
python学习日记(文件操作)
文件操作概述
计算机系统分为:操作系统,计算机硬件,应用程序。
我们用python或其他语言编写的应用程序若想要把数据永久保存下来,必须要保存于硬盘中,这就涉及到应用程序要操作硬件,众所周知,应用程序是无法直接操作硬件的,这就用到了操作系统。操作系统把复杂的硬件操作封装成简单的接口给用户/应用程序使用,其中文件就是操作系统提供给应用程序来操作硬盘虚拟概念,用户或应用程序通过操作文件,可以将自己的数据永久的保存下来。
读文件
#相对路径下创建的log文件,也可以绝对路径,不过要写完整路径名 f = open('log',mode='r',encoding='utf-8')#以什么编码方式创建的,以什么编码方式读出来 l = f.read() print(l) f.close() #文件使用完毕后必须关闭,因为文件对象会占用操作系统的资源, # 并且操作系统同一时间能打开的文件数量也是有限的
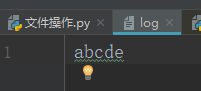

写文件
f = open('log',mode='w',encoding='utf-8')#写入的话是先清空原有内容,再写入新的数据,若文件不存在,创建新文件 f.write('这是新写入的内容') f.close() #对写完新内容的文件进行读取 f = open('log',mode='r',encoding='utf-8')#以什么编码方式创建的,以什么编码方式读出来 l = f.read() print(l) f.close() #文件使用完毕后必须关闭,因为文件对象会占用操作系统的资源, # 并且操作系统同一时间能打开的文件数量也是有限的

追加内容
#对文件进行追加内容,指针在文件末尾,若文件不存在,创建新文件 f = open('log',mode='a',encoding='utf-8') f.write('---这是追加的内容') f.close() #对追加完内容的文件进行读取 f = open('log',mode='r',encoding='utf-8')#以什么编码方式创建的,以什么编码方式读出来 l = f.read() print(l) f.close() #文件使用完毕后必须关闭,因为文件对象会占用操作系统的资源, # 并且操作系统同一时间能打开的文件数量也是有限的

二进制文件
前面讲的默认都是读取文本文件,并且是以utf-8编码的文本文件。要读取二进制文件,比如,图片、视频等,用'rb' 模式打开即可。非文本文件
rb
一、
f = open('log',mode='w',encoding='utf-8')#写入的话是先清空原有内容,再写入新的数据 f.write('abcd123') f.close() f = open('log',mode='rb')#bytes类型,非文本文件等 l = f.read() print(l) f.close() #文件使用完毕后必须关闭,因为文件对象会占用操作系统的资源, # 并且操作系统同一时间能打开的文件数量也是有限的

二、汉字
f = open('log',mode='w',encoding='utf-8')#写入的话是先清空原有内容,再写入新的数据 f.write('这是五个字') f.close() f = open('log',mode='rb')#bytes类型,非文本文件等 l = f.read() print(l) f.close() #文件使用完毕后必须关闭,因为文件对象会占用操作系统的资源, # 并且操作系统同一时间能打开的文件数量也是有限的

wb
一、
f = open('log',mode='wb')#写入的话是先清空原有内容,再写入新的数据,若文件不存在,创建新文件 f.write('abcde'.encode('utf-8'))#涉及到str-->bytes f.close() f = open('log',mode='r') l = f.read() print(l,type(l))#自动帮你转换成str f.close() #文件使用完毕后必须关闭,因为文件对象会占用操作系统的资源, # 并且操作系统同一时间能打开的文件数量也是有限的

二、汉字
f = open('log',mode='wb')#写入的话是先清空原有内容,再写入新的数据,若文件不存在,创建新文件 f.write('三个字'.encode())#涉及到str-->bytes,编码方式默认是utf-8 f.close() f = open('log',mode='r',encoding='utf-8') l = f.read() print(l,type(l))#自动帮你转换成str f.close() #文件使用完毕后必须关闭,因为文件对象会占用操作系统的资源, # 并且操作系统同一时间能打开的文件数量也是有限的

ab
同理,不再赘述。
读写r+
一、先读再写
f = open('log',mode='r+',encoding='utf-8')#打开一个文件用于读写 print(f.read())#读完,光标移动到最后,写才没有覆盖 f.write('123') f.close()

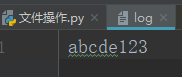
二、先写再读
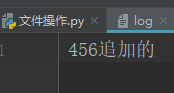
f = open('log',mode='r+',encoding='utf-8')#打开一个文件用于读写 f.write('456')#指针在文件开头 print(f.read()) f.close()

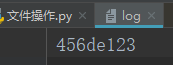
写完之后,指针在‘456’的后面,然后执行读,读的是当前指针之后的字符串。
w+
打开一个文件用于读写,并从头开始编辑,即原有内容会被删除,若文件不存在,创建新文件。
f = open('log',mode='w+',encoding='utf-8')#打开一个文件用于读写 f.write('456')#指针在文件开头 print(f.read())#指针已经到了最后,所以读是无输出的 f.close()
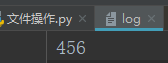
a+
打开一个文件用于读写,文件已存在,指针在文件末尾,不存在,创建新文件。
f = open('log',mode='a+',encoding='utf-8')#打开一个文件用于读写 f.write('追加的')#指针在文件末尾 print(f.read())#追加,所以读无输出 f.close()
二进制文件
同理。
seek (字节)
一、
f = open('log',mode='r+',encoding='utf-8')#打开一个文件用于读写 print(f.read()) f.close() f = open('log',mode='r+',encoding='utf-8')#打开一个文件用于读写 f.seek(3)#指针移到3,指定光标位置 print(f.read()) f.close()

二、
f = open('log',mode='w',encoding='utf-8') f.write('晴川历历汉阳树') f.close() f = open('log',mode='r+',encoding='utf-8')#打开一个文件用于读写 f.seek(3)#seek单位是字节,一个中文三个字节 print(f.read()) f.close()

对于中文,不是3的整数倍,就会引发异常。
tell(字节)
一、
f = open('log',mode='r+',encoding='utf-8')#打开一个文件用于读写 f.seek(3)#指针移到3,指定光标位置 print(f.tell())#找到指针当前位置,seek指定的为3 print(f.read()) f.close()

二、
f = open('log',mode='w',encoding='utf-8') f.write('晴川Abc') f.close() f = open('log',mode='r+',encoding='utf-8')#打开一个文件用于读写 f.seek(3)#seek单位是字节,一个中文三个字节 print(f.read(2))#从当前指针位置读取几个字符 print(f.tell())#tell单位是字节,找到指针当前位置 f.close()

read(字符)
f = open('log',mode='w',encoding='utf-8') f.write('晴川abc历历汉阳树') f.close() f = open('log',mode='r+',encoding='utf-8')#打开一个文件用于读写 f.seek(3)#seek单位是字节,一个中文三个字节 print(f.read(3))#从当前指针位置读取几个字符 f.close()

with ... as...
可以省去.close()
with open('log',mode='r+',encoding='utf-8') as f1,\ open('log',mode='a+',encoding='utf-8') as f2:#\可以用来换行 l1 = f1.read() print(l1) f2.write('汉阳树')#此时指针在末尾 f2.seek(0) l2 = f2.read() print(l2)

readline(),readlines()
with open('log',mode='w+',encoding='utf-8') as f1,\ open('log',mode='r+',encoding='utf-8') as f2: f1.write('晴川历历汉阳树\n芳草萋萋鹦鹉洲') f1.seek(0) print(f2.read()) f2.seek(0) print('########分界线#######') print(f2.readline(),end='\n')#只能读取一行 f2.seek(0) print(f2.readlines())#读取多行,并且是一个列表

注:列表可以用for循环读取。
truncate(size)
从文件的首行字符开始截断,截断文件为size个字节,无size表示从当前位置截断,截断之后后面的所有字符被删除。
f = open('log',mode='w+',encoding='utf-8') f.write('晴川历历汉阳树,芳草萋萋鹦鹉洲') f.truncate(3)#按字节,一个中文三个字节,否则引发异常 f.seek(0) print(f.read()) f.close() f = open('log',mode='w+',encoding='utf-8') f.write('晴aaa川历历汉阳树,芳草萋萋鹦鹉洲') f.truncate(5)#按字节,一个中文三个字节,否则引发异常 f.seek(0) print(f.read()) f.close()

编码
编码概述
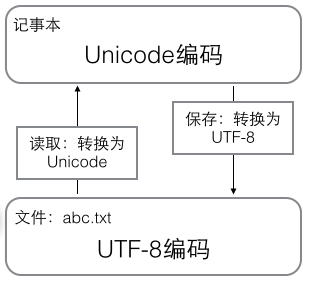
在计算机内存中,统一使用unicode编码,当需要保存到硬盘中或者需要传输的时候,就转换为UTF-8编码。
用记事本编辑的时候,从文件读取的UTF-8字符被转换为Unicode字符到内存里,编辑完成后,保存的时候再把unicode转换为utf-8保存到文件:
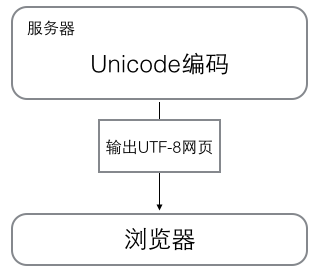
浏览网页的时候,服务器会把动态生成的unicode内容转换为utf-8再传输到浏览器:
#str --->bytes encode 编码 s = '李白'#字符串是unicode b = s.encode('utf-8')#编码成其他编码方式用来保存或传输 print(b,type(b)) #bytes --->str decode 解码 s1 = b.decode('utf-8') print(s1,type(s1))

s = 'aaa' b = s.encode('utf-8')#编码 print(b,type(b)) #bytes --->str decode 解码 s1 = b.decode('gbk') print(s1,type(s1))

pass
作者:Gruffalo
---------------------------------------------
天行健,君子以自强不息
地势坤,君子以厚德载物
内容仅为自己做日常记录,备忘笔记等
真小白,努力学习ing...一起加油吧!(ง •̀_•́)ง

 浙公网安备 33010602011771号
浙公网安备 33010602011771号