SpringBoot开发案例之多任务并行+线程池处理

前言
前几篇文章着重介绍了后端服务数据库和多线程并行处理优化,并示例了改造前后的伪代码逻辑。当然了,优化是无止境的,前人栽树后人乘凉。作为我们开发者来说,既然站在了巨人的肩膀上,就要写出更加优化的程序。
改造
理论上讲,线程越多程序可能更快,但是在实际使用中我们需要考虑到线程本身的创建以及销毁的资源消耗,以及保护操作系统本身的目的。我们通常需要将线程限制在一定的范围之类,线程池就起到了这样的作用。
程序逻辑
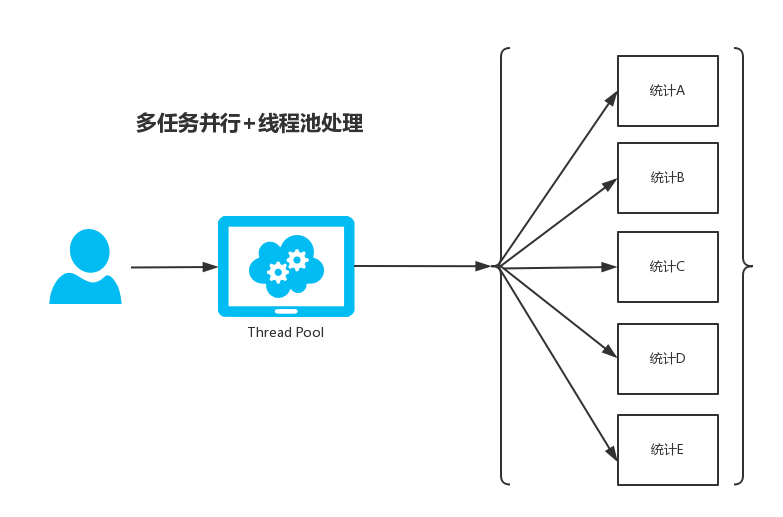
一张图能解决的问题,就应该尽可能的少BB,当然底层原理性的东西还是需要大家去记忆并理解的。
Java 线程池
Java通过Executors提供四种线程池,分别为:
- newCachedThreadPool创建一个可缓存线程池,如果线程池长度超过处理需要,可灵活回收空闲线程,若无可回收,则新建线程。
- newFixedThreadPool 创建一个定长线程池,可控制线程最大并发数,超出的线程会在队列中等待。
- newScheduledThreadPool 创建一个定长线程池,支持定时及周期性任务执行。
- newSingleThreadExecutor 创建一个单线程化的线程池,它只会用唯一的工作线程来执行任务,保证所有任务按照指定顺序(FIFO, LIFO, 优先级)执行。
优点
- 重用存在的线程,减少对象创建、消亡的开销,性能佳。
- 可有效控制最大并发线程数,提高系统资源的使用率,同时避免过多资源竞争,避免堵塞。
- 提供定时执行、定期执行、单线程、并发数控制等功能。
代码实现
方式一(CountDownLatch)
/**
* 多任务并行+线程池统计
* 创建者 科帮网 https://blog.52itstyle.com
* 创建时间 2018年4月17日
*/
public class StatsDemo {
final static SimpleDateFormat sdf = new SimpleDateFormat(
"yyyy-MM-dd HH:mm:ss");
final static String startTime = sdf.format(new Date());
/**
* IO密集型任务 = 一般为2*CPU核心数(常出现于线程中:数据库数据交互、文件上传下载、网络数据传输等等)
* CPU密集型任务 = 一般为CPU核心数+1(常出现于线程中:复杂算法)
* 混合型任务 = 视机器配置和复杂度自测而定
*/
private static int corePoolSize = Runtime.getRuntime().availableProcessors();
/**
* public ThreadPoolExecutor(int corePoolSize,int maximumPoolSize,long keepAliveTime,
* TimeUnit unit,BlockingQueue<Runnable> workQueue)
* corePoolSize用于指定核心线程数量
* maximumPoolSize指定最大线程数
* keepAliveTime和TimeUnit指定线程空闲后的最大存活时间
* workQueue则是线程池的缓冲队列,还未执行的线程会在队列中等待
* 监控队列长度,确保队列有界
* 不当的线程池大小会使得处理速度变慢,稳定性下降,并且导致内存泄露。如果配置的线程过少,则队列会持续变大,消耗过多内存。
* 而过多的线程又会 由于频繁的上下文切换导致整个系统的速度变缓——殊途而同归。队列的长度至关重要,它必须得是有界的,这样如果线程池不堪重负了它可以暂时拒绝掉新的请求。
* ExecutorService 默认的实现是一个无界的 LinkedBlockingQueue。
*/
private static ThreadPoolExecutor executor = new ThreadPoolExecutor(corePoolSize, corePoolSize+1, 10l, TimeUnit.SECONDS,
new LinkedBlockingQueue<Runnable>(1000));
public static void main(String[] args) throws InterruptedException {
CountDownLatch latch = new CountDownLatch(5);
//使用execute方法
executor.execute(new Stats("任务A", 1000, latch));
executor.execute(new Stats("任务B", 1000, latch));
executor.execute(new Stats("任务C", 1000, latch));
executor.execute(new Stats("任务D", 1000, latch));
executor.execute(new Stats("任务E", 1000, latch));
latch.await();// 等待所有人任务结束
System.out.println("所有的统计任务执行完成:" + sdf.format(new Date()));
}
static class Stats implements Runnable {
String statsName;
int runTime;
CountDownLatch latch;
public Stats(String statsName, int runTime, CountDownLatch latch) {
this.statsName = statsName;
this.runTime = runTime;
this.latch = latch;
}
public void run() {
try {
System.out.println(statsName+ " do stats begin at "+ startTime);
//模拟任务执行时间
Thread.sleep(runTime);
System.out.println(statsName + " do stats complete at "+ sdf.format(new Date()));
latch.countDown();//单次任务结束,计数器减一
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
方式二(Future)
/**
* 多任务并行+线程池统计
* 创建者 科帮网 https://blog.52itstyle.com
* 创建时间 2018年4月17日
*/
public class StatsDemo {
final static SimpleDateFormat sdf = new SimpleDateFormat(
"yyyy-MM-dd HH:mm:ss");
final static String startTime = sdf.format(new Date());
/**
* IO密集型任务 = 一般为2*CPU核心数(常出现于线程中:数据库数据交互、文件上传下载、网络数据传输等等)
* CPU密集型任务 = 一般为CPU核心数+1(常出现于线程中:复杂算法)
* 混合型任务 = 视机器配置和复杂度自测而定
*/
private static int corePoolSize = Runtime.getRuntime().availableProcessors();
/**
* public ThreadPoolExecutor(int corePoolSize,int maximumPoolSize,long keepAliveTime,
* TimeUnit unit,BlockingQueue<Runnable> workQueue)
* corePoolSize用于指定核心线程数量
* maximumPoolSize指定最大线程数
* keepAliveTime和TimeUnit指定线程空闲后的最大存活时间
* workQueue则是线程池的缓冲队列,还未执行的线程会在队列中等待
* 监控队列长度,确保队列有界
* 不当的线程池大小会使得处理速度变慢,稳定性下降,并且导致内存泄露。如果配置的线程过少,则队列会持续变大,消耗过多内存。
* 而过多的线程又会 由于频繁的上下文切换导致整个系统的速度变缓——殊途而同归。队列的长度至关重要,它必须得是有界的,这样如果线程池不堪重负了它可以暂时拒绝掉新的请求。
* ExecutorService 默认的实现是一个无界的 LinkedBlockingQueue。
*/
private static ThreadPoolExecutor executor = new ThreadPoolExecutor(corePoolSize, corePoolSize+1, 10l, TimeUnit.SECONDS,
new LinkedBlockingQueue<Runnable>(1000));
public static void main(String[] args) throws InterruptedException {
List<Future<String>> resultList = new ArrayList<Future<String>>();
//使用submit提交异步任务,并且获取返回值为future
resultList.add(executor.submit(new Stats("任务A", 1000)));
resultList.add(executor.submit(new Stats("任务B", 1000)));
resultList.add(executor.submit(new Stats("任务C", 1000)));
resultList.add(executor.submit(new Stats("任务D", 1000)));
resultList.add(executor.submit(new Stats("任务E", 1000)));
//遍历任务的结果
for (Future<String> fs : resultList) {
try {
System.out.println(fs.get());//打印各个线任务执行的结果,调用future.get() 阻塞主线程,获取异步任务的返回结果
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
} finally {
//启动一次顺序关闭,执行以前提交的任务,但不接受新任务。如果已经关闭,则调用没有其他作用。
executor.shutdown();
}
}
System.out.println("所有的统计任务执行完成:" + sdf.format(new Date()));
}
static class Stats implements Callable<String> {
String statsName;
int runTime;
public Stats(String statsName, int runTime) {
this.statsName = statsName;
this.runTime = runTime;
}
public String call() {
try {
System.out.println(statsName+ " do stats begin at "+ startTime);
//模拟任务执行时间
Thread.sleep(runTime);
System.out.println(statsName + " do stats complete at "+ sdf.format(new Date()));
} catch (InterruptedException e) {
e.printStackTrace();
}
return call();
}
}
}
执行时间
以上代码,均是伪代码,下面是2000+个学生的真实测试记录。
2018-04-17 17:42:29.284 INFO 测试记录81e51ab031eb4ada92743ddf66528d82-单线程顺序执行,花费时间:3797
2018-04-17 17:42:31.452 INFO 测试记录81e51ab031eb4ada92743ddf66528d82-多线程并行任务,花费时间:2167
2018-04-17 17:42:33.170 INFO 测试记录81e51ab031eb4ada92743ddf66528d82-多线程并行任务+线程池,花费时间:1717

作者: 小柒
出处: https://blog.52itstyle.vip

分享是快乐的,也见证了个人成长历程,文章大多都是工作经验总结以及平时学习积累,基于自身认知不足之处在所难免,也请大家指正,共同进步。
本文版权归作者所有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出, 如有问题, 可邮件(345849402@qq.com)咨询。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号