【玄铁杯第三届RISC-V应用创新大赛】LicheePi 4A Yolov5n的HHB编译顺利通过的环境
【玄铁杯第三届RISC-V应用创新大赛】LicheePi 4A Yolov5n的HHB编译顺利通过的环境
实验环境:
win11+WSL2+vscode
一、环境搭建(虚拟机vmware和wsl应该都行,博主两种环境都有分别在两台电脑上,主要介绍博主目前使用环境)
1.1. 安装WSL2
为什么安装wsl2不安装wsl,因为我觉得wsl2新一些优化应该好一些,其实都行,依据自己的喜好。
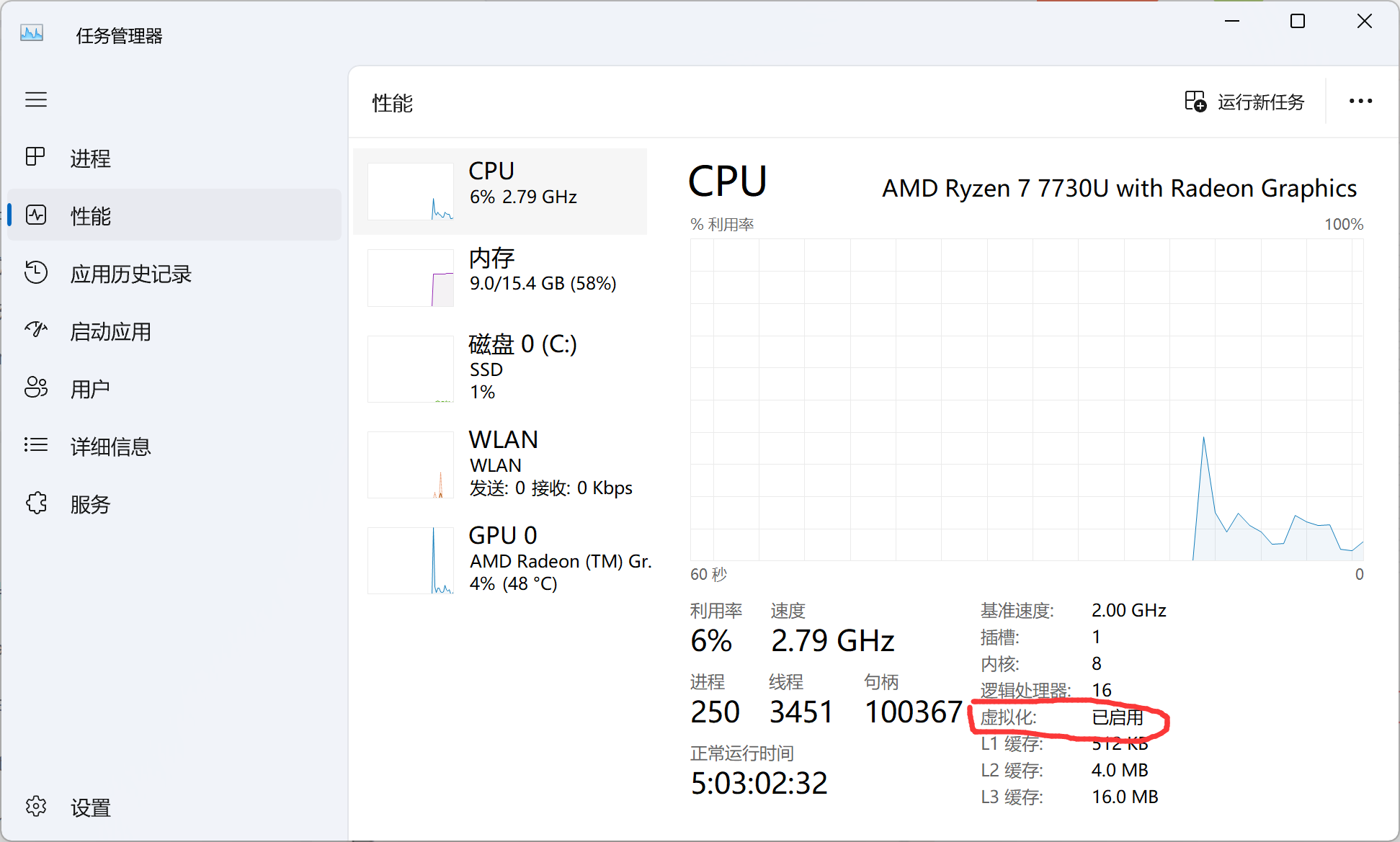
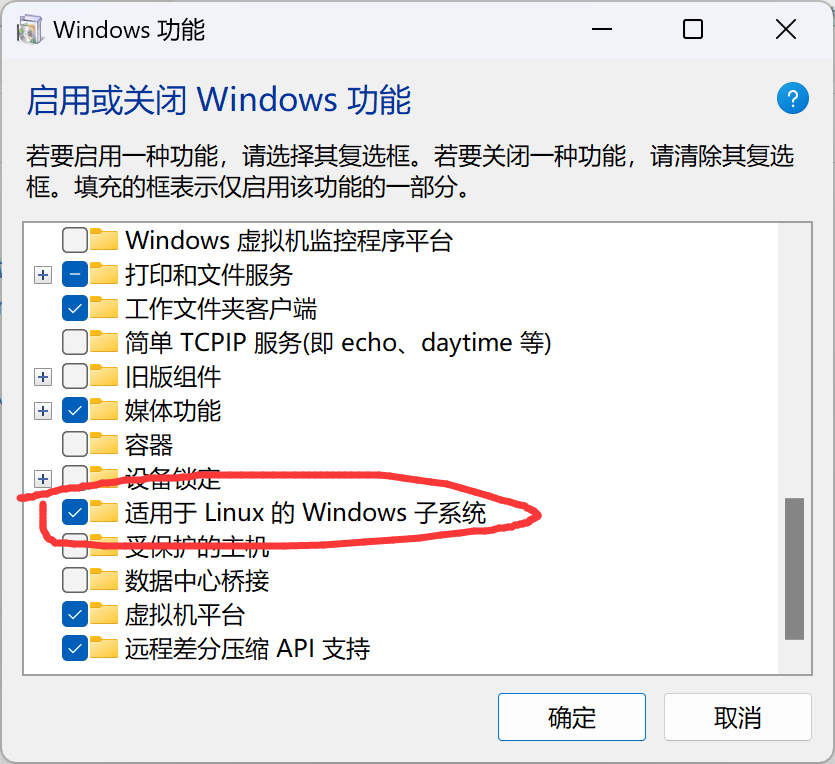
开启虚拟化(控制面板 --> 程序 网上还说了需要开启 Hyper-V , 博主我没有开启也没有影响,因为说开了会电脑变卡,我就没管,只是勾选了适用于linux子系统)
1.2 wsl2配置
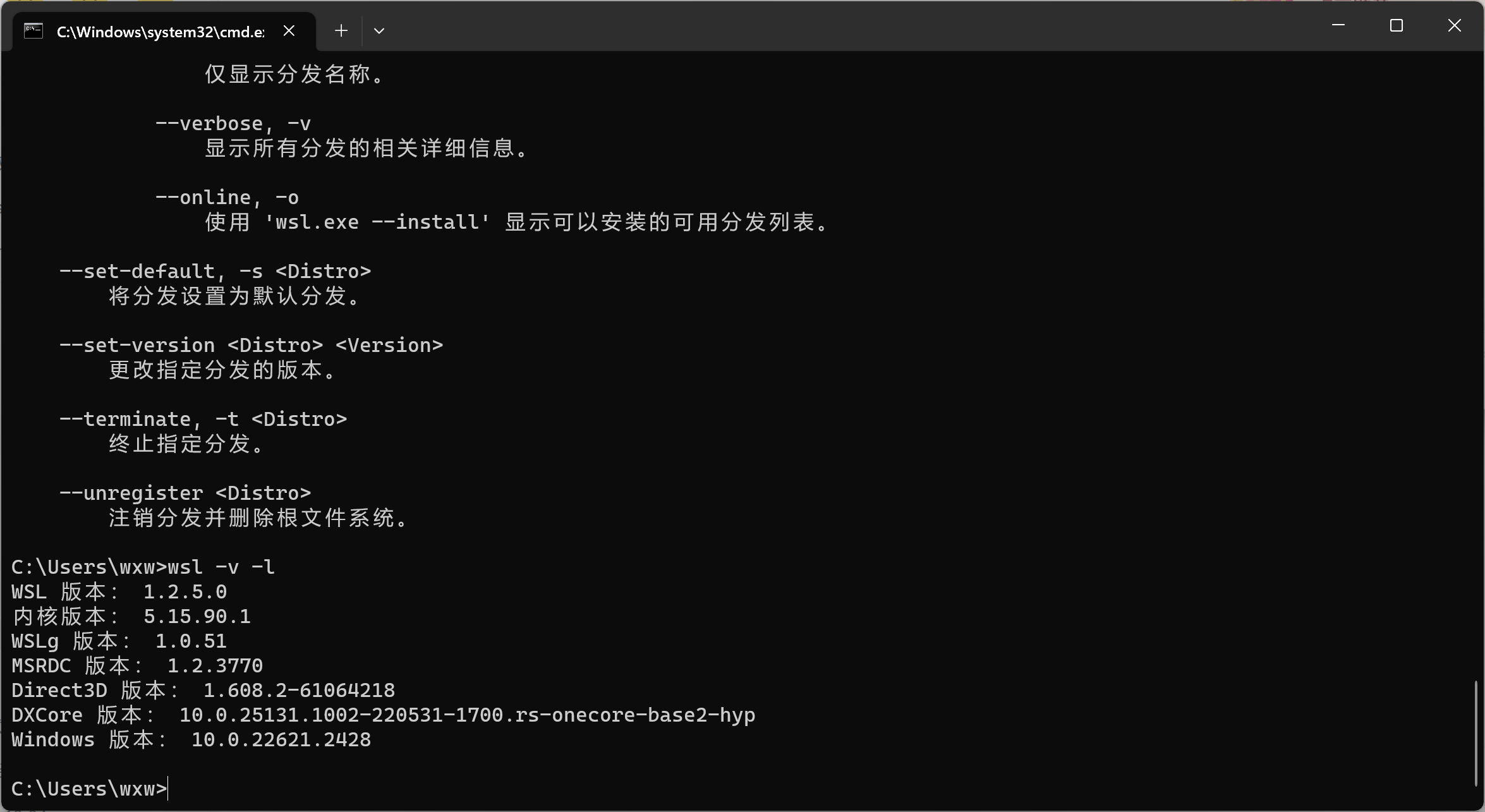
更新WSL2
wsl --update
查看版本
wsl -v -l
设置WSL默认版本
wsl --set-default-version 2
1.3 下载ubuntu镜像
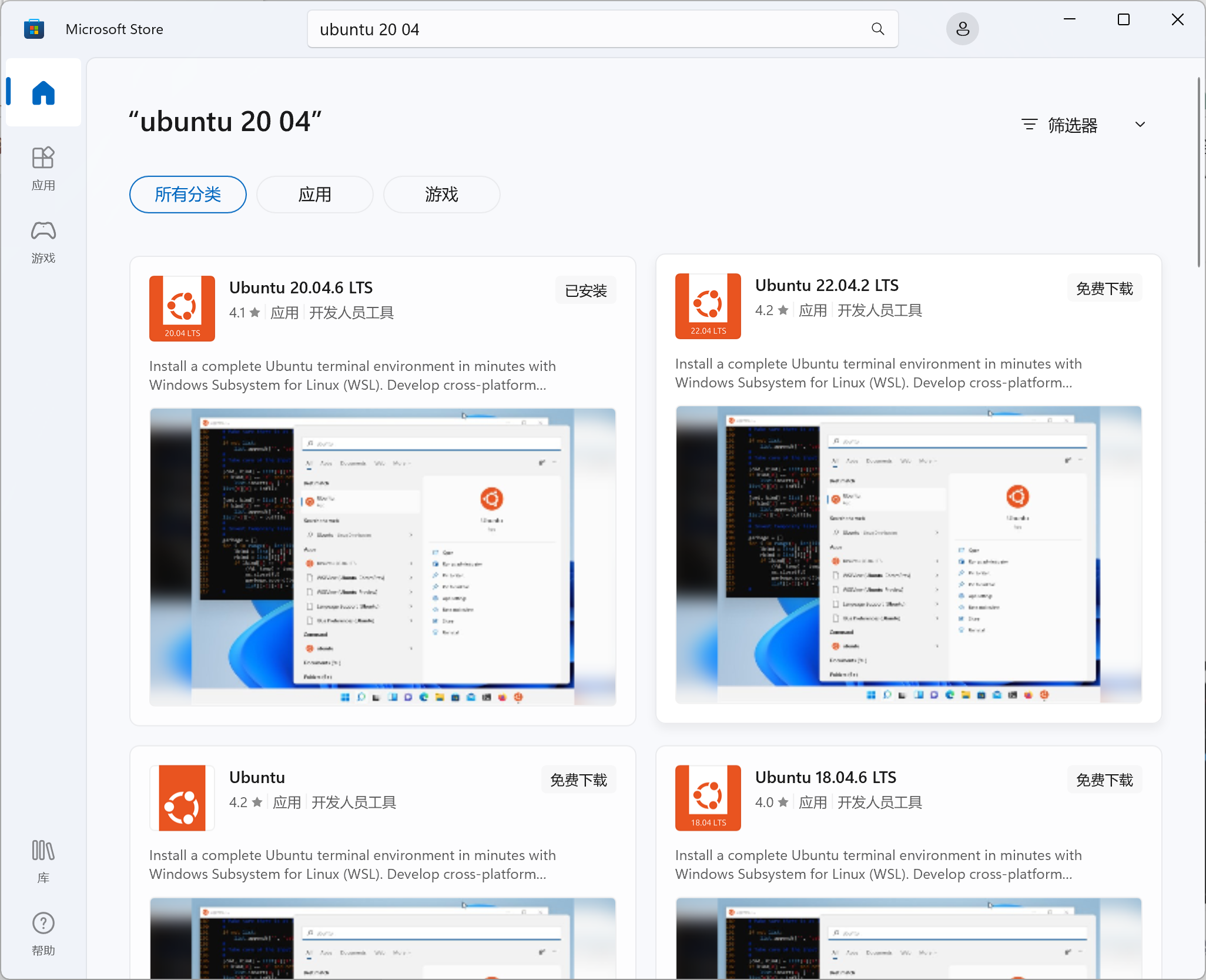
打开微软商店下载ubuntu20.04(根据自己的喜好,下载22.04也行,博主安装的是20.04)
1.4 配置vscode环境
打开vscode后安装wsl插件,然后会自动加载wsl系统
二、yolovn模型 hhb编译以及量化
2.1搭建docker环境并启动容器
首先要在自己的电脑上安装 Docker,先卸载可能存在的 Docker 版本:
sudo apt-get remove docker docker-engine docker.io containerd runc
安装Docker依赖的基础软件:
sudo apt-get update
sudo apt-get install apt-transport-https ca-certificates curl gnupg-agent software-properties-common
添加官方源
sudo apt-get update
sudo apt-get install apt-transport-https ca-certificates curl gnupg-agent software-properties-common
安装 Docker:
sudo apt-get update
sudo apt-get install docker-ce docker-ce-cli containerd.io
安装完毕后,获取 HHB 环境的 Docker 镜像
docker pull hhb4tools/hhb:2.4.5(如果有人拉取很慢的原因,可以挂上代理,速度会快很多)
拉取镜像完毕后,使用下面的命令进入 Docker 镜像:
docker run -itd --name=your.hhb2.4 -p 22 "hhb4tools/hhb:2.4.5"
docker exec -it your.hhb2.4 /bin/bash
进入 Docker 镜像后,可使用下面的命令确认 HHB 版本并配置交叉编译环境:
hhb --version
export PATH=/tools/Xuantie-900-gcc-linux-5.10.4-glibc-x86_64-V2.6.1-light.1/bin/:$PATH
2.2 开始编译yolov5n模型以及量化
2.2.1 复现一下之前别人的错误
cd /home
git clone https://github.com/ultralytics/yolov5.git
cd yolov5
pip3 install ultralytics
python3 export.py --weights yolov5n.pt --include onnx
下面是博主的输出信息,可见已经得到了onnx模型
root@3eb4c58bfd83:/home/yolov5# python3 export.py --weights yolov5n.pt --include onnx
export: data=data/coco128.yaml, weights=['yolov5n.pt'], imgsz=[640, 640], batch_size=1, device=cpu, half=False, inplace=False, keras=False, optimize=False, int8=False, dynamic=False, simplify=False, opset=17, verbose=False, workspace=4, nms=False, agnostic_nms=False, topk_per_class=100, topk_all=100, iou_thres=0.45, conf_thres=0.25, include=['onnx']
YOLOv5 🚀 v7.0-226-gdd9e338 Python-3.8.10 torch-2.1.0+cu121 CPU
Fusing layers...
YOLOv5n summary: 213 layers, 1867405 parameters, 0 gradients, 4.5 GFLOPs
PyTorch: starting from yolov5n.pt with output shape (1, 25200, 85) (3.9 MB)
ONNX: starting export with onnx 1.14.0...
ONNX: export success ✅ 0.5s, saved as yolov5n.onnx (7.6 MB)
Export complete (0.8s)
Results saved to /home/yolov5
Detect: python detect.py --weights yolov5n.onnx
Validate: python val.py --weights yolov5n.onnx
PyTorch Hub: model = torch.hub.load('ultralytics/yolov5', 'custom', 'yolov5n.onnx')
Visualize: https://netron.app
root@3eb4c58bfd83:/home/yolov5# ls
CITATION.cff README.md classify export.py models setup.cfg utils yolov5n.pt
CONTRIBUTING.md README.zh-CN.md data hhb_out requirements.txt train.py val.py yolov5n_hat.onnx
LICENSE benchmarks.py detect.py hubconf.py segment tutorial.ipynb yolov5n.onnx yolov5n_hat.pt
root@3eb4c58bfd83:/home/yolov5#
cd /home/example/th1520_npu/yolov5n
cp ../../../yolov5/yolov5n.onnx ./
hhb -D --model-file yolov5n.onnx --data-scale-div 255 --board th1520 --input-name "images" --output-name "/model.24/m.0/Conv_output_0;/model.24/m.1/Conv_output_0;/model.24/m.2/Conv_output_0" --input-shape "1 3 384 640" --calibrate-dataset kite.jpg --quantization-scheme "int8_asym"
博主的输出信息:
root@3eb4c58bfd83:/home/example/th1520_npu/yolov5n# ls
coco.names inference.py kite.jpg yolov5n.c
root@3eb4c58bfd83:/home/example/th1520_npu/yolov5n# cp ../../../yolov5/yolov5n.onnx ./
root@3eb4c58bfd83:/home/example/th1520_npu/yolov5n# ls
coco.names inference.py kite.jpg yolov5n.c yolov5n.onnx
root@3eb4c58bfd83:/home/example/th1520_npu/yolov5n#
root@3eb4c58bfd83:/home/example/th1520_npu/yolov5n# hhb -D --model-file yolov5n.onnx --data-scale-div 255 --board th1520 --input-name "images" --output-name "/model.24/m.0/Conv_output_0;/model.24/m.1/Conv_output_0;/model.24/m.2/Conv_output_0" --input-shape "1 3 384 640" --calibrate-dataset kite.jpg --quantization-scheme "int8_asym"
[2023-10-17 12:39:46] (HHB LOG): Start import model.
Traceback (most recent call last):
File "/usr/local/bin/hhb", line 8, in <module>
sys.exit(main())
File "/usr/local/lib/python3.8/dist-packages/hhb/main.py", line 470, in main
sys.exit(_main(argv))
File "/usr/local/lib/python3.8/dist-packages/hhb/main.py", line 464, in _main
arg_manage.run_command(args_filter, curr_command_type)
File "/usr/local/lib/python3.8/dist-packages/hhb/core/arguments_manage.py", line 1461, in run_command
return args_filter.filtered_args.func(args_filter)
File "/usr/local/lib/python3.8/dist-packages/hhb/core/main_command_manage.py", line 121, in driver_main_command
mod, params = import_model(
File "/usr/local/lib/python3.8/dist-packages/hhb/core/frontend_manage.py", line 392, in import_model
mod, params = frontend.load(path, input_name, input_shape, output_name)
File "/usr/local/lib/python3.8/dist-packages/hhb/core/frontend_manage.py", line 95, in load
return relay.frontend.from_onnx(onnx_model, input_dict)
File "/usr/local/lib/python3.8/dist-packages/tvm/relay/frontend/onnx.py", line 5924, in from_onnx
mod, params = g.from_onnx(graph, opset)
File "/usr/local/lib/python3.8/dist-packages/tvm/relay/frontend/onnx.py", line 5585, in from_onnx
self._construct_nodes(graph)
File "/usr/local/lib/python3.8/dist-packages/tvm/relay/frontend/onnx.py", line 5697, in _construct_nodes
op = self._convert_operator(op_name, inputs, attr, self.opset)
File "/usr/local/lib/python3.8/dist-packages/tvm/relay/frontend/onnx.py", line 5817, in _convert_operator
sym = convert_map[op_name](inputs, attrs, self._params)
File "/usr/local/lib/python3.8/dist-packages/tvm/relay/frontend/onnx.py", line 623, in _impl_v1
input_shape = infer_shape(data)
File "/usr/local/lib/python3.8/dist-packages/tvm/relay/frontend/common.py", line 528, in infer_shape
out_type = infer_type(inputs, mod=mod)
File "/usr/local/lib/python3.8/dist-packages/tvm/relay/frontend/common.py", line 503, in infer_type
new_mod = _transform.InferType()(new_mod)
File "/usr/local/lib/python3.8/dist-packages/tvm/ir/transform.py", line 161, in __call__
return _ffi_transform_api.RunPass(self, mod)
File "tvm/_ffi/_cython/./packed_func.pxi", line 331, in tvm._ffi._cy3.core.PackedFuncBase.__call__
File "tvm/_ffi/_cython/./packed_func.pxi", line 262, in tvm._ffi._cy3.core.FuncCall
File "tvm/_ffi/_cython/./packed_func.pxi", line 251, in tvm._ffi._cy3.core.FuncCall3
File "tvm/_ffi/_cython/./base.pxi", line 181, in tvm._ffi._cy3.core.CHECK_CALL
tvm._ffi.base.TVMError: Traceback (most recent call last):
7: TVMFuncCall
6: tvm::runtime::PackedFuncObj::Extractor<tvm::runtime::PackedFuncSubObj<tvm::runtime::TypedPackedFunc<tvm::IRModule (tvm::transform::Pass, tvm::IRModule)>::AssignTypedLambda<tvm::transform::{lambda(tvm::transform::Pass, tvm::IRModule)#7}>(tvm::transform::{lambda(tvm::transform::Pass, tvm::IRModule)#7}, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >)::{lambda(tvm::runtime::TVMArgs const&, tvm::runtime::TVMRetValue*)#1}> >::Call(tvm::runtime::PackedFuncObj const*, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >, tvm::runtime::TVMRetValue)
5: tvm::transform::Pass::operator()(tvm::IRModule) const
4: tvm::transform::Pass::operator()(tvm::IRModule, tvm::transform::PassContext const&) const
3: tvm::transform::ModulePassNode::operator()(tvm::IRModule, tvm::transform::PassContext const&) const
2: _ZN3tvm7runtime13PackedFuncObj9ExtractorINS0_16PackedFuncSubObjIZNS0_15TypedPackedFuncIFNS_8IRModuleES5_NS_9transform11PassContextEEE17AssignTypedLambdaIZNS_5relay9transform9InferTypeEvEUlS5_RKS7_E_EEvT_EUlRKNS0_7TVMArgsEPNS0_11TVMRetValueEE_EEE4CallEPKS1_SH_SL_
1: tvm::relay::TypeInferencer::Infer(tvm::GlobalVar, tvm::relay::Function)
0: tvm::relay::TypeSolver::Solve() [clone .cold]
File "/flow/hhb/src/relay/analysis/type_solver.cc", line 624
TVMError:
---------------------------------------------------------------
An error occurred during the execution of TVM.
For more information, please see: https://tvm.apache.org/docs/errors.html
---------------------------------------------------------------
Check failed: (false) is false: relay.concatenate requires all tensors have the same shape on non-concatenating axes
root@3eb4c58bfd83:/home/example/th1520_npu/yolov5n#
以上复现就是和之前提交问题没有解决的一样的报错,那么怎么解决这个问题?
2.2.2博主提供的一种解决方法(这也是博主询问和摸索得到的,首先感谢hhb4tools 的工程师大佬)
首先问题出现的原因:yolov5n.c是模型输入尺寸为384 640,而官方的默认模型尺寸为640 640,所以尺寸不匹配当然会报错,所以解决方法有两种一种是修改尺寸,一种是修改yolov5n.c文件。(博主展示的方法是前一种)
cd /home
git clone https://github.com/ultralytics/yolov5.git
cd yolov5
pip3 install ultralytics
python3 export.py --weights yolov5n.pt --include onnx -imgsz 384 640
cd /home/example/th1520_npu/yolov5n
cp ../../../yolov5/yolov5n.onnx ./
hhb -D --model-file yolov5n.onnx --data-scale-div 255 --board th1520 --input-name "images" --output-name "/model.24/m.0/Conv_output_0;/model.24/m.1/Conv_output_0;/model.24/m.2/Conv_output_0" --input-shape "1 3 384 640" --calibrate-dataset kite.jpg --quantization-scheme "int8_asym"
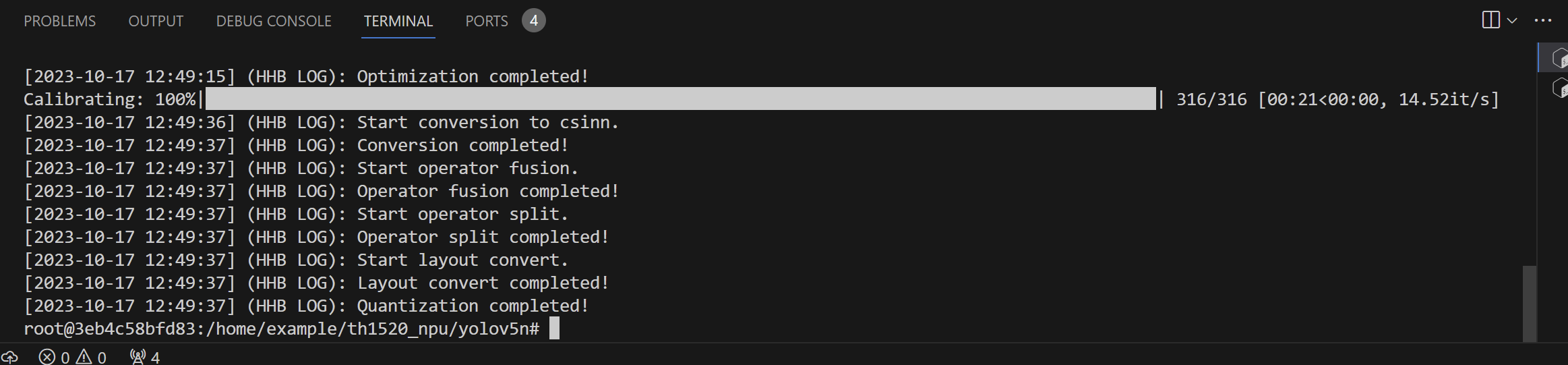
输出信息,可见编译通过,所以这个博主我提供的一种解决方法:
root@3eb4c58bfd83:/home/yolov5# python3 export.py --weights yolov5n.pt --include onnx --imgsz 384 640
export: data=data/coco128.yaml, weights=['yolov5n.pt'], imgsz=[384, 640], batch_size=1, device=cpu, half=False, inplace=False, keras=False, optimize=False, int8=False, dynamic=False, simplify=False, opset=17, verbose=False, workspace=4, nms=False, agnostic_nms=False, topk_per_class=100, topk_all=100, iou_thres=0.45, conf_thres=0.25, include=['onnx']
YOLOv5 🚀 v7.0-226-gdd9e338 Python-3.8.10 torch-2.1.0+cu121 CPU
Fusing layers...
YOLOv5n summary: 213 layers, 1867405 parameters, 0 gradients, 4.5 GFLOPs
PyTorch: starting from yolov5n.pt with output shape (1, 15120, 85) (3.9 MB)
ONNX: starting export with onnx 1.14.0...
ONNX: export success ✅ 0.4s, saved as yolov5n.onnx (7.4 MB)
Export complete (0.6s)
Results saved to /home/yolov5
Detect: python detect.py --weights yolov5n.onnx
Validate: python val.py --weights yolov5n.onnx
PyTorch Hub: model = torch.hub.load('ultralytics/yolov5', 'custom', 'yolov5n.onnx')
Visualize: https://netron.app
root@3eb4c58bfd83:/home/yolov5# cd /home/example/th1520_npu/yolov5n
root@3eb4c58bfd83:/home/example/th1520_npu/yolov5n# cp ../../../yolov5/yolov5n.onnx ./
root@3eb4c58bfd83:/home/example/th1520_npu/yolov5n# ls
coco.names inference.py kite.jpg yolov5n.c yolov5n.onnx
root@3eb4c58bfd83:/home/example/th1520_npu/yolov5n# hhb -D --model-file yolov5n.onnx --data-scale-div 255 --board th1520 --input-name "images" --output-name "/model.24/m.0/Conv_output_0;/model.24/m.1/Conv_output_0;/model.24/m.2/Conv_output_0" --input-shape "1 3 384 640" --calibrate-dataset kite.jpg --quantization-scheme "int8_asym"
[2023-10-17 12:49:13] (HHB LOG): Start import model.
[2023-10-17 12:49:14] (HHB LOG): Model import completed!
[2023-10-17 12:49:14] (HHB LOG): Start quantization.
[2023-10-17 12:49:14] (HHB LOG): get calibrate dataset from kite.jpg
[2023-10-17 12:49:14] (HHB LOG): Start optimization.
[2023-10-17 12:49:15] (HHB LOG): Optimization completed!
Calibrating: 100%|██████████████████████████████████████████████████████████████████████████████████████████████| 316/316 [00:21<00:00, 14.52it/s]
[2023-10-17 12:49:36] (HHB LOG): Start conversion to csinn.
[2023-10-17 12:49:37] (HHB LOG): Conversion completed!
[2023-10-17 12:49:37] (HHB LOG): Start operator fusion.
[2023-10-17 12:49:37] (HHB LOG): Operator fusion completed!
[2023-10-17 12:49:37] (HHB LOG): Start operator split.
[2023-10-17 12:49:37] (HHB LOG): Operator split completed!
[2023-10-17 12:49:37] (HHB LOG): Start layout convert.
[2023-10-17 12:49:37] (HHB LOG): Layout convert completed!
[2023-10-17 12:49:37] (HHB LOG): Quantization completed!
root@3eb4c58bfd83:/home/example/th1520_npu/yolov5n#

 浙公网安备 33010602011771号
浙公网安备 33010602011771号