 spark-shell中 sc.textFile(path) 默认就会读取HDFS文件(不配置时默认读取本地文件系统),此时如果需要读取本地文件,需要添加 file:// 前缀。在读取 HDFS 文件时,path 如果不加 / ,默认读取 hdfs://hdfs-zwf/user/root ,如果加了 / ,从 HDFS 根路径开始读取,也就是hdfs://hdfs-zwf 。
提示:hdfs://hdfs-yjx 是 Hadoop 的 core-site.xml 配置文件中 fs.defaultFS 属性的值。
# path 如果不加`/`,默认读取`hdfs://hdfs-zwf/user/root`
sc.textFile("data/wordcount").flatMap(_.split("\\s+")).map(_ -> 1).reduceByKey(_ + _).take(10)
# path 如果加了`/`,从 HDFS 根路径开始读取,也就是`hdfs://hdfs-zwf`
sc.textFile("/data/wordcount").flatMap(_.split("\\s+")).map(_ -> 1).reduceByKey(_ + _).take(10)
# 使用 hdfs:// 前缀从指定位置读取(推荐使用)
sc.textFile("hdfs://hdfs-yjx/data/wordcount").flatMap(_.split("\\s+")).map(_ -> 1).reduceByKey(_ +_).take(10)
3、YARN模式
独立部署由Spark提供自身提供计算资源,无其他框架提供资源,但这种方式降低了和其他第三方资源框架的耦合性,独立性非常强。但是spark主要是计算引擎,而不是资源调度框架,所以本身提供的资源调度并不是它的强项,因此我们需要利用Yarn集群整合Spark。
- 上传文件
将spark安装包上传到服务器,解压重命名为Spark-3.3.2。
tar -zxvf spark-3.3.2-bin-hadoop3.tgz -C /usr/local/spark-yarn/
mv /opt/yjx/spark-3.3.2-bin-hadoop3/ /usr/local/spark-yarn/
解压目录说明
bin 可执行脚本
conf 配置文件
data 示例程序使用数据
examples 示例程序
jars 依赖 jar 包
kubernetes k8s 容器相关文件
python Python API
R R API
sbin 集群管理命令
yarn 整合 yarn 需要的文件
修改配置文件
- 修改Hadoop的Yarn-site.xml文件(三台机器都需要修改)
vim /usr/local/hadoop/hadoop-3.3.4/etc/hadoop/yarn-site.xml
- 添加以下内容
<!-- 设置是否对容器强制执行物理内存限制 -->
<!-- 是否启动一个线程检查每个任务正在使用的物理内存量,如果任务超出分配值,则将其直接杀掉,默认为 true -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<!-- 设置是否对容器强制执行虚拟内存限制 -->
<!-- 是否启动一个线程检查每个任务正在使用的虚拟内存量,如果任务超出分配值,则将其直接杀掉,默认为 true -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
- 修改Spark-env.sh环境配置脚本文件
cd /usr/local/spark-yarn/spark-3.3.2-bin-hadoop3/conf
cp spark-env.sh.template spark-env.sh
vim spark-env.sh
- 在文件末尾添加以下内容
export JAVA_HOME=/usr/local/java/jdk1.8.0_351
export HADOOP_HOME=/usr/lcoal/hadoop/hadoop-3.3.4
HADOOP_CONF_DIR=/usr/local/hadoop/hadoop-3.3.4/etc/hadoop
YARN_CONF_DIR=/usr/local/hadoop/hadoop-3.3.4/etc/hadoop
SPARK_DIST_CLASSPATH=$(/opt/yjx/hadoop-3.3.4/bin/hadoop classpath)
- 配置历史服务
由于Spark-shell停止后,集群监控的4040页面就无法访问了,导致历史任务的运行情况也无法得知,所以开发时为了便于查看一般会配置历史服务器记录任务运行情况。
- 修改Spark-defaults.conf配置文件(在spark解压包中的conf目录下)
cp spark-defaults.conf.template spark-defaults.conf
vim spark-defaults.conf
- 在文件末尾添加以下内容
# 开启记录事件日志的功能
spark.eventLog.enabled true
# 设置事件日志存储的目录。注意:配置的 HDFS 路径要存在
spark.eventLog.dir hdfs://hdfs-zwf/spark-logs
spark.history.fs.logDirectory hdfs://hdfs-zwf/spark-logs
# 日志优化选项,压缩日志
spark.eventLog.compress true
# 历史服务器与 YARN 关联
spark.yarn.historyServer.address=node2:16066
# 历史服务器 WEBUI 访问端口
spark.history.ui.port=16066
- 修改spark-env.sh环境配置脚本文件
vim spark-env.sh
- 在文件末尾添加以下内容
SPARK_HISTORY_OPTS="
-Dspark.history.ui.port=16066
-Dspark.history.fs.logDirectory=hdfs://hdfs-zwf/spark-logs
-Dspark.history.retainedApplications=30"

- 将配置好的spark分发到其他节点上。(如果需要三个节点都运行spark任务就执行这一步)
scp -r root@node2:/usr/local/spark/spark-yarn/spark-3.3.2 /usr/local/spark/spark-yarn/
scp -r root@master:/usr/local/spark/spark-yarn/spark-3.3.2 /usr/local/spark/spark-yarn/
- 启动服务
启动Zookeeper(三台启动都要启动)
zkServer.sh start
zkServer.sh status
启动hadoop集群并在HDFS中创建spark-logs目录
start-all.sh
hdfs dfs -mkdir -p /spark-logs
启动YARN历史服务
mapred --daemon start historyserver
启动spark历史服务
cd /usr/lcoal/spark-yarn/spark-3.3.2-hadoop3/
sbin/start-history-server.sh
- 提交应用(测试集群环境)
# yarn-client 模式在当前运行节点控制台即可看到日志信息,方便测试调试程序
bin/spark-submit \
--master yarn \
--executor-memory 1G \
--executor-cores 1 \
--class org.apache.spark.examples.SparkPi \
./examples/jars/spark-examples_2.12-3.3.2.jar \
10
# yarn-cluster 模式需要通过 YARN 历史服务或者通过 Spark 历史服务查看日志
bin/spark-submit \
--master yarn \
--deploy-mode cluster \
--executor-memory 1G \
--executor-cores 1 \
--class org.apache.spark.examples.SparkPi \
./examples/jars/spark-examples_2.12-3.3.2.jar \
10
访问 YARN 集群结果如下,点击最后的 History 即可查看通过 Spark 历史服务查看日志。
在浏览器中访问http://node2:19888即可查看历史记录,任务处理进度
- 关闭服务
先关闭历史服务器、再关闭hadoop集群、最后关闭zookeeper集群
mapred --daemon stop historyserver #关闭历史服务器
sbin/stop-history-server.sh #关闭spark历史服务器
stop-all.sh #关闭hadoop集群服务
zKServer.sh stop #三个节点都要关闭zk服务
关机拍快照
- spark任务提交参数如下(通用参数):

YARN集群独有的参数


六、核心编程
1、RDD概念
Spark计算框架为了能够进行高并发和高吞吐的数据处理,封装了三大数据结构,用于处理不同的应用场景。三大数据结构分别是:
RDD:弹性分布式数据集,是一个读取分区记录的集合,是 Spark 对需要处理的数据的基本抽象。
广播变量:分布式共享只读变量。
累加器:分布式共享只写变量。
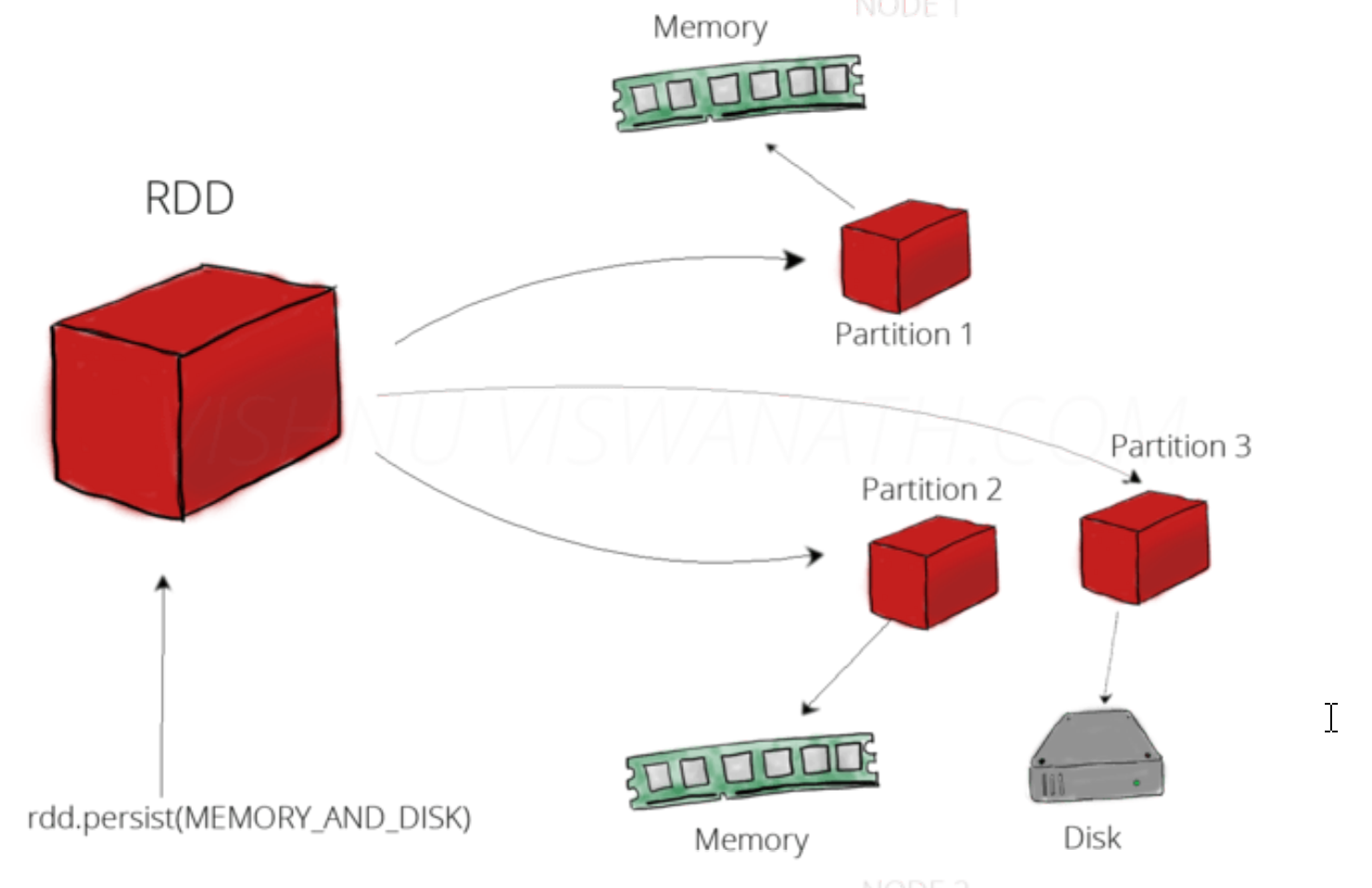
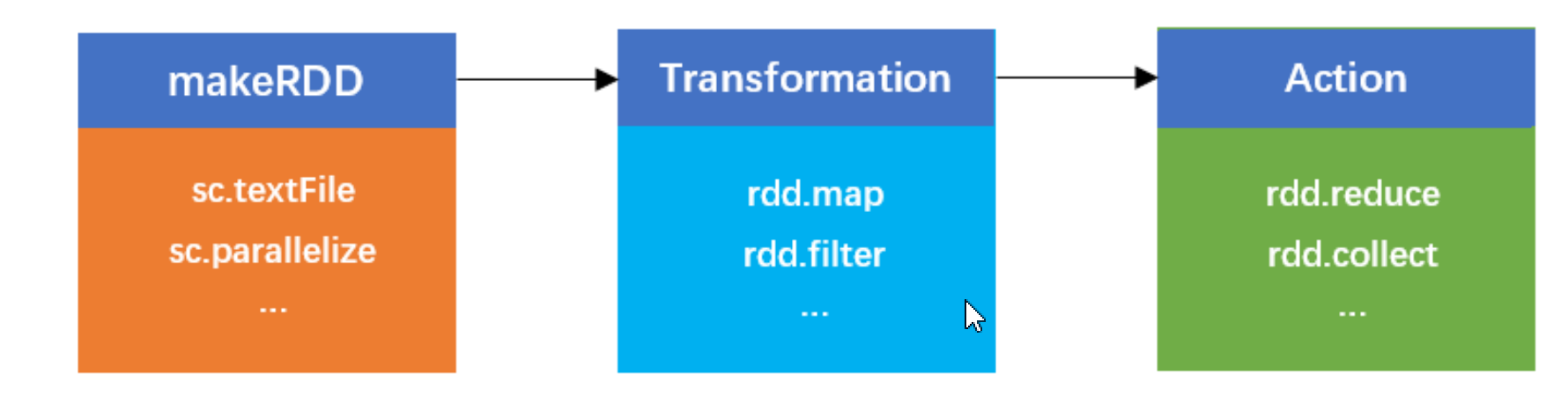
Spark 中的计算过程可以简单的抽象为对 RDD 的创建、转换和返回操作结果的过程
- RDD总结:
RDD 是 Resilient Distributed Dataset 的缩写,意思为弹性分布式数据集(一种数据结构),是一个读取分区记录的集 合,是 Spark 对需要处理的数据的基本抽象。源码中是一个抽象类,代表一系列弹性的、不可变、可分区、里面元素可并 行计算的集合。
RDD五大属性:分区列表、分区计算函数、一系列依赖关系、计算向数据靠拢(移动数据不如移动计算)

- 集合创建RDD
package com.yjxxt.rdd
import org.apache.spark.SparkContext
import org.apache.spark.rdd.RDD
object CreateRDDFromMemory {
def main(args: Array[String]): Unit = {
// 建立连接
val sc = new SparkContext("local[*]", "CreateRDD")
// 通过内存创建 RDD
val list = List(1, 2, 3, 4, 5)
// parallelize 表示并行度,为了方便使用可以调用 makeRDD
//val rdd: RDD[Int] = sc.parallelize(list)
// 通过源码得知 makeRDD 内部调用了 parallelize
val rdd: RDD[Int] = sc.makeRDD(list)
rdd.foreach(println)
// 关闭连接
if (!sc.isStopped) sc.stop()
}
}
- 文件创建RDD
package com.yjxxt.rdd
import org.apache.spark.SparkContext
import org.apache.spark.rdd.RDD
object CreateRDDFromFile {
def main(args: Array[String]): Unit = {
// 建立连接
val sc = new SparkContext("local[*]", "CreateRDD")
// path 可以是具体的文件,也可以是目录,当 path 是目录时,则获取目录下所有文件
val rdd01: RDD[String] = sc.textFile("data/test.txt")
rdd01.foreach(println)
val rdd02: RDD[String] = sc.textFile("data/wordcount")
rdd02.foreach(println)
// 还支持通配符匹配
val rdd03: RDD[String] = sc.textFile("data/wordcount/wd1*.txt")
rdd03.foreach(println)
// 访问的节点必须为 Active NameNode,也就是说 node01 必须是 Active NameNode
val rdd04: RDD[String] = sc.textFile("hdfs://node02:8020/yjx/wordcount")
rdd04.foreach(println)
// textFile 是按行读取,wholeTextFiles 是按整个文件读取
// 返回格式为元组:(文件地址+文件名, 文件内容)
val rdd05: RDD[(String, String)] = sc.wholeTextFiles("data/test.txt")
rdd05.foreach(println)
val rdd06: RDD[(String, String)] = sc.wholeTextFiles("hdfs://node02:8020/yjx/wordcount")
rdd06.foreach(println)
// 关闭连接
if (!sc.isStopped) sc.stop()
}
}
在 spark-shell 中 sc.textFile(path) 默认读取 HDFS 文件,如果需要读取本地文件,需要添加 file:// 前缀。在 读取 HDFS 文件时,path 如果不加 / ,默认读取 hdfs://hdfs-yjx/user/root ,如果加了 / ,从 HDFS 根路径开始读 取,也就是 hdfs://hdfs-zwf 。
2、Partition
一个Partition对应一个Task,partition是Spark计算任务的基本处理单位,决定了并行计算的粒度,而Partition中的每一条Record为基本处理对象。例如对某个RDD进行Map操作,在具体执行时是由多个并行的task对各自分区的每一条记录进行映射。
spark支持集合分区处理、文件分区处理、重分区处理(在创建RDD时设置分区数参数)、分区器的分区处理(HashPartitioner、RangePartition)
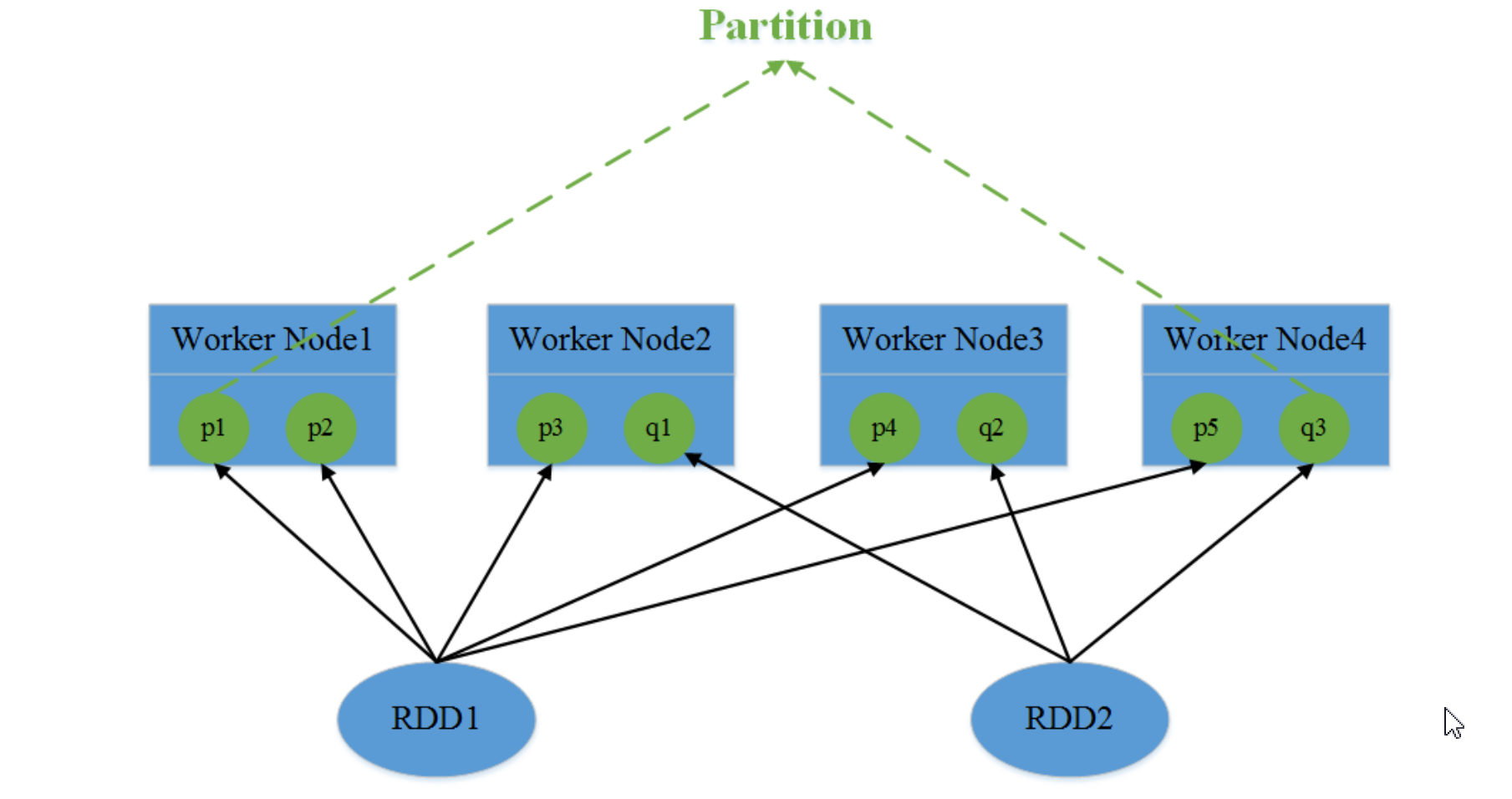
2-1、集合分区
package com.yjxxt.partition
import org.apache.spark.SparkContext
import org.apache.spark.rdd.RDD
object PartitionDemo {
def main(args: Array[String]): Unit = {
// 建立连接
val sc = new SparkContext("local[*]", "PartitionDemo")
val list = List(1, 2, 3, 4, 5)
// 创建 RDD 并设置分区数 numSlices
val rdd: RDD[Int] = sc.makeRDD(list, 2)
// numSlices 参数是可以不传递的,不传递时将使用默认值 defaultParallelism
// defaultParallelism 默认值表示将按当前运行环境的最大可用 CPU 核数进行分区
//val rdd: RDD[Int] = sc.makeRDD(list)
// 将数据写出到文件
rdd.saveAsTextFile("output")
// 关闭连接
if (!sc.isStopped) sc.stop()
}
}
运行结果如下:
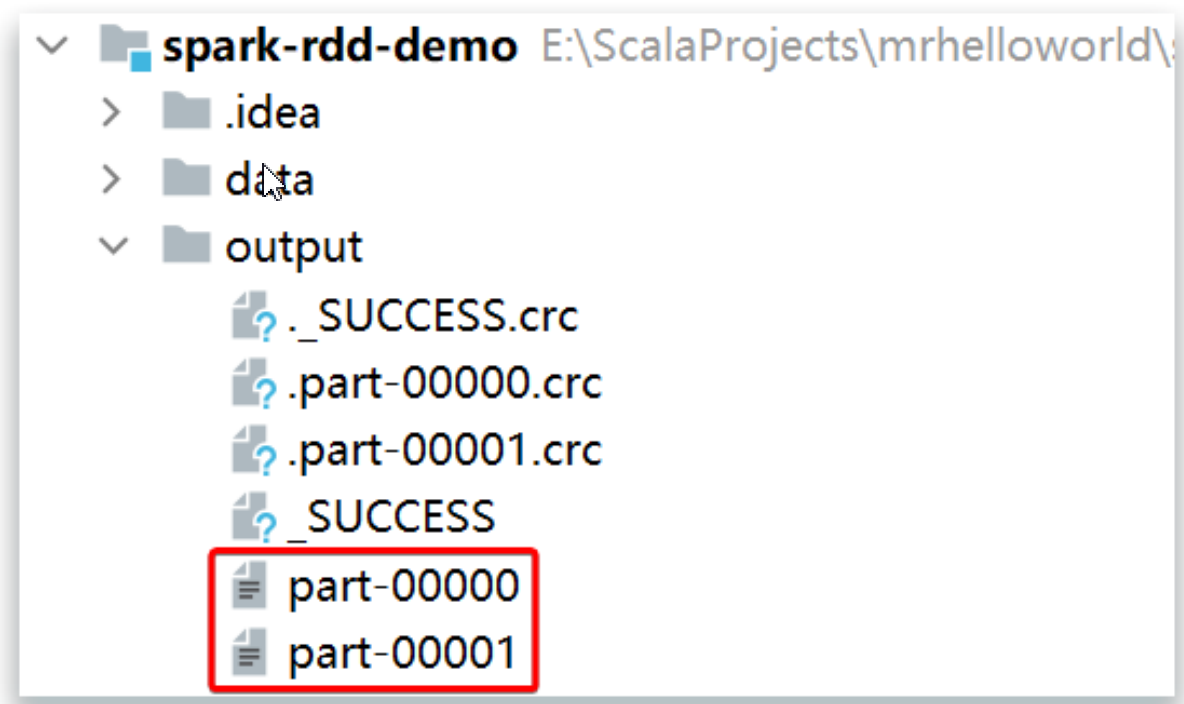
根据上述代码可以得知, makeRDD 函数的 numSlices 参数是可以不传递的,不传递时将使用默认值 defaultParallelism ,该默认值表示将按当前运行环境的最大可用 CPU 核数进行分区。
- 集合分区数计算逻辑源码
def positions(length: Long, numSlices: Int): Iterator[(Int, Int)] = {
(0 until numSlices).iterator.map {
i =>
//numslices:分区数 i是迭代的数值 length是集合长度
val start = ((i * length) / numSlices).toInt
val end = (((i + 1) * length) / numSlices).toInt
(start, end)
}
}
- 执行结果
// 计算分区所对应的集合索引区间
def positions(length: Long, numSlices: Int): Iterator[(Int, Int)] = {
// 遍历 0 到 分区数的左闭右开区间(左边包含右边不包含)
// 刚才的案例中分区数为 12,则 0 until 12
(0 until numSlices).iterator.map { i =>
// start = 分区的索引从 0 开始 * 集合长度 / 分区数
// start 第 1 次 = 0 * 5 / 12 = 0
// start 第 2 次 = 1 * 5 / 12 = 0
// start 第 3 次 = 2 * 5 / 12 = 0
// start 第 4 次 = 3 * 5 / 12 = 1
// start 第 5 次 = 4 * 5 / 12 = 1
// start 第 6 次 = 5 * 5 / 12 = 2
// start 第 7 次 = 6 * 5 / 12 = 2
// start 第 8 次 = 7 * 5 / 12 = 2
// start 第 9 次 = 8 * 5 / 12 = 3
// start 第 10 次 = 9 * 5 / 12 = 3
// start 第 11 次 = 10 * 5 / 12 = 4
// start 第 12 次 = 11 * 5 / 12 = 4
val start = ((i * length) / numSlices).toInt
// end = (分区的索引从 0 开始 + 1) * 集合长度 / 分区数
// end 第 1 次 = (0 + 1) * 5 / 12 = 0
// end 第 2 次 = (1 + 1) * 5 / 12 = 0
// end 第 3 次 = (2 + 1) * 5 / 12 = 1
// end 第 4 次 = (3 + 1) * 5 / 12 = 1
// end 第 5 次 = (4 + 1) * 5 / 12 = 2
// end 第 6 次 = (5 + 1) * 5 / 12 = 2
// end 第 7 次 = (6 + 1) * 5 / 12 = 2
// end 第 8 次 = (7 + 1) * 5 / 12 = 3
// end 第 9 次 = (8 + 1) * 5 / 12 = 3
// end 第 10 次 = (9 + 1) * 5 / 12 = 4
// end 第 11 次 = (10 + 1) * 5 / 12 = 4
// end 第 12 次 = (11 + 1) * 5 / 12 = 5
val end = (((i + 1) * length) / numSlices).toInt
/*
第 1 个分区 part-00000 - (0, 0)
第 2 个分区 part-00001 - (0, 0)
第 3 个分区 part-00002 - (0, 1) => 1
第 4 个分区 part-00003 - (1, 1)
第 5 个分区 part-00004 - (1, 2) => 2
第 6 个分区 part-00005 - (2, 2)
第 7 个分区 part-00006 - (2, 2)
第 8 个分区 part-00007 - (2, 3) => 3
第 9 个分区 part-00008 - (3, 3)
第 10 个分区 part-00009 - (3, 4) => 4
第 11 个分区 part-00010 - (4, 4)
第 12 个分区 part-00011 - (4, 5) => 5
*/
(start, end)
}
}
注意,这里计算的是分区所对应的集合索引区间(左闭右开),假设集合为:
val list = List("Hello Hadoop", "Hello ZooKeeper", "Hello Hadoop Hive", "Hello Hadoop HBase", "Hive Scala Spark")
结果为:

2-2、文件分区
读取文件时,RDD分区默认跟Hadoop分区一致,默认分区数是当Hadoop集群分区>=2时,默认为二个分区,否则就是一个分区。
- 案例:
object WordCountDemo {
//wordcount案例
def main(args: Array[String]): Unit = {
//初始化函数
val conf = new SparkConf()
//设置运行本地模式
conf.setMaster("local").setAppName("WordCount")
//根据配置对象初始化上下文对象
val sc = new SparkContext(conf)
//读取文件,按行读取 numslics:分区数
val v1: RDD[String] = sc.textFile("./data/wordcount",2)
//将空格拆分每一行数据 拆分一个个的单词
val v2: RDD[String] = v1.flatMap(w => w.split("\\s+"))
//将单词进行分组 Array[key->()]
val v3: RDD[(String, Iterable[String])] = v2.groupBy(v => v)
val v4: RDD[(String, Int)] = v3.map(kv => (kv._1, kv._2.size))
val array: Array[(String, Int)] = v4.take(10)
array.foreach(println)
//关闭连接 如果SC未停止 就停止SparkContext()
if(!sc.isStopped){
sc.stop()
}
}
}
设置了分区数就会走以下源码:每个分区总字节大小=文件总字节长度/(分区数==0?1:分区数),但是如果不是最后一个分区,每个分区就会多读一行内容,就会产生新的分区,由此就出现了设置了两个分区,最终出现了3个分区内容。

其他的分区器:HashPartitioner、RagePartitioner
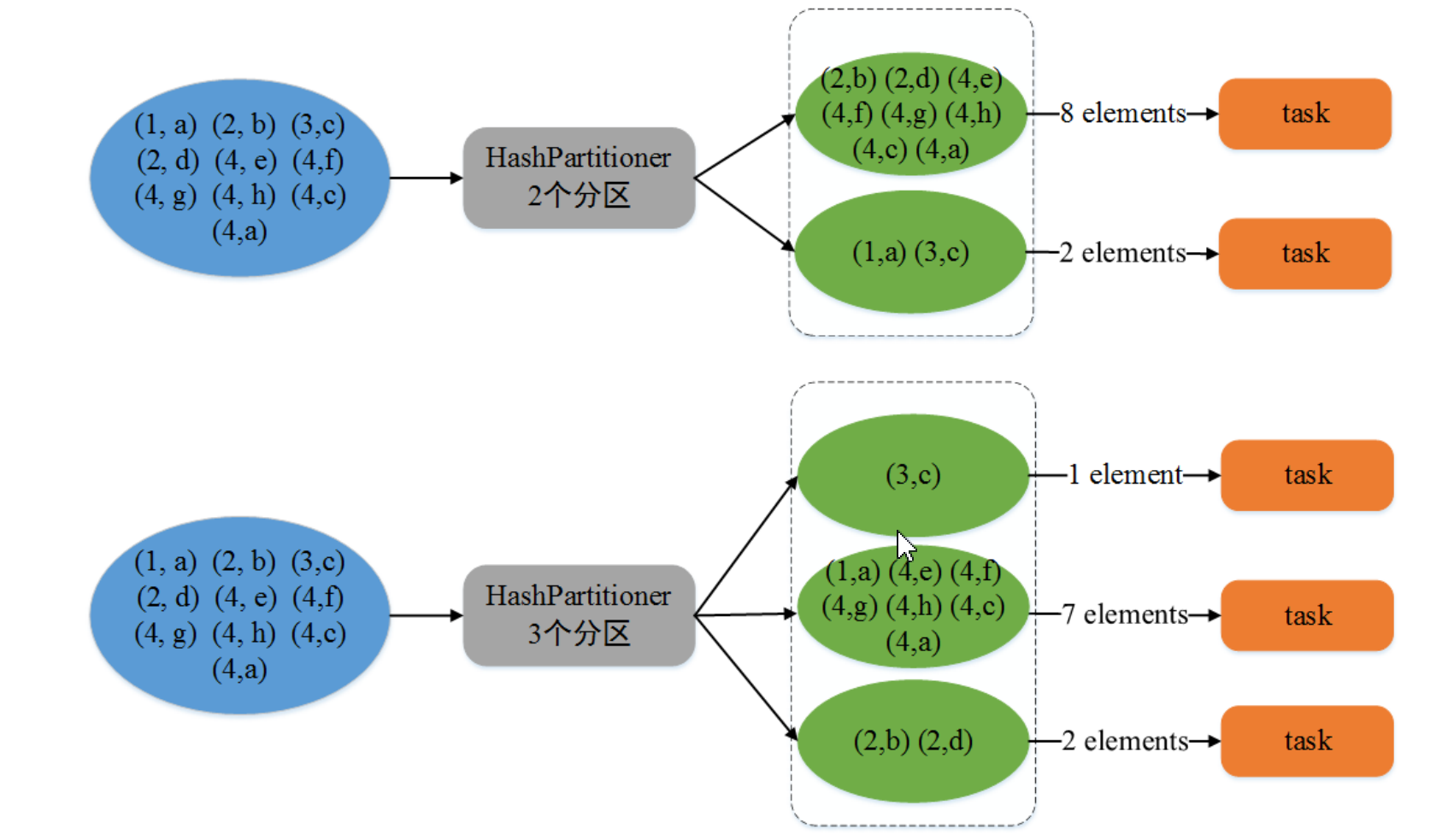
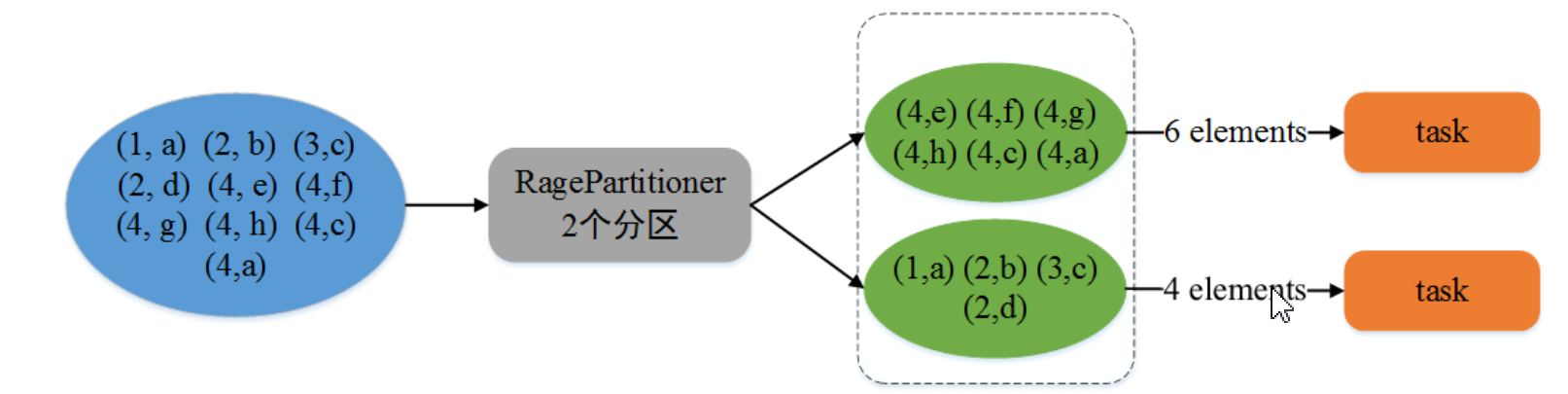
3、算子
Spark 记录了 RDD 之间的生成和依赖关系。但是只有当进行行动操作时,Spark 才会根据 RDD 的依赖关系生成 DAG(有向无环图), 并从起点开始真正的计算。
算子分为两大类:
转换算子(本质就是函数)=>转换往往是从一个RDD到另一个RDD的计算。在执行应用的程序时,遇到转换算子,并不会立即触发计算操作,而是延时到遇到Action算子时才会操作,如:Map flatMap filter等。
行动算子(本质就是函数)=>一个行动往往代表一种输出到外部系统的操作,count、take、foreach等。
控制算子:将RDD持久化,持久化单位是Partition。控制算子有三种:cache、persist、checkpoint,cache 和 persist 都是懒执行的,必须由一个 Action 类算子触发执行。 checkpoint 算子不仅能将 RDD 持久化到磁盘,还能切断 RDD 之间的依赖关系。
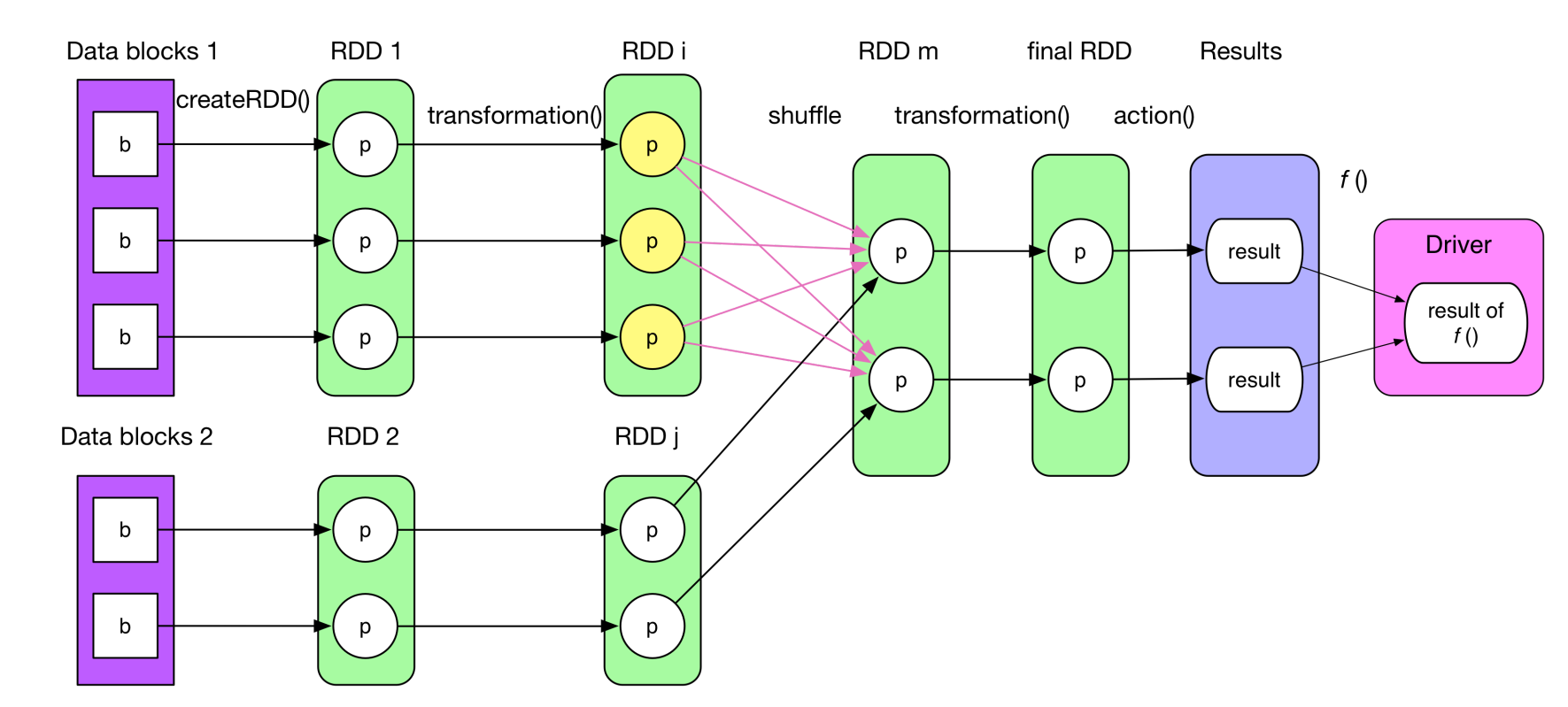
算子是一个函数空间到另一个空间的映射。RDD根据数据处理方式不同可以把算子分为:单value类型、双value类型和key-value类型。
3-1、转换算子(单value)
理解:功能的补充和封装,将旧的RDD转换为新的RDD
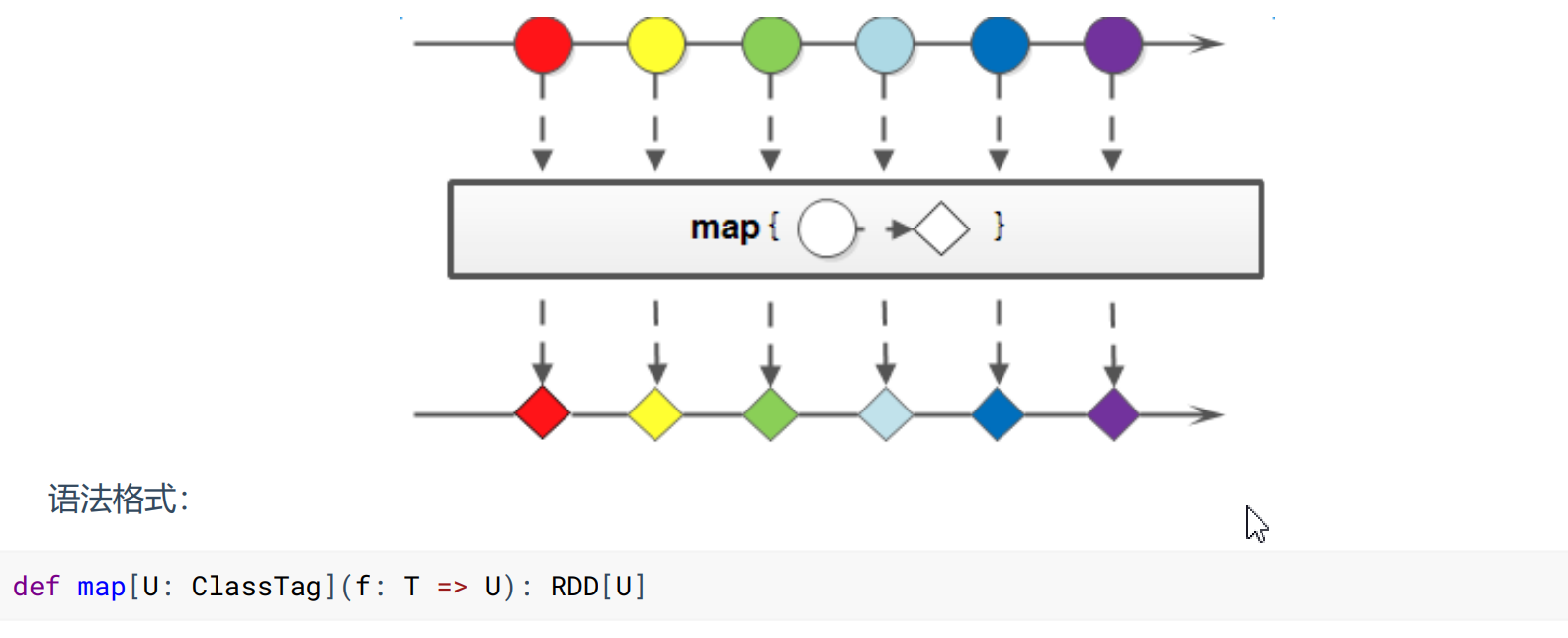
- Map
将处理的数据逐条进行映射转换,将返回值构成新的 RDD。这里的转换可以是类型的转换,也可以是值的转换。
- mapPartitions & mapPartitionsWithIndex
mapPartitions会以分区为单位,将整个分区的数据加载到内存中。处理完不会立即释放,因为存在引用关系,所以内存较小时,数据较大时会出现OOM。
mapPartitionsWithIndex与MapPartitions区别在于多了一个分区号参数。
能用mapPartitions解决的都能使用Map,mapPartition还可用于分区间的数据库连接,比如基于分区的数据库连接,可以减少数据的连接次数,提高运行性能!

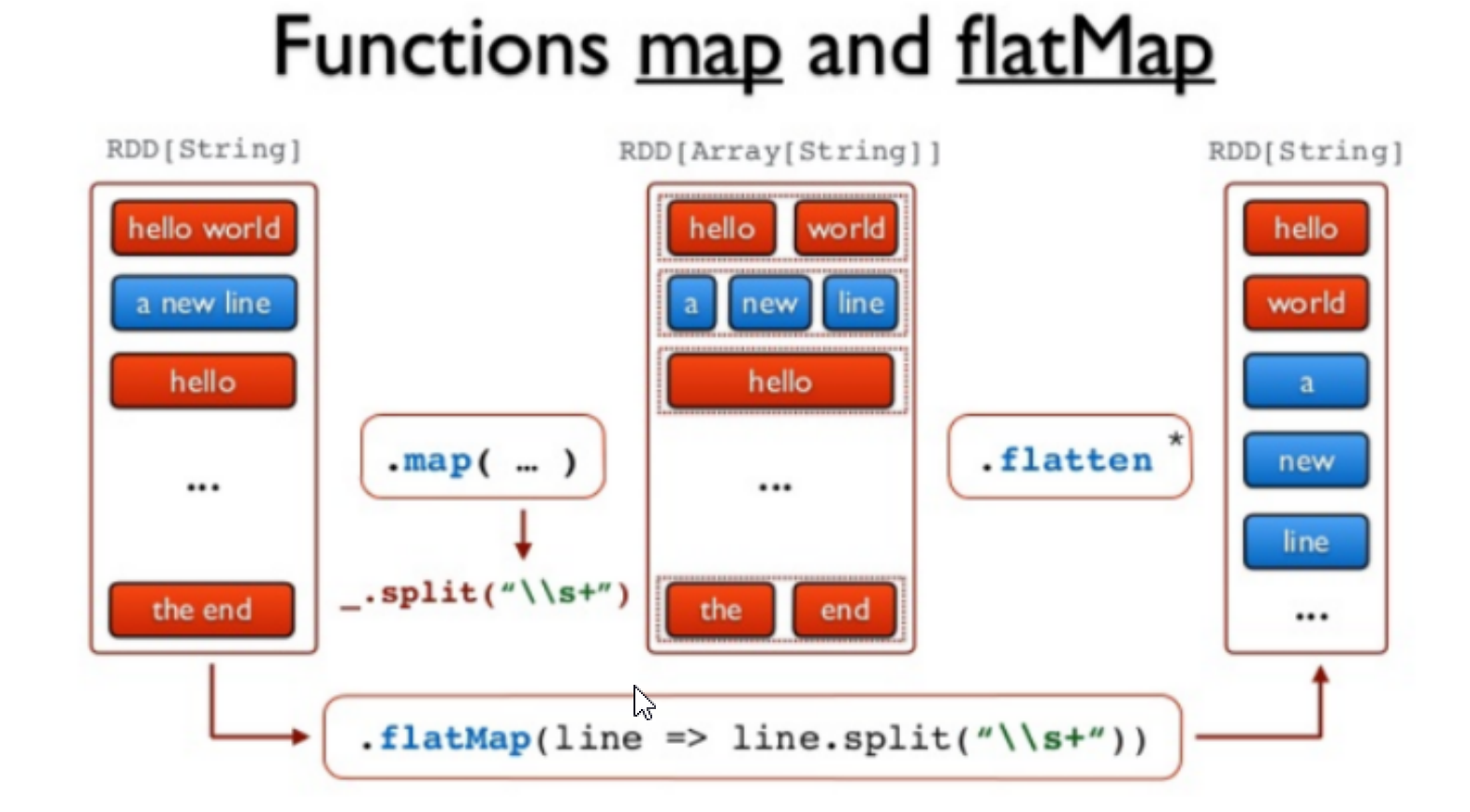
- flatMap
简单理解就是先把Map再flatten,将函数作用于集合中每个元素,然后将结果展平,返回新的集合。

- glom
将同一个分区多个单个值转换为相同类型的单个数组处理,适用于以分区为单位的数据统计。

- groupBy(Shuffle)
按照传入参数类型进行分组,相同类型的为一组,由于可能会出现多个分区,每个分区会出现多个分组,最终要进行分区与分区之间的分组就会出现打乱重组的过程就会产生shuffle。

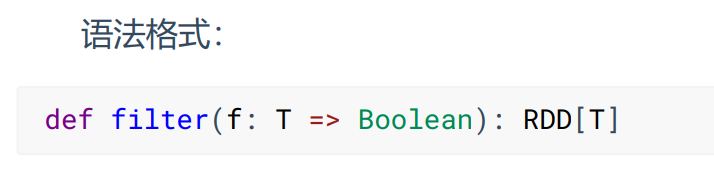
- filter
对传递的数据按照传入的函数条件进行过滤,晒选出符合函数规则的数据,筛选后分区不变,单分区内的数据可能不均衡,生产环境下,可能会出现数据倾斜。
- sample
采样就是从大量的数据中获取少量的数据,获取的方法可以依据某种策略,得到数据用于分析,企图使用少量的数据结果代替全局。


- distinct(shuffle)
将数据集中重复的数据去重。scala底层采用了Hashset的方式,而Spark的distinct则是采用了MapReduceByKey、map的方式进行去重。

- coalesce(shuffle)
缩减分区数,用于大数据集过滤后,提高小数据集的执行效率,可以理解为合并分区,可能导致数据倾斜。缩小分区数,默认是不会进行shuffle分区重组,只会合并分区,可能会出现数据倾斜,因为防止数据倾斜,可以把第二个参数设置为true。

- repartition(shuffle)
repartition实际上本质是调用了coalesce(n,true),开启shuffle,一定会产生shuffle,也就是数据打乱重组。

- sortBy (shuffle)
sortBy函数可以根据指定的规则对数据源中的数据进行排序,默认为升序,该函数会产生shuffle

3-2、转换算子(双value)
双value的转换算子有并集、交集、差集,使用Union、intersection、subtract,但是两个RDD的元素类型必须相同,否则编译不通过。

- 拉链
将两个RDD的合并成一个RDD,两个RDD的分区数量都必须相同,否则会抛出异常。

3-3、转换算子(k-v)
- partitionBy(shuffle)
将数据按照指定的分区重新进行分区,spark默认采用HashPartitioner。通用的分区器有HashPartitioner和RangePartitioner、PythonPartitioner



还可以自定义分区
package com.yjxxt.operator.transformation
import org.apache.spark.Partitioner
class MyPartitioner extends Partitioner {
// 分区数
override def numPartitions: Int = 3
// 分区规则
override def getPartition(key: Any): Int = key match {
case 1 => 1
case 2 => 2
case _ => 0
}
}
//使用自定义分区
val mkRDD = sc.makeRDD(List((1, "张三"), (2, "李四"), (3, "王五"), (4, "赵六")), 4)
// 自定义分区
mkRDD.partitionBy(new MyPartitioner)
//使用默认HashPartitioner
mkRDD.partitionBy(new HashPartitioner(2))
- sortByKey(shuffle)
按照(k,v)二元组中的k进行排序,默认是升序,但是如果排序的是多元组(x1,x2,x3,x4,...),会先按照x1排序,如果x1相同,再按x2排序,依次类推。

- reduceByKey(shuffle)
将相同的key的值聚合到一起,Reduce任务的个数可以通过numPartitions参数来设置。分区内和分区间的聚合计算逻辑一致。

- groupByKey(shuffle)
groupByKey是根据K进行分组,会返回(K,iterable[V])格式的数据,与前面的groupby区别在于groupby是根据传入参数的返回类型的进行分组,如果传入传入二元组(K,V),会返回(K,Iterable[(k,v)])格式数据。


reduceBykey与groupByKey的区别?
从shuffle角度:reduceByKey和groupByKey都存在shuffle操作,但是reduceBykey可以在shuffle前后内相同的key进行预聚合,这样会减少落盘的数据,而groupByKey只能进行分组,不存在数据量减少的问题,reduceByKey的性能比较高。
从功能的角度:reduceByKey是先分组再聚合,而groupByKey只是进行分组。
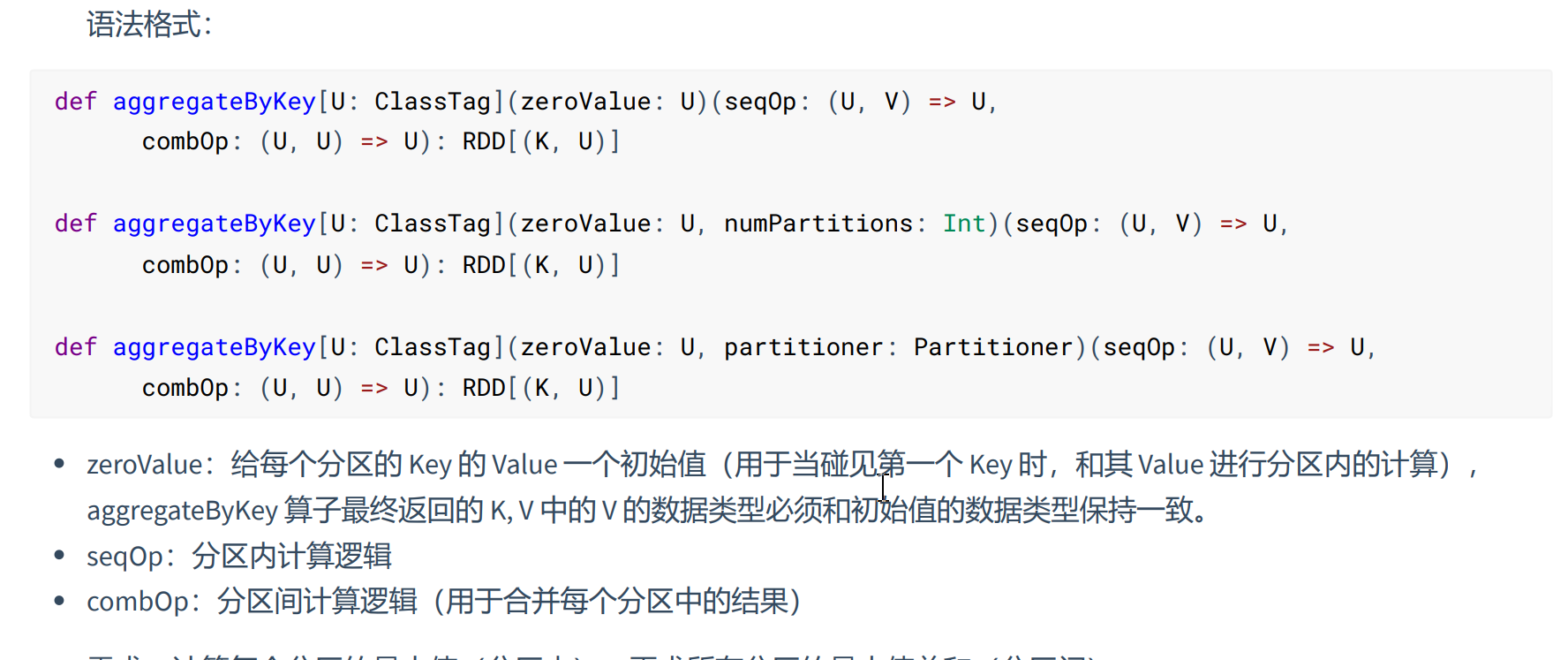
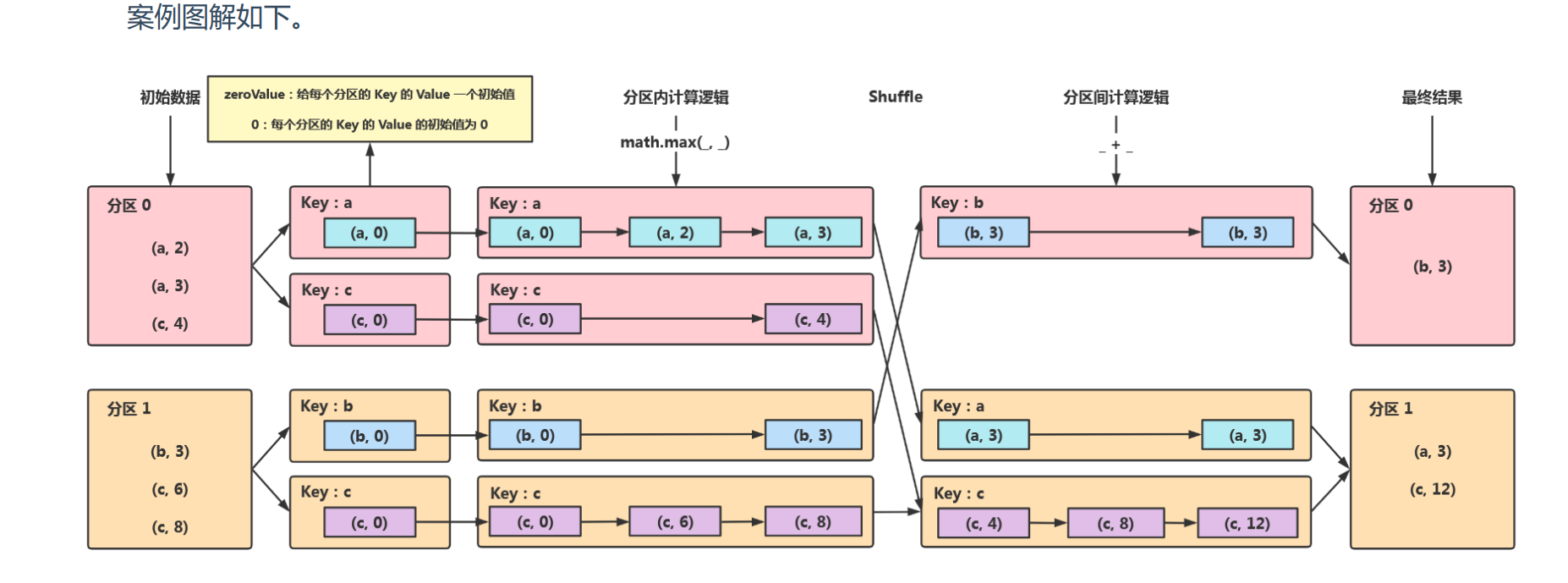
- aggregateByKey(shuffle)
aggregateByKey算子功能与reduceBykey一样是先聚合再分组,但是reduceByKey分区内和分区间的聚合计算逻辑必须一致,而aggregateByKey分区间和分区内的聚合计算逻辑可以不一致(可以一致),也可以设置初始化值。
为了便于理解这个算子的作用,可以看如下图所示
- mapValues
针对于k,v形式的数据只对v进行操作。

- foldByKey(shuffle)
通俗点讲:foldByKey就是aggregateByKey在分区内和分区外计算逻辑相同时的缩写,只保留初始化参数和一个分区聚合计算逻辑参数。

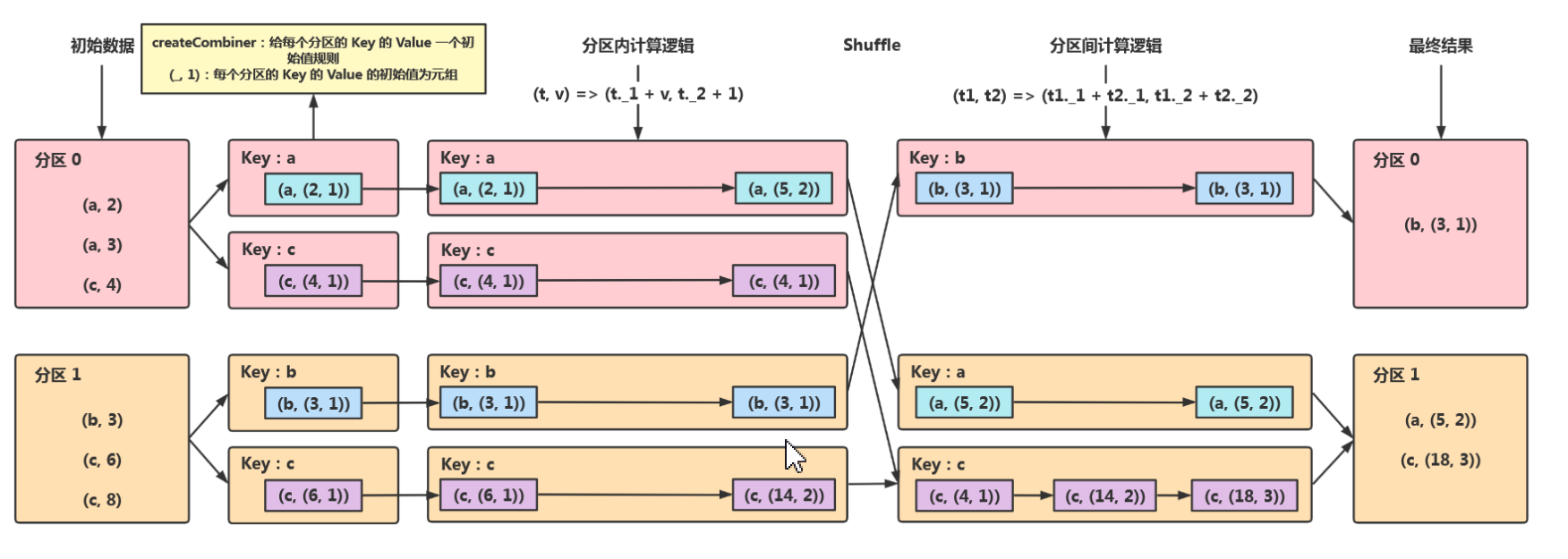
- combineByKey(shuffle)
combineByKey与aggregateByKey大致运行逻辑是一致的,区别在于combineBykey的初始值,赋值是(k,(v,初始值)),而aggregateByKey的初始值赋值是(k,初始值),都是分为分区内和分区外聚合计算逻辑参数。

为了更好理解的combineByKey,如下图所示:
- cogroup
根据两个不同的数据源中,先按Key进行分组,然后将同一个RDD计算出的数据使用compactbuffer()收集成集合,另外RDD计算出来的数据使用另外compactBuffer()收集,如果RDD该k的分组没有值,就返回空compactBuffer()集合。
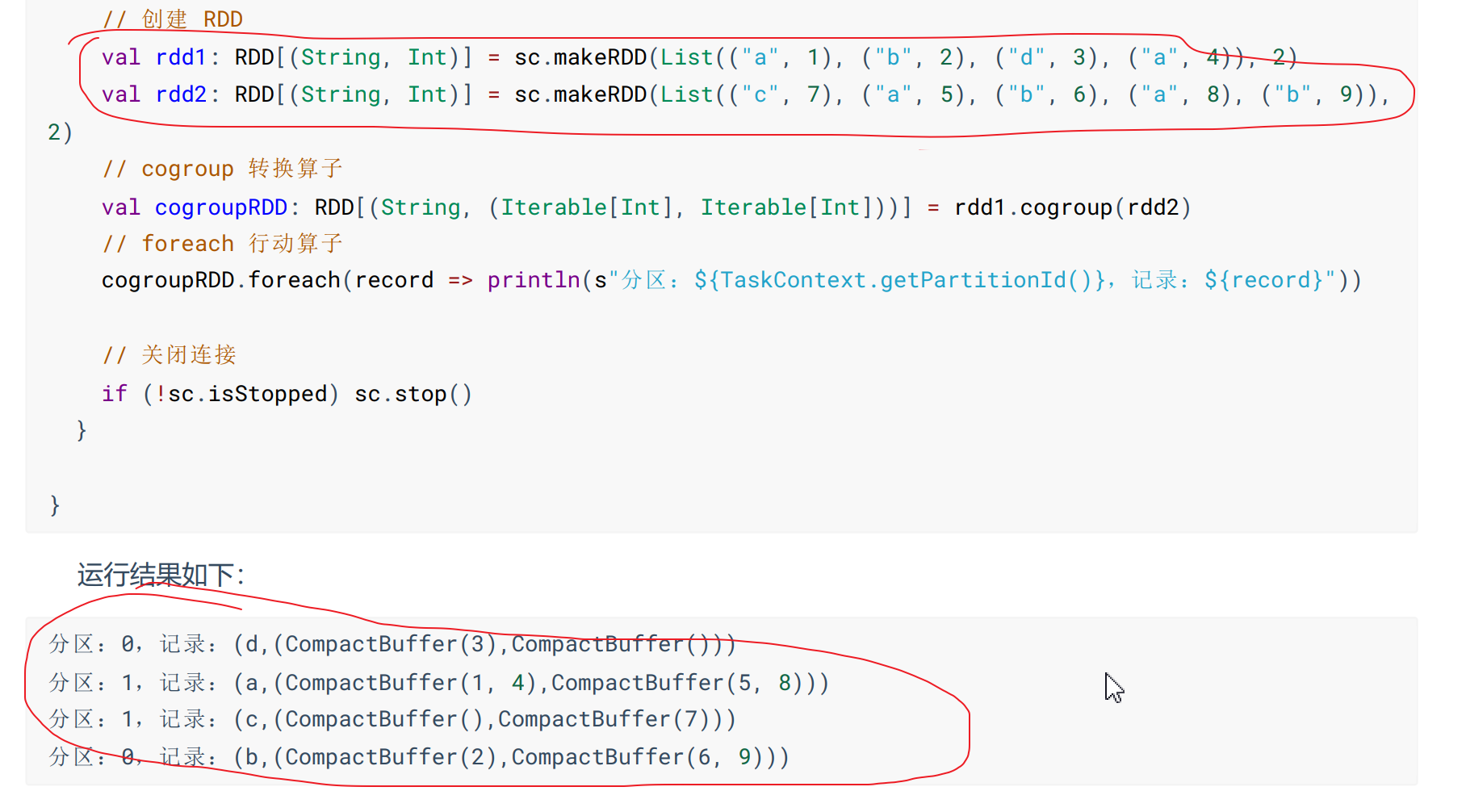
3-4、行动算子
生成作业并触发任务的调度和执行。
- reduce
通过函数先聚合RDD中所有元素,先聚合分区内数据,再聚合分区间数据

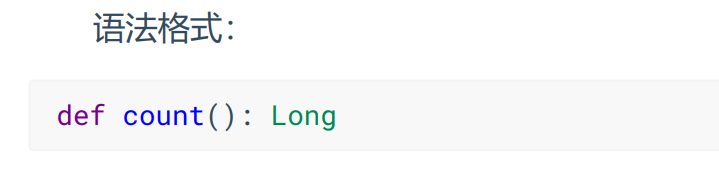
- count
返回RDD中元素的个数
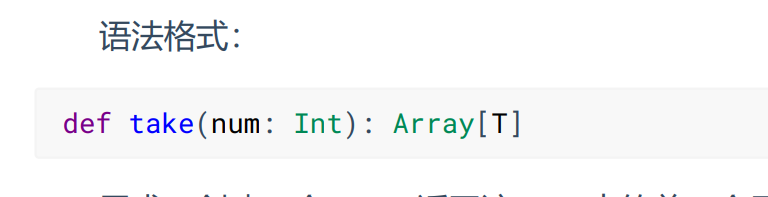
- take
返回RDD的前n个元素组成的数组
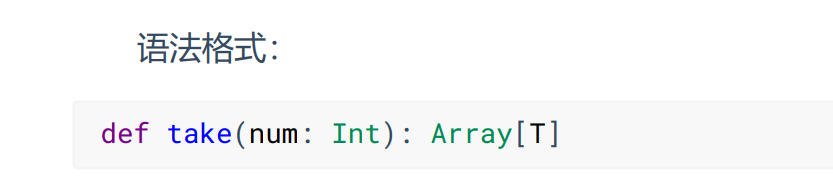
- takeOrdered
返回RDD排序后的前n个元素组成的数组,默认正序,如果要是用倒叙使用以下语法:
val result04: Array[Int] = mkRDD.takeOrdered(3)(Ordering.Int.reverse)
- first
返回RDD中的第一个元素,底层就是调用take(1)
- foreach
遍历数据集中每个元组,运行相应的计算逻辑,但是foreach返回空值,一般用于打印出数据。
- foreachPartition
按分区循环遍历数据集中的每个元素。

- collect
把所有分区中的数据全部收集到Driver中,如果数据量太大容易造成OOM,慎用!以数组的形式返回。

- aggregate
aggregate与reduce算子本质的本质都是聚合,但是aggregate可以设置初始值参与计算,并且aggregate分区内和分区间的聚合计算逻辑可以不一致,并且初始值参与分区内和分区间的计算,而reduce分区内和分区间的聚合计算逻辑必须一致,且没有初始值。

- fold
fold实际上就是分区内和分区外聚合计算逻辑一致,简化参数的个数,并且还可以复制初始值,初始值参于分区内外聚合计算。是aggregate的参数简化版算子。

- countByValue&countByKey
countByValue是对kv数据集按照v进行计数,而countByKey是对kv数据集按照k进行计数。
countByValue 底层调用的是 map().countByKey()。countByKey 底层调用的是 reduceByKey。

- save系列
saveAsTextFile:将数据集中以TextFile的形式保存到文件系统(HDFS)或者其他组件中。
saveAsSequenceFile:将数据集中的元素以Hadoop SequenceFile的格式保存到HDFS文件系统或者其他文件系统。
saveAsObjectFile:将RDD中的元素序列化成对象,存储到文件中。


3-5、控制算子
控制算子可以将RDD持久化,持久化的单位是Partition,控制算子有三种:cache(只存在内存),persist(保存到磁盘上,暂时落盘,作业结束删除),checkpoint(永久落盘,一般保存在HDFS上),主要目的防止不需要重新计算的数据不再重新计算。
cache 和 persist 都是懒执行的,必须由一个 Action 类算子触发执行。 checkpoint 算子不仅能将 RDD 持久化 到磁盘,还能切断 RDD 之间的依赖关系。
checkpoint 可以理解为改变了数据源,因为关键数据已经计算完成,没有必要重头进行读取,所以 checkpoint 算子不仅能将 RDD 持久化到磁盘,还能切断 RDD 之间的依赖关系。




4、闭包检测
在RDD中传输对象类型进行分布计算时,会检测对象是否序列化,如果未序列化,对象无法进行分布式传输计算。
- 解决方案
对象类继承 scala.Serializable。
使用样例类,样例类默认继承序列化接口。
- Kryo序列化框架
由于 Java 自身的序列化比较重(字节多),所以出于性能的考虑,Spark 2.0 开始支持另外一种序列化机制 Kryo。
Kryo 的速度是 Serializable 的 10 倍。当 RDD 在 Shuffle 数据的时候,简单数据类型、数组和字符串类型已经在 Spark 内部使用 Kryo 来序列化。
- 使用方式如下:
val conf: SparkConf = new SparkConf()
.setMaster("local[*]").setAppName("SerializDemo")
// 设置 Kryo 序列化器
.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
// 注册 Kryo 序列化器
.registerKryoClasses(Array(classOf[User]))
5、血统和依赖关系
血统:spark根据Application中RDD从加载数据到触发job整个过程的转换算子和活动算子会形成一个有向无环图,活动算子触发job时,job会从活动算子依次往上找,直到找到加载数据源再进行计算。
依赖关系:分为宽依赖和窄依赖.
窄依赖:RDD与RDD的partition之间的关系是一对一的关系(如Map、filter)
宽依赖:RDD与RDD的partition之间的关系是一对多的关系,宽依赖会产生shuffle(如reduceBykey)
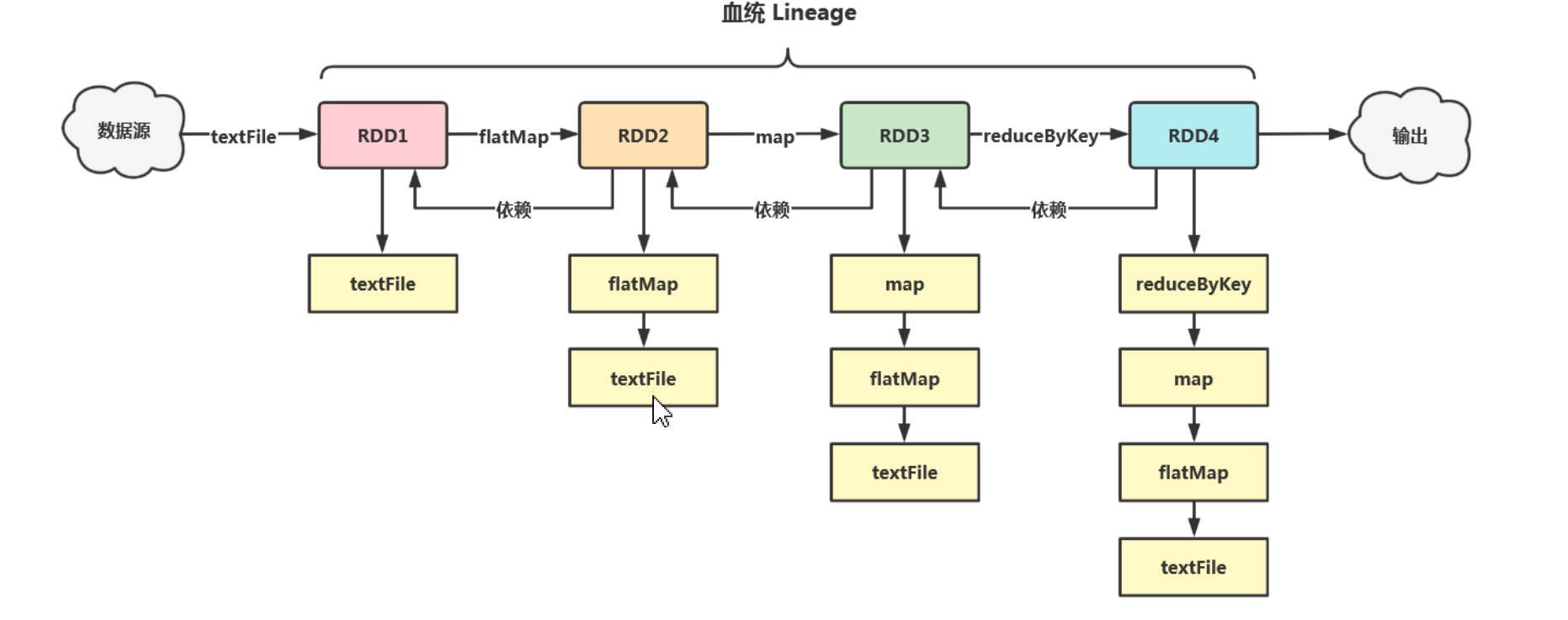
宽依赖是划分stage阶段的标志,分区数等于并行度等于最后一个stage的Task数。
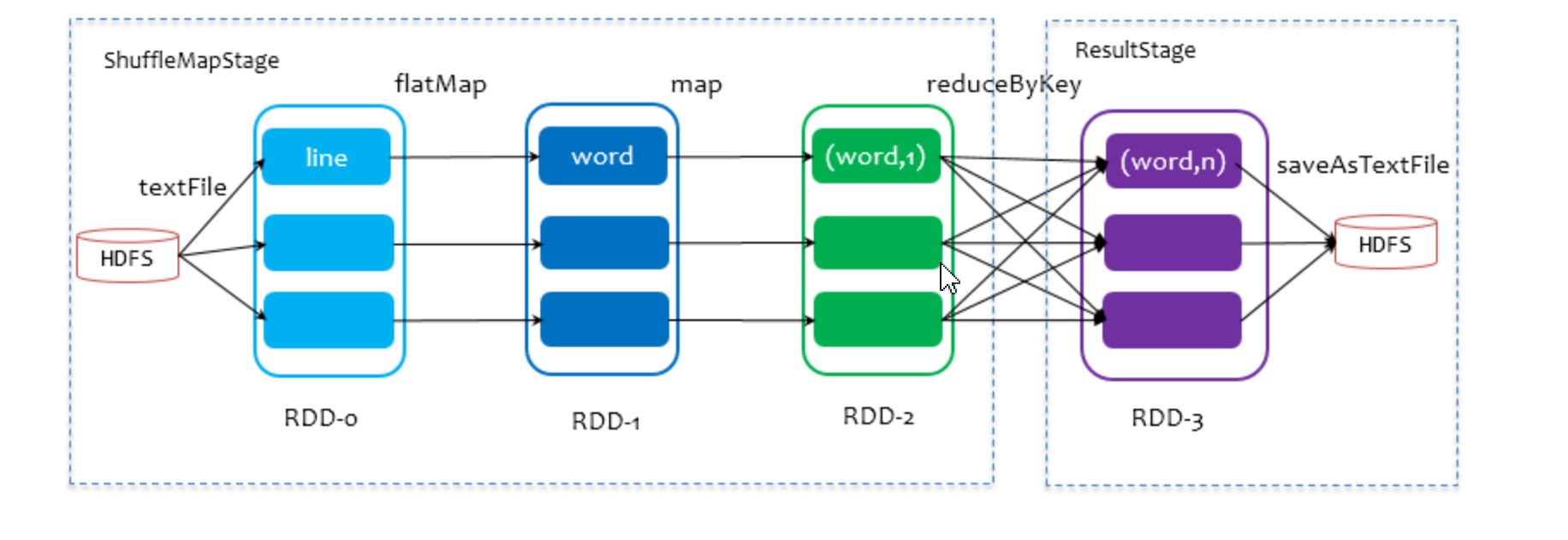
6、job作业
Application提交到Spark中,一个sparkContext生成一个Application,遇到活动算子催生多个job,一个job中有多个转换算子和一个行动算子,遇到一个活动算子就催生一个job,Stage 是 Job 的子集,以 RDD 宽依赖(即 Shuffle)为界,遇到 Shuffle 就做一次划分; Task 是 Stage 的子集,以并行度(分区数)来衡量,分区数是多少,就有多少个 Task。

7、数据本地化
数据本地化的最终目的是提供Application的运行效率,本地化级别分为:进程本地化(PROCESS_LOCAL 性能最好)、节点本地化(NODE_LOCAL)、没有最佳(NO_PREF)、机架本地化(RACK_LOCAL)、任何地方(ANY)
spark.locality.wait 默认值是 3s。Task 任务分配的时候,先是按照 PROCESS_LOCAL 方式去分配 Task,如果 PROCESS_LOCAL 不满足,默认等待 3 秒,看能不能按照这个级别去分配,如果等了 3 秒也实现不 了,那么就按 NODE_LOCAL 级别去分配。以此类推,每次都是等待 3 秒
// 全局设置,默认 3s
spark.locality.wait=3s
// 建议 60s
spark.locality.wait.process=60s
// 建议 30s
spark.locality.wait.node=30s
// 建议 20s
spark.locality.wait.rack=20s
8、广播变量
当有一个过滤敏感词的需求时,如果不使用广播变量,就会在每个Task中进行过滤,数据会产生冗余,如果我们使用广播变量,广播变量可以作用在每个Executor中,就大大减少了数据的冗余度。并且广播变量只能共享分布式只读变量,为了防止数据被篡改。
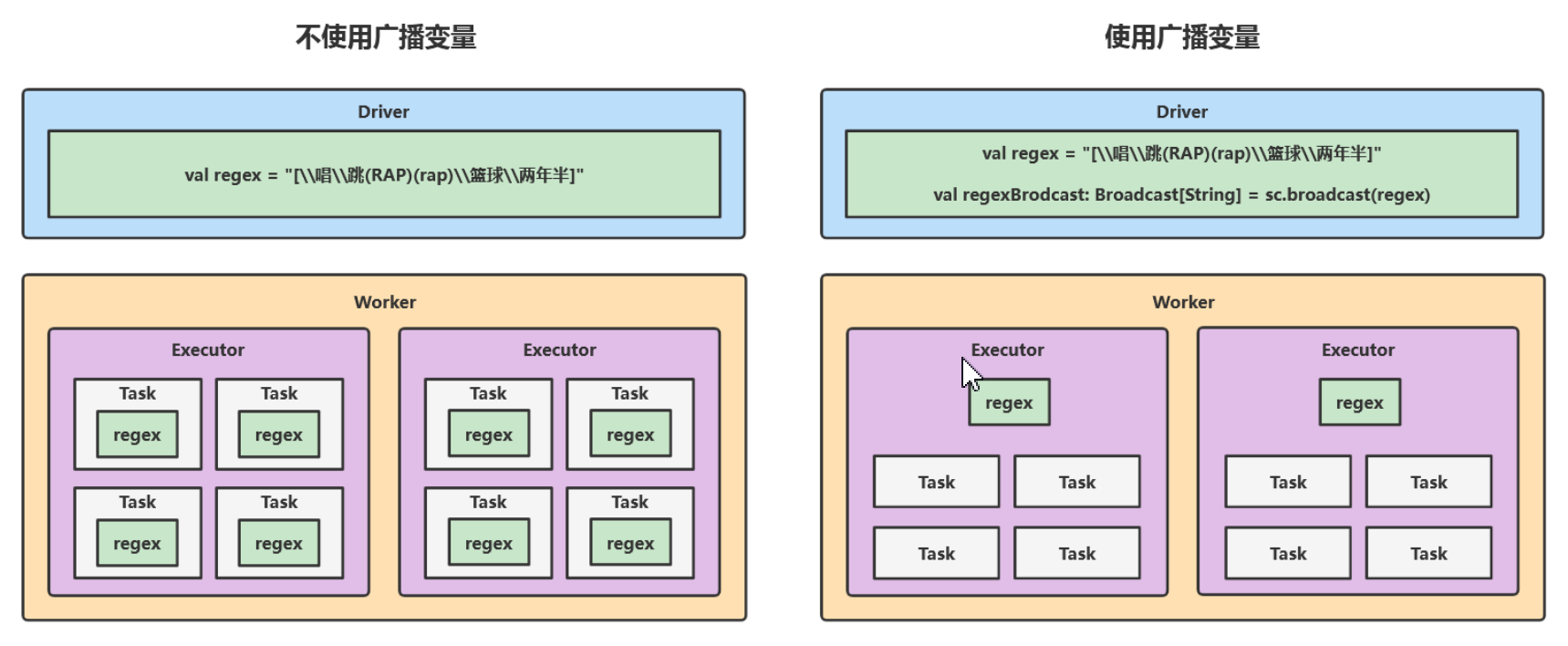
- 使用方式如下:

9、累加器
累加器是为了解决excutor数据与Driver数据共享问题,如果不是使用累加器,每个Task中的进行计算的值只能在Task作用中,无法汇聚累加到Driver,因此累加器是共享分布式每个Task计算后的数据。
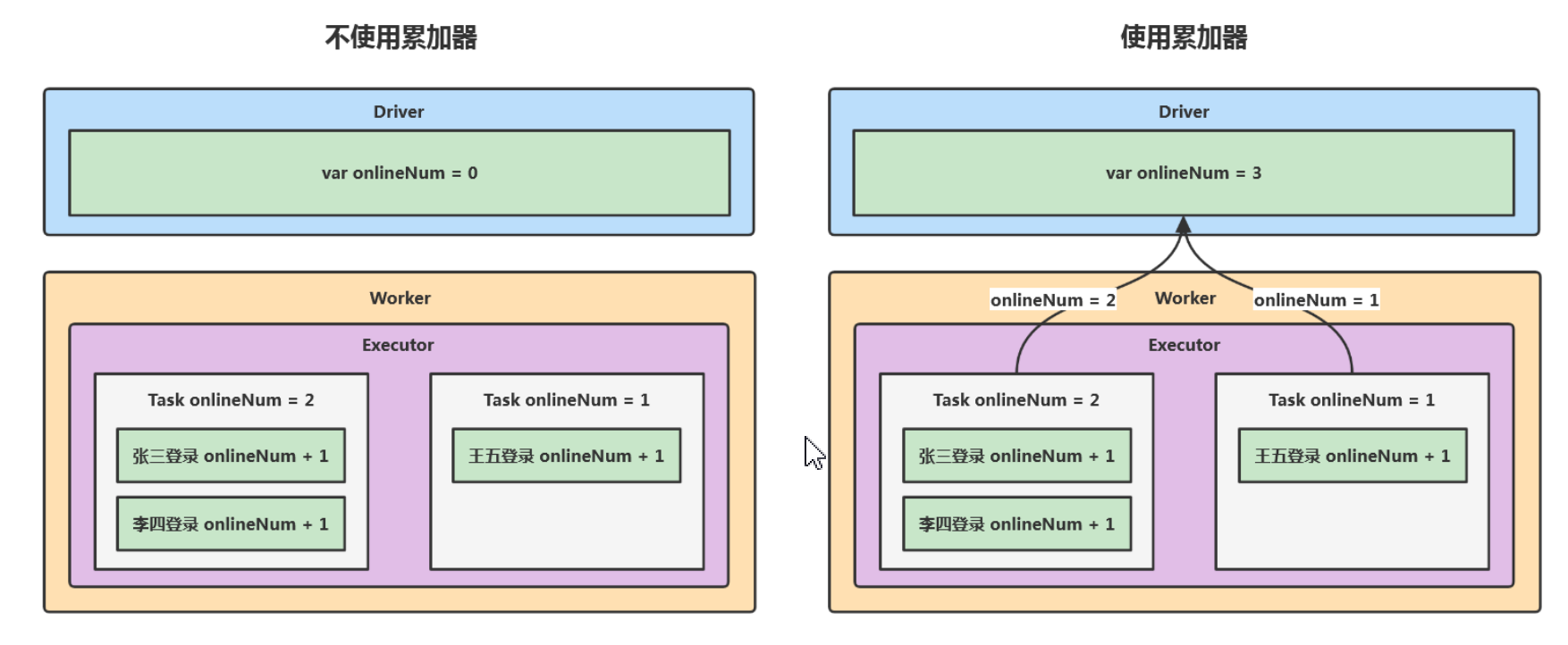
- 使用方式如下:

- 自定义累加器(继承 AccumulatorV2[入参类型,返回类型]类)
package com.yjxxt.accumulator
import org.apache.spark.SparkContext
import org.apache.spark.rdd.RDD
import org.apache.spark.util.AccumulatorV2
import scala.collection.mutable
object WordCountAccumulatorDemo {
def main(args: Array[String]): Unit = {
// 建立连接
val sc = new SparkContext("local[*]", "OnlineCountDemo")
// 初始化自定义累加器
val wordCountAccumulator = new WordCountAccumulator
// 注册累加器
sc.register(wordCountAccumulator, "wordCountAccumulator")
// 创建 RDD
val rdd: RDD[String] = sc.textFile("data/wordcount", 2)
// 自定义累加器 实现 WordCount
rdd.flatMap(_.split("\\s+")).foreach(wordCountAccumulator.add)
// 获取累加器
println(wordCountAccumulator.value)
// 关闭连接
if (!sc.isStopped) sc.stop()
}
/**
* 自定义累加器
*/
class WordCountAccumulator extends AccumulatorV2[String, mutable.Map[String, Long]] {
// 定义可变 Map 存放 Word 和 Count(这个就是自定义的累加器)
private var wd = mutable.Map[String, Long]()
// 累加器是否为零(空)
override def isZero: Boolean = this.wd.isEmpty
// 拷贝新的累加器
override def copy(): AccumulatorV2[String, mutable.Map[String, Long]] = new WordCountAccumulator
// 重置累加器
override def reset(): Unit = this.wd.clear()
// 累加器相加
override def add(word: String): Unit = {
val newCount = wd.getOrElse(word, 0L) + 1L
wd.update(word, newCount)
}
// 累加器合并
override def merge(other: AccumulatorV2[String, mutable.Map[String, Long]]): Unit = {
val m1 = this.wd
val m2 = other.value
m2.foreach {
case (word, count) => {
val newCount = m1.getOrElse(word, 0L) + count
m1.update(word, newCount)
}
}
}
// 获取累加器
override def value: mutable.Map[String, Long] = wd
}
}
七、Shuffle
shuffle定义:Shuffle 本质上而言,就是在计算数据的交、并、差、聚合、排序等过程。而分布式计算分而治之的思想,让每个节点 只计算部分数据,也就是只处理一个分片,那么要想求得某个 Key 对应的全量数据,就必须把相同 Key 的数据汇集到同一 个 Reduce 任务节点来处理,于是 MapReduce 编程范式定义了一个叫做 Shuffle 的过程来实现这个效果。
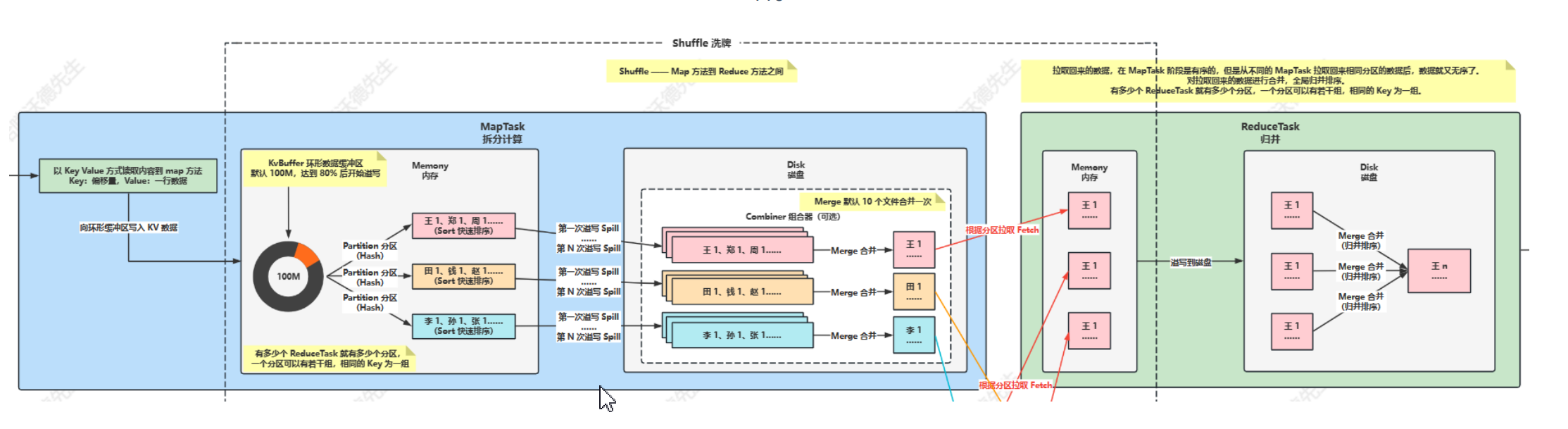
- Hadoop MR-Shuffle
MR-Shuffle 描述的是数据从 Map 端到 Reduce 端的过程,大致分为分区(Partition)、排序(Sort)、溢写(Spill)、 合并(Merge)、小聚合(Combiner)、拉取拷贝(Copy)、合并排序(Merge Sort)这几个过程。
- Spark-shuffle
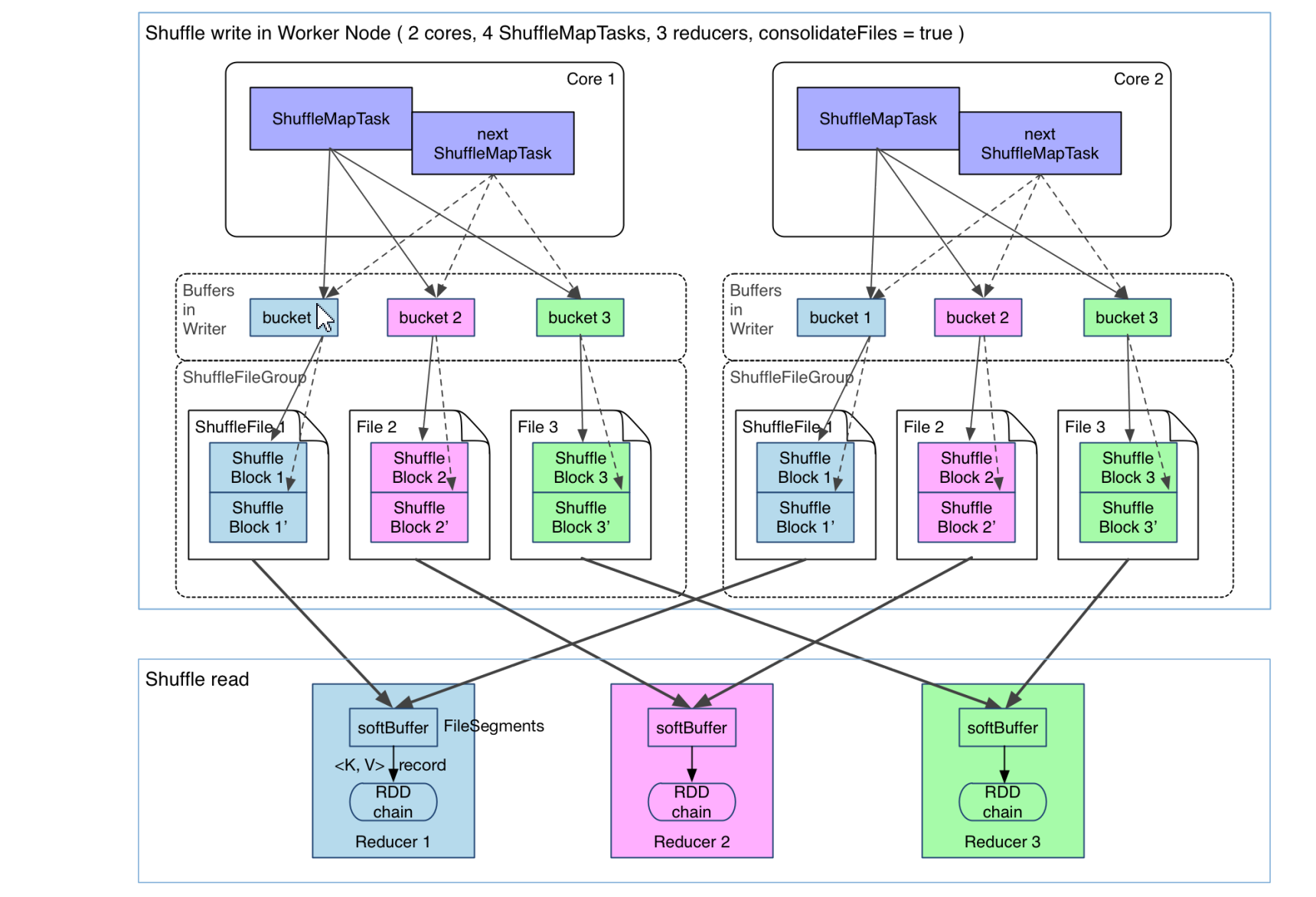
Shuffle Write 阶段:将数据 Partition 好,并持久化形成一个 ShuffleBlockFile,或者简称 FileSegment。之所以要持久化,一方面是要减少内存存储空间压力,另一方面也是为了容错性。
Shuffle Read 阶段:Reducer Fetch 属于自己的 FileSegment,完成后续操作。
- Sort Shuffle
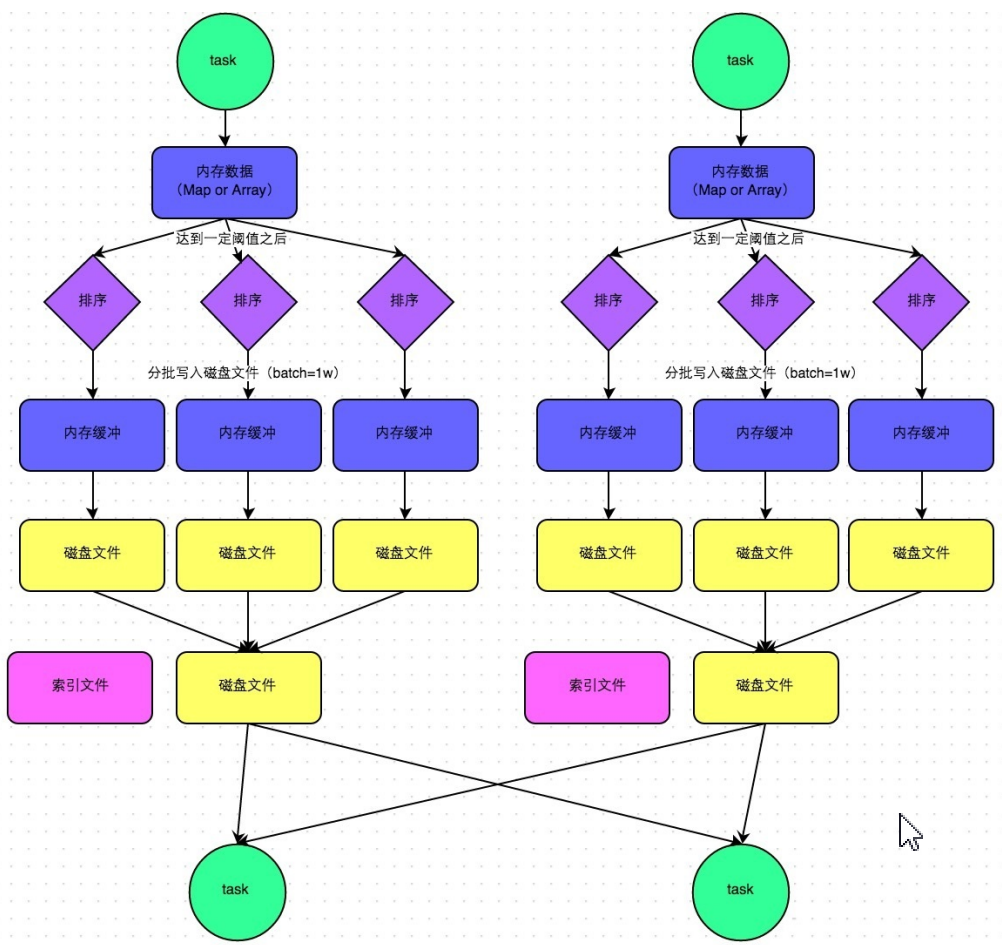
park 引入了类似于 Hadoop MapReduce 的 Shuffle 机制。该机制每一个 ShuffleMapTask 不会为后续的任务创建单独的文件,而是会将所有的 Task 结果写入同一个文 件,并且对应生成一个索引文件。也就是说 Hash Shuffle 为每一个 Reduce 产生一个文件,但是 Sort Shuffle 只产生一个按 照 Reducer ID 排序可索引的文件。
- 总结:
shuffle逻辑流:Hadoop MR 是基于文件的数据结构,Spark 是基于 RDD 的数据结构,计算性能要比 Hadoop 高。
Shuffle Sort:Hadoop MapReduce 是基于排序的,进入 combine() 和 reduce() 的 Records 必须先 Sort。这样的好处在于 combine()/reduce() 可以处理大规模的数据,Mapper 对每段数据先做排序,Reducer 对排好序的每段数据做归并。
在 Spark 中,数据在 ReduceTask 端一定不排序,在 MapTask 端,可以根据设置或算子决定排序或不排。如果不需要 Sort,就退化成 Hash-Based Shuffle 的方式,省去排序的开销。
Shuffle Fetch:Hadoop Reduce 端将 MapTask 的文件拉取到同一个 Reduce 分区,是将文件进行归并排序,合并,将文件直接保存在 磁盘上。
Spark Shuffle Read 拉取来的数据首先肯定是放在 Reduce 端的内存缓存区中,现在的实现都是内存 + 磁盘的方式(数据 结构使用 ExternalAppendOnlyMap),当然也可以通过 spark.shuffle.spill=false 来设置只能使用内存。
使用 ExternalAppendOnlyMap 的时候如果内存的使用达到一定临界值,会首先尝试在内存中扩大 ExternalAppendOnlyMap(内部有实现算法),如果不能扩容的话才会 Spill 到磁盘。
- shuffle优化
Hadoop MR 的 Shuffle 方式单一,优化主要从 Split 切片,Merge 合并,Map-Side 预聚合(Combiner),压缩等方面进行 优化。
Spark 针对不同类型的操作,不同类型的参数,会使用不同类型的 Shuffle Write,并且提供了丰富的 Shuffle 可配置选 择,所以 Spark 更加全面。
八、 内存管理
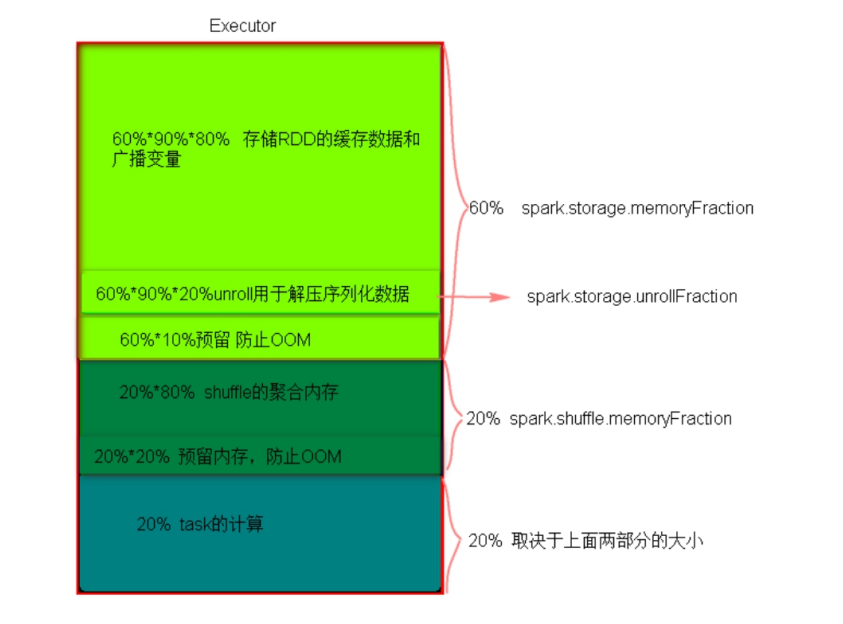
- 静态内存
静态内存管理使用起来非常简单,但由于没有根据具体的数据规模与计算任务相对应的配置,很容易造成"一半海 水,一半火焰"的局面,即存储内存和执行内存中的一方剩余大量的空间,而另一方却早早被占满,不得不淘汰或移出旧 的内容以存储新的内容。
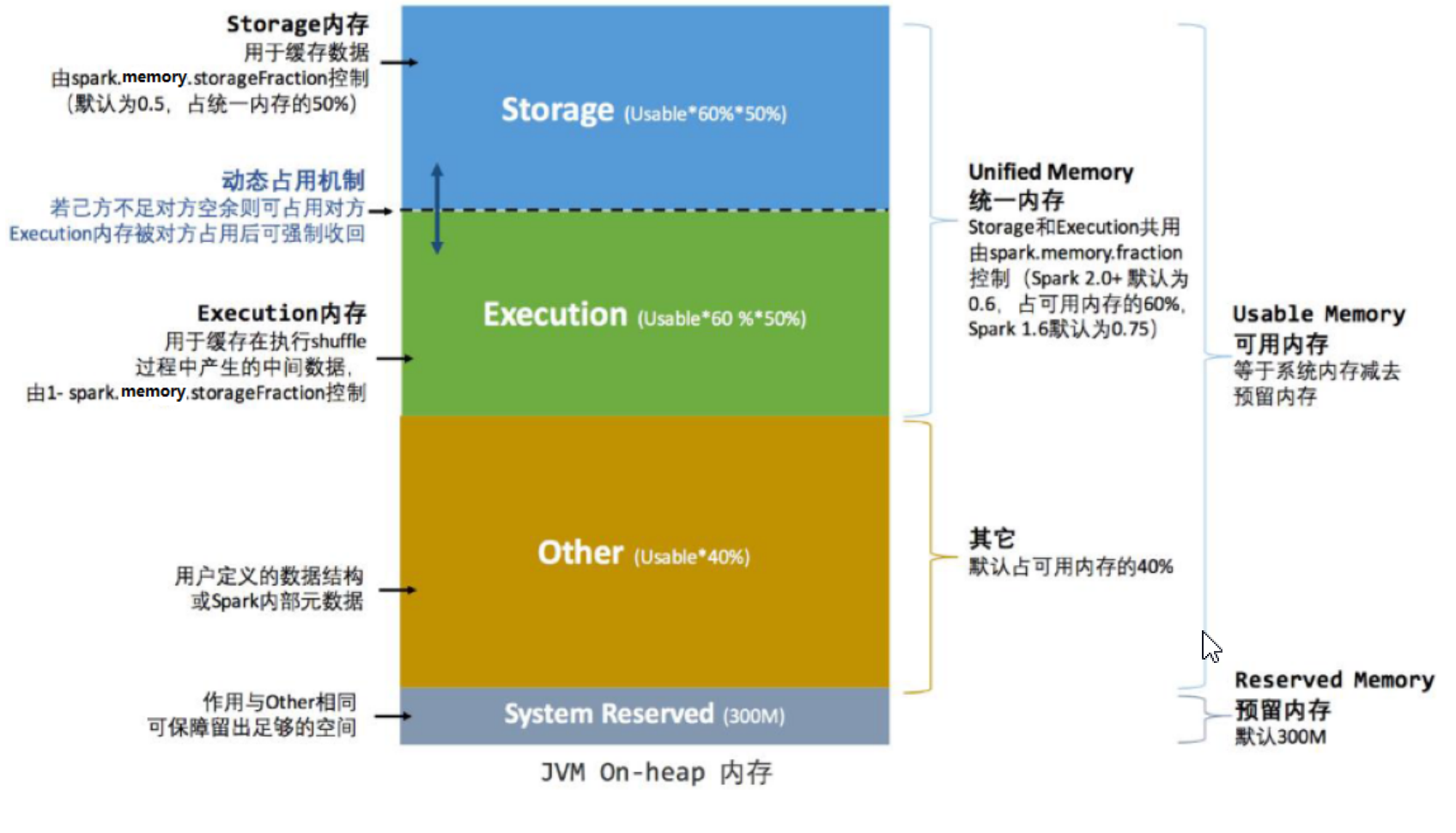
- 统一内存
统一内存管理与静态内存管理的区别在于储存内存和执行内存共享同一块空间,可以动态借用对方的空闲区域。
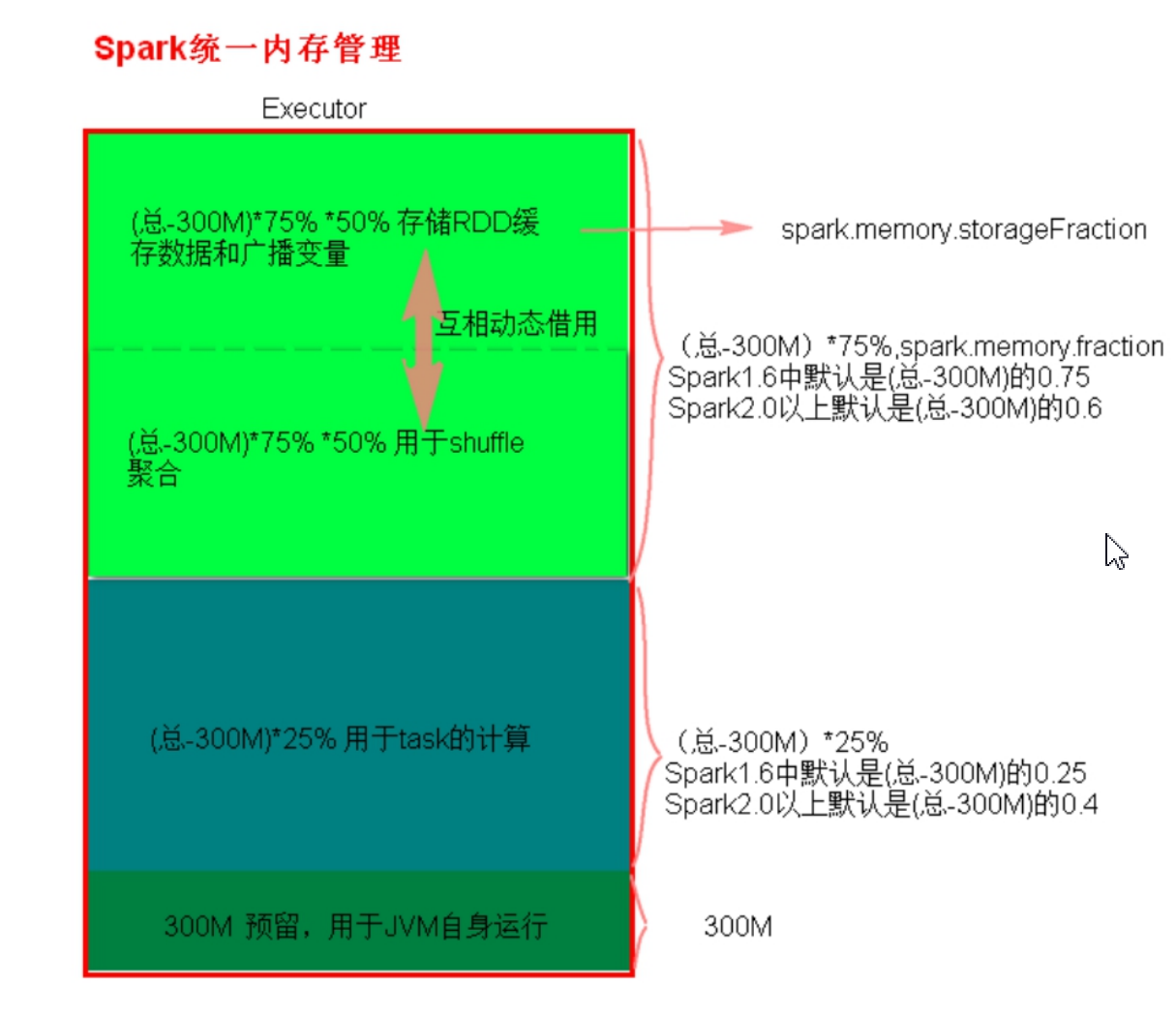
- 内存估算

- 内存配置

九、优化
- 内存管理
Spark 内存管理分为静态内存管理和统一内存管理,Spark1.6 之前(不包含)使用的是静态内存管理,Spark1.6 之 后引入了统一内存管理。Spark1.6 及 1.6 版本之后的版本默认使用的是统一内存管理。要想使用静态内存可以通过设置 参数 spark.memory.useLegacyMode 为 true 来开启(默认为 false )。
优化:由于执行内存和存储内存之间可以相互借用,执行内存和存储内存各占一半,可以调整执行内存比例比存储内存大,这样就不会出现借用了还需要还,保证系统计算的稳定。

- 资源调优
持久化与序列化:由于 Java 自身的序列化比较重(字节多),所以出于性能的考虑,Spark 2.0 开始支持另外一种序列化机制 Kryo。
Kryo 的速度是 Serializable 的 10 倍。当 RDD 在 Shuffle 数据的时候,简单数据类型、数组和字符串类型已经在 Spark 内部使用 Kryo 来序列化。
- 数据持久化
持久化策略:么建议使用 MEMORY_AND_DISK_SER 策略,而不是 MEMORY_AND_DISK 策略。因为 既然到了这一步,就说明 RDD 的数据量很大,内存无法完全放下。
通常不建议使用 DISK_ONLY 和后缀为 _2 的级别:因为完全基于磁盘文件进行数据的读写,会导致性能急剧降低,有 时还不如重新计算一次所有RDD。后缀为 _2 的级别,必须将所有数据都复制一份副本,并发送到其他节点上,数据复制以 及网络传输会导致较大的性能开销,除非是要求作业的高可用性,否则不建议使用。
- CPU优化
spark.default.parallelism :RDD 任务的默认并行度,Spark 中所谓的并行度是指 RDD 中的分区数,即 RDD 中 的 Task 数。当初始 RDD 没有设置分区数(numPartitions 或 numSlice )时,则分区数采用 spark.default.parallelism 的取值。建议:设置初始分区的 2~3 倍之间。例如向 YARN 申请的 Executor Cores 资源个数为 10 个,根据当前任务的提交参数,将此参数设置为 20 或 30 为最优效果。
- JVM调优
Spark JVM 调优主要是降低 GC 时间,可以从以下几个角度进行优化:
修改 Execution 内存的比例;
修改 JVM 内存大小与比配;
增加内存。
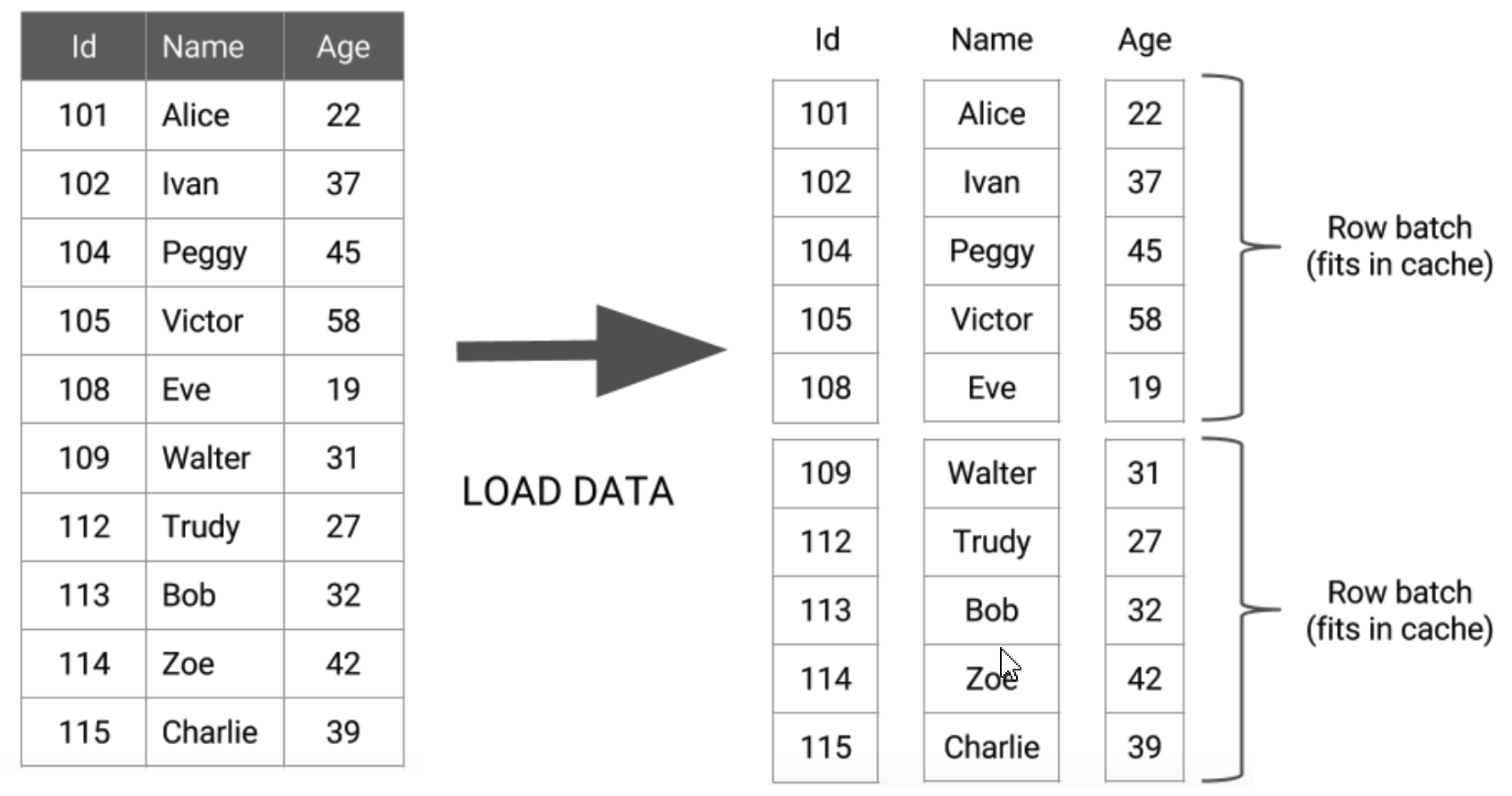
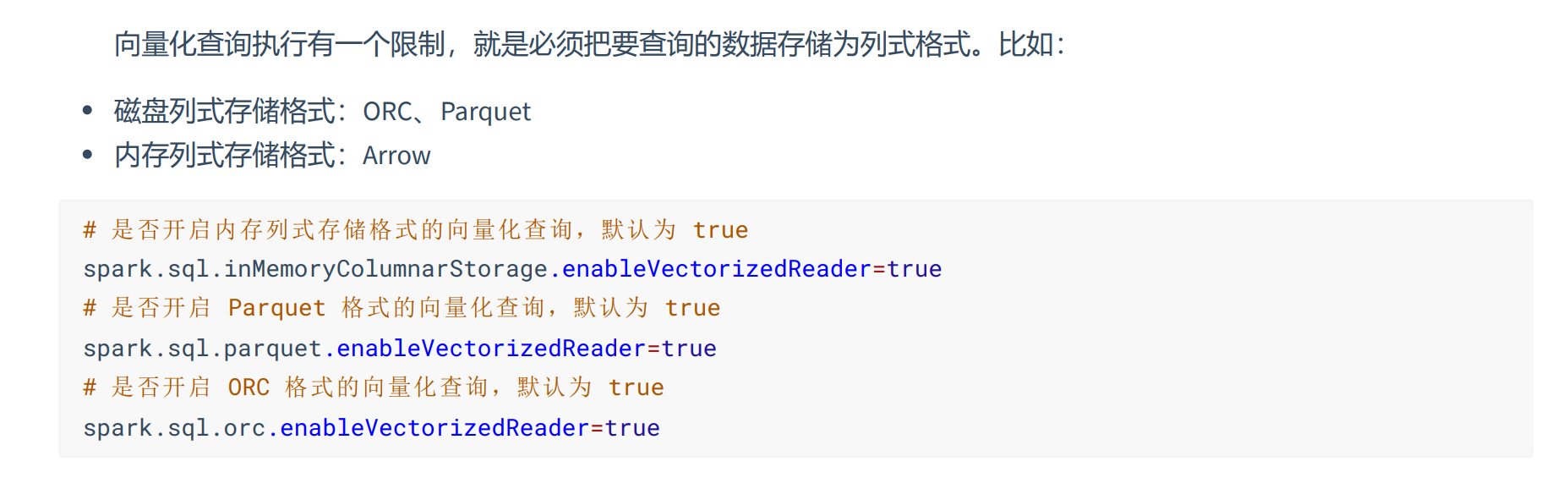
- 向量化执行
Spark 实现了向量执行引擎(Vectorized Execution Engine),对内存中的列式数据,一个 Batch 调用一次 SIMD 指令 (而非每一行调用一次),不仅减少了函数调用次数、降低了 Cache Miss,而且可以充分发挥 SIMD 指令的并行能力,大 幅缩短了计算耗时。向量执行引擎,通常能够带来数倍的性能提升。
总结:让计算更多的停留在函数内,而不是频繁的交互切换,提高了 CPU 的流水线并行度。数据不仅按列式 存储,而且按列(Batch Data)计算
- 动态分配资源
动态请求策略:如果应用有 Tasks 在等待,超过一定的时间(spark.dynamicAllocation.schedulerBacklogTimeout 秒) 就会申请 1 个 Executor。此后每隔一定的时间(spark.dynamicAllocation.sustainedSchedulerBacklogTimeout 秒)就会检测 应用是否有 Tasks 在等待,有就继续申请 Executor。
简单的理解:Spark 之所以快有一部分原因就是粗粒度资源申请,该功能相当于将 Spark 打回了 YARN 原形,也使用细粒度资源申请处理应用。如果多个应用程序在 Spark 群集中共享资源,则此功能特别有用。

- SQL优化
RBO:基于规则优化的优化器,是一种经验式、启发式的优化思路,优化规则都已 经预先定义好了,只需要将 SQL 往这些规则上套就可以。简单的说,RBO 就像是一个经验丰富的老司机,基本优化 套路全都知道。
常见:
谓词下推:尽量让过滤条件靠近from数据源,进行过滤。
列裁剪(Column Pruning)表示扫描数据源的时候,只读取那些与查询相关的字段。
常量替换:把进行运算的表达式尽量用常量替换,减少运算。
CBO:为基于 代价优化的策略,它需要计算所有可能执行计划的代价,并挑选出代价最小的执行计划。开启 CBO 后,CBO 优化器可以基于表和列的统计信 息进行一系列的估算,最终选择出最优的查询计划。比如:Build 侧表选择(小表 JOIN 大表)、优化 JOIN 类型、优化多 表 JOIN 顺序等。比较耗费CPU。
- JOIN优化
将大表通过广播传递到每个Excutor进行JOIN,每个Executor JOIN完后,Driver再收集每个Executor处理完JOIN后的表信息。但是小表的数据过大容易造成OOM。需要在配置中开启,或者通过SQL强制开启。
Broadcast 阶段 :小表被缓存在 Executor 中; Hash Join 阶段:在每个 Executor 中执行 Hash Join。
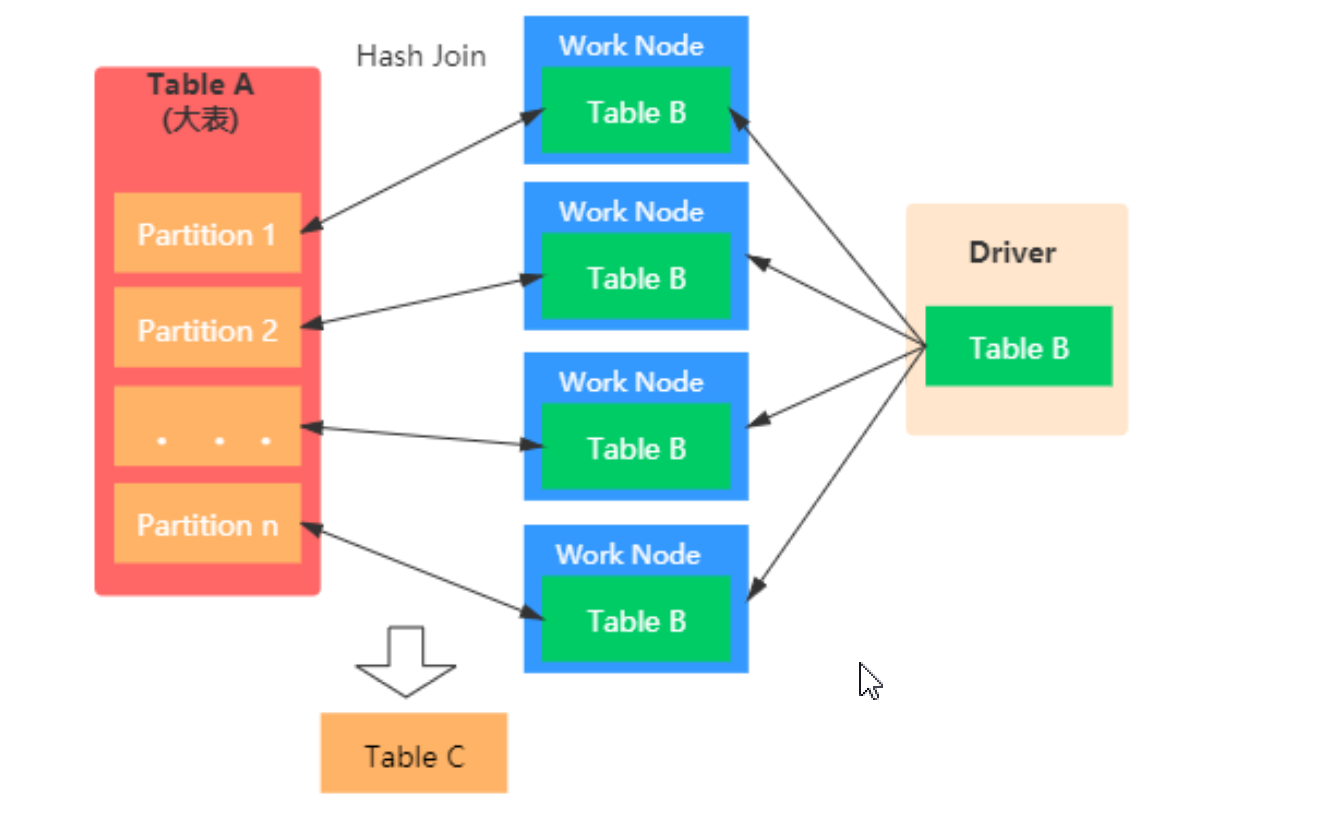
// Hint 强制开启广播 JOIN
// SQL 版本
// BROADCASTJOIN(表) 等价于 BROADCAST(表) 等价于 MAPJOIN(表)
println("==================== Hint 强制开启广播 JOIN SQL 版本 ====================")
val sql =
"""
|SELECT /*+ BROADCASTJOIN(d) */
|e.deptno, SUM(e.sal) AS sum_sal
|FROM scott.emp AS e, scott.dept AS d
|WHERE e.deptno = d.deptno
|GROUP BY e.deptno;
|""".stripMargin
spark.sql(sql).explain()
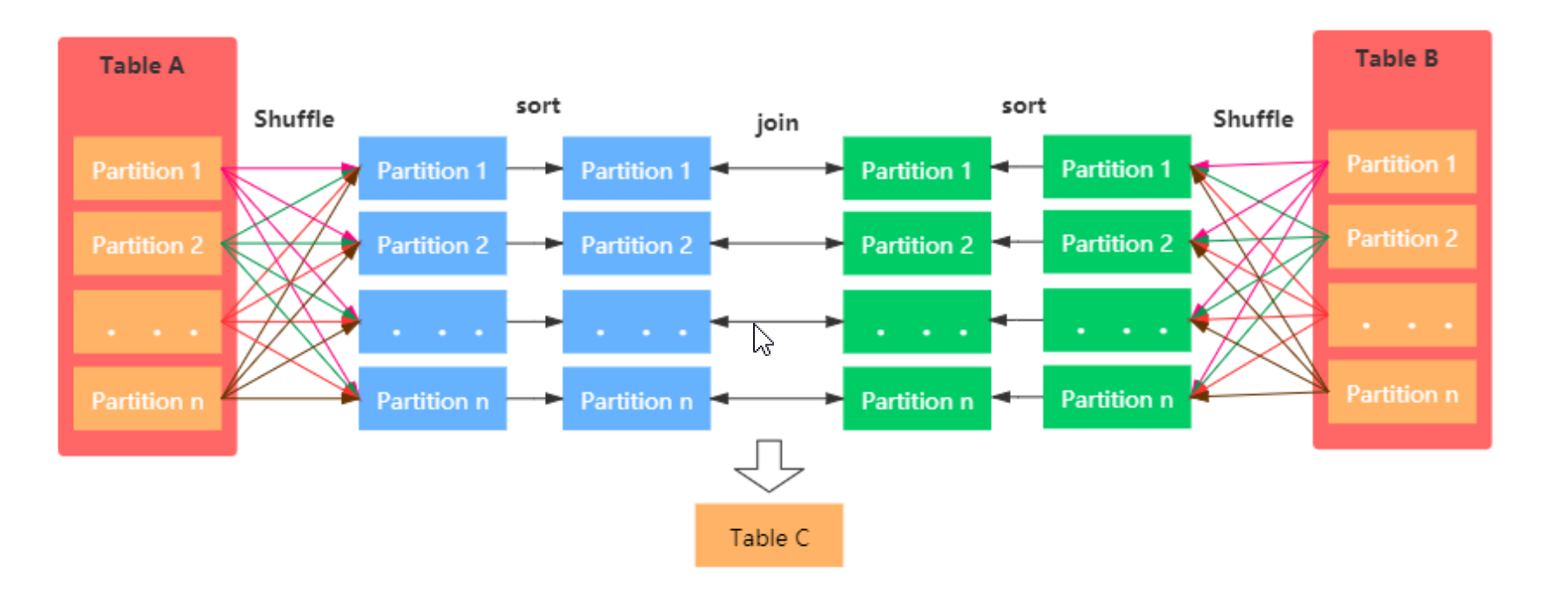
Sort Merge Bucket Join:在进行表join前,先把两张大表进行排序,并把同一个key的表数据放进一个桶中,把大表化成小表,减少数据的扫描范围,最终把各个桶中的数据进行JOIN操作。

- 数据倾斜
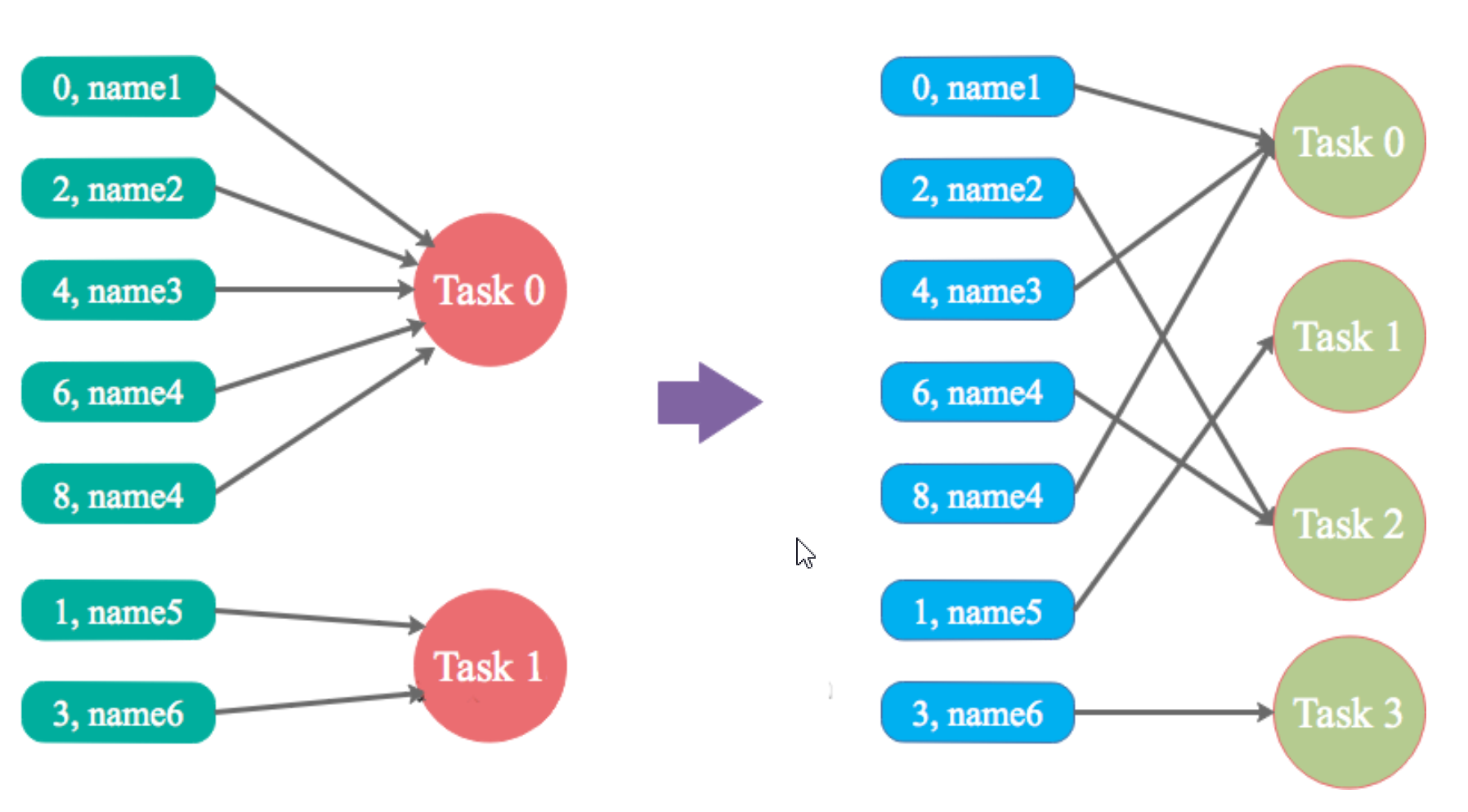
数据倾斜,即单个节点任务所处理的数据量远大于同类型任务所处理的数据量,导致该节点成为整个作业的瓶颈,这 是分布式系统不可能避免的问题。
在并行计算的作业中,整个作业的进度是由运行时间最长的那个 Task 决定的,在出现数据倾斜 时,整个作业的运行将会非常缓慢,甚至会发生 OOM 异常。
- 单表数据倾斜优化
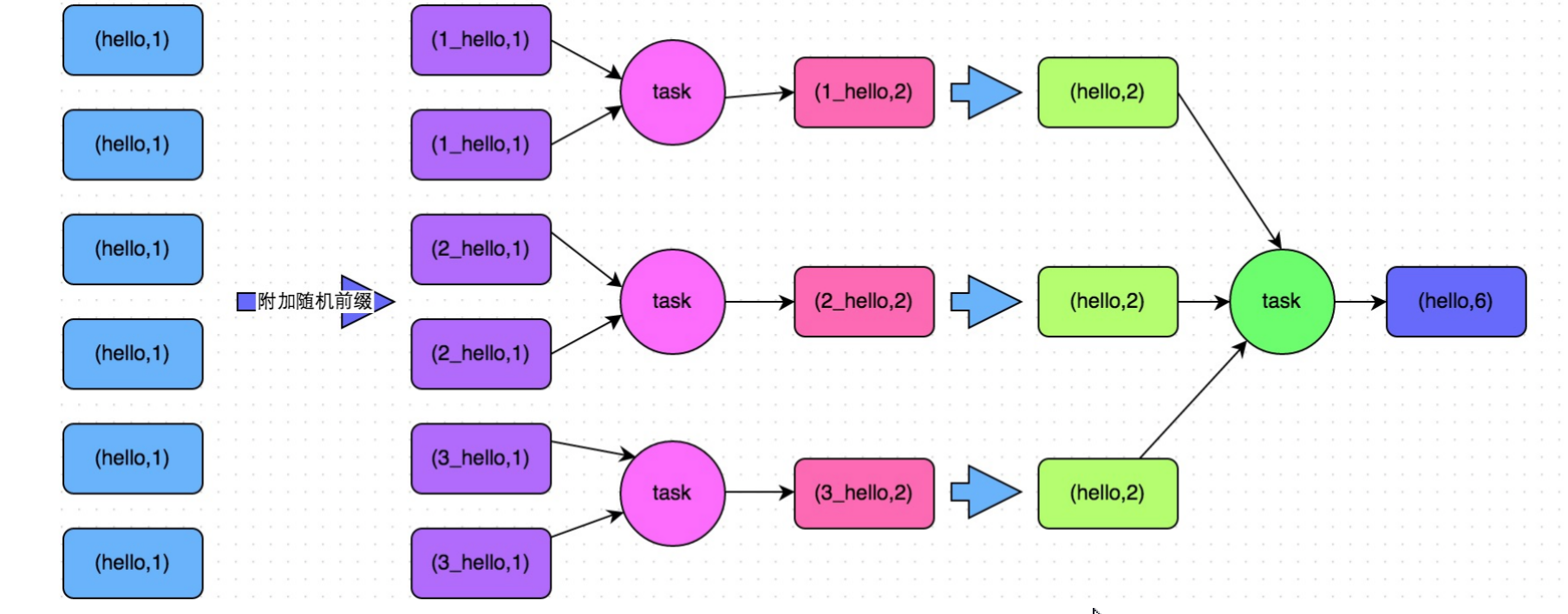
两阶段聚合(加盐局部聚合 + 去盐全局聚合)+ Map-Side 聚合(将 groupByKey 算子转换为 reduceByKey 算子,reduceByKey 可以在 Map 端预聚合,类似于 MapReduce 中的 Combiner)。
首先,通过 map 算子给每个数据的 Key 添加随机数前缀,对 Key 进行打散,将原先一样的 Key 变成不一样的 Key,然 后进行第一次聚合,这样就可以让原本被一个 Task 处理的数据分散到多个 Task 上去做局部聚合;随后,去除掉每个 Key 的前缀,再次进行聚合。
- 多表join数据倾斜优化
广播JOIN: 在 Spark JOIN 策略中,当一张小表足够小并且可以先缓存到内存中时,可以使用 Broadcast Hash Join,其原理就是先 将小表聚合到 Driver 端,再广播到各个大表分区中,那么再次进行 JOIN 时,就相当于大表的各自分区的数据与小表进行 本地 JOIN,从而规避了 Shuffle。广播 JOIN 是 Spark SQL 中最常用的优化方案。
适用场景:适用于小表 JOIN 大表。小表足够小,可被加载到 Driver 端并通过 Broadcast 广播到各个 Executor 中。
大小表 JOIN:把大表中的key加随机前缀,打散分配不同分区进行处理,然后将小表进行膨胀开来,与打散分区后的大表进行join,就能避免数据倾斜。
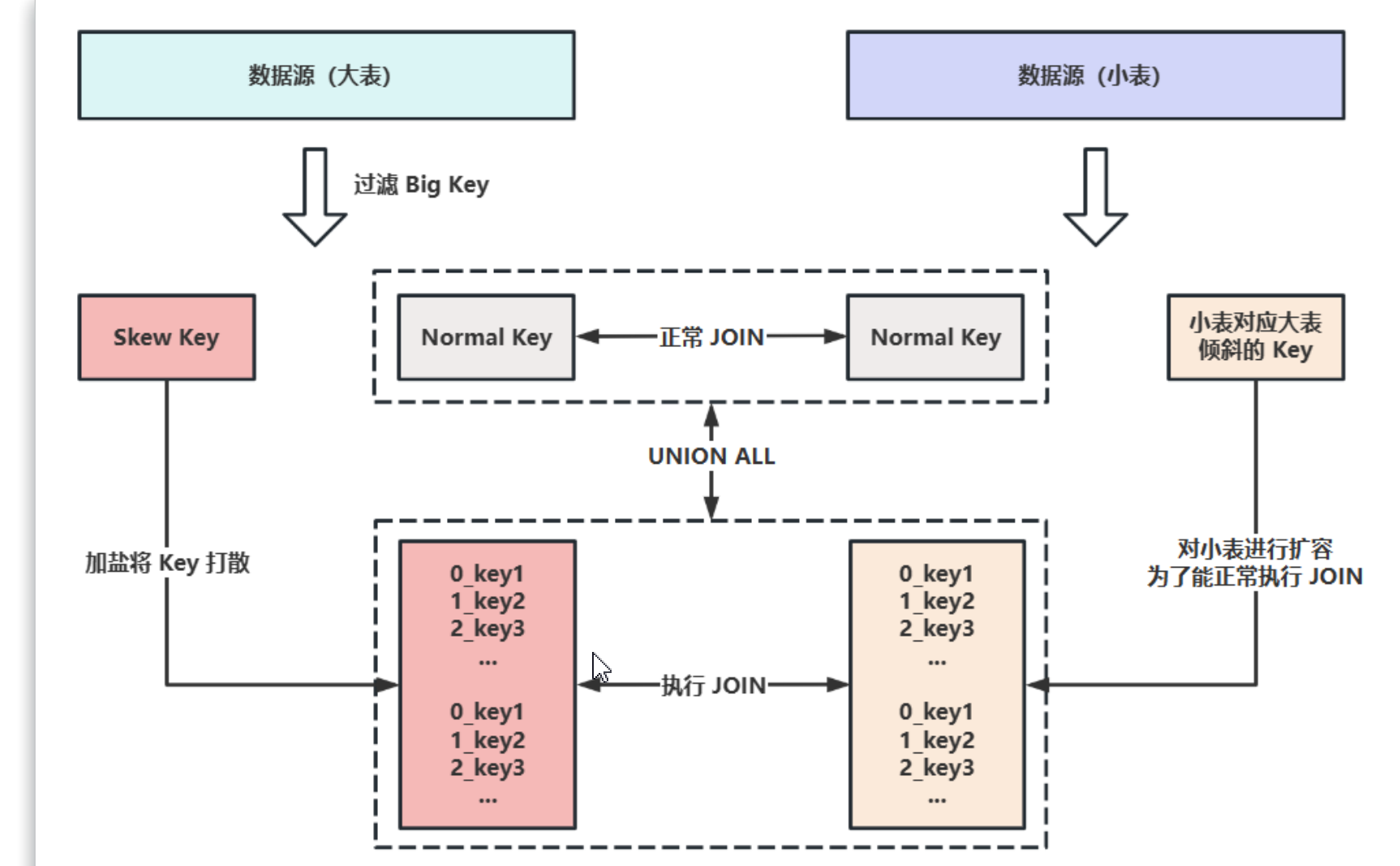
- 其他处理数据倾斜的方案
Hive ETL 预处理数据:方案实现思路:此时可以评估一下,是否可以通过 Hive 来进行数据预处理(即通过 Hive ETL 预先对数据按照 Key 进 行聚合,或者是预先和其他表进行 JOIN),然后在 Spark 作业中针对的数据源就不是原来的 Hive 表了,而是预处理后的 Hive 表。此时由于数据已经预先进行过聚合或 JOIN 操作,那么在 Spark 作业中也就不需要使用原先的 Shuffle 类算子执行 这类操作了。
过滤少数导致倾斜的 Key:将导致数据倾斜的 Key 给过滤掉之后,这些 Key 就不会参与计算了,自然不可能产生数据倾斜.
提高 Shuffle 操作的并行度:增加 Shuffle Read Task 的数量,可以让原本分配给一个 Task 的多个 Key 分配给多个 Task,从而让每 个 Task 处理比原来更少的数据。
- job优化
Map端分区内进行预聚合,其他节点在拉取所 有节点上相同的 Key 时,就会大大减少需要拉取的数据数量,从而也就减少了磁盘 IO 以及网络传输开销。
单个文件较大:调小 spark.sql.files.maxPartitionBytes 可提高 map 任务数,但注意最后要合并小文件(Spark3.0 新特 性 AQE 默认已开启 Shuffle 合并),否则数据写入 HDFS 会造成小文件过多;
小文件过多:调大 spark.sql.files.maxPartitionBytes 并同时设置 spark.files.openCostInBytes 为最小文件数的大小,可以 控制多个小文件合并到一个分区,减少分区读取。
Reduce 端优化:
合理设置 Reduce 数量:在 Spark 中 Reduce 数量其实就是最后执行的 Task 的数量,这个是和并行度相关的,spark.default.parallelism :RDD 任务的默认并行度,Spark 中所谓的并行度是指 RDD 中的分区数,即 RDD 中 的 Task 数。(调整并行数)设置初始分区的 2~3 倍之间。例如向 YARN 申请的 Executor Cores 资源个数为 10 个,根据当前任务的提交参数,将此参数设置为 20 或 30 为最优效果.(调整并行数)
推荐在插入表数据前进行缩小分区操作,如 coalesce 算子和 repartition 算子,因为 coalesce 算子不会产生 Shuffle。(缩小分区数)
Spark Shuffle 过程中,Shuffle Reduce Task 的 Buffer 缓冲区大小决定了 Reduce Task 每次能够拉取的数据量,如果内存 资源较为充足,适当增加拉取数据缓冲区的大小,可以减少拉取数据的次数,也就可以减少网络传输的次数,进而提升性 能。(增加缓存空间)
调整拉取重试次数:Reduce Task拉取属于自己的数据时,如果因为网络异常导致拉取失败,会自动重试,可以适当增大次数,防止因数据拉取失败导致作业执行失败!
调整拉取重试隔间时间:reduce Task拉取数据重试时间,增加shuffle操作的稳定性!
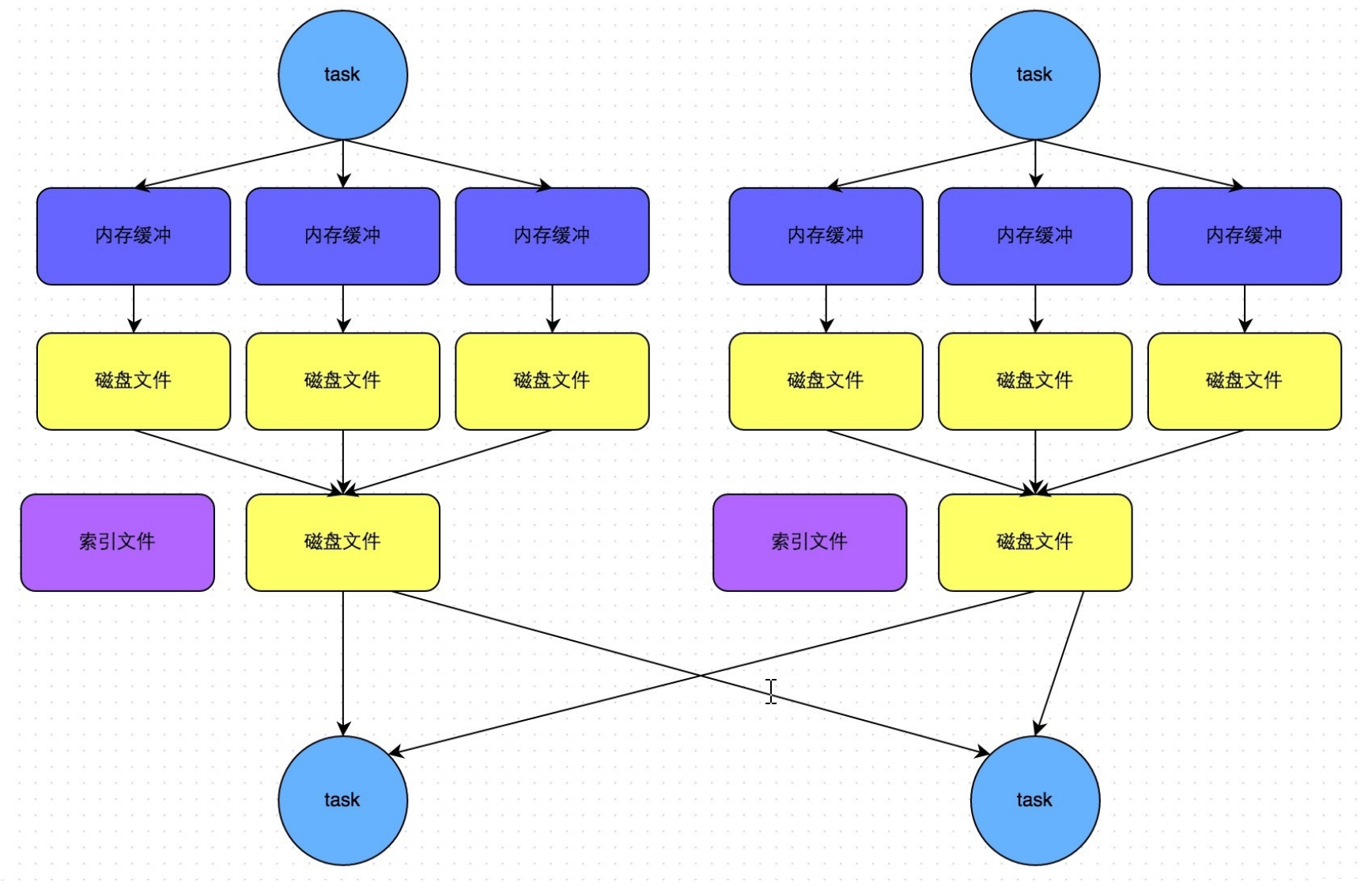
- 合理利用ByPass
在这种机制下,当前 Stage 的 Task 会为下游的每个 Task 都创建临时磁盘文件。将数据按照 Key 值进行 Hash,然后根 据 Hash 值,将 Key 写入对应的磁盘文件中(这也相当于一次另类的排序,将相同的 Key 放在一起了)。最终,同样会将 所有临时文件依次合并成一个磁盘文件,建立索引。
- 数据本地化
核心思想:计算向数据靠拢,移动数据不如移动数据。
等级:
PROCESS_LOCAL :进程本地化,性能最好。指代码和数据在同一个进程中,也就是同一个 Executor 中;计算数据的 Task 由 Executor 执行,此时数据在 Executor 的 BlockManager 中;
NODE_LOCAL :节点本地化。代码和数据在同一个节点中,数据存储在节点的 HDFS Block,Task 在节点的某个 Executror 执行;或者数据和 Task 在同一个节点不同的 Executor 中,数据需要跨进程传输;
RACK_LOCAL :机架本地化。数据和 Task 在一个机架的两个节点上,数据需要通过网络在节点之间进行传输;
NO_PREF :没有最佳位置这一说,数据从哪里访问都一样,不需要位置优先,比如 SparkSQL 直接读取 MySQL;
ANY :数据和 Task 可能在集群中的任何地方,而且不在一个机架中,性能最差。
- 总结:计算时会从进程本地化开始找依次向下找,我们可以跳转数据查找的等待时间,让计算逻辑在合理的时间内找到最近的数据。
- 调节连接等待时长
调节连接等待时长:Task在运行时,由于时间太短,数据没有被拉取处理,被java的垃圾回收机制清理掉,导致整个Excutor无法正常处理数据,可以延长连接等待时间。
--conf spark.network.timeout=300s
- Spark代码优化
避免创建重复的RDD、避免使用Suffle类算子、使用广播变量(对大变量进行广播)、使用Map-Side预聚合Shuffle操作、使用Kryo序列化器、优化数据结构、使用高性能库(fastutil)
避免使用Shuffle类算子:尽量不使用ReduceByKey、groupBykey、repartition等会引发Shuffle的算子。
使用广播变量:把较大表广播出去,可以实现每个Excutor共享只读变量,提高shuffle的查询效率。
Map-Side预聚合:在MapTask阶段,使用组合器进行局部聚合,减少shuffle阶段落盘次数。
使用Kryo序列化器:在传输对象数据时,使用Kryo序列化器,可以提高网络IO传输速率。
优化数据结构:尽量把对象用字符串替代,字符串用基本数据类型替代(Int,long,char等),集合用数组替代。
使用高性能库:使用第三方高性能库,比如fastUtil等。
十、Spark3新特性
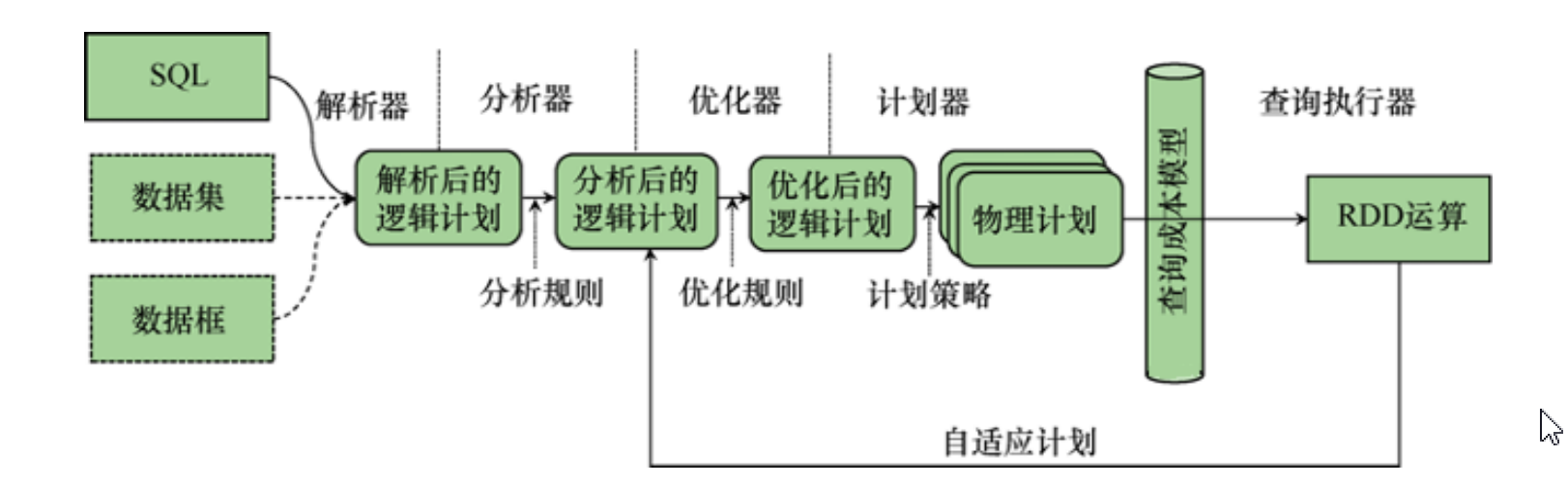
AQE:Adaptive Query Execution(AQE) 是英特尔大数据技术团队和百度大数据基础架构部工程师在 Spark 社区版本的基础 上,改进并实现的自适应执行引擎。
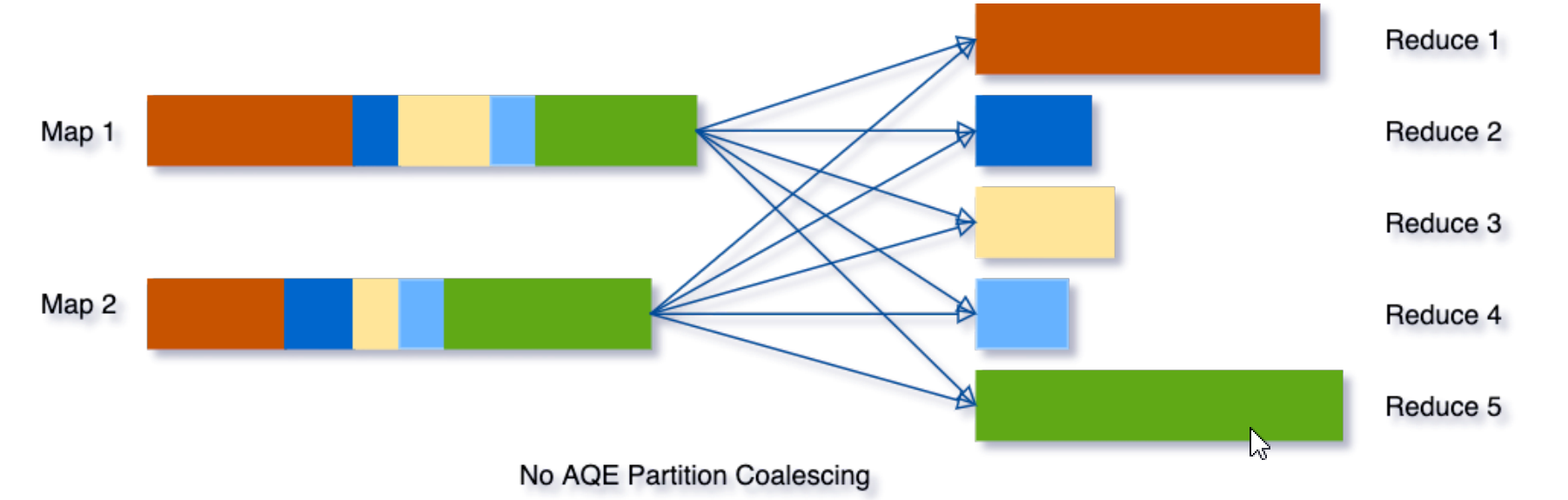
动态合并 Shuffle 分区:为了解决这个问题,我们可以在任务开始时先设置较多的 Shuffle 分区数,然后在运行时通过查看 Shuffle 文件统计信 息将相邻的小分区合并成更大的分区。
动态切换 JOIN 策略 动态切换 JOIN 策略
DPP:的第二个比较重要的性能优化是动态分区裁减(Dynamic Partition Pruning,简称 DPP),所谓的动态分区裁 剪就是基于运行时(RunTime)推断出来的信息来进一步进行分区裁剪,从而减少事实表中数据的扫描量、降低 I/O 开 销,提升执行性能。
需要剪裁的表必须是分区表,且分区字段必须在 ON 条件中;
JOIN 类型必须是 INNER、LEFT OUTER(右表为分区表)、RIGHT OUTER(左表为分区表)、LEFT SEMI(无限制); 另一张表需要存在至少一个过滤条件,比如 FROM A JOIN B ON A.key = B.key WHERE A.id = 5。
本文来自博客园,作者:戴莫先生Study平台,转载请注明原文链接:https://www.cnblogs.com/smallzengstudy/p/17843382.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号