jvm面试
1、说一下jdk的对空间的内存划分是怎样的?
Jdk1.7堆空间划分如下

Jdk1.8堆空间将永久代取消,改为元空间
2、JVM中一次完整的GC流程是怎样的,对象如何晋升到老年代
- Java堆 = 老年代 + 新生代
- 新生代 = Eden + S0 + S1
- 当 Eden 区的空间满了, Java虚拟机会触发一次 Minor GC,以收集新生代的垃圾,存活下来的对象,则会转移到 Survivor区。
- 大对象(需要大量连续内存空间的Java对象,如那种很长的字符串)直接进入老年态;
如果对象在Eden出生,并经过第一次Minor GC后仍然存活,并且被Survivor容纳的话,年龄设为1,每熬过一次Minor GC,年龄+1,若年龄超过一定限制(15),则被晋升到老年态。即长期存活的对象进入老年态。 - 老年代满了而无法容纳更多的对象,Minor GC 之后通常就会进行Full GC,Full GC 清理整个内存堆 – 包括年轻代和年老代。
- Major GC 发生在老年代的GC,清理老年区,经常会伴随至少一次Minor GC,比Minor GC慢10倍以上。
3、什么情况下会发生栈内存溢出?
思路: 描述栈定义,再描述为什么会溢出,再说明一下相关配置参数,OK的话可以给面试官手写是一个栈溢出的demo
答案:
- 栈是线程私有的,他的生命周期与线程相同,每个方法在执行的时候都会创建一个栈帧,用来存储局部变量表,操作数栈,动态链接,方法出口等信息。局部变量表又包含基本数据类型,对象引用类型
- 如果线程请求的栈深度大于虚拟机所允许的最大深度,将抛出StackOverflowError异常,方法递归调用产生这种结果。
- 如果Java虚拟机栈可以动态扩展,并且扩展的动作已经尝试过,但是无法申请到足够的内存去完成扩展,或者在新建立线程的时候没有足够的内存去创建对应的虚拟机栈,那么Java虚拟机将抛出一个OutOfMemory 异常。(线程启动过多)
- 参数 -Xss 去调整JVM栈的大小
4、详解JVM内存模型
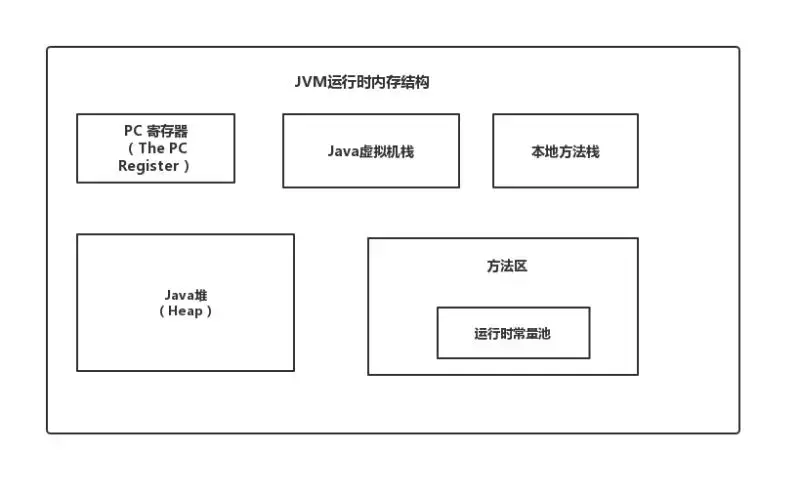
-
程序计数器:当前线程所执行的字节码的行号指示器,用于记录正在执行的虚拟机字节指令地址,线程私有。
-
Java虚拟栈:存放基本数据类型、对象的引用、方法出口等,线程私有。
-
Native方法栈:和虚拟栈相似,只不过它服务于Native方法,线程私有。
-
Java堆:java内存最大的一块,所有对象实例、数组都存放在java堆,GC回收的地方,线程共享。
-
方法区:存放已被加载的类信息、常量、静态变量、即时编译器编译后的代码数据等。(即永久带),回收目标主要是常量池的回收和类型的卸载,各线程共享
5、JVM内存为什么要分成新生代,老年代,持久代。新生代中为什么要分为Eden和Survivor。
1)共享内存区划分
- 共享内存区 = 持久带 + 堆
- 持久带 = 方法区 + 其他
- Java堆 = 老年代 + 新生代
- 新生代 = Eden + S0 + S1
2)一些参数的配置
- 默认的,新生代 ( Young ) 与老年代 ( Old ) 的比例的值为 1:2 ,可以通过参数 –XX:NewRatio 配置。
- 默认的,Edem : from : to = 8 : 1 : 1 ( 可以通过参数 –XX:SurvivorRatio 来设定)
- Survivor区中的对象被复制次数为15(对应虚拟机参数 -XX:+MaxTenuringThreshold)
3)为什么要分为Eden和Survivor?为什么要设置两个Survivor区?
- 如果没有Survivor,Eden区每进行一次Minor GC,存活的对象就会被送到老年代。老年代很快被填满,触发Major GC.老年代的内存空间远大于新生代,进行一次Full GC消耗的时间比Minor GC长得多,所以需要分为Eden和Survivor。
- Survivor的存在意义,就是减少被送到老年代的对象,进而减少Full GC的发生,Survivor的预筛选保证,只有经历16次Minor GC还能在新生代中存活的对象,才会被送到老年代。
- 设置两个Survivor区最大的好处就是解决了碎片化,刚刚新建的对象在Eden中,经历一次Minor GC,Eden中的存活对象就会被移动到第一块survivor space S0,Eden被清空;等Eden区再满了,就再触发一次Minor GC,Eden和S0中的存活对象又会被复制送入第二块survivor space S1(这个过程非常重要,因为这种复制算法保证了S1中来自S0和Eden两部分的存活对象占用连续的内存空间,避免了碎片化的发生)
6、你知道哪几种垃圾收集器,各自的优缺点,重点讲下cms和G1,包括原理,流程,优缺点。
思路: 一定要记住典型的垃圾收集器,尤其cms和G1,它们的原理与区别,涉及的垃圾回收算法。
答案:
1)几种垃圾收集器:
- Serial收集器: 单线程的收集器,收集垃圾时,必须stop the world,使用复制算法。
- ParNew收集器: Serial收集器的多线程版本,也需要stop the world,复制算法。
- Parallel Scavenge收集器: 新生代收集器,复制算法的收集器,并发的多线程收集器,目标是达到一个可控的吞吐量。如果虚拟机总共运行100分钟,其中垃圾花掉1分钟,吞吐量就是99%。
- Serial Old收集器: 是Serial收集器的老年代版本,单线程收集器,使用标记整理算法。
- Parallel Old收集器: 是Parallel Scavenge收集器的老年代版本,使用多线程,标记-整理算法。
- CMS(Concurrent Mark Sweep) 收集器: 是一种以获得最短回收停顿时间为目标的收集器,标记清除算法,运作过程:初始标记,并发标记,重新标记,并发清除,收集结束会产生大量空间碎片。
- G1收集器: 标记整理算法实现,运作流程主要包括以下:初始标记,并发标记,最终标记,筛选标记。不会产生空间碎片,可以精确地控制停顿。
2)CMS收集器和G1收集器的区别:
- CMS收集器是老年代的收集器,可以配合新生代的Serial和ParNew收集器一起使用;
- G1收集器收集范围是老年代和新生代,不需要结合其他收集器使用;
- CMS收集器以最小的停顿时间为目标的收集器;
- G1收集器可预测垃圾回收的停顿时间
- CMS收集器是使用“标记-清除”算法进行的垃圾回收,容易产生内存碎片
- G1收集器使用的是“标记-整理”算法,进行了空间整合,降低了内存空间碎片。
7、强引用、软引用、弱引用、虚引用的区别?
思路: 先说一下四种引用的定义,可以结合代码讲一下,也可以扩展谈到ThreadLocalMap里弱引用用处。
答案:
1)强引用
我们平时new了一个对象就是强引用,例如 Object obj = new Object();即使在内存不足的情况下,JVM宁愿抛出OutOfMemory错误也不会回收这种对象。
2)软引用
如果一个对象只具有软引用,则内存空间足够,垃圾回收器就不会回收它;如果内存空间不足了,就会回收这些对象的内存。
SoftReference<String> softRef=new SoftReference<String>(str); // 软引用
3)弱引用
具有弱引用的对象拥有更短暂的生命周期。在垃圾回收器线程扫描它所管辖的内存区域的过程中,一旦发现了只具有弱引用的对象,不管当前内存空间足够与否,都会回收它的内存。
String str=new String("abc");
WeakReference<String> abcWeakRef = new WeakReference<String>(str);
str=null;
等价于
str = null;
System.gc();
4)虚引用(幽灵引用)
如果一个对象仅持有虚引用,那么它就和没有任何引用一样,在任何时候都可能被垃圾回收器回收。虚引用主要用来跟踪对象被垃圾回收器回收的活动。
9、JVM的常用参数调优你知道哪些?
两个:一个-Xms堆内存初始化大小,一般默认为物理内存的六十四分之一
一个-Xmx堆内存最大分配空间,一般默认为物理内存的四分之一
9、举例几种常见的垃圾收集算法?
- 标记清除法
标记清除法用在新生代,首先标记出所需要回收的对象,在标记完成后统一回收所有被标记的对象
- 复制算法
复制算法用在存活区,把不需要回收的对象全部放在s0/s1区,然后将s1/s0区进行统一的清理
- 标记整理法
标记整理法用在老年代,将需要回收的对象压缩在一边进行垃圾回收
10、在JVM中,如何判断一个对象是否死亡?
判断对象是否死亡有两种方法:1.引用计数法,2.可达性分析算法
引用计数法是最简单最古老的算法,JVM为每个对象分配一个计数器,当对象被引用时,计数器就加1,当对象没有被引用或者离开作用域,计数器就减1。当计数器的值为0时,就代表该对象已经死亡
可达性分析算法,是用GCROOTs 作为对象的起点开始往下搜索,能搜索到这个对象,就表示对象是可达的,不能搜素到表示对象是不可达的
可作为GCRoots的对象包括下面几种:
-
虚拟机栈中引用的对象
-
方法区中类静态属性引用的对象
-
方法区中常量引用的对象
-
本地方法栈中引用的对象
11、什么是类加载?
虚拟机把描述类的数据加载到内存里面,并对数据进行校验、解析和初始化,最终变成可以被虚拟机直接使用的class对象;
12、类加载的过程?
主要分为以下几个过程:加载、验证、准备、解析、初始化;
加载:
加载分为三步:
1、通过类的全限定性类名获取该类的二进制流;
2、将该二进制流的静态存储结构转为方法区的运行时数据结构;
3、在堆中为该类生成一个class对象;
验证:
验证该class文件中的字节流信息复合虚拟机的要求,不会威胁到jvm的安全;
准备:
为class对象的静态变量分配内存,初始化其初始值;
解析:
该阶段主要完成符号引用转化成直接引用;
初始化:
到了初始化阶段,才开始执行类中定义的java代码;
初始化阶段是调用类构造器的过程;
13、什么是双亲委派模型?
当一个类加载器收到一个类加载的请求,他首先不会尝试自己去加载,而是将这个请求委派给父类加载器去加载,只有父类加载器在自己的搜索范围类查找不到给类时,子加载器才会尝试自己去加载该类;
14、为什么需要双亲委派模型?
为了防止内存中出现多个相同的字节码;
因为如果没有双亲委派的话,用户就可以自己定义一个java.lang.String类,那么就无法保证类的唯一性;
15、怎么打破双亲委派模型?
自定义类加载器,继承ClassLoader类,重写loadClass方法和findClass方法;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号